四. 基于环视Camera的BEV感知算法-BEVDistill
目录
-
- 前言
- 0. 简述
- 1. 算法动机&开创性思路
- 2. 主体结构
- 3. 损失函数
- 4. 性能对比
- 总结
- 下载链接
- 参考
前言
自动驾驶之心推出的《国内首个BVE感知全栈系列学习教程》,链接。记录下个人学习笔记,仅供自己参考
本次课程我们来学习下课程第四章——基于环视Camera的BEV感知算法,一起去学习下 BEVDistill 感知算法
课程大纲可以看下面的思维导图
0. 简述
本次课程是我们 BEV 算法讲解部分最后一个论文框架,我们这篇文章来看一下能不能用一个不一样的视角去构造 BEV 特征,
我们还是从以下四个方面展开,算法动机&开创性思路、主体结构、损失函数以及性能对比
1. 算法动机&开创性思路
我们本节课程要学习的算法叫 BEVDistill,我们在讲解 BEVDistill 算法之前,我们先复习一下图像是怎么生成 BEV 特征的,点云是怎么生成 BEV 特征的,那我们在这里以 BEVFusion 的框架为例,如下图所示:
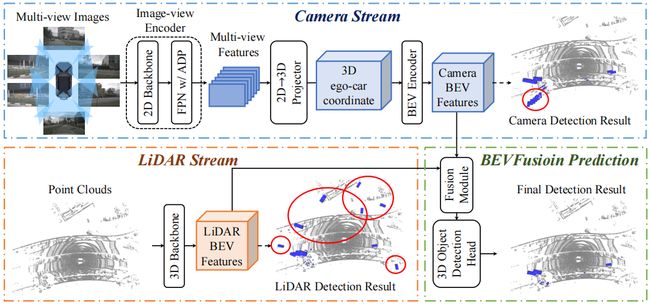
BEVFusion 本身包含 Camera Stream 图像输入和 LiDAR Stream 点云输入,它们可以分别得到 Camera BEV Feature 利用图像特征去构造的一个 BEV 空间特征,LiDAR BEV Feature 利用点云特征去构造的一个 BEV 空间特征
输入图像怎么处理呢,用 Camera Stream 专门处理图像网络的,利用图像编码器 Encoder 可以得到图像特征,然后通过 2D 到 3D 的一个转换图像特征可以从 2D 映射到 3D 然后再投影到 BEV 空间,通过这样的方式可以得到所谓的 Camera BEV Feature
那点云是怎么处理的呢,点云其实是 LiDAR Stream,它是用来专门处理点云数据的,我们输入的 Point Clouds 点云数据通过 3D Backbone 主干网络之后我们可以得到 3D 的点云特征,我们可以把这个点云特征拍扁到 BEV 上得到这个点云的 BEV 特征
那我们到这里有什么呢,我们有了图像的 BEV 特征有了点云的 BEV 特征,下一步呢是做融合,利用这个融合模块可以得到混合特征,那混合特征就可以拿去做预测。此外 BEVFusion 作者为了实现每个模态的一个独立检测功能,额外加入了两个 Detection Head,可以分别输出相机检测结果的和点云检测结果,也就是说我们利用单一的相机数据可以有个预测结果,利用单一的点云数据也可以有个预测结果
那我们这里也可以发现像 BEVFusion 这种做法存在两种 BEV 特征,一种呢我们叫 Camera BEV Feature,图像的 BEV 特征,那另外一种叫 LiDAR BEV Feature,点云的 BEV 特征,那这两种 BEV 特征它各有什么特性呢,Camera BEV Feature 和 LiDAR BEV Feature 它们都有什么特点呢
那它们的特点呢我们其实要从纯视觉方案和融合方案的思路出发,那我们一般认为纯视觉方案成本比较低,因为相机相对而言还是比较便宜的,另外纯视觉方案可能对于偏远距离的目标比较有优势,其实也很好理解,因为远距离的目标很多时候前端的点云采集设备它只能采集到少量的点,因此很难用来做检测;那么相比图像纯视觉方案而言呢,点云最显著的优势是提供了 3D 的空间信息,因为它额外提供了深度维度,有了更精准的位置信息,BEVFusion 在这里是通过自适应融合的方法融合了点云和图像特征来做后续检测任务,所以属于融合处理的方案
那我们思考一个问题,有没有一种可能能够同时利用相机和点云的优势,在预测阶段可以不用依赖于点云信息呢。那也就是说我们训练的时候相机和点云是同时训练的,那测试的时候呢我们把 LiDAR Stream 扔掉,利用 Camera Stream 去做推理
那其实这种思路以前也有很多研究人员尝试过,核心思想是利用 LiDAR 模态也就是点云模态提供的几何语义去增强图像检测器的一个性能,那我们检测器的核心呢是图像,图像是核心,我们的点云数据如何提供更好的辅助信息可以帮助图像取得更好的性能呢,这是我们需要去思考的

那上面的左图是一种方案,我们刚讲过一般而言我们说点云的优势其实在于包含了 3D 空间的信息,那么像这种 3D 空间信息可以转换为一种深度监督,它是用于监督的。从图中我们可以看到点云是作为 Ground Truth 存在的,用来监督 2D 图像深度预测得准不准,那比如说 2D 有一个深度预测结果,我们通过 2D 深度预测结果与原本的点云 GT 两个做比对来判断 2D 图像深度预测得是否准确
那我们这个思路是什么意思呢,输入点云可以投影到多视角图像上,通过相机参数可以获得深度监督图,那这个监督图和 2D 框架预测出的深度可以进行损失函数的计算,它用于监督 2D 深度估计网络从而促使我们 2D 深度估计得更准,2D 深度如果估计得更准了,那从 2D 到 3D 空间特征的转换构造也会更准,从而我们构造的 3D 特征空间也会更好,从而 BEV 特征空间也会更好,那我们检测如果是基于 BEV 空间去做的检测,检测结果也会更好
那所以我们左图呢是一种方式,那这个方式中我们点云提供的辅助信息是什么呢,是深度辅助监督,通过点云提供的比较准确的深度监督值呢为我们 2D 的深度估计网络提供更好的一个可学习的信息
另外一种思路我们想一下点云还能为图像做什么呢,我们知道上面左图中点云是提供 Depth,那右图中点云是提供什么呢,另外一种我们叫蒸馏,蒸馏这个词呢是叫 Distillation,那 BEVDistill 其实也是蒸馏这个词的缩写把前面拿过来再添上个 BEV,组合成的 BEVDistill 也就是我们本篇文章的缩写
那我们说的 BEVDistill 从字面意思上来讲呢也就包含两层意思,前面一层呢是 BEV,我们在什么上面做的 Distill 呢,在 BEV 上面做的 Distill,那什么叫 Distill 呢,它是一种蒸馏,那可能这个词不是特别好理解,我们举一个通俗的例子,那我们大家都知道蒸馏水是用蒸馏的方法去除我们纯净水中的一些不挥发的杂质,那我们最终可以得到一个冷凝水,我们可以把它当作一个叫浓缩精华的一个过程,我们在深度网络当中讲的蒸馏呢其实偏向于这个概念,是一种浓缩精华的过程
普通的水经过蒸馏它之后的精华是蒸馏水,那网络蒸馏之后的精华是什么,我们从网络能得到什么呢,是知识,是学习得到的知识,那比如 BEV 网络学习到的是 BEV 空间的知识,那比如 2D 检测网络它学习到的是 2D 目标的知识,那比如像车辆检测网络它学到的是车辆的通用结构,行人检测网络它学习到的是行人的通用结构,那像这个知识呢它是一种可迁移的知识
那比如我们输入点云数据可以得到点云特征,输入图像数据可以得到图像 BEV 特征,通常情况下我们认为点云的 BEV 特征由于 3D 信息是更丰富的,所以它在空间定位上比图像而言要更好。那么蒸馏框架可以以点云特征为参考,促使图像 BEV 特征向点云 BEV 特征进行学习,那这就是一个跨模态知识迁移的过程,促使 2D 分支是模仿 3D 分支,那模仿的好我们认为学的好,模仿的差呢我们认为你这个学习没有学习到精准,你这个知识迁移的就不太够
那 OK 我们大家再思考一个问题,那我们这里 BEV 空间的作用是什么,我们为什么要在 BEV 空间上去做这个蒸馏的操作呢,那我们在这里说的 BEV 空间是给点云空间,图像空间提供了一个共享的 BEV 表示,来自不同模态的特征可以自然的去对齐的而不会损失太多的信息,也就是说我们提供的这个 BEV 空间是点云和图像的一个共有空间,我们在这个共有空间上去做对齐而不是我随便以一个 2D 场景或者 3D 场景去做额外的对比
那所以上面的左图点云为图像提供的是什么呢,其实提供的是 Depth,是一个深度值,那我们说右图提供的是什么辅助信息呢,其实是一种深度特征的监督,我们 LiDAR 有一个 BEV Feature,Camera 有一个 BEV Feature,我促使 Camera BEV Feature 去向 LiDAR BEV Feature 去学习,提供的其实是一个 Feature 层面的监督信息
以上是 BEVDistill 的一个思路动机,那我们接下来看一看它的主体结构是什么
2. 主体结构
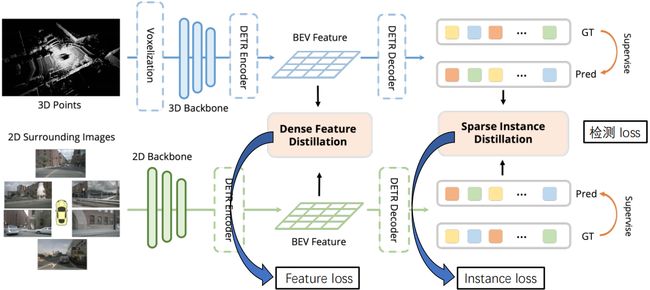
BEVDistill 网络框图如下所示:

BEVDistll 整体设计流程总结如下
- 输入:3D Points 以及 Camera images
- 步骤 1:LiDAR Stream
- 步骤 2:Camera Stream
- 步骤 3:Distillation
- 输出:检测结果
那首先老套路我们从输入输出看起,输入呢我们在 BEV 空间促使图像和点云去做特征的对齐,那么输入呢一个是点云输入一个是图像输入,那输出呢对于 3D 检测任务而言它也自然是 3D 检测结果
我们点云输入通过 体素化、3D Backbone、Encoder 我们可以得到 LiDAR BEV Feature,也就是图中蓝色的部分,那同时通过 Decoder 可以得到 3D 检测结果。那我们多视角图像输入呢通过 2D Backbone、Encoder 可以得到 2D 空间去构造的 BEV Feature,然后我们再经过 Decoder 可以得到图像 BEV 的 3D 检测结果
那 BEVDistill 作者所阐述的蒸馏也就是知识迁移的核心在哪呢,一个是 Dense Feature Disillation,另一个是 Sparse Instance Distillation,一个叫密集的特征蒸馏,一个叫稀疏实例蒸馏,那我们可以发现其实作者这里加了很多限定词
我们先看第一个特征蒸馏,特征蒸馏那顾名思义迁移的知识是什么呢,显然是特征,哪里的特征呢,BEV 的特征,那为什么说是 Dense 的特征呢,那也就是为什么说这是密集的,它其实呢是针对 BEV 空间而言的,因为是对 BEV 空间每个位置去做的一一对齐所以是一种密集对齐
我们再看第二个叫实例蒸馏,那这种迁移的知识是什么呢,其实是一个个的目标实例,那也就是说我们不仅仅呢要做到特征层面的对齐同时呢还需要做到预测结果的对齐,那对于实例而言,实例显然是稀疏的,因为不可能空间所有位置全都密密麻麻的盘满了目标
所以这里流程其实很清晰,输入点云通过点云处理网络我们可以得到点云 BEV 和点云的预测结果,输入图像通过图像处理网络我们可以得到图像 BEV 和图像的预测结果,那我们对齐在哪里做的呢,我们做的是 BEV 特征和预测结果分别进行的对齐
OK,我们接下来呢详细看一下 BEVDistill 这个网络具体是怎么做,那我们首先看上面的部分也就是点云的处理流程,如下图所示:

LiDAR Stream 整体设计流程总结如下:
- 输入:3D Points
- 步骤 1:3D Backbone
- 步骤 2:DETR Encoder 生成 BEV Feature
- 步骤 3:DETR Decoder
- 输入:检测结果
输入原始的点云数据通过体素化的处理,通过 3D Backbone 然后再通过 DETR Encoder 提取特征可以得到 BEV Feature,然后我们再用一个 Decoder 可以得到我们基于点云的检测结果,那大家可以看到 BEVDisitll 中的点云处理模块都是我们之前讲过的一些小模块的组合。那比如说我们把前面这个体素的骨干网络换成基于 Pillar 的或者说基于点的比如 PointNet、PointNet++ 等等可不可以呢,那肯定是可以的,我们只要能生成这个 BEV Feature 前面怎么操作我们是不太关心的
那我们再来,有了 BEV Feature 我们一定要用 DETR Decoder 吗,它是必要的吗,那肯定也不是,我们有了 BEV Feature 我们可以直接连上一个 Detection Head 卷积也好全连接也好等等,我们可以直接预测 3D 结果的,无非是 DETR Decoder 可能在某个数据集下在某个场景下它表现的性能更好一点,我们说点云模块我们主要关注两个重点内容,一个呢是 BEV Feature,利用输入点云得到的 BEV 特征,另一个呢是我们说的检测结果,是输入点云我们得到的检测结果
那么接下来再来看一下图像处理流程是怎么样做的,如下图所示:

Camera Stream 整体设计流程总结如下:
- 输入:Camera images
- 步骤 1:2D Backbone
- 步骤 2:DETR Encoder 生成 BEV Feature
- 步骤 3:DETR Decoder
- 输入:检测结果
图像处理流程我们在前面的章节包括第三章第四章也一直在讲,输入图像我们怎么处理,图像编码网络 2D Backbone 可以得到图像特征,那这个 Backbone 可以有什么呢,我们说过 2D Backbone 它包括 ResNet、Swin Transformer 等等都是可以的
我们最终的目标是一致的,是得到什么呢,可以得到 BEV Feature,我们得到了这个很重要的东西之后呢,引入了后续的 Decoder 可以得到检测结果,那同样这里的 2D Backbone 可以换吗,可以,随便换,后面的解码头可以换吗,可以,随便换,你只要能实现这个功能就可以了
我换好的 2D Backbone 能得到 BEV Feature 那就是一个好的 2D Backbone,我换好的 Decoder 可以得到检测结果,那就是一个好的 Detection Head,所以说图处理流程和点云处理流程一样,我们重点关注两个事情,一个呢是 BEV Feature 也就是我们通过图像处理后所重构出来的 BEV 特征空间,另外一个呢是图像的检测结果
我们为什么要关注这两个事情呢,我们上面说的两个核心的模块其实都与 BEVDistill 的核心内容有关,也就是与蒸馏相关,我们来看下蒸馏部分的整体设计,如下图所示:

Distillation 整体设计流程总结如下:
- 输入 1:BEV Feature
- 输入 2:双流检测结果
- 步骤 1:Dense Feature Distillation
- 步骤 2:Sparse Instance Distillation
那作为图像的两块,图像的 BEV Feature 和图像的检测结果与点云的 BEV Feature 和点云的检测结果,两块是需要去学习的,我们说点云的 BEV 它是作为老师,图像的 BEV 作为学生,学生向老师学习,把老师的知识如果全都学到了,我们就认为学的很好,图像已经完全掌握了点云的本领,同样点云的检测结果如果作为老师,图像的检测结果如果作为学生,学生向老师学习,那两个学习模块是怎么做的呢,我们接着往下看
3. 损失函数
那对于两个学习模块作者其实呢主要还是靠两个损失函数来控制的,一个呢叫 Feature loss 特征损失,我们度量特征差异一般怎么做呢,两个特征,点云的 BEV Feature 和图像的 BEV Feature 我们想度量两种特征的差异一般怎么做,我们一般直接做差就好了,比如使用 L1 损失或者使用 L2 损失,那现在大家思考一个问题,我们如果直接做差其他什么都不管会不会有什么问题,那肯定是存在问题的
问题主要来源于模特表征之间的一个差异,我们知道图像其实算是一个密集性的表征,比如图像的特征网格之上可能每个位置都是有值的,而点云的特征网格可能某些位置是没有值的,我们说图像是密集型表征,前景和背景一般都有值,而点云是稀疏表征,它只有当目标产生反射值的时候才会有值
那所以简单讲图像是表征了很多的背景,而点云呢对于背景表征是比较少的,所以我们如果将两张 Feature Map 直接做差是不太合理的,那所以作者基于这个问题就思考说那我们能不能只计算前景区域就可以了,我们把前景区域的权重提高,把背景区域的权重降低,从而我们促使两个 Feature Map 在前景区域只要趋于一致就可以了,从而不用学习无关背景,作者在 Feature loss 这里设置的时候引入了前景的权重,对前景区域也就是目标的区域去进行保留,对非目标的区域权重是进行了相应的降低的
上面是我们说的 Feature loss 特征层面的损失函数,特征蒸馏部分是这么做的,我们再看第二部分也就是实例蒸馏
实例蒸馏同样的也是引入了一个损失函数叫 Instance loss 实例损失,那么这一部分我们再思考一个问题,是不是说 teacher 网络的预测结果和 student 网络的预测结果是不是越接近越好,是不是说学生的预测一定要和老师的预测一样呢,那显然也不是的,老师也是有犯错的时候的,老师的预测结果中也包含很多的误检,那所以说并不是所有来自老师的预测都应该被视为有价值的一个线索,可能有一些预测结果偏移量很高,旋转角很大等等,它是有一些本身质量不太高的预测结果的
那我们希望学生在学习的时候呢取其精华去其糟粕,我们希望它学习到好的预测而不要学习到这些差的预测,那这个思路是不是又回到我们前面说的 Feature loss 的思路了
我们希望呢在 Feature 学的时候学前景不要学背景,我们希望在 Instance 学的时候呢,学好不要学坏的,那一个很直接的方法是什么呢,乘上权重,我们给好的预测结果权重比较高,给坏的预测结果权重比较低,所以作者在文章中引出了一个叫预测结果质量的一个评价标准,和我们的 GT 真实框 IoU 高的我们认为这是一个预测,它有一个比较高的评价得分或者说权重得分,那和 GT 真实框 IoU 比较低的,它有一个比较低的权重质量得分,用这个质量得分作为权重去控制损失函数的大小
那比如我们这里有一个很好的预测结果,我们认为学生应该同时预测出这个好结果,损失函数里面对于这个结果我们就设一个很高的值,那相反比如老师预测结果很坏,学生是可以忽略这种结果的,那这个权重可以给的稍微低一点
所以总结一下 BEVDistill 分为两路,有一条是点云支路,另外一条是图像支路,是分别得到 BEV Feature 和预测结果的,然后再利用特征损失和实例损失引导学生向老师学习
4. 性能对比
OK,我们最后来看一下实验结果,总体性能如下表所示:
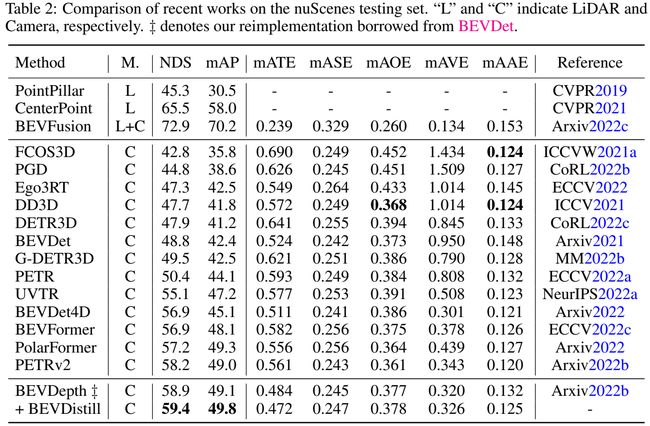
那 BEVDistill 的训练原作者的说法训练设置是 8 张 A100,24 个 epoch,batch 等于 1。那我们上表给的是在 nuScenes 测试集上的一个结果,L 是纯 LiDAR 的方法也就是我们输入是只有点云数据的,C 是纯 Camera 的方法也就是输入是只有纯图像数据的,纯视觉方案,L+C 它就属于融合类的方案像 BEVFusion,因为它输入是既有点云数据也有图像数据的
那大家想一下我们刚讲过 BEVDistill 其实是有两条支路的,有一条支路是输入点云有一条支路是输入图像,它是同时使用了点云和图像作为输入的,那作者为什么把它归为 C 类呢,那这个 C 其实就是 Camera-only 是纯视觉方案,那作者为什么把它归为纯视觉方案呢
那这里其实是因为点云支路它只是作为监督信息提供到图像支路的,它并不参与推理的过程,它提供的是一个比较好的辅助特征,那比如比较好的 Feature 或者比较好的预测结果,是作为一种辅助信息帮助纯视觉方案学得更好,而不是说我们最后的推理过程也要使用点云数据,那所以它这种监督其实和我们通常理解的深度值监督类似,我们平常更多讨论的可能是一些 Depth 的监督,我们 Box 的监督等等,而像这种监督其实是一种特征层面的监督和预测集合层面的监督
那我们看 BEVDistill 和纯视觉方案相比性能还是不错的,NDS 提高到了 59.4

我们还是具体看一下消融实验,表 3 是两个蒸馏模块的性能比较,前面是 BEV Feature 层面的,后面是结果层面的,那 BEV Feature 层面如果我们只引入这个 BEV Feature,提升在 2.4 左右,那我们如果只引入后面的预测结果,提升在 1.6 左右,两个同时使用呢是提高到了 45.7,所以说无论是 BEV 的特征层面的蒸馏,还是后面 instance 预测集合层面的蒸馏两个都是有必要的

那表 4 是和其他的蒸馏方法的对比看出来提升还是比较明显,提升其实是在于以前的做法是对全局特征做的,而 BEVDistill 其实是偏向对前景去做,重建的目标更集中更好一点,那我们既然说前景权重是很重要的,所以表 5 中作者也给出了一系列前景权重的计算方法,是使用 Center 做呢还是使用 Heatmap 做呢,用预测结果做呢,还是用 GT 做呢,那这里作者也给出了很多种方案,从实验结果看呢 GT-Heatmap 更好一点的

表 6 这里还给出了损失函数的对比,我们的检测头呢一般是包含两个支路的,前面 cls 是分类支路,后面的 reg 是回归支路,回归的是我们的坐标位置还有中心点还有尺寸等等啊,那这里作者对分类损失进行了测试,主要测试 CE 交叉熵损失和 infoNCE 对比损失,对比损失可以使得正样本对之间互信息量最大,负样本对之间互信息量最小
那表 7 是对特征对齐而言的,2D 和 3D BEV Feature 对齐而言,那也就是说 BEV 空间中同一位置的 2D 和 3D 的 BEV 特征应该趋于一致,那怎么去度量这种一致呢,作者这里也选取了三种不同方式进行实验对比

那我们也能看到作者做的实验是非常丰富的,他对我们的主干网络也有一个讨论如表 8 所示,我们是使用 BEVFormer 呢还是用 BEVFormer-T 呢,这个 T 代表了引入多帧的时序信息

另外作者还有讨论我们的 Backbone 用 ResNet 好还是 MobileNet 好,另外还把 BEVFormer 换成 BEVDet,可以看到就是这么多对比,那作者的方案性能还是不错的,对于不同的框架不同的网络不同的 Detector 而言 BEVDistill 的性能还是都有所提升的


此外作者还做了 Waymo 数据集,表 11 和表 12 也是针对不同的数据集,那表 11 是做了 Waymo,那表 12 是给出了 nuScenes 详细的指标,这些指标是我们第三章节中中所提到的一些误差指标和一些准确率指标
除了一些指标的结果之外,作者这里还给了可视化的结果,如上图所示,图中蓝色的是检测结果,橙色的是 GT 我们叫 Ground Truth,是真值,橙色蓝色同时包围的一个目标是一个好的预测结果,因为相当于是我们在 GT 中标注了这个目标我们的检测结果也检测出了这个目标,那就是一个好的结果。有蓝色的没有橙色的属于误检,也就是我们检测出来了但是实际上那个位置并没有物体,有橙色没有蓝色属于漏检,也就是说我们在 GT 当中标注的可是我们却没有检测出来。我们也能看到在远距离区域有橙色框但却没有蓝色框,那就说明 BEVDistill 在远距离情况下会产生一些漏检的结果
那我们这个分析也是基于作者在论文中去给的示例的一些分析,那实际远距离情况像 BEVDistill 能做到什么样还是需要再讨论的
OK,本节内容呢是和大家一起学习了一下一个不太一样的 BEV 工作叫 BEVDistill,那这个工作其实比较灵活,大家在实验中也能看到,我们的主干网络、Detector 等等都是可以更换的,它其实提供的是一种核心的思路,是针对着 Feature 层面的对齐和预测目标层面的对齐,像这种思路其实也是在现在的跨模态研究中比较通用的一种思路了
总结
本次课程我们学习了一个不太一样的 BEV 感知算法叫 BEVDistill,BEVDistill 有 LiDAR 和 Camera 两条支路,分别得到 BEV Feature 和预测结果,然后再利用特征损失和实例损失去引导图像支路像点云支路去学习,考虑到点云模态和图像模态之间的差异性,我们在计算损失的时候是不能直接做差的,需要分别乘上相应的权重。本身 BEVDistill 中的各个模块是可以替换的,它提供的是一种核心的思路,是对特征层面和预测结果层面的对齐。
OK,以上就是 BEVDistll 的全部内容了,这也是我们整个 BEV 感知课程中讲解的最后一个论文框架了,下节我们一起去分析下 BEVFormer 的相关代码,敬请期待
下载链接
- 论文下载链接【提取码:6463】
- 数据集下载链接【提取码:data】
参考
- Chen et al. Bevdistill: Cross-modal bev distillation for multi-view 3d object detection