高级排序算法详解(希尔排序)
希尔排序
- 一、排序原理
- 二、API设计
- 三、代码实现
- 【Shell .java】
- 【ShellTest .java】
- 【运行结果】
- 四、时间复杂度分析
- 【插入排序与希尔排序比较】
- 【SortCompare .java】
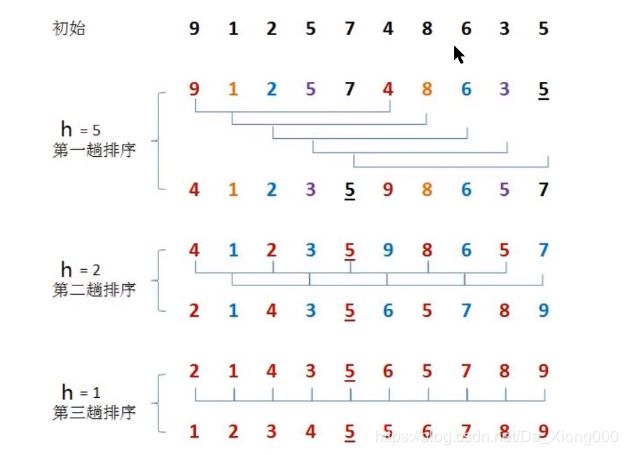
一、排序原理
希尔排序是插入排序的一种,又称”缩小增量排序”,是插入排序算法的一种改进版本。
前面学习插入排序的时候,我们会发现一个很不友好的事儿,如果已排序的分组元素为{2,5,7,9,10} ,未排序的分组元素为{1,8},那么下一个待插入元素为1 , 我们需要拿着1从后往前,依次和10,9,7,5,2进行比较、交换位置,才能完成真正的插入,每次交换只能和相邻的元素交换位置。那如果我们要提高效率,直观的想法就是一次交换 ,能把1放到更前面的位置,比如一次交换就能把1插到2和5之间,这样一次交换1就向前走5个位置,减少交换的次数。
希尔排序的原理:
- 选定一个增长量h ,按照增长量h作为数据分组的依据,对数据进行分组;
- 对分好组的每一组数据完成插入排序;
- 减小增长量,最小减为1 , 重复第二步操作。
(先按照增长量进行分组,对每一组进行排序交换;减少增量,最少减为1;重复操作)
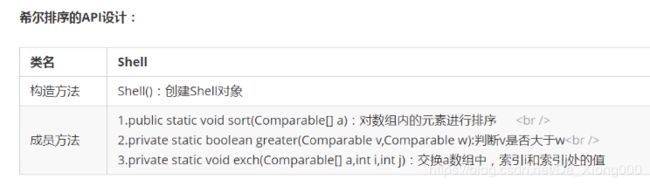
二、API设计
三、代码实现
【Shell .java】
package ShellSorting.sort;
//希尔排序
public class Shell {
//第一个函数:对数组a中的元素进行排序
public static void sort(Comparable[] a){
//1.根据a的长度确定增长量h 的初始值;
int h = 1;
while(h<a.length/2){
h=h*2+1;
}
//2.希尔排序;
while(h>=1){
//排序
//2.1 首先找到待插入的元素
//假设每个分组的第一个元素已排好,从每组第二个元素开始与前面第一个待插入的元素的索引其实就是h的值
for(int i=h;i<a.length;i++){
//2.2把待插入的元素插入到有序数列中
for(int j=i;j>=h;j-=h){
//待插入的元素是a[j],比较a[j]和a[j-h],
//如果j-h大,则交换;如果j大,那么就找到了a[j]应该放的位置,结束循环
if(greater(a[j-h],a[j])){
//交换元素
exch(a,j-h,j);
}else{
//带插入元素已经找到了合适的位置,结束循环;
break;
}
}
}
//减少h的值
h = h/2;
}
}
//第二个函数:比较元素v是否大于w
private static boolean greater(Comparable v,Comparable w){
return v.compareTo(w)>0;
}
//第三个元素:数组元素i与j交换位置
private static void exch(Comparable[] a,int i,int j){
Comparable temp;
temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}
【ShellTest .java】
package ShellSorting.test;
import ShellSorting.sort.Shell;
import java.util.Arrays;
public class ShellTest {
public static void main(String[] args) {
Integer[] a = {9,1,2,5,7,4,8,6,3,5};
Shell.sort(a);
System.out.println(Arrays.toString(a));
}
}
【运行结果】

四、时间复杂度分析
希尔排序的高效率得益于:在第一次将隔很远的元素进行比较交换,大大减少了比较次数和交换次数,提高了效率。
在三种简单排序中,我们都是采用事前估计的方法;
希尔排序中,我们不采用事前估算法.如果用事前估算法对希尔排序分析,我们会涉及到很多或者很复杂的数学知识,为了避免这些,我们采用事后估算对希尔排序进行分析:
对100000到1的逆向数据进行测试。在执行排序前前记录一个时间 ,在排序完成后记录一个时间 ,两个时间的时间差就是排序的耗时。
【插入排序与希尔排序比较】
【SortCompare .java】
package ShellSorting.test;
import ShellSorting.sort.Insertion;
import ShellSorting.sort.Shell;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.Objects;
public class SortCompare {
//主方法中:调用不同的测试方法,完成测试
public static void main(String[] args) throws Exception {
//1.创建一个ArrayList集合,保存读取出来的整数;
ArrayList<Integer> list = new ArrayList<>();
//2.创建缓存读取流BufferedReader:读取数据并存储到ArrayList中;
BufferedReader reader = new BufferedReader(new InputStreamReader((SortCompare.class.getClassLoader().getResourceAsStream("reverse_arr.txt"))));
String line = null;
while((line = reader.readLine())!=null){
//line是字符串,把line转换成Integer,存储到集合中
int i = Integer.parseInt(line); //将line转换成整数
list.add(i);
}
reader.close();
//3.把ArrayList集合转换成数组
Integer[] a = new Integer[list.size()];
list.toArray(a);
//4.调用测试代码并完成测试
testInsertion(a); //10000个数据 运行37499毫秒
testShell(a); //10000个数据 运行30毫秒
}
//测试希尔排序运行时间
public static void testShell(Integer[] a){
//1.获取执行之前的时间
long start = System.currentTimeMillis();
//2.执行算法代码
Shell.sort(a);
//3.获取执行之后的时间
long end = System.currentTimeMillis();
//4.算出程序执行的时间并输出
System.out.println("希尔排序执行的时间为:"+(end-start)+"毫秒");
}
//测试插入排序运行时间
public static void testInsertion(Integer[] a){
//1.获取执行之前的时间
long start = System.currentTimeMillis();
//2.执行算法代码
Insertion.sort(a);
//3.获取执行之后的时间
long end = System.currentTimeMillis();
//4.算出程序执行的时间并输出
System.out.println("插入排序执行的时间为:"+(end-start)+"毫秒");
}
}
这段程序会用到以前的插入排序代码:
插入排序
运行结果:
插入排序执行时间为:37499毫秒
希尔排序执行时间为:30毫秒
总结:希尔排序的性能远远高于插入排序!
喜欢的话记得点赞收藏哟
数据结构与算法—博文专栏持续更新!