Structure-from-Motion Revisited(COLMAP) 流程介绍
Structure-from-Motion Revisited(COLMAP)流程介绍
- 主要贡献
-
- 1 场景图增强
- 2 下一最佳视图选择
- 3 稳健高效的三角化
- 4 BA
- 5 冗余视图挖掘
- 运行流程
-
- 1. GUI 运行
Reference:
- Structure-from-Motion Revisited 原文
- COLMAP 使用教程
- Colmap论文——《Structure-from-Motion Revisited》论文阅读笔记
- 笔记:三维重建系列 COLMAP: Structure-from-Motion Revisited
相关文章:
- NeRF 其一:NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
- NeRF 其二:Mip-NeRF
- NeRF 其三:Instant-NGP
- 3DGS 其一:3D Gaussian Splatting for Real-Time Radiance Field Rendering
原理挺简单的,但是这文章有点难啃,好多东西该讲没讲,该描述没描述。
COLMAP 的整体流程非常王道,在此不做赘述。

主要贡献
1 场景图增强
在前面的步骤中,得到了匹配图像对 C \mathcal{C} C,这些图像对又被称为场景图(scene graph)。为了提高 初始化 和 三角测量 模块的鲁棒性,故在此提出了一个多模型几何验证策略。
步骤如下:
- 估计一基础矩阵 F F F,如果内点个数大于等于 N F N_F NF,也就说明图像的匹配关系是没有问题的,这时图像就通过来几何验证;
- 若相机标定了,可以估计一个基础矩阵并得到它的内点个数 N E N_E NE,如果 N E / N F > ϵ E F N_E/N_F > \epsilon_{EF} NE/NF>ϵEF,算法内就认为标定参数是没有问题的;
- 使用该图像对计算单应矩阵的内点个数 N H N_H NH,如果满足条件 N H / N F < ϵ H F N_H/N_F < \epsilon_{HF} NH/NF<ϵHF,就认为相机是在一个常规
general场景下移动的(而不是纯旋转 or 平面场景); - 在同时满足 2.3. 步骤时,分解本质矩阵 E E E,根据内点的对应关系三角化,并得到一个中值三角化的角度 α m \alpha_m αm。使用 α m \alpha_m αm,可以用来区分纯旋转(全景
panoramic)和平面场景planar(问题是,这里写的第三步不就是用来干这个的?二次筛选?); - 有些网络图像存在:水印、时间戳、或第几帧的显示,这里将这些归类为(WTFs-watermarks, timestamps, and frames,这里感觉笔者故意凑这几个在玩梗,想写的是 What the Fuck),这些会导致误匹配。针对这种问题,通过估计图像间的相似变换并计算图像边缘的内点数 N S N_S NS,如果某对图像的 N S / N F > ϵ S F N_S/N_F > \epsilon_{SF} NS/NF>ϵSF 或者 N S / N E > ϵ S E N_S/N_E > \epsilon_{SE} NS/NE>ϵSE,即边缘匹配点的占比实在过大,则认为这是一对 WTF 图像,不加入到场景图中;
- 在筛选后,使用
general, panoramic, planar标记场景图的模型类别,并使用 N H N_H NH、 N E N_E NE、 N F N_F NF 中最大的那个作为模型内点; - 初始化重建倾向于选择非全景的、标定完美的图像对(考虑多视角多相机?)。不使用全景图像点对是为了避免退化点来增加三角化及后续图像配准的鲁棒性。
2 下一最佳视图选择
一个错误的视图选取可能会导致一连串的相机误匹配和错误的三角测量;而且,对下一最佳视图选择会极大地影响姿势估计的质量以及三角测量的完整性和准确性。因此,准确的姿态估计对于稳健的 SfM 至关重要,因为如果姿态不准确,点的三角测量可能会失败。
一种流行的方法是,找到一张能观察到最多已经三角化过的点的图像。但有实验表面,使用 PnP 的相机姿势的准确性取决于 观测点的数量 及 其在图像中的分布。因此,作者提出一种使用多尺度格网来度量匹配点分布状况的方法:
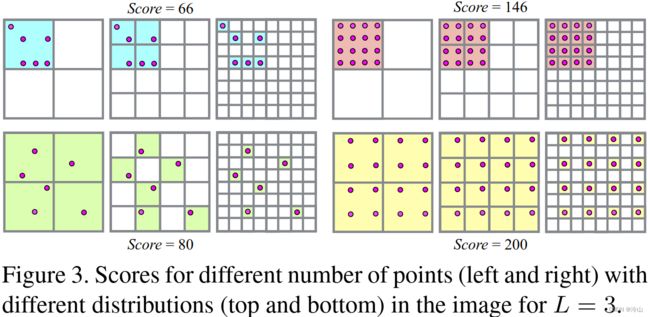
如上图所示,作者将图像划分成不同尺度格网,然后对不同尺度的格网点分布状况进行打分,这样可以同时考虑到点的数量与分布的影响。总的来说,点的数量越多,分布越均匀,则该图像的得分越高。上图中纵向是点分布的差异与得分差异的对比,横向是点数量与得分的对比。分数的计算方式如下所示:
S c o r e 左上 = 1 × 2 + 4 × 4 + 6 × 8 = 66 S c o r e 右上 = 1 × 2 + 4 × 4 + 16 × 8 = 146 S c o r e 左下 = 4 × 2 + 6 × 4 + 6 × 8 = 80 S c o r e 右下 = 4 × 2 + 16 × 4 + 16 × 8 = 200 \begin{aligned} Score_{\text{左上}} &= 1\times2+4\times4+6\times8=66\\ Score_{\text{右上}} &= 1\times2+4\times4+16\times8=146\\ Score_{\text{左下}} &= 4\times2+6\times4+6\times8=80\\ Score_{\text{右下}} &= 4\times2+16\times4+16\times8=200\\ \end{aligned} Score左上Score右上Score左下Score右下=1×2+4×4+6×8=66=1×2+4×4+16×8=146=4×2+6×4+6×8=80=4×2+16×4+16×8=200可见在同样点数量下,点分布越均匀得分越高。对不同匹配图像进行打分后,选择得分最高的图像作为下一最佳匹配图像。实验表明,使用该策略可以提升重建的鲁棒性和精度。
3 稳健高效的三角化
为了处理任意级别的异常值污染,作者使用 RANSAC 提出了一种高效的、基于采样和多视图的三角化方法。
考虑特征轨迹 T = { T n ∣ n = 1 ⋯ N T } \mathcal{T}=\{T_n | n=1 \cdots N_T\} T={Tn∣n=1⋯NT} 为一组具有未知先验内点比率 ϵ \epsilon ϵ 的测量值。测量 T n T_n Tn 由归一化图像观测 x ˉ n ∈ R 2 \bar{\mathbf{x}}_n\in \mathbb{R}^2 xˉn∈R2 和 对应的相机位姿 P n ∈ S E ( 3 ) \mathbf{P}_n\in \mathbf{SE}(3) Pn∈SE(3) 组成,其定义了从世界到相机坐标系的映射。目标是最大限度地支持符合条件良好的双视图三角测量的测量:
X a b ∼ τ ( x ˉ a , x ˉ b , P a , P b ) with a ≠ b , \mathbf{X}_{ab}\sim\tau\left(\bar{\mathbf{x}}_a,\bar{\mathbf{x}}_b,\mathbf{P}_a,\mathbf{P}_b\right){ } \text{ with } a\neq b, Xab∼τ(xˉa,xˉb,Pa,Pb) with a=b,其中 τ \tau τ 指代任意一种三角化的方式,COLMAP 里用的是 DLT(Direct Linear Transform,直接线性变换); X a b \mathbf{X}_{ab} Xab 是被三角化的点。在上一节讲过,COLMAP 不会从全景图像进行三角测量,以避免由于不准确的姿态估计而导致错误的三角测量角度。
条件良好的模型满足两个约束:
-
一个足够大的三角化角度 α \alpha α:
cos α = t a − X a b ∥ t a − X a b ∥ 2 ⋅ t b − X a b ∥ t b − X a b ∥ 2 . \cos\alpha=\frac{\mathbf{t}_a-\mathbf{X}_{ab}}{\left\|\mathbf{t}_a-\mathbf{X}_{ab}\right\|_2}\cdot\frac{\mathbf{t}_b-\mathbf{X}_{ab}}{\left\|\mathbf{t}_b-\mathbf{X}_{ab}\right\|_2}. cosα=∥ta−Xab∥2ta−Xab⋅∥tb−Xab∥2tb−Xab. -
三角化生成的三维点投影回图像上的深度值应该为正:
d = [ p 31 p 32 p 33 p 34 ] [ X a b T 1 ] T d=\begin{bmatrix}p_{31}&p_{32}&p_{33}&p_{34}\end{bmatrix}\begin{bmatrix}\mathbf{X}_{ab}^T&1\end{bmatrix}^T d=[p31p32p33p34][XabT1]T其中 p m m p_{mm} pmm 代表 P \mathbf{P} P 的第 m m m 行第 n n n 列元素。如果测量 T n T_n Tn 有正深度 d n d_n dn 且其重投影误差:
e n = ∥ x ˉ n − [ x ′ / z ′ y ′ / z ′ ] ∥ 2 with [ x ′ y ′ z ′ ] = P n [ X a b 1 ] \left.e_n=\left\|\bar{\mathbf{x}}_n-\begin{bmatrix}x'/z'\\y'/z'\end{bmatrix}\right.\right\|_2\text{with}\begin{bmatrix}x'\\y'\\z'\end{bmatrix}=\mathbf{P}_n\begin{bmatrix}\mathbf{X}_{ab}\\1\end{bmatrix} en= xˉn−[x′/z′y′/z′] 2with x′y′z′ =Pn[Xab1]小于某个阈值 t t t。
值得注意的是,三角化的过程中使用了RANSAC,即从上述特征追踪中随机选择至少两个点进行三角化,统计内点数(即,重投影误差小于阈值记为内点),选择内点数最多的那个作为三角化点。这个过程中存在一个问题就是,假如该点被追踪到了比较少的次数,此时随机采样会重复选择相同的一对点进行三角化,这样会造成不必要的资源消耗。为了不重复采点,本文使用了可产生不重复随机组的 random sampler 的方式;另外,为了能够保证以置信度为 η \eta η 的概率至少选择一对无外点的最小解集,该过程至少重复进行 K K K 次。(这里可以参考其他文献:假设内点所占总数据比率为 ϵ \epsilon ϵ,至少迭代多少次得到最佳:RANSAC基本原理)还好这一块还有点印象,论文内这一块没讲清楚,也没见其他人提到的,离谱。
4 BA
为了减少累积误差,在图像配准和三角化后执行 BA。通常不需要在每个步骤之后执行全局 BA,因为增量 SfM 只会影响局部模型。因此,COLMAP 在每次图像配准后对连接最多的图像集执行局部 BA,仅在模型增长一定百分比后才执行全局 BA,以分摊时间消耗。
- 参数化:
- 在局部 BA 中,损失函数 ρ j \rho_j ρj 使用 Cauchy 函数以对抗外点带来的影响;
- 几百个相机的情况下,使用稀疏直接求解器,而当相机数较多的时候,使用 PCG 求解器;
- 过滤:
- BA 后,一些观察结果与模型不符。因此,要过滤具有较大重投影误差的观测结果;
- 对于每个点,通过检查所有匹配的视角光线的最小三角化角度来判断这个几何关系是否比较好;
- 全局 BA 后,还会检查退化相机,比如:由全景图或人工增强的图像引起的。通常此类相机的所有观测均为异常值,或者内参会收敛到一个虚假的最小值。因此,COLMAP 不将焦距和畸变参数限制在先验的固定范围内,而是让它们在 BA 中自由优化。由于主点校准是一个病态问题,COLMAP 将其固定在未校准相机相机的图像中级。具有异常视野或大畸变系数幅度的相机被认为是错误估计,其在全局 BA 后被过滤。
- 重新三角测量:由于 BA 对位姿进行了优化,这使得之前由于不准确/错误位姿导致无法三角化的点有了能够被重新三角化的可能性,所以在 BA 之后执行一步重三角化(类比于BA之前的三角化)。局部 BA 的三角化点(pre-global BA RT)可能还是有一定的漂移,因此 COLMAP 不仅对局部 BA 再三角化,还对全局 BA 做再三角化(post-global BA RT)。这一步的目的是通过继续跟踪以前未能三角化的点(比如,由于不准确的位姿等)来提高重建的完整性。COLMAP 内不会增加三角化的阈值,而是继续跟踪误差低于过滤阈值的观察结果。
- 迭代优化:由于漂移或 pre-global BA RT,通常 BA 中观测到极大量的异常值并随后被过滤掉。由于 BA 严重受到异常值的影响,因此再进行一次全局 BA 可显著提升结果。因此,文中提出执行 BA-RT-过滤 的迭代优化步骤,直到滤掉的观测数和 post-global BA RT 的点数减少。在大多数情况下,在第二次迭代后,结果会显著改善并且优化会收敛。
5 冗余视图挖掘
BA 是 SfM 的主要性能瓶颈,文中利用增量 SfM 和密集照片集合的固有特性,通过将冗余相机聚类为高场景重叠组来更有效地参数化 BA。
COLMAP 将摄像机和点划分为通过分隔变量连接的子图,具体操作如下:
图像与地图点根据重建过程中是否受到最新帧点影响分为两类。对于比较大的重建问题,大部分场景不受影响,因为模型通常在局部扩展。也就是说,最新的重建帧仅会影响其邻近的图像以及地图点,很大一部分图像/地图点并不会发生改变。文内将不受影响的那部分场景划分为一个个高度重叠图像的组 G = { G r ∣ r = 1 … N G } \mathcal{G}=\left\{G_r \mid r=1 \ldots N_G\right\} G={Gr∣r=1…NG},并参数化每个组 G r G_r Gr 为单个相机(即,将每组相机使用一个(自由)相机来代替,这样可以减少 BA 优化过程中自由参数的数量,也就降低了计算量)。受最新扩展影响的图像被独立分组,以允许对其参数进行最佳改进。
那么问题来了,什么才叫做高重合度呢? 作者提到,一个组内相机的共视区域必须高度重合。令场景中共有 N X N_X NX 个点, 那么每一张图像都可表示成一个二值向量 v i ∈ { 0 , 1 } N X \mathbf{v}_i \in\{0,1\}^{N_X} vi∈{0,1}NX,其中当某个地图点被观测到时为 1,否则为 0;有了以上定义之后,我们可以定义图像 a a a 与图像 b b b 之间的重合度 V a b V_{a b} Vab 为:
V a b = ∥ v a ∧ v b ∥ / ∥ v a ∨ v b ∥ V_{a b}=\left\|\mathbf{v}_a \wedge \mathbf{v}_b\right\| /\left\|\mathbf{v}_a \vee \mathbf{v}_b\right\| Vab=∥va∧vb∥/∥va∨vb∥接着对待处理帧的 K r K_r Kr 个空间最近邻的那些图像计算重合度得分并排序,若共视程度大于阈值且组内图像数量小于阈值,则将该图像加入该组,这样可以构造一组高重合度的相机集合。对于这一个相机组的 BA(Group BA) 损失被构造为如下形式:
E g = ∑ j ρ j ( ∥ π g ( G r , P c , X k ) − x j ∥ 2 2 ) E_g=\sum_j \rho_j\left(\left\|\pi_g\left(\mathbf{G}_r, \mathbf{P}_c, \mathbf{X}_k\right)-\mathbf{x}_j\right\|_2^2\right) Eg=j∑ρj(∥πg(Gr,Pc,Xk)−xj∥22)
上式中 G r ∈ S E ( 3 ) \mathbf{G}_r \in \mathbf{S E}(3) Gr∈SE(3) 表示该组共用的外参, P c \mathbf{P}_c Pc 表示组内每张图像的位姿。在进行优化的时候,组内每张图像的位姿为 P c r = P c G r \mathbf{P}_{cr}=\mathbf{P}_c\mathbf{G}_r Pcr=PcGr,其中 P c \mathbf{P}_c Pc 在优化过程中固定不变, G r \mathbf{G}_r Gr 可变。全局的损失函数 E ˉ \bar{E} Eˉ 是所有分组代价 和 非分组代价之和。如此,BA 优化的时候,自由变量的数量就大大减少了,BA 优化的效率得到了大幅度提升。
运行流程
1. GUI 运行
编译流程参考 COLMAP Installation
- GUI 显示:
cd build
./src/colmap/exe/colmap gui