智能汽车「利好」数据服务,特斯拉/英伟达/大众都在布局
硬件预埋,正在推动智能驾驶行业进入数据驱动迭代周期。
今年,英伟达在Orin进入规模上量阶段的同时,推出了Drive Map,基于精确测绘数据与匿名众包数据相结合,提供厘米级的定位精度。后者,由搭载英伟达Hyperion架构的车辆提供数据众包,包括来自摄像头、激光雷达和毫米波雷达的数据。
所有这些数据,从车端不断上传到云端。然后,加载到英伟达的Omniverse平台,后者是一个为虚拟仿真和实时物理精确模拟而构建的开放平台,用于更新地图数据。同时,这些数据会转换成模拟测试环境,可用于Nvidia Drive Sim,一个端到端的自动驾驶车辆模拟平台。
而在Omniverse的背后,还有数据自动标签技术。
“Omniverse允许我们创建多样化、海量、精确的数据集,以构建高质量、高性能和安全的数据集,这对人工智能至关重要。”这其中,对于传统手工数据标注的增强,是关键要素之一。
2021年初,特斯拉披露正在位于纽约的Gigafactory招聘一组数据标签员,以提供图像标注支持,帮助训练Autopilot/FSD神经网络。原因是,对于自动驾驶演进来说,算法方面的差距会逐渐缩小,数据将是真正影响技术能力和用户体验的重要因素。
而按照此前公布的数据,特斯拉总共有近千人的数据标注团队规模。“数据需求缺口仍在,市场远未饱和。这对于真正优质的数据供应商来说,正是抢占市场高地的绝佳时机。”数据堂公司相关负责人表示。
一、
特斯拉AI主管Andrej Karpathy去年透露,公司只有“几十名”工程师在研究神经网络,但背后有一个“庞大”的团队在研究标签。一方面,手动高质量标准仍是基础工作,另一方面,标签自动化也是趋势,从而应对车队收集的大量数据。
对于人工标注岗位(大概每小时20美元的工资),特斯拉也多次明确其重要性:基于Autopilot标注界面来标记图像,对于训练深度神经网络至关重要。
比如,标注团队将与Autopilot团队的计算机视觉工程师互动,以帮助改进内部标注工具的设计;同时,标注团队将获得基本的计算机视觉和机器学习知识,以更好地理解算法如何使用标签,因为这将帮助在标记过程中出现的困难的「边缘情况」做出准确判断。
实际上,这个背后所传递的信息是:数据标注并非简单的「拉框」,也不是纯粹的逐条标注。“这种方式既费时又费钱。”一些行业人士指出,大部分传统外包商交付的结果数据经多次返修,依然无法达到客户要求的精确度。
2021年,数据堂的智能驾驶数据服务同比去年,业务涨幅达65%。这家连续数年在智能驾驶数据服务市场占有率领军的企业,也拿到了长城、上汽、小鹏、蔚来、宇通等国内一线车企的订单。
同时,考虑到数据合规的重要性,这家公司还在去年拿到了相关的测绘资质,意味着可以在真实的道路环境下合法采集数据,并合规地进行数据标注和处理,这也是其他数据服务商难以比拟的优势,也是拿到车企订单的准入门槛。
而这个赛道的下一波红利,来自标注工具的自动化。原因是,随着搭载具备数据采集、回传功能的新车规模逐步增长,对于庞大数据的处理成为了刚需。
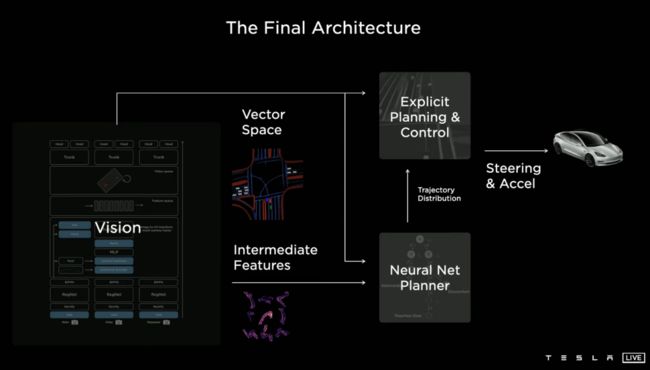
以特斯拉为例,为了配合后端Dojo超级计算机(6个训练模块组成一个2x3的矩阵,两个矩阵组成一个计算机机柜,每个机柜提供超过每秒100千兆的浮点运算)的需求,推出了自动标注工具。
当然,Andrej Karpathy也明确表示,手工标注在语义等方面非常擅长,但计算机在几何、重建、三角测量和跟踪方面更擅长。现在,需要人工和计算机合作来创建这些矢量空间数据集。
同样以视觉感知起家的Mobileye,庞大的实际道路行驶数据库是这家公司的顶梁柱。这家公司拥有近二十几年时间积累的1600万段1分钟的视频片段,接近200PB的数据存储量,也是亚马逊AWS全球存储容量最大的客户之一。
这背后,同样依靠大规模数据标记。公开数据显示,Mobileye背后有一支2500多人组成的数据标注团队,每月处理5000万个数据集——相当于500,000小时的驾驶里程,并建立了一个庞大的内部搜索引擎数据库。
这意味着,标注效率以及准确性,决定了视觉及多融合感知技术的迭代速度。“高质量数据,某种意义上就是决定性的要素。”在行业人士看来,一套高质高效的数据集,也是加快功能开发周期的关键。
为此,数据堂也推出了自研的数据标注工具,内置ML辅助预识别功能,真正实现半自动化作业,有效提升人均效率30%以上。近30套标注工具,可灵活应用于语音、图像、3D点云、文本等多类型数据的标注,已成功应用在11年近5000多个项目的实施过程中。
比如,漏标是很严重的标注错误。数据堂在工具中内置了地面检测算法、颜色自动渲染,标注时可以根据颜色来判断标注物体,以减少漏标。
此外,这套工具还内置插值算法预标注功能,如在第一、五帧标注了目标ID,则会自动标注中间帧位置,只需查看或微调位置即可(主要用于目标追踪项目)。
二、
事实上,从去年开始,基于影子模式、整车OTA等功能的数据驱动闭环模式已经成为智能驾驶方案供应商、一线品牌车企的新一轮技术竞赛焦点。
此外,下一代传感器也开始增加OTA功能,这意味着,基于数据驱动模式,可以实现传感器性能的优化并适配新的功能要求。
比如,NXP去年推出的首款专用16nm成像雷达处理器为例,S32R平台提供高性能的硬件安全引擎,支持OTA更新,符合新的网络安全标准。
同时,激光雷达的OTA也正在成为标准配置。比如,此前百度Apollo定制的禾赛科技全新架构激光雷达,将同步支持OTA以满足批量化智能管理及远程升级迭代需求。
“软件将是激光雷达的另一个‘大脑‘,除了基于采集数据的融合帮助系统做出正确的决策,还将会自动适应环境变化,并通过定期更新来提高性能。”科络达CEO吴柏仪表示,作为整车OTA解决方案提供商,公司已经率先实现了ADAS相关传感器的OTA升级。
高工智能汽车研究院监测数据显示,2021年中国市场(不含进出口)乘用车新车前装标配搭载OTA功能上险量为745.37万辆,其中,FOTA搭载量为382.93万辆,同比增长162.03%,前装搭载率为18.78%。
而对于智能驾驶方案供应商来说,数据采集、处理、训练并循环迭代功能被认为是实现软件定义汽车的关键。本周,博世旗下的ETAS宣布和PLC2 Design计划联合开发一个整体解决方案,在车载数据预处理和边缘计算领域协助客户实现数据验证。
在此之前,PLC2 Design已经与博世跨领域计算解决方案部门进行合作,提供类似的开放和模块化的解决方案,比如,基于FPGA用于边缘设备和云端数据中心的视频无损压缩和解压缩。
目前,ETAS已经参股PLC2 Design,并计划将双方的整体解决方案作为一个系统组件进行对外销售。而按照博世的规划,ETAS将强化汽车基础软件、中间件和开发工具的业务。
同时,博世也在为L4级自动驾驶物色「数据科学家」岗位,与软件敏捷开发团队中的深度学习工程师和数据工程师合作,从真实世界和模拟数据中提取自动驾驶所需的关键要素。
众所周知,早期的ADAS研发基本上是以基于规则的逻辑开发,这意味着开发人员决定对给定事件(输入)的反应(输出)。而基于神经网络训练的决策算法,则是根据可识别特征的权重来决定如何对事件作出反应。
“我们从大量车辆中获取大量数据并进行分析,以找出哪些功能运行良好,哪些不正常。我们越能分析车辆的行为,就越能更好地测试功能。”该公司负责人表示,这和传统开发方式相比,是一次革命。
而在前装量产赛道,市场已经启动。
“这将是一个循序渐进的过程,从良好天气条件、规则的道路,再到更复杂的环境和天气情况。这将是一个长期的竞争过程。”大众旗下软件子公司CARIAD在收购海拉图像处理公司的基础上,正在加快数据驱动的软件开发,并提高图像处理算法的自研比重。
此前,小鹏汽车多次强调,除了自有的数据采集车,大量用户车辆产生的数据,也可以在线检测长尾事件,并获取这些数据上传至云端,用于算法改进。
理想汽车也强调,数据是自动驾驶技术最大壁垒,公司计划通过搭载更加丰富的传感器组合,实现高质量数据采集,从而实现自动驾驶算法的更快收敛。
一周前,大众集团宣布为了加快E³2.0软件平台的开发进程,已经在德国及美国等国家部署数百辆定制化开发车队,配备高性能传感器和联网计算平台,并提供处理实时数据的能力,缩短开发时间。
按照计划,这家传统汽车巨头将从2024年开始,通过建立一个跨品牌车辆的神经网络,通过不断交换数据,创建一个拥有数百万辆汽车的自主学习系统。大众集团表示,这些车将是“时间机器”,同时与其他联网汽车共享道路、交通和其他系统的实时数据。
在这方面,除了特斯拉、Mobileye,几家中国本土供应商也已经率先起跑。
比如,智驾科技去年量产的MAXIPILOT®1.0,就是首度在1R1V硬件平台中部署OTA数据闭环,与客户协同建立数据全场景触发机制和平台,为自动驾驶技术迭代打下了多维基础。
同样已经进入前装量产赛道的知行科技,也拥有一套自建的数据闭环和云平台网络,基于原生云架构的设计方式,可以实现算法和功能的快速更新和迭代,通过大数据驱动提供真正安全可靠的智能驾驶功能。
而在大众集团看来,这套数据驱动开发模式,与技术本身无关,而是对传统汽车开发模式的一次颠覆性变革,比如,硬件和软件的开发分离,并最终实现端到端自主学习。
在高工智能汽车研究院看来,这是新一轮智能驾驶方案市场份额争夺战的制高点,同时也将为整车OTA(包括域控制、传感器等)、云服务、数据标注等产业链相关环节带来新一轮市场红利。