零一万物开源Yi-VL多模态大模型,推理&微调最佳实践来啦!
近期,零一万物Yi系列模型家族发布了其多模态大模型系列,**Yi Vision Language(Yi-VL)**多模态语言大模型正式面向全球开源。凭借卓越的图文理解和对话生成能力,Yi-VL模型在英文数据集MMMU和中文数据集CMMMU上取得了领先成绩,展示了在复杂跨学科任务上的强大实力。
基于Yi语言模型的强大文本理解能力,只需对图片进行对齐,就可以得到不错的多模态视觉语言模型——这也是Yi-VL模型的核心亮点之一。
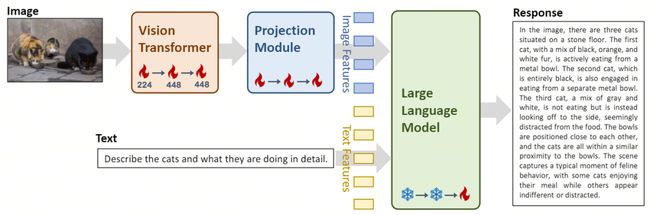
在架构设计上,Yi-VL模型基于开源 LLaVA架构,包含三个主要模块:
-
Vision Transformer(简称ViT) 用于图像编码,使用开源的OpenClip ViT-H/14模型初始化可训练参数,通过学习从大规模"图像-文本"对中提取特征,使模型具备处理和理解图像的能力。
-
Projection模块 为模型带来了图像特征与文本特征空间对齐的能力。该模块由一个包含层归一化(layer normalizations)的多层感知机(Multilayer Perceptron,简称MLP)构成。这一设计使得模型可以更有效地融合和处理视觉和文本信息,提高了多模态理解和生成的准确度。
-
Yi-34B-Chat和Yi-6B-Chat 大规模语言模型的引入为 Yi-VL 提供了强大的语言理解和生成能力。该部分模型借助先进的自然语言处理技术,能够帮助 Yi-VL 深入理解复杂的语言结构,并生成连贯、相关的文本输出。
技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了大模型面试与技术交流群, 想要进交流群、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2060,备注:技术交流
资料1

用通俗易懂方式讲解系列
- 用通俗易懂的方式讲解:自然语言处理初学者指南(附1000页的PPT讲解)
- 用通俗易懂的方式讲解:NLP 这样学习才是正确路线
- 用通俗易懂的方式讲解:28张图全解深度学习知识!
- 用通俗易懂的方式讲解:不用再找了,这就是 NLP 方向最全面试题库
- 用通俗易懂的方式讲解:实体关系抽取入门教程
- 用通俗易懂的方式讲解:灵魂 20 问帮你彻底搞定Transformer
- 用通俗易懂的方式讲解:图解 Transformer 架构
- 用通俗易懂的方式讲解:大模型算法面经指南(附答案)
- 用通俗易懂的方式讲解:十分钟部署清华 ChatGLM-6B,实测效果超预期
- 用通俗易懂的方式讲解:内容讲解+代码案例,轻松掌握大模型应用框架 LangChain
- 用通俗易懂的方式讲解:如何用大语言模型构建一个知识问答系统
- 用通俗易懂的方式讲解:最全的大模型 RAG 技术概览
- 用通俗易懂的方式讲解:利用 LangChain 和 Neo4j 向量索引,构建一个RAG应用程序
- 用通俗易懂的方式讲解:使用 Neo4j 和 LangChain 集成非结构化知识图增强 QA
- 用通俗易懂的方式讲解:面了 5 家知名企业的NLP算法岗(大模型方向),被考倒了。。。。。
以下为大家带来推理、微调最佳实践教程。
环境配置与安装
本文使用的模型为Yi-VL-6B模型,可在ModelScope的Notebook的环境(这里以PAI-DSW为例)的配置下运行(显存24G) 。
环境配置与安装
本文主要演示的模型推理代码可在魔搭社区免费实例PAI-DSW的配置下运行(显存24G) :
点击模型右侧Notebook快速开发按钮,选择GPU环境:
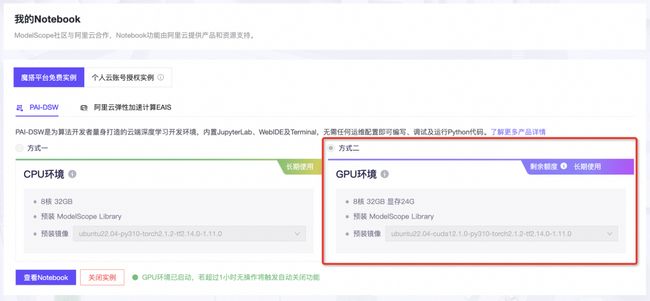
打开Terminal环境:

模型链接和下载
Yi系列模型现已在ModelScope社区开源,包括:
Yi-VL-34B模型:
https://modelscope.cn/models/01ai/Yi-VL-34B/summary
Yi-VL-6B模型:
https://modelscope.cn/models/01ai/Yi-VL-6B/summary
社区支持直接下载模型的repo:
from modelscope import snapshot_download
model_dir = snapshot_download("01ai/Yi-VL-6B", revision = "master")
Yi多模态模型推理
安装环境
使用方式参考:https://github.com/01-ai/Yi/tree/main/VL
安装环境
git clone https://github.com/01-ai/Yi.git
cd Yi/VL
export PYTHONPATH=$PYTHONPATH:$(pwd)
pip install -r requirements.txt
模型推理
CUDA_VISIBLE_DEVICES=0 python single_inference.py --model-path /model-path --image-file /mnt/workspace/test.png --question "图里有几只羊?"
选择了几张图,试下效果:



![]()
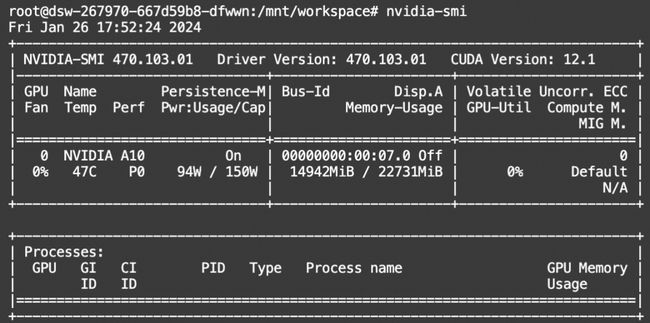
显存占用情况如下:
Yi系列模型微调和微调后推理
我们使用SWIFT来对模型进行微调, swift是魔搭社区官方提供的LLM&AIGC模型微调推理框架. 微调代码开源地址: https://github.com/modelscope/swift
我们使用数据集coco-mini-en-2进行微调. 任务是: 描述图片中的内容。
环境准备:
git clone https://github.com/modelscope/swift.git
cd swift
pip install .[llm]
微调脚本: LoRA
# https://github.com/modelscope/swift/tree/main/examples/pytorch/llm/scripts/yi_vl_6b_chat
# Experimental environment: V100, A10, 3090
# 18GB GPU memory
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model_type yi-vl-6b-chat \
--sft_type lora \
--tuner_backend swift \
--template_type AUTO \
--dtype AUTO \
--output_dir output \
--dataset coco-mini-en \
--train_dataset_sample -1 \
--num_train_epochs 1 \
--max_length 2048 \
--check_dataset_strategy warning \
--lora_rank 8 \
--lora_alpha 32 \
--lora_dropout_p 0.05 \
--lora_target_modules DEFAULT \
--gradient_checkpointing true \
--batch_size 1 \
--weight_decay 0.01 \
--learning_rate 1e-4 \
--gradient_accumulation_steps 16 \
--max_grad_norm 0.5 \
--warmup_ratio 0.03 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 10 \
--use_flash_attn false \
训练过程支持本地数据集,需要指定如下参数:
--custom_train_dataset_path xxx.jsonl \
--custom_val_dataset_path yyy.jsonl \
自定义数据集的格式可以参考:
https://github.com/modelscope/swift/blob/main/docs/source/LLM/自定义与拓展.md#注册数据集的方式
微调后推理脚本: (这里的ckpt_dir需要修改为训练生成的checkpoint文件夹)
# Experimental environment: V100, A10, 3090
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--ckpt_dir "output/yi-vl-6b-chat/vx_xxx/checkpoint-xxx" \
--load_dataset_config true \
--max_length 2048 \
--use_flash_attn false \
--max_new_tokens 2048 \
--temperature 0.5 \
--top_p 0.7 \
--repetition_penalty 1. \
--do_sample true \
--merge_lora_and_save false \
训练后生成样例:

[PROMPT]This is a chat between an inquisitive human and an AI assistant. Assume the role of the AI assistant. Read all the images carefully, and respond to the human's questions with informative, helpful, detailed and polite answers. 这是一个好奇的人类和一个人工智能助手之间的对话。假设你扮演这个AI助手的角色。仔细阅读所有的图像,并对人类的问题做出信息丰富、有帮助、详细的和礼貌的回答。
### Human: [-100 * 1]
please describe the image.
### Assistant:
[OUTPUT]A large airplane is on display in a museum.
###
[LABELS]People walking in a museum with a airplane hanging from the celing.
[IMAGES]['https://xingchen-data.oss-cn-zhangjiakou.aliyuncs.com/coco/2014/val2014/COCO_val2014_000000492132.jpg']

[PROMPT]This is a chat between an inquisitive human and an AI assistant. Assume the role of the AI assistant. Read all the images carefully, and respond to the human's questions with informative, helpful, detailed and polite answers. 这是一个好奇的人类和一个人工智能助手之间的对话。假设你扮演这个AI助手的角色。仔细阅读所有的图像,并对人类的问题做出信息丰富、有帮助、详细的和礼貌的回答。
### Human: [-100 * 1]
please describe the image.
### Assistant:
[OUTPUT]A bowl of fruit and cake next to a cup of coffee.
###
[LABELS]a bowl of fruit and pastry on a table
[IMAGES]['https://xingchen-data.oss-cn-zhangjiakou.aliyuncs.com/coco/2014/val2014/COCO_val2014_000000558642.jpg']