linux服务器开发学习笔记03
预处理 gcc -E hello.c -o helle.i
编译 gcc -S hello.i -o hello.s
汇编 gcc -c hello.s -o hello.o
链接 gcc hello.o -o hello
进程
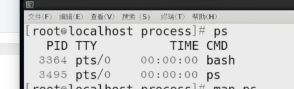
ps -u test u 命令可以帮助查看当前系统属于test用户的所有进程 最后的u表示用用户格式显示
- UNIX options
BSD options
-- GNU long options
ps 后面的选项以短破拆号-开头和没有它开头的含义是不同的。一般来说,有 - 开头的表示的是”UNIX options”,没有-开头的叫 “BSD options”,而以双破折号 - - 开头的叫 “GNU long options”。
图2-查看进程
图2中列出了当前用户test的进程。每一列的含义如下:
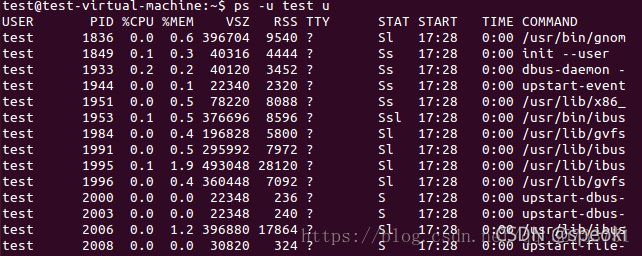
名称 含义
USER 进程的属主
PID 进程的 id 号
%CPU 进程占用的 CPU 百分比
%MEM 占用的内存百分比
VSZ 进程虚拟大小
RSS 驻留页的数量
TTY 终端 id 号
STAT 进程状态(D、R、S、T、W、X、Z、<、N、L、s 等)
START 进程开始运行时间
TIME 进程累积使用的CPU时间
COMMAND 使用的命令
以下是进程状态值的含义( 从这里也可以看出,进程它是有状态的):
名称 含义
D 不可中断睡眠
R 运行或就绪态
S 休眠状态
T 停止或被追踪
W 进入内存交换(从内核2.6开始无效)
X 死掉的进程
Z 僵尸进程
< 优先级高的进程
N 优先级较低的进程
L 有些页被锁进内存
s 进程的领导者(在它之下有子进程)
程序和进程之间的特点
它们的区别在于程序作为一个静态的二进制可执行文件永久存储在磁盘空间中,没有执行的意义。而进程是由操作系统创建,调度运行,分配系统资源,完成任务后销毁等等。整个过程进程是处于动态的,由操作系统维护管理。
程序是静态的文件,进程是处于动态运行的程序。
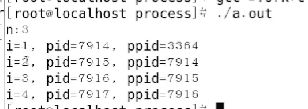
同一个程序运行不同的数据集就是不同的进程,进程间是独立的,数据集不相同。比如:同时开两个终端,各自都有一个bash进程,但彼此的bash进程pid不同。
fork创建进程
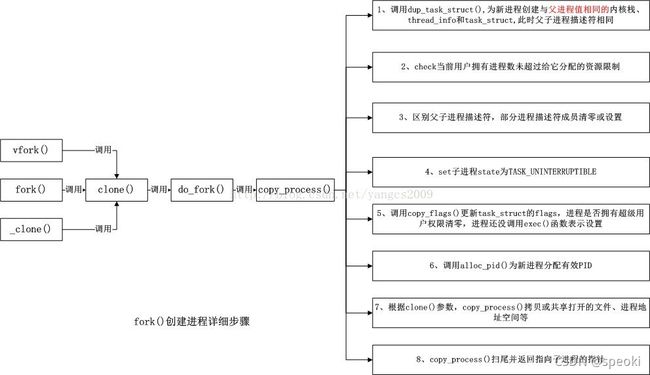
1.调用dup_task_struct()为新进程创建与父进程只相同的内核栈,thread_info和task_struct此时,父子进程描述符相同
2.check当前用户拥有进程数未超过给它分配的资源限制
3.区别父子进程描述符,部分进程描述符成员清零或设置
4.set子进程state为TASK_UNINTERRUPTIBLE
5.调用copy_flags()更新task_struct的flags进程是否拥有超级用户权限清零,进程还没调用exec()函数表示设置
6.调用alloc_pid()为新进程分配有效PID
7.根据clone()参数,copy_process()拷贝或共享打开的文件,进程地址空间等
8.copy_process()扫尾并返回指向子进程的指针
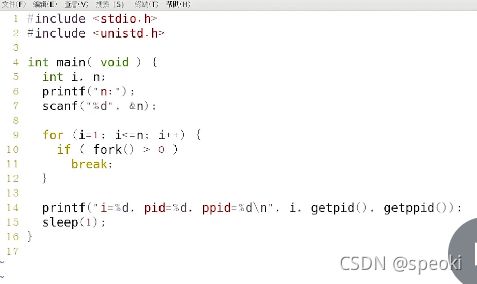
2.fork()系统调用函数用法
#includefork函数被调用一次,返回两次
返回值:子进程中返回0,父进程中返回子进程的ID,出错返回-1
而这个ID=0的进程不可能是其他的进程,因为进程ID=0总是由内核交换进程使用,返回值pid<0,即是pid=-1,fork函数创建进程失败。而pid大于即子进程的ID返回给父进程(每个进程都有一个非负整数表示的唯一进程ID)。所以通过这个子进程ID,父进程也可以确定自己独有的可执行代码(若有)。其他fork之后的代码父子进程都要执行,除非有进程退出,或者通过pid的选择语句。
当然,为了能深入了解fork函数的返回值,可以去看看读共享写复制机制,然后再回过头来看fork函数的返回值,你就非常清楚了。
子进程可以通过getppid函数获得自己父进程的ID,进程可以通过getpid函数获得自己的ID。
所以可以通过fork函数的返回值来进入父子进程独有的代码段(但是要借助ifelse(else if else )选择语句)。
注:父子进程共享代码段,但是分别拥有自己的数据段和堆栈段

fork函数创建进程
fork #include

getpid getppid
#include


得到子进程的Pid getpid() 得到子进程的父进程pid getppid()
确定返回来的是子进程(0)还是父进程(非零)
tail 查看文件尾部

head查看头部

注意一下aux和ef之间的区别
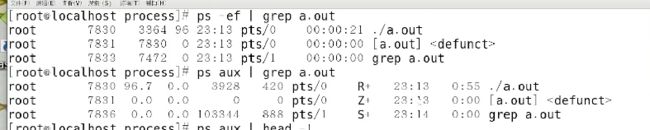


判断一下不要重复创建同一个进程
如果创建的是父进程就退出了
PCB进程控制块
PCB进程控制块是进程的静态描述,由PCB、有关程序段和该程序段对其进行操作的数据结构集三部分组成。 在Unix或类Unix系统中,进程是由进程控制块,进程执行的程序,进程执行时所用数据,进程运行使用的工作区组成。 其中进程控制块是最重要的一部分。



pcb进程块实际上是一个结构体
操作系统的第一个数据块描述
PCB中包含以下内容:
(1)进程标识符(内部,外部)
(2)处理机的信息(通用寄存器,指令计数器,PSW,用户的栈指针)。
(3)进程调度信息(进程状态,进程的优先级,进程调度所需的其它信息,事件)
(4)进程控制信息(程序的数据的地址,资源清单,进程同步和通信机制,链接指针
Linux的进程控制块为一个由结构task_struct所定义的数据结构,task_struct存在/include/ linux/sched.h 中,其中包括管理进程所需的各种信息。Linux系统的所有进程控制块组织成结构数组形式。早期的Linux版本是多可同时运行进程的个数由NR_TASK(缺省值为512)规定,NR_TASK即为PCB结果数组的长度。近期版本中的PCB组成一个环形结构,系统中实际存在的进程数由其定义的全局变量nr_task来动态记录。结构数组:struct task_struct *task[NR_TASK]={&init_task}来记录指向各PCB的指针,该指针数组定义于/kernel/sched.c中。
在创建一个新进程时,系统在内存中申请一个空的task_struct区,即空闲PCB块,并填入所需信息。同时将指向该结构的指针填入到task[]数组中。当前处于运行状态进程的PCB用指针数组current_set[]来指出。这是因为Linux支持多处理机系统,系统内可能存在多个同时运行的进程,故current_set定义成指针数组。
(1)unsigned short pid 为用户标识
(2)int pid 为进程标识
(3)int processor标识用户正在使用的CPU,以支持对称多处理机方式;
(4)volatile long state 标识进程的状态,可为下列六种状态之一:
可运行状态(TASK-RUNING);
可中断阻塞状态(TASK-UBERRUPTIBLE)
不可中断阻塞状态(TASK-UNINTERRUPTIBLE)
僵死状态(TASK-ZOMBLE)
暂停态(TASK_STOPPED)
交换态(TASK_SWAPPING)
(5)long prority表示进程的优先级
(6)unsigned long rt_prority 表示实时进程的优先级,对于普通进程无效
(7)long counter 为进程动态优先级计数器,用于进程轮转调度算法
(8)unsigned long policy 表示进程调度策略,其值为下列三种情况之一:
SCHED_OTHER(值为0)对应普通进程优先级轮转法(round robin)
SCHED_FIFO(值为1)对应实时进程先来先服务算法;
SCHED_RR(值为2)对应实时进程优先级轮转法
(9)struct task_struct *next_task,*prev_task为进程PCB双向链表的前后项指针
(10)struct task_struct *next_run,*prev_run为就绪队列双向链表的前后项指针
(11)struct task_struct *p_opptr,*p_pptr,*p_cptr,*p_ysptr,*p_ptr指明进程家族间的关系,分别为指向祖父进程、父进程、子进程以及新老进程的指针。

sched.h文件中
PCB:进程控制块,实际是一个结构体,放在sched.h文件中,Linux下可以通过whereis sched.h命令查看具体路径
该结构体主要包含:
1.进程id
用于区别进程
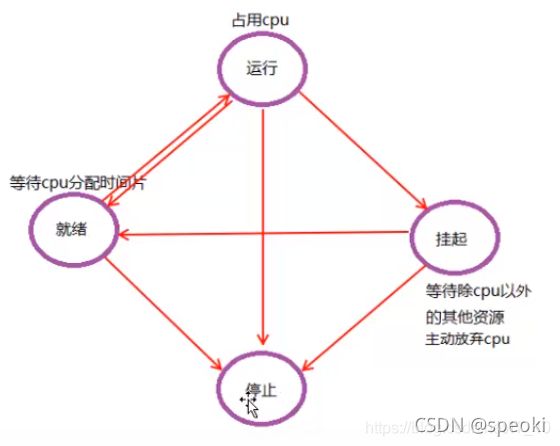
2.进程的状态:就绪、运行、挂起、停止
进程切换时需要保存和恢复的一些CPU寄存器
- 3描述虚拟地址空间的信息
- 4描述控制终端的信息
如xshell打开两个终端连接同一个linux主机,在两个终端中执行同一个程序,这个终端的信息都分别存在PCB中 - 5当前工作目录
如分别在/home和/etc目录下分别执行pwd命令,shell进程输出的结果是不一样的,这个工作目录就记录在PCB中 - 6umask掩码
8.文件描述符
9.和信号相关的信息
10.用户id和组id
11.会话和进程组
12.进程可以使用的资源上限
ulimit -a
Windows中的线程是系统处理机调度的基本单位. 线程可以执行进程中的任意代码, 包括正在被其他线程执行的代码. 进程中的所有线程共享进程的虚拟地址空间和系统资源. 每个线程拥有自己的例外处理过程, 一个调度优先级以及线程上下文数据结构. 线程上下文数据结构包含寄存器值, 核心堆栈, 用户堆栈和线程环境块.
Windows中的进程控制块是EPROCESS结构, 线程控制块是ETHREAD结构. EPROCESS/ETHREAD的定义在inside windows2000中有比较详细的描述。
Windows的进程链表是一个双向环链表。这个环链表LIST_ENTRY结构把每个EPROCESS链接起来. 那么只要找到一个EPROCESS结构, 我们就可以遍历整个链表, 这就是枚举进程的原理。
ps 命令
ps命令
查看正在运行的进程
ps aux查看系统中所有的进程
使用BS 操作系统格式
ps le 查看系统中所有的进程,使用Linux 标准命令格式
a:显示一个终端的所有进程,除会话引线外;
u:显示进程的归属用户及内存的使用情况;
x:显示没有控制终端的进程;
-l:长格式显示更加详细的信息;
-e:显示所有进程;
-r 只显示正在运行的程序
e 列出程序的时候显示出每个程序的环境变量
如果需要查找某一个特定的进程,可以把ps和grep一起用
ps -aux|grep Oracle,查找Oracle的进程
“ps aux” 可以查看系统中所有的进程;
“ps -le” 可以查看系统中所有的进程,而且还能看到进程的父进程的 PID 和进程优先级;
“ps -l” 只能看到当前 Shell 产生的进程;
ps -ef
当前所有的进程。包括显示创建进程的用户标识uid, 进程标识pid, 父进程标识ppid, 创建时间,所执行程序,可以用ps -ef
ps lax
ps lax可以提供进程ID,父进程PPID,谦让度和等待的资源
NI:谦让度
WCHAN:正在等待的进程资源
关于 ps -ef|grep php|grep -v grep|wc -l
这条命令我们解释下
grep -v grep 代表在查询的最终结果中去掉grep命令本身
wc -l 标示统计查询到的结果数量
很简单 ,为了去除包含grep的进程行 ,避免影响最终数据的正确性 。

linux下获取占用CPU资源最多的10个进程,可以使用如下命令组合:
ps aux|head -1;ps aux|grep -v PID|sort -rn -k +3|head
linux下获取占用内存资源最多的10个进程,可以使用如下命令组合:
ps aux|head -1;ps aux|grep -v PID|sort -rn -k +4|head
命令组合解析(针对CPU的,MEN也同样道理):
ps aux|head -1;ps aux|grep -v PID|sort -rn -k +3|head
该命令组合实际上是下面两句命令:
ps aux|head -1
ps aux|grep -v PID|sort -rn -k +3|head
head -K(K指代行数,即输出前几位的结果)
|为管道符号,将查询出的结果导到下面的命令中进行下一步的操作
接下来的grep -v PID是将ps aux命令得到的标题去掉,即grep不包含PID这三个字母组合的行,再将其中结果使用sort排序。
sort -rn -k +3该命令中的-rn的r表示是结果倒序排列,n为以数值大小排序,而-k +3则是针对第3列的内容进行排序,再使用head命令获取默认前10行数据。(其中的|表示管道操作)
ps -ef只打印进程,而ps -eLf会打印所有的线程
进程转换和进程id
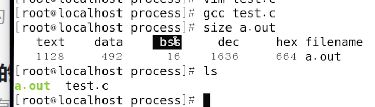
size a.out



ps -ef | head
pstree
pstree 进程和作业管理
选项
-a:显示每个程序的完整指令,包含路径,参数或是常驻服务的标示;
-c:不使用精简标示法;
-G:使用VT100终端机的列绘图字符;
-h:列出树状图时,特别标明现在执行的程序;
-H<程序识别码>:此参数的效果和指定"-h"参数类似,但特别标明指定的程序;
-l:采用长列格式显示树状图;
-n:用程序识别码排序。预设是以程序名称来排序;
-p:显示程序识别码;
-u:显示用户名称;
-U:使用UTF-8列绘图字符;
-V:显示版本信息。
实例
进程的创建和销毁
在不开启小内核的情况下,32为系统最大的pid个数是32768,实际的pid个数会根据cpu个数来调节,如果cpu个数小于32个,则实际的pid个数为32768,如果超过32个,则实际的pid个数为1024*cpus。
cat /proc/sys/kernel/pid_max
pid_max的来源,唯一可以调节pid_max的途径就是改变cpus
# 关于CONFIG_BASE_SMALL
如果关闭这个选项,则会减少一部分内核数据结构。但是会减少性能。
缺省情况下,内核将进程ID的最大值限制为32768,2^15。系统管理员可以设置/proc/sys/kernel/pid_max的值来突破这个缺省的限制,但会牺牲一些兼容性。
在Unix中,载入内存并执行程序映像的操作与创建一个新进程的操作是分离的。Unix有一个系统调用(实际上是一系列系统调用之一)是可以将二进制文件的程序映像载入内存,替换原先进程的地址空间,并开始运行它。这个过程称为运行一个新的程序,而相应的系统调用称为exec系统调用。同时,另一个不同的系统调用是创建一个新的进程,它基本上就是复制父进程。通常情况下新的进程会立刻执行一个新的程序。完成创建新进程的这种行为叫做派生(fork),完成这个功能的系统调用就是fork()。
用户和组
用户和组:Linux中通过用户和组进行认证,每个用户和唯一的正整数关联,称为用户ID(uid)。每一个进程与一系列用户ID关联:
真实uid(real uid):每一个进程与一个用户ID关联,用来识别运行这个进程的用户。用于辨识进程的真正所有者,且会影响到进程发送信号的权限。没有超级用户权限的进程仅在其RUID与目标进程的RUID相匹配时才能向目标进程发送信号,例如在父子进程间,子进程从父进程处继承了认证信息,使得父子进程间可以互相发送信号。
有效UID(effective uid):在创建与访问文件的时候发挥作用。具体来说,创建文件时,系统内核将根据创建文件的进程的EUID与EGID设定文件的所有者/组属性,而在访问文件时,内核亦根据访问进程的EUID与EGID决定其能否访问文件。
保留uid(saved uid):于以提升权限运行的进程暂时需要做一些不需特权的操作时使用,这种情况下进程会暂时将自己的有效用户ID从特权用户(常为root) 对应的UID变为某个非特权用户对应的UID,而后将原有的特权用户UID复制为SUID暂存;之后当进程完成不需特权的操作后,进程使用SUID的值重 置EUID以重新获得特权。在这里需要说明的是,无特权进程的EUID值只能设为与RUID、SUID与EUID(也即不改变)之一相同的值。
文件系统uid(filesystem uid):在Linux中使用,且只用于对文件系统的访问权限控制,在没有明确设定的情况下与EUID相同(若FSUID为root的UID,则SUID、RUID与EUID必至少有一亦为root的UID),且EUID改变也会影响到FSUID。设立FSUID是为了允许程序(如NFS服务器)在不需获取向给定UID账户发送信号的情况下以给定UID的权限来限定自己的文件系统权限。
会话和进程组
每个进程都属于某个进程组。进程组是由一个或多个相互间有关联的进程组成的,它的目的是为了进行作业控制。进程组的主要特征就是信号可以发送给进程组中的所有进程:这个信号可以使同一个进程组中的所有进程终止、停止或者继续运行。每个进程组都由进程组ID(pgid)唯一的标识,并且有一个组长进程。进程组ID就是组长进程的pid。只要在某个进程组中还有一个进程存在,则该进程组就存在。即使组长进程终止了,该进程组依然存在。
当有新的用户登陆计算机,登陆进程就会为这个用户创建一个新的会话。这个会话中只有用户的登陆shell—个进程。登陆shell做为会话首进程(session leader)。会话首进程的pid就被作为会话的ID。一个会话就是一个或多个进程组的集合。会话囊括了登陆用户的所有活动,并且分配给用户一个控制终端(controling terminal)。控制终端是一个用于处理用户I/O的tty设备。因此,会话的功能和shell差不多。没有谁刻意去区分它们。
会话中的进程组分为一个前台进程组和零个或多个后台进程组。当用户退出终端时,向前台进程组中的所有进程发送SIGQUIT信号。当出现网络中断的情况时,向前台进程组中的所有进程发送SIGHUP信号。当 用户敲入了终止键(一般是Ctrl+C) ,向前台进程组中的所有进程发送SIGINT信号。
相关系统调用:setsid,getsid,setpgid,getpgid。
特殊进程:
Init 进程
Idle进程
空闲进程,当没有其他进程在运行时,内核所运行的进程—它的pid是0。
init进程,在启动后,内核运行的第一个进程称为init进程,它的pid是1。除非用户显式地指定内核所要运行的程序(通过内核启动的init参数),否则内核依次寻找一个init程序,第一被发现的就会当做init运行。如果所有的都失败了,内核就会发出panic,挂起系统。在内核交出控制后,init会接着完成后续的启动过程。典型的情况是init会初始化系统,启动各种服务和启动登陆进程。
Orphan Process孤儿进程
Zombie Process僵尸进程
等待终止的子进程
用信号通知父进程是可以的,但是很多的父进程想知道关于子进程终止的更多信息——例如子进程的返回值。如果在终止过程中,子进程完全消失了,就没有给父进程留下任何可以来了解子进程的东西。Unix的设计者们做出了这样的决定:如果一个子进程在父进程之前结束,内核应该把子进程设置为一个特殊的状态。处于这种状态的进程叫做僵死(zombie)进程。进程只保留最小的概要信息一一些保存着有用信息的内核数据结构(进程号,退出状态,运行时间等)。僵死的进程等待这父进程来查询自己的信息(这叫做在僵死进程上等待)。只要父进程获取了子进程的信息,子进程就会消失,否则一直保持僵死状态。
为避免僵死进程,如进程可以显示等待子进程结束、处理或者忽略SIGCHLD信号。
守护线程

当进程是会话的领头进程时setsid()调用失败并返回(-1)。
setsid()调用成功后,返回新的会话的ID,调用setsid函数的进程成为新的会话的领头进程,并与其父进程的会话组和进程组脱离。
由于会话对控制终端的独占性,进程同时与控制终端脱离。
1 setid命令
setid主要是重新创建—个 session,子进程从父进程继承了 SessionID、进程组D和打开的终端,子进程
如果要脱离父进程,不受父进程控制,我们可以用这个 setid命令
2.
chdir() 改变当前工作目录函数
int chdir(const char *path );
说明:chdir函数用于改变当前工作目录。调用参数是指向目录的指针,调用进程需要有搜索整个目录的权限。每个进程都具有一个当前工作目录。在解析相对目录引用时,该目录是搜索路径的开始之处。如果调用进程更改了目录,则它只对该进程有效,而不能影响调用它的那个进程。在退出程序时,shell还会返回开始时的那个工作目录。
(1) 内核解析参数中的路径名,并确保这个路径名有效。为了做到这一点,就路径名解析而言,内核使用相同的算法。如果路径名无效,它输出错误消息并退出。
(2) 如果路径名有效,内核定位该目录的索引节点,并检查它的文件类型和权限位,确保目标文件是目录以及进程的所有者可以访问该目录(否则改变到新目录就没有用)。
(3) 内核用新目标目录的路径名和/或索引节点替换u区中当前目录路径名和/或它的索引节点号


chdir()

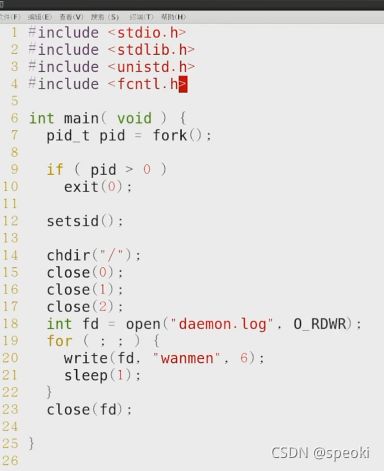
Daemon Process守护进程
守护进程运行在后台,不与任何控制终端相关联。守护进程通常在系统启动时就运行,它们以root用户运行或者其他特殊的用户(例如apache和postfix),并处理一些系统级的任务。习惯上守护进程的名字通常以d结尾(就像crond和sshd),但这不是必须的,甚至不是通用的。对于守护进程有两个基本要求:它必须是init进程的子进程,并且不与任何控制终端相关联。
一般来讲,进程可以通过以下步骤成为守护进程:
1,调用fork(),创建新的进程,它会是将来的守护进程。
2,在守护进程的父进程中调用exit()。这保证了守护进程的祖父进程确认父进程已经结束。还保证了父进程不再继续运行,守护进程不是组长进程。最后一点是顺利完成以下步骤的前提。
3,调用setsid(),使得守护进程有一个新的进程组和新的会话,两者都把它作为首进程。这也保证它不会与控制终端相关联(因为进程刚刚创建了新的会话,同时也就不会为其关联一个控制终端)。
4,用chdir()将当前工作目录改为根目录。因为前面调用fork()创建了新进程,它所继承来的当前工作目录可能在文件系统中任何地方。而守护进程通常在系统启动时运行,同时不希望一些随机目录保持打开状态,也就阻止了管理员卸载守护进程工作目录所在的那个文件系统。
5,关闭所有的文件描述符。不需要继承任何打开的文件描述符,对于无法确认的文件描述符,让它们继续处于打开状态。
6,打开0、1和2号文件描述符(标准输入、标准输出和标准错误),把它们重定向到/dev/null。
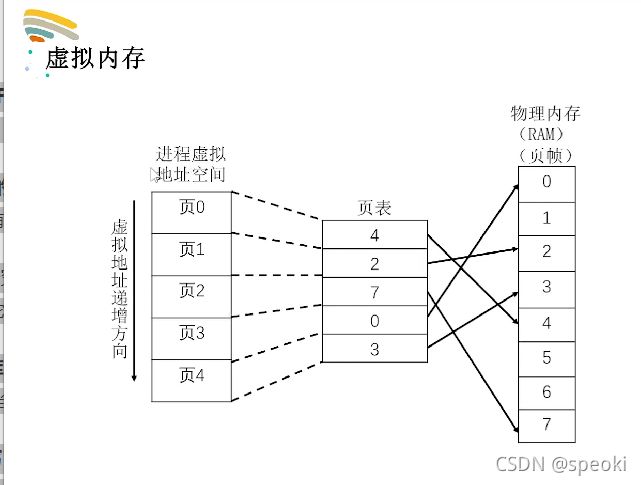
虚拟内存和命令行参数


![]()
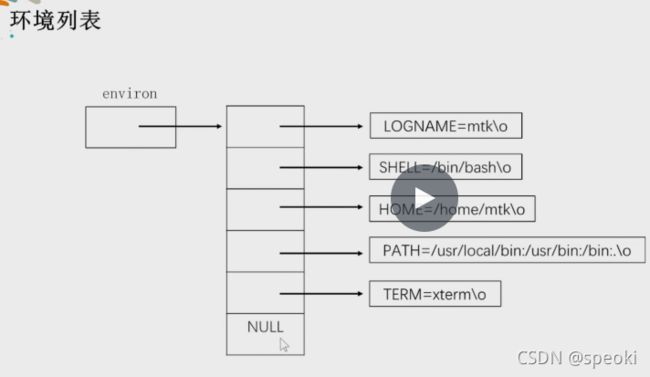
环境变量和列表
env | more

env | head -3
前3条
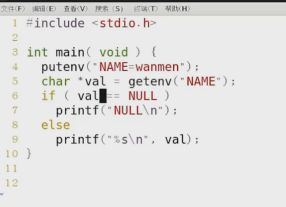
函数 putenv(char* string)
头文件#include

![]()
返回0正确返回1错误
Linux中echo $$命令的作用
echo $$ 返回登录shell的PID
echo $? 返回上一个命令的状态,0表示没有错误,其它任何值表明有错误
echo $# 返回传递到脚本的参数个数
echo $* 以一个单字符串显示所有向脚本传递的参数,与位置变量不同,此选项参数可超过9个
echo $! 返回后台运行的最后一个进程的进程ID号
echo $@ 返回传递到脚本的参数个数,但是使用时加引号,并在引号中返回每个参数
echo $- 显示shell使用的当前选项
echo $0 是脚本本身的名字
echo $_ 是保存之前执行的命令的最后一个参数
echo $1 传入脚本的第一个参数
echo $2 传入脚本的第二个参数
例题:
请在屏幕上面显示出您的环境发量 HOME 不 MAIL:
答:
echo $HOME 或者是 echo ${HOME}
echo $MAIL 或者是 echo ${MAIL}
不能够有空格








gcc编译为什么要加-g选项
加上-g 选项,会保留代码的文字信息,便于调试下面两幅图是有无 -g 选项调试的区别
gdb调试代码
l
r 运行
q 退出
b breakpoint
info b 断点的信息
s 继续
quit 退出
set follow-fork-mode child

父子进程间共享文件和写时拷贝
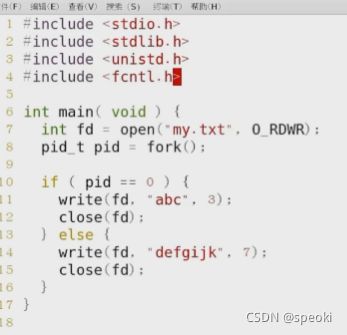
fork之后,父子进程间数据不共享,包括全局数据、栈区数据以及堆区数据
fork之后,父子进程间文件描述符和文件偏移量是共享的。
子进程可以使用fork之前open返回的文件描述符。因为调用fork之后,只拷贝了PCB本身,拷贝的只是指针,没有拷贝指针所指向的内容,这种情况叫做浅拷贝。子进程的指针依旧指向struct file,所以父子进程对于文件描述符和文件偏移量是共享的。




从fork函数开始以后的代码父子共享,即父进程要执行这段代码,子进程也要执行这段代码。(子进程获得父进程数据空间,堆和栈的副本。但是父子进程并不共享这些存储空间部分。父,子进程共享代码段。)
现在很多现实并不执行一个父进程数据段,栈和堆的完全复制。而是采用写时复制技术。这些区域有父子进程共享,而且内核将他们的访问权限改变为只读的。如果父子进程中的任一个试图修改这些区域,则内核只为修改区域的那块内存制作一个副本,通常是虚拟存储器系统中的一“页”。
一般来说,在fork之后的父进程先执行还是子进程先执行是不确定的。(取决于内核的调度算法)

为了深入了解进程间共享问题,我们先来了解下进程的地址空间的概念。所谓的地址空间说的是进程虚拟地址空间。就是每个进程都有自己的4GB虚拟地址空间。
通过程序运行时发现,父子进程打印的全局,静态,局部变量值不一样的,但是它们的地址是一样的。所以我们可以确定父进程在fork子进程时,子进程几乎把整个父进程复制了过去(包括0-4G虚拟地址空间)。
在修改数据时,虽然父子进程的数据的虚拟地址相同,但是虚拟地址实际映射到的物理地址却是不同的。
换句话说,虚拟地址在映射到物理内存的地址时,系统会在物理内存中找一块还没有用,空闲的物理内存,把这个虚拟地址映射到这块空闲的内存的物理地址。
读共享写复制
fork之后,父子进程在进行读写操作时各自的数据空间发生了以下变化:

父子进程数据空间分析:
从图5可以看出父子进程打印出来的数据时不同的,这意味着子进程的数据空间在进行写操作前并没有额外的开辟物理内存映射,而是和父进程共享的同一块物理内存(也间接说明了虚拟内存空间是共享的)。换句话说,当父子进程任何一个进程发生写操作的时候,都会先针对部分写操作的数据开辟新的物理内存,然后把复制的数据映射到物理内存当中。
虚拟地址到物理地址的映射过程:
实际上在系统中有一个MMU单元,主要负责虚拟地址到物理地址的映射(感兴趣的同学可以去看看操作系统哈)。
首先它会根据虚拟地址在物理内存中找一块还没有被使用,**空闲的内存块,**然后把虚拟地址映射到这块物理内存中。那么进程是怎么找到MMU的呢?答案是三级页表,那么这个页表的映射过程又得另说了,可以确定的是这个映射过程实际上是非常复杂的(这里只是方便理解,简化了一下,有兴趣的可以参考这位大佬的OS笔记:OS 学习笔记导航)。
我们可以得出一个结论,对于读操作,父子进程间是共享的;对于写操作,父子进程间是不共享的。这种机制就是写时复制机制(copy on write)。
fork函数实际只会以只读的形式让子进程B共享进程A的物理页面
同时父进程A也对这些页面设置为只读权限,也就是对此共享物理页面进行了写保护,这样一来,只有A,B任何一个进程对这些共享物理页面进行写操作时都会产生页面异常中断,此时CPU会对此异常进行处理,取消对共享物理页面的写操作,然后为执行写操作的进程复制一块新的物理页面,使A,B进程各自拥有一块相同的物理页面,这才真正的执行了复制操作(其实只复制了这一块物理页面),然后将这块复制的物理页面标记改为可写状态(原先是只读的),因此,在对进程间虚拟地址空间范围内执行写操作时,才会触发写时复制操作。
在复制之前,会申请一块物理页面来存放复制的物理页面,然后将此物理页面取消共享,并标记的读状态改为可写状态(因为共享属性和读写属性也复制了,所以必须把这些属性改掉),这块物理页面只属于当前执行写操作的进程,其他进程不能对此物理页面进行读写操作,同时在复制时也只会复制针对部分写操作的数据,而不是复制整个数据空间,因此其他部分还是共享的,这样做的目的是为了高效。(以上来自linux 0.11内核版本)
vfork的用法

相关函数:wait, execve
头文件:#include
定义函数:pid_t vfork(void);
函数说明:
vfork()会产生一个新的子进程, 其子进程会复制父进程的数据与堆栈空间, 并继承父进程的用户代码,组代码, 环境变量、已打开的文件代码、工作目录和资源限制等。
Linux 使用copy-on-write(COW)技术, 只有当其中一进程试图修改欲复制的空间时才会做真正的复制动作, 由于这些继承的信息是复制而来, 并非指相同的内存空间, 因此子进程对这些变量的修改和父进程并不会同步。
此外,子进程不会继承父进程的文件锁定和未处理的信号。
注意:Linux 不保证子进程会比父进程先执行或晚执行,因此编写程序时要留意死锁或竞争条件的发生。
返回值:如果 vfork()成功则在父进程会返回新建立的子进程代码(PID), 而在新建立的子进程中则返回0. 如果vfork 失败则直接返回-1, 失败原因存于errno 中.
错误代码:
1、EAGAIN:内存不足.
2、ENOMEM:内存不足, 无法配置核心所需的数据结构空间.
exit
_exit
at_exit
退出进程
vfork
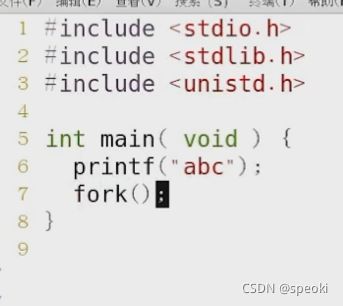
printf(“abc\n”)
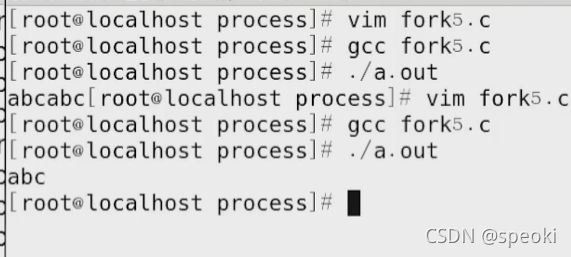
5.12进程终止


at_exit
atexit(3)
on_exit
_exit(3)
exit(3)
typedef struct node{
void (*pf)(void);
struct node* next
}node_t;


1.正常退出
a. 在main()函数中执行return 。
b.调用exit()函数
c.调用_exit()函数
2.异常退出
a.调用abort函数
b.进程收到某个信号,而该信号使程序终止。
但不管是哪种退出方式,系统最终都会执行内核中的某一代码。这段代码用来关闭进程所用已打开的文件描述符,释放它所占用的内存和其他资源。
1.exit和return 的区别:
exit是一个函数,有参数。exit执行完后把控制权交给系统
return是函数执行完后的返回。renturn执行完后把控制权交给调用函数。
- exit()和_exit()函数的区别
exit和_exit函数都是用来终止进程的。当程序执行到exit或_exit时,系统无条件的停止剩下所有操作,清除各种数据结构,并终止本进程的运行。
a. exit在头文件stdlib.h中声明,而_exit()声明在头文件unistd.h中声明。 exit中的参数exit_code为0代表进程正常终止,若为其他值表示程序执行过程中有错误发生。
b. _exit()执行后立即返回给内核,而exit()要先执行一些清除操作,然后将控制权交给内核。
c. 调用_exit函数时,其会关闭进程所有的文件描述符,清理内存以及其他一些内核清理函数,但不会刷新流(stdin, stdout, stderr …). exit函数是在_exit函数之上的一个封装,其会调用_exit,并在调用之前先刷新流。
d. exit()函数与_exit()函数最大区别就在于exit()函数在调用exit系统之前要检查文件的打开情况,把文件缓冲区的内容写回文件。由于Linux的标准函数库中,有一种被称作“缓冲I/O”的操作,其特征就是对应每一个打开的文件,在内存中都有一片缓冲区。每次读文件时,会连续的读出若干条记录,这样在下次读文件时就可以直接从内存的缓冲区读取;同样,每次写文件的时候也仅仅是写入内存的缓冲区,等满足了一定的条件(如达到了一定数量或遇到特定字符等),再将缓冲区中的内容一次性写入文件。这种技术大大增加了文件读写的速度,但也给编程代来了一点儿麻烦。比如有一些数据,认为已经写入了文件,实际上因为没有满足特定的条件,它们还只是保存在缓冲区内,这时用_exit()函数直接将进程关闭,缓冲区的数据就会丢失。因此,要想保证数据的完整性,就一定要使用exit()函数。
父子进程终止的先后顺序不同会产生不同的结果
1.父进程先于子进程终止:
此种情况就是我们前面所用的孤儿进程。当父进程先退出时,系统会让init进程接管子进程 。
2.子进程先于父进程终止,而父进程又没有调用wait函数
此种情况子进程进入僵死状态,并且会一直保持下去直到系统重启。子进程处于僵死状态时,内核只保存进程的一些必要信息以备父进程所需。此时子进程始终占有着资源,同时也减少了系统可以创建的最大进程数。
什么是 僵死状态呢?
一个已经终止、但是其父进程尚未对其进行善后处理(获取终止子进程的有关信息,释放它仍占有的资源)的进程被称为僵死进程(zombie)。
3.子进程先于父进程终止,而父进程调用了wait函数
此时父进程会等待子进程结束。
子进程的退出

wait()
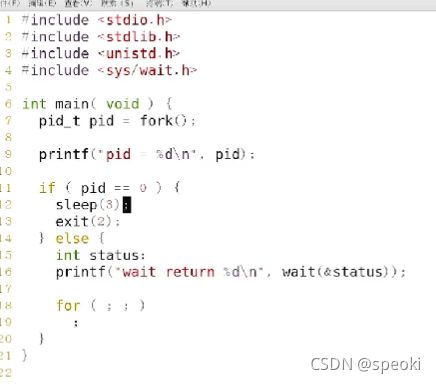


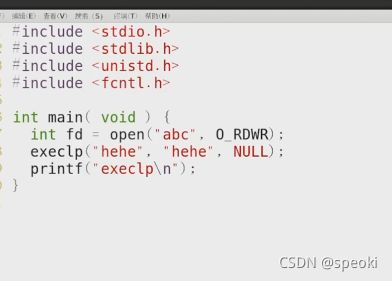
文件描述符和exec


execlp
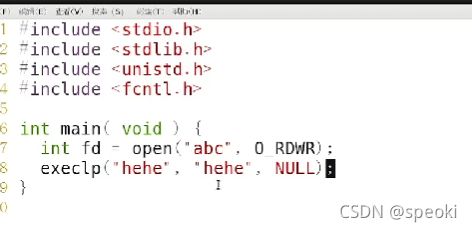
hehe.c








父子进程通信的两种方式 消息队列和共享内存
Linux消息队列是链式队列,链队上每个结点都是一个消息。一个进程可以将某一消息加入消息队列中,另一个进程可以从此消息队列中读取消息。
#include
#include
#include
#include
#include
#include
#define SIZE 1024
const long id = 1000;
/*
* a example to send and receive message
* */
int main() {
key_t unique_key;
int msgid;
int status;
char str[SIZE];
struct msgbuf {
long msgtype;
char msgtext[SIZE];
}sndmsg, rcvmsg;
/*
* get the identifier of a message queue
* if the new message queue is created then msgget return the id
* else return -1
* */
if((msgid = msgget(unique_key, IPC_PRIVATE | 0666)) == -1) {
fprintf(stderr, "msgget error!\n");
exit(1);
}
int pid = fork();
if(pid == 0) {
sndmsg.msgtype = id;
strcpy(str, "Hello World, I am wangzhicheng!\n");
sprintf(sndmsg.msgtext, str);
/*
* send message to message queue
* */
if(msgsnd(msgid, (struct msgbuf *)&sndmsg, sizeof(str) + 1, 0) == -1) {
fprintf(stderr, "msgsnd error! \n");
exit(2);
}
return 0;
}
else if(pid > 0) {
sleep(3);
if((status = msgrcv(msgid, (struct msgbuf *)&rcvmsg, sizeof(str) + 1, id, IPC_NOWAIT)) == -1) {
fprintf(stderr, "msgrcv error!\n");
exit(4);
}
printf("The received message is:%s\n", rcvmsg.msgtext);
msgctl(msgid, IPC_RMID, 0); // delete the message queue
return 0;
}
else {
fprintf(stderr, "fork error!\n");
msgctl(msgid, IPC_RMID, 0);
exit(5);
}
}
要点分析
1.msgget(long key, int msgflag)函数用于创建消息队列,key可由用户设定,msgflag指明了消息队列的操作权限和控制命令。0666表示此消息队列可读写,IPC_PRIVATE表示创建自己的消息队列。
2.当父进程fork出子进程后,子进程使用msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg)函数来将消息挂载到消息队列中,其中msgp指向消息缓存,msgfla表明进程在消息队列满或空应采取的行动,IPC_NOWAIT表示当消息队列为空时,函数返回错误信息。
3.当子进程执行完毕后,父进程使用msgrcv函数从消息队列中取出消息。之所以要让父进程休眠3秒,就是要等子进程把消息挂载到消息队列上。
4.消息队列可通过函数msgctl和关键字IPC_RM(remove)ID回收。
二、共享内存方式
共享内存是进程间通信最快的一种方式
#include 要点分析:
-
shmget用于获取共享内存,IPC_CREAT和0600指明了创建一个可读写的共享内存。
-
shmat用于将共享内存映射到进程内存空间,让进程可以像在自己的地址空间里访问共享内存。
-
子进程被创建后将字符串写入shmaddr所指向的共享内存中。
-
父进程同样使用shmat进行地址映射,然后从共享内存中读取数据。
-
shmdt表明进程断开与共享内存的地址映射。
-
shmctl和IPC_RMID用于共享内存的回收。