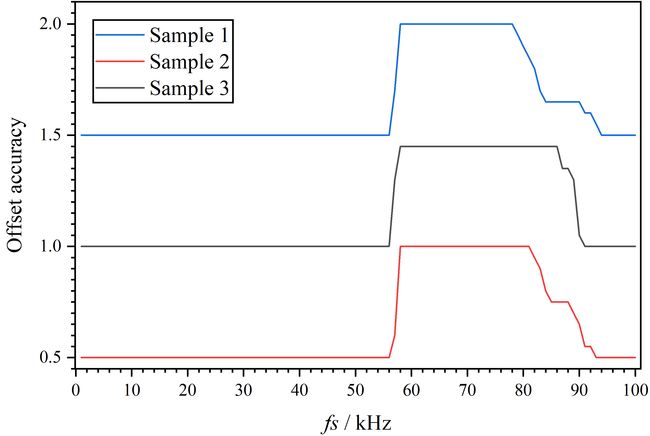
无线通信网络拓扑推理采样率实验(对比测试)
接上文:
无线通信网络拓扑推理采样率实验(数据生成)
四、对比测试
#作者:zhouzhichao
#创建时间:25年6月11日
#内容:进行采样率实验
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
import sys
import torch
torch.set_printoptions(linewidth=200)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from torch_geometric.nn import GCNConv
sys.path.append('D:\无线通信网络认知\论文1\大修意见\Reviewer1-1 阈值相似性图对比实验')
from gcn_dataset import graph_data
print(torch.__version__)
print(torch.cuda.is_available())
from sklearn.metrics import roc_auc_score, precision_score, recall_score, accuracy_score
mode = "gcn"
class Net(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = GCNConv(Input_L, 200)
self.conv2 = GCNConv(200, 100)
# self.conv1 = GCNConv(Input_L, 2000)
# self.conv2 = GCNConv(2000, 500)
def encode(self, x, edge_index):
c1_in = x.T
c1_out = self.conv1(c1_in, edge_index)
c1_relu = c1_out.relu()
c2_out = self.conv2(c1_relu, edge_index)
c2_relu = c2_out.relu()
return c2_relu
def decode(self, z, edge_label_index):
# 节点和边都是矩阵,不同的计算方法致使:节点->节点,节点->边
distance_squared = torch.sum((z[edge_label_index[0]] - z[edge_label_index[1]]) ** 2, dim=-1)
return distance_squared
def decode_all(self, z):
prob_adj = z @ z.t() # 得到所有边概率矩阵
return (prob_adj > 0).nonzero(as_tuple=False).t() # 返回概率大于0的边,以edge_index的形式
@torch.no_grad()
def get_val(self, gcn_data):
#获取未参与训练的节点索引
edge_index = gcn_data.edge_index # [2, 30]
edge_label_index = gcn_data.edge_label_index # [2, 60]
edge_label = gcn_data.edge_label
# 转置方便处理,变成 (num_edges, 2)
edge_index_t = edge_index.t() # [30, 2]
edge_label_index_t = edge_label_index.t() # [60, 2]
# 把边转成集合形式的字符串,方便查找(也可用tuple)
edge_index_set = set([tuple(e.tolist()) for e in edge_index_t])
# 判断edge_label_index中的每个边是否在edge_index_set里
is_in_edge_index = [tuple(e.tolist()) in edge_index_set for e in edge_label_index_t]
is_in_edge_index = torch.tensor(is_in_edge_index)
# 不相同的列(边)
val_col = edge_label_index[:, ~is_in_edge_index]
val_label = edge_label[~is_in_edge_index]
val_col = val_col[:,:20]
val_label = val_label[:20]
divide_index = 10
val_col_1 = val_col[:,:divide_index]
val_label_1 = val_label[:divide_index]
val_col_0 = val_col[:, divide_index:]
val_label_0 = val_label[divide_index:]
return val_col_1, val_label_1, val_col_0, val_label_0
@torch.no_grad()
def test_val(self, gcn_data, threshhold):
model.eval()
# same_col, diff_col, same_label, diff_label = col_devide(gcn_data)
val_col_1, val_label_1, val_col_0, val_label_0 = self.get_val(gcn_data)
# 1
z = model.encode(gcn_data.x, gcn_data.edge_index)
out = model.decode(z, val_col_1).view(-1)
out = 1 - out
out_np = out.cpu().numpy()
labels_1 = val_label_1.cpu().numpy()
# roc_auc_s = roc_auc_score(labels_np, out_np)
pred_1 = (out_np > threshhold).astype(int)
accuracy_1 = accuracy_score(labels_1, pred_1)
precision_1 = precision_score(labels_1, pred_1, zero_division=1)
recall_1 = recall_score(labels_1, pred_1, zero_division=1)
# 0
z = model.encode(gcn_data.x, gcn_data.edge_index)
out = model.decode(z, val_col_0).view(-1)
out = 1 - out
out_np = out.cpu().numpy()
labels_0 = val_label_0.cpu().numpy()
# roc_auc_d = roc_auc_score(labels_np, out_np)
pred_0 = (out_np > threshhold).astype(int)
accuracy_0 = accuracy_score(labels_0, pred_0)
precision_0 = precision_score(labels_0, pred_0, zero_division=1)
recall_0 = recall_score(labels_0, pred_0, zero_division=1)
accuracy = (accuracy_1 + accuracy_0)/2
precision = (precision_1 + precision_0)/2
recall = (recall_1 + recall_0)/2
return accuracy, precision, recall
@torch.no_grad()
def calculate_threshhold(self, gcn_data):
model.eval()
z = model.encode(gcn_data.x, gcn_data.edge_index)
out = model.decode(z, gcn_data.edge_label_index).view(-1)
out = 1 - out
out_np = out.cpu().numpy()
labels_np = gcn_data.edge_label.cpu().numpy()
threshhold = 0
accuracy_max = 0
for th in np.arange(-2, 1.1, 0.1):
pred_labels = (out_np > th).astype(int)
accuracy = accuracy_score(labels_np, pred_labels)
if accuracy>accuracy_max:
accuracy_max = accuracy
threshhold = th
return threshhold
N = 30
train_n = 20
M = 3000
snr = 40
def graph_normalize(gcn_data):
for i in range(gcn_data.x.shape[1]):
gcn_data.x[:, i] = gcn_data.x[:,i]/torch.max(torch.abs(gcn_data.x[:,i]))
print("snr: ", snr)
fs_list = []
accuracy_list = []
for fs_i in range(100):
fs = fs_i + 1
fs_list.append(fs)
accuracy = []
for i in range(3):
root = "1k-100kHz data (pyg)//graph " + "fs-" + str(fs) + "kHz i-" + str(i)
gcn_data = graph_data(root)
graph_normalize(gcn_data)
Input_L = gcn_data.x.shape[0]
model = Net()
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.01)
criterion = torch.nn.BCEWithLogitsLoss()
model.train()
def train():
optimizer.zero_grad()
z = model.encode(gcn_data.x, gcn_data.edge_index)
out = model.decode(z, gcn_data.edge_label_index).view(-1)
out = 1 - out
loss = criterion(out, gcn_data.edge_label)
loss.backward()
optimizer.step()
return loss
min_loss = 99999
count = 0#早停
for epoch in range(100000):
loss = train()
if loss100:
threshhold = model.calculate_threshhold(gcn_data)
break
accuracy_value, precision_value, recall_value = model.test_val(gcn_data,threshhold)
accuracy.append(accuracy_value)
accuracy_list.append(np.mean(accuracy))
data = {
'fs_list': fs_list,
'accuracy_list': accuracy_list
}
# 创建一个 DataFrame
df = pd.DataFrame(data)
#
# # 保存到 Excel 文件
file_path = 'D:\无线通信网络认知\论文1\大修意见\Reviewer2-2 采样率实验\\accuracy-fs.xlsx'
df.to_excel(file_path, index=False)
优化方案
先对波形进行采样,再随机生成多个样本,这样很难测试出采样率对拓扑推理准确率的影响,因为噪声、拓扑、幅值等都是变化的。
更好的方法是先生成多个样本,再对这些样本进行降采样,这样就对样本进行了控制,噪声、拓扑、幅值不变,只让采样率变化,实现严格的控制变量。
对比测试程序优化:
#作者:zhouzhichao
#创建时间:25年6月11日
#内容:进行采样率实验
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
import sys
import torch
torch.set_printoptions(linewidth=200)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from torch_geometric.nn import GCNConv
sys.path.append('D:\无线通信网络认知\论文1\大修意见\Reviewer1-1 阈值相似性图对比实验')
from gcn_dataset import graph_data
print(torch.__version__)
print(torch.cuda.is_available())
from sklearn.metrics import roc_auc_score, precision_score, recall_score, accuracy_score
mode = "gcn"
class Net(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = GCNConv(Input_L, 200)
self.conv2 = GCNConv(200, 100)
# self.conv1 = GCNConv(Input_L, 2000)
# self.conv2 = GCNConv(2000, 500)
def encode(self, x, edge_index):
c1_in = x.T
c1_out = self.conv1(c1_in, edge_index)
c1_relu = c1_out.relu()
c2_out = self.conv2(c1_relu, edge_index)
c2_relu = c2_out.relu()
return c2_relu
def decode(self, z, edge_label_index):
# 节点和边都是矩阵,不同的计算方法致使:节点->节点,节点->边
distance_squared = torch.sum((z[edge_label_index[0]] - z[edge_label_index[1]]) ** 2, dim=-1)
return distance_squared
def decode_all(self, z):
prob_adj = z @ z.t() # 得到所有边概率矩阵
return (prob_adj > 0).nonzero(as_tuple=False).t() # 返回概率大于0的边,以edge_index的形式
@torch.no_grad()
def get_val(self, gcn_data):
#获取未参与训练的节点索引
edge_index = gcn_data.edge_index # [2, 30]
edge_label_index = gcn_data.edge_label_index # [2, 60]
edge_label = gcn_data.edge_label
# 转置方便处理,变成 (num_edges, 2)
edge_index_t = edge_index.t() # [30, 2]
edge_label_index_t = edge_label_index.t() # [60, 2]
# 把边转成集合形式的字符串,方便查找(也可用tuple)
edge_index_set = set([tuple(e.tolist()) for e in edge_index_t])
# 判断edge_label_index中的每个边是否在edge_index_set里
is_in_edge_index = [tuple(e.tolist()) in edge_index_set for e in edge_label_index_t]
is_in_edge_index = torch.tensor(is_in_edge_index)
# 不相同的列(边)
val_col = edge_label_index[:, ~is_in_edge_index]
val_label = edge_label[~is_in_edge_index]
val_col = val_col[:,:20]
val_label = val_label[:20]
divide_index = 10
val_col_1 = val_col[:,:divide_index]
val_label_1 = val_label[:divide_index]
val_col_0 = val_col[:, divide_index:]
val_label_0 = val_label[divide_index:]
return val_col_1, val_label_1, val_col_0, val_label_0
@torch.no_grad()
def test_val(self, gcn_data, threshhold):
model.eval()
# same_col, diff_col, same_label, diff_label = col_devide(gcn_data)
val_col_1, val_label_1, val_col_0, val_label_0 = self.get_val(gcn_data)
# 1
z = model.encode(gcn_data.x, gcn_data.edge_index)
out = model.decode(z, val_col_1).view(-1)
out = 1 - out
out_np = out.cpu().numpy()
labels_1 = val_label_1.cpu().numpy()
# roc_auc_s = roc_auc_score(labels_np, out_np)
pred_1 = (out_np > threshhold).astype(int)
accuracy_1 = accuracy_score(labels_1, pred_1)
precision_1 = precision_score(labels_1, pred_1, zero_division=1)
recall_1 = recall_score(labels_1, pred_1, zero_division=1)
# 0
z = model.encode(gcn_data.x, gcn_data.edge_index)
out = model.decode(z, val_col_0).view(-1)
out = 1 - out
out_np = out.cpu().numpy()
labels_0 = val_label_0.cpu().numpy()
# roc_auc_d = roc_auc_score(labels_np, out_np)
pred_0 = (out_np > threshhold).astype(int)
accuracy_0 = accuracy_score(labels_0, pred_0)
precision_0 = precision_score(labels_0, pred_0, zero_division=1)
recall_0 = recall_score(labels_0, pred_0, zero_division=1)
accuracy = (accuracy_1 + accuracy_0)/2
precision = (precision_1 + precision_0)/2
recall = (recall_1 + recall_0)/2
return accuracy, precision, recall
@torch.no_grad()
def calculate_threshhold(self, gcn_data):
model.eval()
z = model.encode(gcn_data.x, gcn_data.edge_index)
out = model.decode(z, gcn_data.edge_label_index).view(-1)
out = 1 - out
out_np = out.cpu().numpy()
labels_np = gcn_data.edge_label.cpu().numpy()
threshhold = 0
accuracy_max = 0
for th in np.arange(-2, 1.1, 0.1):
pred_labels = (out_np > th).astype(int)
accuracy = accuracy_score(labels_np, pred_labels)
if accuracy>accuracy_max:
accuracy_max = accuracy
threshhold = th
return threshhold
N = 30
train_n = 20
def graph_normalize(gcn_data):
for i in range(gcn_data.x.shape[1]):
gcn_data.x[:, i] = gcn_data.x[:,i]/torch.max(torch.abs(gcn_data.x[:,i]))
# for fs_i in range(100):
fs = 100
snr = 10
# for i in range(3):
for i in [0,1,2]:
root = "1k-100kHz data (pyg)/graph " + "fs-" + str(fs) + "kHz snr-"+str(snr)+"db i-" + str(i)
raw_data = graph_data(root)
graph_normalize(raw_data)
fs_list = []
accuracy_list = []
for fs in range(100, 0, -1):
fs_list.append(fs)
gcn_data = raw_data
target_size = int((gcn_data.x.shape[0]-1)/100*fs)
# 创建均匀分布的索引
indices = torch.linspace(0, gcn_data.x.shape[0] - 1, target_size).long()
gcn_data.x = gcn_data.x[indices]
Input_L = gcn_data.x.shape[0]
model = Net()
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.01)
criterion = torch.nn.BCEWithLogitsLoss()
model.train()
def train():
optimizer.zero_grad()
z = model.encode(gcn_data.x, gcn_data.edge_index)
out = model.decode(z, gcn_data.edge_label_index).view(-1)
out = 1 - out
loss = criterion(out, gcn_data.edge_label)
loss.backward()
optimizer.step()
return loss
min_loss = 99999
count = 0#早停
for epoch in range(100000):
loss = train()
if loss100:
threshhold = model.calculate_threshhold(gcn_data)
break
accuracy_value, precision_value, recall_value = model.test_val(gcn_data,threshhold)
accuracy_list.append(accuracy_value)
data = {
'fs_list': fs_list,
'accuracy_list': accuracy_list
}
# 创建一个 DataFrame
df = pd.DataFrame(data)
#
# # 保存到 Excel 文件
file_path = 'D:\无线通信网络认知\论文1\大修意见\Reviewer2-2 采样率实验\\accuracy-fs snr '+str(snr)+'db data '+str(i)+'.xlsx'
df.to_excel(file_path, index=False)
测试结果: