【JVM】优化参数+优化工具
【JVM】优化参数+优化工具
- (一)上线前评估的时候JVM设置合适的参数
-
-
- 【1】JVM参数
- 【2】典型JVM参数配置参考
- 【3】内存结构分析
-
- (二)什么时候需要JVM调优?具体的指标?
-
-
- 【1】如果使用合理的 JVM 参数配置,在大多数情况应该是不需要调优的
- 【2】何时进行JVM调优
- 【3】何时进行JVM调优详细描述
- 【4】JVM 有哪些核心指标?合理范围应该是多少?
- 【5】JVM调优的基本原则
- 【6】JVM调优目标
- 【7】JVM排查问题具体要看到指标数据
- 【8】JVM调优的步骤
-
- (三)怎么查看GC日志和堆内存快照?
-
-
- 【1】打印GC日志的参数
- 【2】准备触发Young GC的代码
-
- (1)代码实例
- (2)配置JVM参数
- (3)获得 gc.log 日志
- (4)JVM的Young GC日志应该怎么看
- 【3】准备触发对象进入老年代的代码
-
- (1)动态年龄判定规则
- (2)进入老年代的参数设计
- (3)代码实例01
- (4)GC日志怎么看
- (5)代码实例02
- (6)最终版的GC日志
- (7)代码实例03
- (8)GC日志03
- 【4】准备触发Full GC的代码
-
- (1)配置JVM参数
- (2)代码实例
- (3)GC日志
-
- (四)怎么查看Dump文件
-
- 【1】dump文件的作用
- 【2】获取dump文件
- (五)JVM调优工具的介绍、安装及使用
-
- 【1】VisualVM
-
- (1)打开监测工具并且安装插件
- (2)idea中安装visualvm插件,并且配置路径
- (3)重启idea,点击运行进入
- (4)页面介绍
-
- (1)Spaces
- (2)Graphs
- (3)GC优化的原则和目的
- (5)VisualVM分析优化案例
- 【2】国产idea插件VisualGC
-
- (1)在idea的插件市场下载
- (2)插件下载完成后重启idea就可以看到下方悬停的入口了
- 【3】Alibaba出品线上JVM监控诊断利器:Arthas插件
-
- (1)安装idea的Arthas插件
- (2)本地安装arthas
- (3)arthas的功能特点
- (4)使用案例
-
- (1)准备测试的案例代码(死锁、内存泄漏多种情况、死循环)
- (2)运行代码,启动arthas
- (3)排查定位CPU飙高问题(死循环)
- (4)排查定位死锁问题(死锁)
- (5)monitor - 方法执行监控
- (6)stack - 输出当前方法被调用的调用路径
- (7)trace - 方法内部调用路径,并输出方法路径上的每个节点上耗时
- (8)tt - 方法执行数据的时空隧道
- (9)watch - 方法执行数据观测
- (六)Arthas命令详细介绍
-
- 【1】核心监视功能
-
-
- (1)monitor:监控方法的执行情况
- (2)watch:检测函数返回值
- (3)trace:根据路径追踪,并记录消耗时间
- (4)stack:输出当前方法被调用的调用路径
- (5)tt:时间隧道,记录多个请求
- (6)项目中使用
-
- 【2】JVM相关命令
-
-
- (1)dashboard:实时数据面板
- (2)Thread:线程相关堆栈信息
- (3)jvm
- (4)sysprop:查看/修改属性
- (5)sysenv:查看JVM环境属性
- (6)vmpotion:查看JVM中选项
- (7)getstatic:获取静态成员变量
- (8)ognl:执行ognl表达式
-
- 【3】类和类加载器(class/classLoader)
-
-
- (1)sc:查看类信息
- (2)sm:查看已加载方法信息
- (3)编译与反编译jad、mc、redefine
- (4)dump:保存已加载字节码文件到本地
- (5)classloader:获取类加载器的信息
-
(一)上线前评估的时候JVM设置合适的参数
【1】JVM参数
-Xms设置堆的最小空间大小。
-Xmx设置堆的最大空间大小。
-Xmn:设置新生代大小
-XX:NewSize设置新生代最小空间大小。
-XX:MaxNewSize设置新生代最大空间大小。
-XX:PermSize设置永久代最小空间大小。
-XX:MaxPermSize设置永久代最大空间大小。
-Xss设置每个线程的堆栈大小
-XX:+UseParallelGC:选择垃圾收集器为并行收集器。此配置仅对年轻代有效。即上述配置下,年轻代使用并发收集,而年老代仍旧使用串行收集。
-XX:ParallelGCThreads=20:配置并行收集器的线程数,即:同时多少个线程一起进行垃圾回收。此值最好配置与处理器数目相等。
【2】典型JVM参数配置参考
java-Xmx3550m-Xms3550m-Xmn2g-Xss128k
-XX:ParallelGCThreads=20
-XX:+UseConcMarkSweepGC-XX:+UseParNewGC
(1)-Xmx3550m:设置JVM最大可用内存为3550M。
(2)-Xms3550m:设置JVM促使内存为3550m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
(3) -Xmn2g:设置年轻代大小为2G。整个堆大小=年轻代大小+年老代大小+持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,官方推荐配置为整个堆的3/8。
(4)-Xss128k:设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。更具应用的线程所需内存大 小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000 左右。
-XX:NewRatio=2,年轻代:老年代=1:2
-XX:SurvivorRatio=8,eden:survivor=8:1
堆内存设置为物理内存的3/4左右
【3】内存结构分析
堆内存里对象的一生
堆分为:新生代、老年代
新生代分为:Eden区、From Survivor区、To Survivor区
(1)躲过15次gc,达到15岁高龄之后进入老年代;
(2)动态年龄判定规则,如果Survivor区域内年龄1+年龄2+年龄3+年龄n的对象总和大于Survivor区的50%,此时年龄n以上的对象会进入老年代,不一定要达到15岁
(3)如果一次Young GC后存活对象太多无法放入Survivor区,此时直接计入老年代
(4)大对象直接进入老年代
(1)新对象优先在Eden区分配内存,如果Eden区放不下就直接进入老年代
1-新对象优先在Eden区分配内存,这个区最大,当Eden的空间满了,程序又需要创建对象,就会触发minor GC算法对新生代包括Eden区和Survivor区进行垃圾收集。
2-如果新对象在Eden中放不下,就直接进入老年代
3-使用-XX:PretenureSizeThreshold参数设置大对象的阈值,当大于这个值的时候就判定为大对象,直接进入老年代
(2)minor GC后的存活对象可能进入Survivor区,也可能直接进入老年代
1-如果Survivor区的大小能够盛下所有存活的对象,则Eden区清空,存活的对象放入From Survivor区,新对象继续在Eden区中分配内存,下次触发minor GC的时候,会对新生代包括Eden区和Survivor区进行垃圾收集。Eden区和From Survivor区清空,存活的对象放入To Survivor区,并且年龄+1。
2-如果Survivor区的大小不能够盛下所有存活的对象,则对象直接进入老年代
(3)伴随每次的Minor GC,新生代包括Eden区和Survivor区里存活的对象会在From Survivor区、To Survivor区两个区里来回复制,当对象的年龄达到15时,说明这个对象真的很难死亡,那么就可以把这个对象传入老年代。
(4)在老年代中如果内存也被放满了就会使用full GC进行整个新生代和老年代的垃圾收集

(二)什么时候需要JVM调优?具体的指标?
【1】如果使用合理的 JVM 参数配置,在大多数情况应该是不需要调优的
JVM 经过这么多年的发展和验证,整体是非常健壮的。99%的情况下,基本用不到 JVM 调优。JVM 参数的默认(推荐)值都是经过 JVM 团队的反复测试和前人的充分验证得出的比较合理的值,因此通常来说是比较靠谱和通用的,一般不会出大问题。
大部分情况都是代码 bug 导致 OOM、CPU load高、GC频繁啥的,这些场景也基本都是代码修复即可,通常不需要动 JVM。
【2】何时进行JVM调优
(1)Heap内存(老年代)持续上涨达到设置的最大内存值;
(2)Full GC 次数频繁;
(3)GC 停顿时间过长(超过1秒);
(4)应用出现OutOfMemory等内存异常;
(5)应用中有使用本地缓存且占用大量内存空间;
(6)系统吞吐量与响应性能不高或不降。
【3】何时进行JVM调优详细描述
【1】非计算密集型任务CPU占用过高
有用户线程cpu过高、gc线程cpu过高。用户线程cpu过高一般是出现了死循环,需要查看线程堆栈、结合arthas的watch命令等找出问题根源。gc线程过高一般是Full GC频繁,Full GC频繁一般是因为老年代或方法区(元空间)内存不足。需要对gc日志分析、对堆转储文件分析,确定是哪些对象实例占用了过多内存、反射的类是否过多、被多个类加载器加载的类是否过多等,决定是增加内存大小还是对源码进行处理等。
【2】老年代已使用空间大于70%
有可能发生了内存泄漏、有可能是设置的堆大小无法满足正常业务的需求。需要对堆转储文件分析,确定是哪些对象实例占用了过多内存,并检查是否发生了内存泄漏。对堆大小无法满足正常业务的需求,应调大堆大小,通过-Xms和-Xmx来设置。
【3】Full GC频繁
Full GC频繁一般是因为老年代或方法区(元空间)内存不足。需要对gc日志分析、对堆转储文件分析,确定是哪些对象实例占用了过多内存、反射的类是否过多、被多个类加载器加载的类是否过多等,决定是增加内存大小还是对源码进行处理等。
【4】单次GC时间大于1秒
(1)老年代内存过大。老年代中累积了大量对象时才触发full gc,这次gc的任务很重,耗费的时间很长。通过测试,选择一个合适的老年代大小。
(2)年轻代过小。年轻代过小,当年轻代空间不足时对象就会分配到老年代,而这些对象可能是“短命”的,但会停留在老年代很久。当full gc时,gc的任务会很重。因此,可以增大年轻代的大小。通过增大-XX:MaxTenuringThreshold=n来设置对象的晋升到老年代的年龄门槛,减缓对象进入老年代。
(3)创建对象的速度过快。对创建对象过快的代码进行优化,防止短时间内大量创建对象,以致年轻代空间不足而提前进入老年代。
(4)gc线程数过少。gc线程数过少,无法充分利用多核cpu的并行处理。gc日志中 user、sys、real时间需要关注。若real时间 与 (user时间/gc线程数+sys)相差不远,则gc线程数合适。
(5)进程被swap出内存。当物理内存不足时,系统会将一些内存存于磁盘的swap区,而swap区的访问速度慢很多。检查进程是否被放到swap区了,若是,应该增大物理内存,减少其他进程对内存的占用。
(6)合适的垃圾收集器。若非jvm专家,建议使用G1。通过-XX:MaxGCPauseMillis来设置最大停顿时间。
【5】出现OOM内存泄漏
老年代或方法区(元空间)内存不足。开启-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath= 。利用mat(memory analizer tool)对堆转储文件进行分析,确定是哪些对象实例占用了过多内存、反射的类是否过多、被多个类加载器加载的类是否过多等,决定是增加内存大小还是对源码进行处理等。
【6】程序的响应速度明显变慢
检查是否存在上面的四种情况或可能出现了死锁。
【4】JVM 有哪些核心指标?合理范围应该是多少?
(1)jvm.gc.time:每分钟的GC耗时在1s以内,500ms以内尤佳
(2)jvm.gc.meantime:每次YGC耗时在100ms以内,50ms以内尤佳
(3)jvm.fullgc.count:FGC最多几小时1次,1天不到1次尤佳
(4)jvm.fullgc.time:每次FGC耗时在1s以内,500ms以内尤佳
通常来说,只要这几个指标正常,其他的一般不会有问题,如果其他地方出了问题,一般都会影响到这几个指标。
调优的目标量化指数
(1)Heap 内存使用率 <= 70%;
(2)Old generation 内存使用率 <= 70%;
(3)avgpause <= 1秒;
(4)Full GC 次数 0 或 avg pause interval >= 24小时。
注意:不同应用的JVM调优量化目标是不一样的。
【5】JVM调优的基本原则
JVM调优是一个手段,但并不一定所有问题都可以通过JVM进行调优解决;因此,在进行JVM调优时,我们要遵循一些原则:
(1)大多数的Java应用不需要进行JVM优化;
(2)大多数导致GC问题的原因是代码层面的问题导致的(代码层面);
(3)上线之前,应先考虑将机器的JVM参数设置到最优;
(4)减少创建对象的数量(代码层面);
(5)减少使用全局变量和大对象(代码层面);
(6)优先架构调优和代码调优,JVM优化是不得已的手段(代码、架构层面);
(7)分析GC情况优化代码比优化JVM参数更好(代码层面)。
通过以上原则,我们发现,其实最有效的优化手段是架构和代码层面的优化,而JVM优化则是最后不得已的手段,也可以说是对服务器配置的最后一次“压榨”。
【6】JVM调优目标
调优的最终目的都是为了令应用程序使用最小的硬件消耗来承载更大的吞吐。JVM调优主要是针对垃圾收集器的收集性能优化,令运行在虚拟机上的应用能够使用更少的内存以及延迟获取更大的吞吐量,总结以下:
(1)延迟:GC低停顿和GC低频率;
(2)低内存占用;
(3)高吞吐量。
其中任何一个属性性能的提高,几乎都是以牺牲其他属性性能的损为代价的,不可兼得。具体根据在业务中的重要性确定。
【7】JVM排查问题具体要看到指标数据
(1)CPU指标
1、查看占用CPU最多的线程
2、查看线程堆栈快照信息
3、分析代码执行热点
4、查看哪个代码占用CPU执行时间最长
5、查看每个方法占用CPU时间比例
(2)JVM 内存指标
1、查看当前 JVM 堆内存参数配置是否合理
2、查看堆中对象的统计信息
3、查看堆存储快照,分析内存的占用情况
4、查看堆各区域的内存增长是否正常
5、查看是哪个区域导致的GC
6、查看GC后能否正常回收到内存
(3)JVM GC指标
1、查看每分钟GC时间是否正常
2、查看每分钟YGC次数是否正常
3、查看FGC次数是否正常
4、查看单次FGC时间是否正常
5、查看单次GC各阶段详细耗时,找到耗时严重的阶段
6、查看对象的动态晋升年龄是否正常
JVM 的 GC指标一般是从 GC 日志里面查看,默认的 GC 日志可能比较少,我们可以添加以下参数,来丰富我们的GC日志输出,方便我们定位问题。GC日志常用 JVM 参数:
// 打印GC的详细信息
-XX:+PrintGCDetails
// 打印GC的时间戳
-XX:+PrintGCDateStamps
// 在GC前后打印堆信息
-XX:+PrintHeapAtGC
// 打印Survivor区中各个年龄段的对象的分布信息
-XX:+PrintTenuringDistribution
// JVM启动时输出所有参数值,方便查看参数是否被覆盖
-XX:+PrintFlagsFinal
// 打印GC时应用程序的停止时间
-XX:+PrintGCApplicationStoppedTime
// 打印在GC期间处理引用对象的时间(仅在PrintGCDetails时启用)
-XX:+PrintReferenceGC
【8】JVM调优的步骤
(1)分析GC日志及dump文件,判断是否需要优化,确定瓶颈问题点;
1、代码bug:升级修复bug。典型的有:死循环、使用无界队列。
2、不合理的JVM参数配置:优化 JVM 参数配置。典型的有:年轻代内存配置过小、堆内存配置过小、元空间配置过小。
(2)确定JVM调优量化目标;
(3)确定JVM调优参数(根据历史JVM参数来调整);
(4)依次调优内存、延迟、吞吐量等指标;
(5)对比观察调优前后的差异;
(6)不断的分析和调整,直到找到合适的JVM参数配置;
(7)找到最合适的参数,将这些参数应用到所有服务器,并进行后续跟踪。
以上操作步骤中,某些步骤是需要多次不断迭代完成的。一般是从满足程序的内存使用需求开始的,之后是时间延迟的要求,最后才是吞吐量的要求,要基于这个步骤来不断优化,每一个步骤都是进行下一步的基础,不可逆行之。
(三)怎么查看GC日志和堆内存快照?
【1】打印GC日志的参数
要查看gc日志,那么首先得把gc日志进行输出,在JVM启动的时候添加参数:
-XX:+PrintGCDetails 打印GC日志细节
-XX:+PrintGCTimeStamps 打印GC日志时间
-Xloggc:gc.log 将GC日志输出到指定的磁盘文件上去,这里会把gc.log输出到项目根路径
然后JVM在运行过程中如果发生gc,那么将会把gc日志输出到gc.log中。
【2】准备触发Young GC的代码
(1)代码实例
public static void main(String[] args) {
// 一个数组占1M内存
byte[] array1 = new byte[1024 * 1024];
array1 = new byte[1024 * 1024];
array1 = new byte[1024 * 1024];
// 使array变量什么都不指向,前3个数组变成垃圾对象
array1 = null;
//前三个数组占3M内存,成为垃圾对象
//再创建一个2M的数组对象,Eden区内存不够会触发Young GC
byte[] array2 = new byte[2 * 1024 * 1024];
}
(1)byte[] array1 = new byte[1024 * 1024];
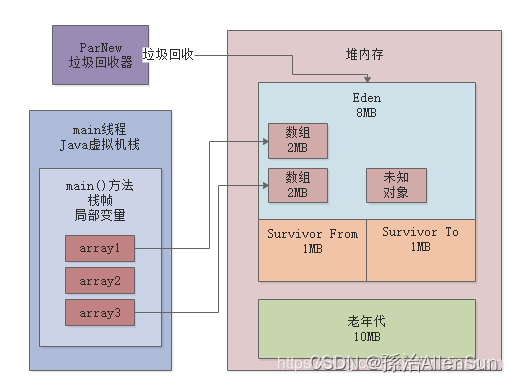
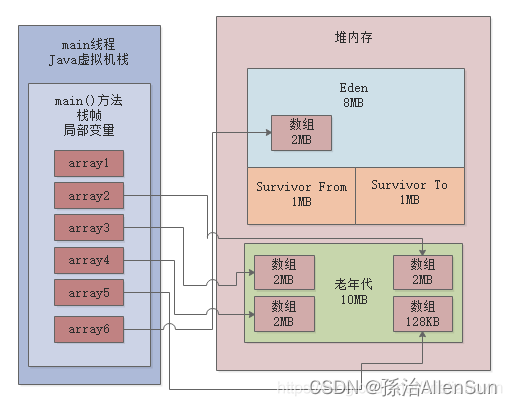
会在JVM的Eden区内放入一个1MB的对象,同时在main线程的虚拟机栈中会压入一个main()方法的栈帧,在main()方法的栈帧内部,会有一个“array1”变量,这个变量是指向堆内存Eden区的那个1MB的数组,如下图:

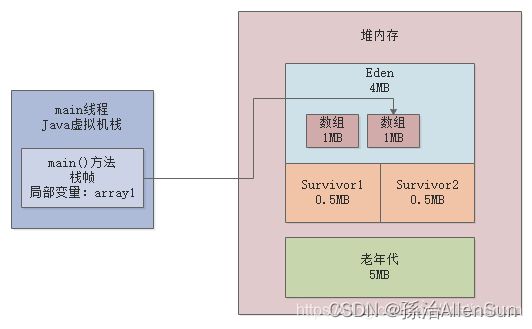
(2)array1 = new byte[1024 * 1024];
会在堆内存的Eden区中创建第二个数组,并且让局部变量指向第二个数组,然后第一个数组就没人引用了,此时第一个数组就成了没人引用的“垃圾对象”了,如下图所示:
(3)array1 = new byte[1024 * 1024];
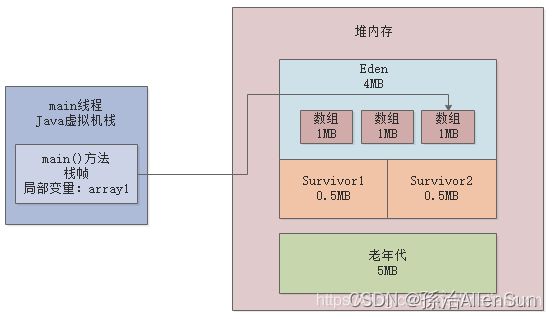
在堆内存的Eden区内创建了第三个数组,同时让array1变量指向了第三个数组,此时前面两个数组都没有人引用了,就都成了垃圾对象,如下图所示
(4)array1 = null;
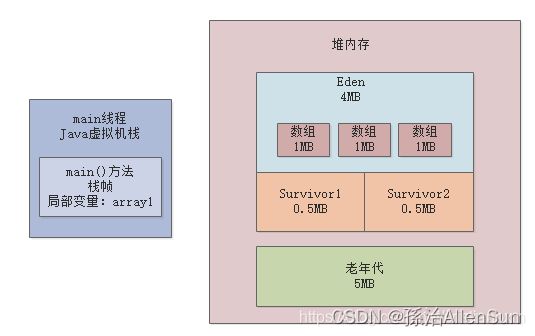
就让array1这个变量什么都不指向了,此时会导致之前创建的3个数组全部变成垃圾对象,如下图
(5)byte[] array2 = new byte[2 * 1024 * 1024];
此时会分配一个2MB大小的数组,尝试放入Eden区中,因为Eden区总共就4MB大小,而且里面已经放入了3个1MB的数组了,所以剩余空间只有1MB了,此时你放一个2MB的数组是放不下的。所以这个时候就会触发年轻代的Young GC。
(2)配置JVM参数
这里配置了新生代大小为5M,堆内存大小为10M,那么老年代大小就是5M。SurvivorRatio=8,那么Eden区就是Survivor区的8倍,所以Eden区占4M,两个Survivor都是占0.5M。MaxTenuringThreshold=15,那么新生代对象只有达到15岁才会进入老年代。PretenuringSizeThreshold等于10M,那么只有大于10M的对象才能直接在老年代分配。使用ParNew + CMS垃圾回收器。
-XX:NewSize=5242880
-XX:MaxNewSize=5242880
-XX:InitialHeapSize=10485760
-XX:MaxHeapSize=10485760
-XX:SurvivorRatio=8
-XX:MaxTenuringThreshold=15
-XX:PretenureSizeThreshold=10485760
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-Xloggc:gc.log
解析:
-XX:InitialHeapSize : 初始堆大小
-XX:MaxHeapSize : 最大堆大小
-XX:NewSize : 初始新生代大小
-XX:MaxNewSize : 最大新生代大小
-XX:PretenureSizeThreshold=10485760 : 指定了大对象阈值是10MB。
-XX:+PrintGCDetils:打印详细的gc日志
-XX:+PrintGCTimeStamps:这个参数可以打印出来每次GC发生的时间
-Xloggc:gc.log:这个参数可以设置将gc日志写入一个磁盘文件

(3)获得 gc.log 日志
在项目的根路径下,就可以看到一个gc.log,点进去查看

Java HotSpot(TM) 64-Bit Server VM (25.271-b09) for bsd-amd64 JRE (1.8.0_271-b09), built on Sep 16 2020 16:54:38 by "java_re" with gcc 4.2.1 Compatible Apple LLVM 10.0.0 (clang-1000.11.45.5)
Memory: 4k page, physical 16777216k(46244k free)
/proc/meminfo:
//这就是告诉你这次运行程序采取的JVM参数是什么,基本都是我们设置的,同时还有一些参数默认就给设置了,不过一般关系不大。
CommandLine flags: -XX:InitialHeapSize=10485760 -XX:MaxHeapSize=10485760 -XX:MaxNewSize=5242880 -XX:MaxTenuringThreshold=15 -XX:NewSize=5242880 -XX:OldPLABSize=16 -XX:PretenureSizeThreshold=10485760 -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:SurvivorRatio=8 -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseConcMarkSweepGC -XX:+UseParNewGC
//系统运行以后过了0.158秒发生了本次GC
//GC (Allocation Failure) :对象分配失败,此时就要触发一次Young GC
//ParNew: 3598K->412K(4608K), 0.0019136 secs
//ParNew: 触发的是年轻代的Young GC,所以是用我们指定的ParNew垃圾回收器执行的 GC
//(4608K): 年轻代可用空间是4608KB,也就是4.5MB。Eden区是4MB,两个Survivor中只有一个是可以放存活对象的,另外一个是必须一直保持空闲的,所以他考虑年轻代的可用空间,就是Eden+1个Survivor的大小,也就是4.5MB。
//3598K->412K:意思就是对年轻代执行了一次GC,GC之前都使用了3598KB了,但是GC之后只有412KB的对象是存活下来
//0.0019136 secs:这个就是本次gc耗费的时间,看这里来说大概耗费了1.9ms,仅仅是回收3MB的对象而已。
0.158: [GC (Allocation Failure) 0.158: [ParNew: 3598K->412K(4608K), 0.0019136 secs] 3598K->1438K(9728K), 0.0020875 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
//GC过后的堆内存使用情况
Heap
//这就是说“ParNew”垃圾回收器负责的年轻代总共有4608KB(4.5MB)可用内存,目前是使用了3645KB(3.6MB)
par new generation total 4608K, used 3645K [0x00000007bf600000, 0x00000007bfb00000, 0x00000007bfb00000)
eden space 4096K, 78% used [0x00000007bf600000, 0x00000007bf928630, 0x00000007bfa00000)
from space 512K, 80% used [0x00000007bfa80000, 0x00000007bfae7010, 0x00000007bfb00000)
to space 512K, 0% used [0x00000007bfa00000, 0x00000007bfa00000, 0x00000007bfa80000)
//就是说Concurrent Mark-Sweep垃圾回收器,也就是CMS垃圾回收器,管理的老年代内存空间一共是5MB,此时使用了1026KB的空间
concurrent mark-sweep generation total 5120K, used 1026K [0x00000007bfb00000, 0x00000007c0000000, 0x00000007c0000000)
//Metaspace元数据空间 和 Class空间,存放一些类信息、常量池之类的东西,此时他们的总容量,使用内存,等等。
Metaspace used 3030K, capacity 4496K, committed 4864K, reserved 1056768K
class space used 335K, capacity 388K, committed 512K, reserved 1048576K
(4)JVM的Young GC日志应该怎么看
(1)GC日志实例
Java HotSpot(TM) 64-Bit Server VM (25.151-b12) for windows-amd64 JRE (1.8.0_151-b12), built on Sep 5 2017 19:33:46 by "java_re" with MS VC++ 10.0 (VS2010)
Memory: 4k page, physical 33450456k(25709200k free), swap 38431192k(29814656k free)
CommandLine flags: -XX:InitialHeapSize=10485760 -XX:MaxHeapSize=10485760 -XX:MaxNewSize=5242880 -XX:NewSize=5242880 -XX:OldPLABSize=16 -XX:PretenureSizeThreshold=10485760 -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:SurvivorRatio=8 -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseConcMarkSweepGC -XX:-UseLargePagesIndividualAllocation -XX:+UseParNewGC
0.268: [GC (Allocation Failure) 0.269: [ParNew: 4030K->512K(4608K), 0.0015734 secs] 4030K->574K(9728K), 0.0017518 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
Heap
par new generation total 4608K, used 2601K [0x00000000ff600000, 0x00000000ffb00000, 0x00000000ffb00000)
eden space 4096K, 51% used [0x00000000ff600000, 0x00000000ff80a558, 0x00000000ffa00000)
from space 512K, 100% used [0x00000000ffa80000, 0x00000000ffb00000, 0x00000000ffb00000)
to space 512K, 0% used [0x00000000ffa00000, 0x00000000ffa00000, 0x00000000ffa80000)
concurrent mark-sweep generation total 5120K, used 62K [0x00000000ffb00000, 0x0000000100000000, 0x0000000100000000)
Metaspace used 2782K, capacity 4486K, committed 4864K, reserved 1056768K
class space used 300K, capacity 386K, committed 512K, reserved 1048576K
(2)第一段:程序运行采用的默认JVM参数
这就是告诉你这次运行程序采取的JVM参数是什么,基本都是我们设置的,同时还有一些参数默认就给设置了,不过一般关系不大。
CommandLine flags: -XX:InitialHeapSize=10485760 -XX:MaxHeapSize=10485760 -XX:MaxNewSize=5242880 .........
(3)第二段:一次GC的概要说明
0.268: [GC (Allocation Failure) 0.269: [ParNew: 4030K->512K(4608K), 0.0015734 secs] 4030K->574K(9728K), 0.0017518 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
解析:
0.268 :系统运行以后过了多少秒发生了本次GC
GC (Allocation Failure) :对象分配失败,此时就要触发一次Young GC
ParNew: 4030K->512K(4608K), 0.0015734 secs
ParNew: 触发的是年轻代的Young GC,所以是用我们指定的ParNew垃圾回收器执行的 GC
(4608K): 年轻代可用空间是4608KB,也就是4.5MB。Eden区是4MB,两个Survivor中只有一个是可以放存活对象的,另外一个是必须一直保持空闲的,所以他考虑年轻代的可用空间,就是Eden+1个Survivor的大小,也就是4.5MB。
4030K->512K: 意思就是对年轻代执行了一次GC,GC之前都使用了4030KB了,但是GC之后只有512KB的对象是存活下来
0.0015734 secs: 这个就是本次gc耗费的时间,看这里来说大概耗费了1.5ms,仅仅是回收3MB的对象而已。
看这行日志,ParNew: 4030K->512K(4608K), 0.0015734 secs
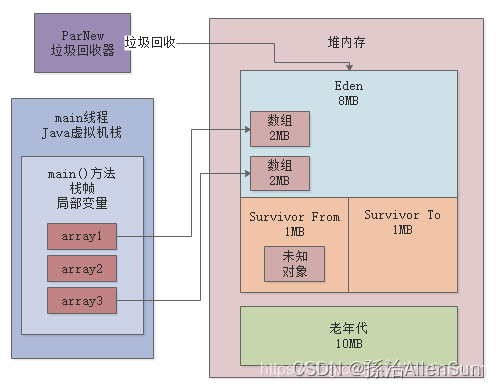
大家很奇怪,我们在GC之前,明明在Eden区里就放了3个1MB的数组,一共是3MB,也就是3072KB的对象,那么GC之前年轻代应该是使用了3072KB的内存啊,为啥是使用了4030KB的内存呢?其实你创建的数组本身虽然是1MB,但是为了存储这个数组,JVM内置还会附带一些其他信息,所以每个数组实际占用的内存是大于1MB的;除了你自己创建的对象以外,可能还有一些你看不见的对象在Eden区里,至于这些看不见的未知对象是什么,后面我们有专门的工具可以分析堆内存快照,以后会带你看到这些对象是什么。所以如下图所示,GC之前,三个数组和其他一些未知对象加起来,就是占据了4030KB的内存。

接着你想要在Eden分配一个2MB的数组,此时肯定触发了“Allocation Failure“,对象分配失败,就触发了Young GC,然后ParNew执行垃圾回收,回收掉之前我们创建的三个数组,此时因为他们都没人引用了,一定是垃圾对象,如下图所示:

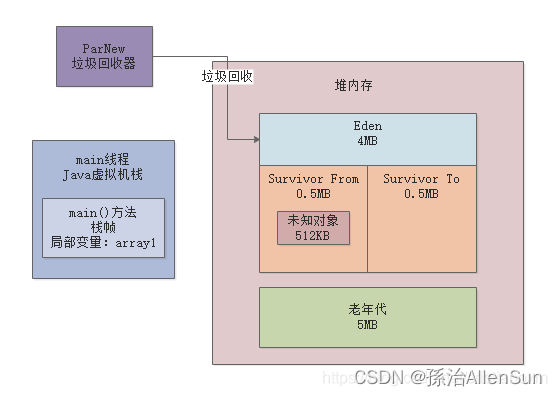
然后我们继续看gc日志,ParNew: 4030K->512K(4608K), 0.0015734 secs
gc回收之后,从4030KB内存使用降低到了512KB的内存使用,也就是说这次gc日志有512KB的对象存活了下来,从Eden区转移到了Survivor1区,其实我们可以把称呼改改,叫做Survivor From区,另外一个Survivor叫做Survivor To区,如下图:
(4)第三段:GC过后的堆内存使用情况
Heap
par new generation total 4608K, used 2601K [0x00000000ff600000, 0x00000000ffb00000, 0x00000000ffb00000)
eden space 4096K, 51% used [0x00000000ff600000, 0x00000000ff80a558, 0x00000000ffa00000)
from space 512K, 100% used [0x00000000ffa80000, 0x00000000ffb00000, 0x00000000ffb00000)
to space 512K, 0% used [0x00000000ffa00000, 0x00000000ffa00000, 0x00000000ffa80000)
concurrent mark-sweep generation total 5120K, used 62K [0x00000000ffb00000, 0x0000000100000000, 0x0000000100000000)
Metaspace used 2782K, capacity 4486K, committed 4864K, reserved 1056768K
class space used 300K, capacity 386K, committed 512K, reserved 1048576K
//这就是说“ParNew”垃圾回收器负责的年轻代总共有4608KB(4.5MB)可用内存,目前是使用了2601KB(2.5MB)。
par new generation total 4608K, used 2601K
gc之后,我们这不是通过如下代码又分配了一个2MB的数组吗:byte[] array2 = new byte[2 * 1024 * 1024];所以此时在Eden区中一定会有一个2MB的数组,也就是2048KB,然后上次gc之后在From Survivor区中存活了一个512KB的对象,大家也不知道是啥,先不用管他。但是此时你疑惑了,2048KB + 512KB = 2560KB。那为什么说年轻代使用了2601KB呢?因为之前说过了每个数组他会额外占据一些内存来存放一些自己这个对象的元数据,所以你可以认为多出来的41KB可以是数组对象额外使用的内存空间。如下图所示
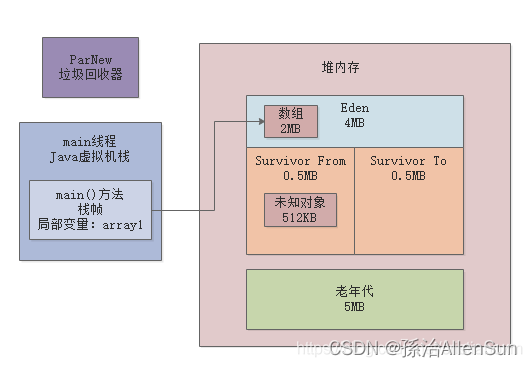
Eden区此时4MB的内存被使用了51%,就是因为有一个2MB的数组在里面。然后From Survivor区,512KB是100%的使用率,此时被之前gc后存活下来的512KB的未知对象给占据了。
eden space 4096K, 51% used [0x00000000ff600000, 0x00000000ff80a558, 0x00000000ffa00000)
from space 512K, 100% used [0x00000000ffa80000, 0x00000000ffb00000, 0x00000000ffb00000)
to space 512K, 0% used [0x00000000ffa00000, 0x00000000ffa00000, 0x00000000ffa80000)
//这个很简单,就是说Concurrent Mark-Sweep垃圾回收器,也就是CMS垃圾回收器
//管理的老年代内存空间一共是5MB,此时使用了62KB的空间,这个是啥你也先不用管了,可以先忽略不计,以后我们有内存分析工具了,你都能看到。
concurrent mark-sweep generation total 5120K, used 62K
//Metaspace元数据空间 和 Class空间,存放一些类信息、常量池之类的东西,此时他们的总容量,使用内存,等等。
Metaspace used 2782K, capacity 4486K, committed 4864K, reserved 1056768K
class space used 300K, capacity 386K, committed 512K, reserved 1048576K
【3】准备触发对象进入老年代的代码
(1)动态年龄判定规则
对象进入老年代的4个常见的时机:
(1)躲过15次gc,达到15岁高龄之后进入老年代;
(2)动态年龄判定规则,如果Survivor区域内年龄1+年龄2+年龄3+年龄n的对象总和大于Survivor区的50%,此时年龄n以上的对象会进入老年代,不一定要达到15岁
(3)如果一次Young GC后存活对象太多无法放入Survivor区,此时直接计入老年代
(4)大对象直接进入老年代
(2)进入老年代的参数设计
模拟出来最常见的一种进入老年代的情况,如果Survivor区域内年龄1+年龄2+年龄3+年龄n的对象总和大于Survivor区的50%,此时年龄n以上的对象会进入老年代,也就是所谓的动态年龄判定规则。
XX:NewSize=10485760
XX:MaxNewSize=10485760
XX:InitialHeapSize=20971520
XX:MaxHeapSize=20971520
XX:SurvivorRatio=8
XX:MaxTenuringThreshold=15
XX:PretenureSizeThreshold=10485760
XX:+UseParNewGC
XX:+UseConcMarkSweepGC
XX:+PrintGCDetails
XX:+PrintGCTimeStamps
Xloggc:gc.log
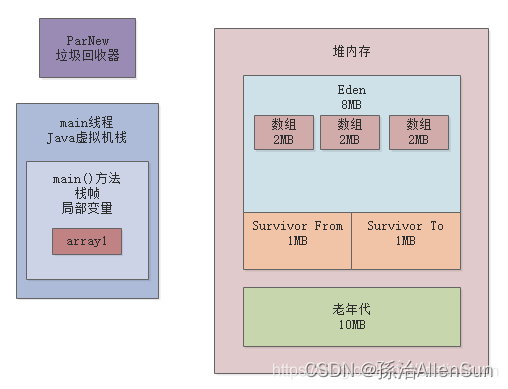
在这些参数里我们注意几点,新生代我们通过“-XX:NewSize”设置为10MB了,然后其中Eden区是8MB,每个Survivor区是1MB,Java堆总大小是20MB,老年代是10MB,大对象必须超过10MB才会直接进入老年代,但是我们通过“-XX:MaxTenuringThreshold=15”设置了,只要对象年龄达到15岁才会直接进入老年代。一切准备就绪,先看看我们当前的内存分配情况,如下图:

(3)代码实例01
public static void main(String[] args) {
// 一个数组占2M内存
byte[] array1 = new byte[2 * 1024 * 1024];
array1 = new byte[2 * 1024 * 1024];
array1 = new byte[2 * 1024 * 1024];
// 使array变量什么都不指向,前3个数组变成垃圾对象
array1 = null;
//前三个数组占6M内存,成为垃圾对象
byte[] array2 = new byte[128 * 1024];
byte[] array3 = new byte[2 * 1024 * 1024];
}
(1)连续创建了3个2MB的数组,最后还把局部变量array1设置为了null
此时的内存如下图所示:
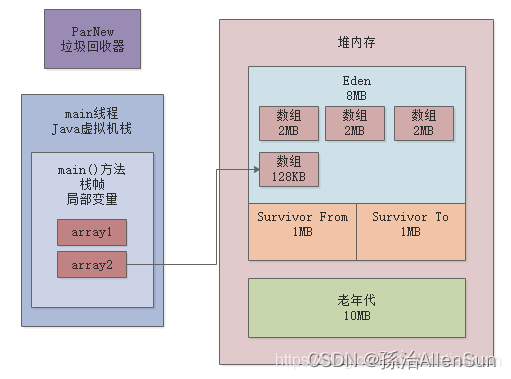
(2)byte[] array2 = new byte[128 * 1024];
此时会在Eden区创建一个128KB的数组同时由array2变量来引用,如下图
(3)byte[] array3 = new byte[2 * 1024 * 1024];
此时Eden区里已经有3个2MB的数组和1个128KB的数组,大小都超过6MB了,Eden总共才8MB,此时是不可能让你创建2MB的数组的。因此此时一定会触发一次Young GC,接着我们开始看GC日志。
(4)GC日志怎么看
(1)GC日志实例
0.297: [GC (Allocation Failure) 0.297: [ParNew: 7260K->715K(9216K), 0.0012641 secs] 7260K->715K(19456K), 0.0015046 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
Heap
par new generation total 9216K, used 2845K [0x00000000fec00000, 0x00000000ff600000, 0x00000000ff600000)
eden space 8192K, 26% used [0x00000000fec00000, 0x00000000fee14930, 0x00000000ff400000)
from space 1024K, 69% used [0x00000000ff500000, 0x00000000ff5b2e10, 0x00000000ff600000)
to space 1024K, 0% used [0x00000000ff400000, 0x00000000ff400000, 0x00000000ff500000)
concurrent mark-sweep generation total 10240K, used 0K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)
Metaspace used 2782K, capacity 4486K, committed 4864K, reserved 1056768K
class space used 300K, capacity 386K, committed 512K, reserved 1048576K
(2)第一段:一次GC的概要说明
这行日志清晰表明了,在GC之前年轻代占用了7260KB的内存,这里大概就是6MB的3个数组 + 128KB的1个数组 + 几百KB的一些未知对象
ParNew: 7260K->715K(9216K), 0.0012641 secs
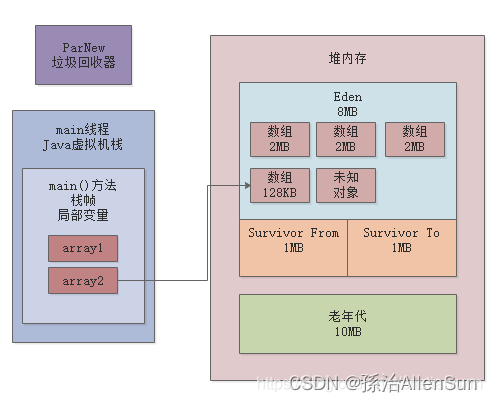
7260K->715K(9216K),一次Young GC过后,剩余的存活对象大概是715KB,之前就说过大概年轻代刚开始会有512KB左右的未知对象,此时再加上我们自己的128KB的数组,差不多就是700KB。
(3)第二段:GC过后的堆内存使用情况
此时From Survivor区域被占据了69%的内存,大概就是700KB左右,这就是一次Young GC后存活下来的对象,他们都进入From Survivor区了。同时Eden区域内被占据了26%的空间,大概就是2MB左右,这就是byte[] array3 = new byte[2 * 1024 * 1024],这行代码在gc过后分配在Eden区域内的数组
par new generation total 9216K, used 2845K [0x00000000fec00000, 0x00000000ff600000, 0x00000000ff600000)
eden space 8192K, 26% used [0x00000000fec00000, 0x00000000fee14930, 0x00000000ff400000)
from space 1024K, 69% used [0x00000000ff500000, 0x00000000ff5b2e10, 0x00000000ff600000)
to space 1024K, 0% used [0x00000000ff400000, 0x00000000ff400000, 0x00000000ff500000)
concurrent mark-sweep generation total 10240K, used 0K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)
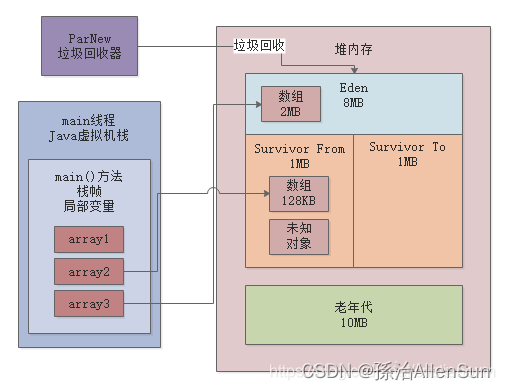
现在Survivor From区里的那700kb的对象,是几岁呢?答案是:1岁。他熬过一次gc,年龄就会增长1岁。而且此时Survivor区域总大小是1MB,此时Survivor区域中的存活对象已经有700KB了,绝对超过了50%。
(5)代码实例02
完善代码实例01,我们把示例代码给完善一下,变成下面的样子,我们要触发出来第二次Young GC,然后看看Survivor区域内的动态年龄判定规则能否生效。
public static void main(String[] args) {
// 一个数组占2M内存
byte[] array1 = new byte[2 * 1024 * 1024];
array1 = new byte[2 * 1024 * 1024];
array1 = new byte[2 * 1024 * 1024];
// 使array变量什么都不指向,前3个数组变成垃圾对象
array1 = null;
//前三个数组占6M内存,成为垃圾对象
byte[] array2 = new byte[128 * 1024];
byte[] array3 = new byte[2 * 1024 * 1024];
array3 = new byte[2 * 1024 * 1024];
array3 = new byte[2 * 1024 * 1024];
array3 = new byte[128 * 1024];
array3 = null;
byte[] array4 = new byte[2 * 1024 * 1024];
}
(1)array3 = new byte[2 * 1024 * 1024];
这几行代码运行过后,实际上会接着分配2个2MB的数组,然后再分配一个128KB的数组,最后是让array3变量指向null,如下图所示。

(2)byte[] array4 = new byte[2 * 1024 * 1024];
Eden区如果要再次放一个2MB数组下去,是放不下的了,所以此时必然会触发一次Young GC
(6)最终版的GC日志
(1)GC日志实例
0.269: [GC (Allocation Failure) 0.269: [ParNew: 7260K->713K(9216K), 0.0013103 secs] 7260K->713K(19456K), 0.0015501 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
0.271: [GC (Allocation Failure) 0.271: [ParNew: 7017K->0K(9216K), 0.0036521 secs] 7017K->700K(19456K), 0.0037342 secs] [Times: user=0.06 sys=0.00, real=0.00 secs]
Heap
par new generation total 9216K, used 2212K [0x00000000fec00000, 0x00000000ff600000, 0x00000000ff600000)
eden space 8192K, 27% used [0x00000000fec00000, 0x00000000fee290e0, 0x00000000ff400000)
from space 1024K, 0% used [0x00000000ff400000, 0x00000000ff400000, 0x00000000ff500000)
to space 1024K, 0% used [0x00000000ff500000, 0x00000000ff500000, 0x00000000ff600000)
concurrent mark-sweep generation total 10240K, used 700K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)
Metaspace used 2782K, capacity 4486K, committed 4864K, reserved 1056768K
class space used 300K, capacity 386K, committed 512K, reserved 1048576K
(2)第一次GC的日志内容
0.269: [GC (Allocation Failure) 0.269: [ParNew: 7260K->713K(9216K), 0.0013103 secs] 7260K->713K(19456K), 0.0015501 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
(3)第二次GC的日志内容
0.271: [GC (Allocation Failure) 0.271: [ParNew: 7017K->0K(9216K), 0.0036521 secs] 7017K->700K(19456K), 0.0037342 secs] [Times: user=0.06 sys=0.00, real=0.00 secs]
注意的是:
ParNew: 7017K->0K(9216K)
这行日志表明,这次GC过后,年轻代直接就没有对象了。在Eden区里有3个2MB的数组和1个128KB的数组,这些对象已经没有了引用,这绝对是会被回收掉的。但是array2这个变量一直引用着一个128KB的数组,它绝对是存活的对象,还有那500多KB的未知对象,此时都去哪里了呢?
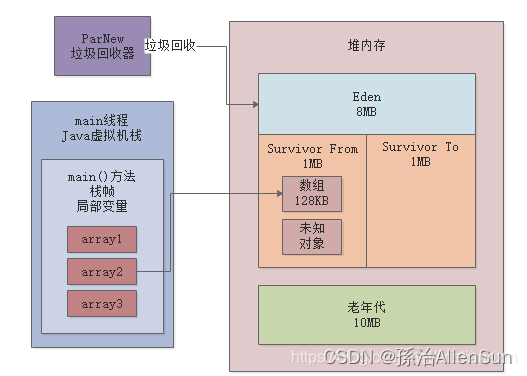
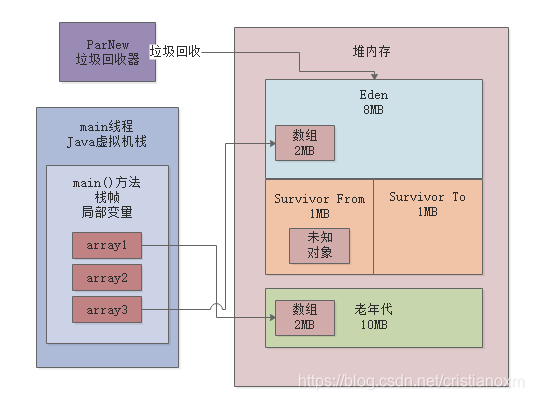
此时会发现Survivor区域中的对象都是存活的,而且总大小超过50%了,而且年龄都是1岁。此时根据动态年龄判定规则:年龄1+年龄2+年龄n的对象总大小超过了Survivor区域的50%,年龄n以上的对象进入老年代。当然这里的对象都是年龄1的,所以直接全部进入老年代了,如下图:

看下面的日志可以确认这一点:
concurrent mark-sweep generation total 10240K, used 700K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)
CMS管理的老年代,此时使用空间刚好是700KB,证明此时Survivor里的对象触发了动态年龄判定规则,虽然没有达到15岁,但是全部进入老年代了。包括我们自己的那个array2变量一直引用的128KB的数组。然后array4变量引用的那个2MB的数组,此时就会分配到Eden区域中,如下图所示

(4)堆内存快照
eden space 8192K, 27% used [0x00000000fec00000, 0x00000000fee290e0, 0x00000000ff400000)
这里就说明Eden区当前就是有一个2MB的数组。
from space 1024K, 0% used [0x00000000ff400000, 0x00000000ff400000, 0x00000000ff500000)
to space 1024K, 0% used [0x00000000ff500000, 0x00000000ff500000, 0x00000000ff600000)
两个Survivor区域都是空的,因为之前存活的700KB的对象都进入老年代了,所以当然现在Survivor里都是空的了。
如果你每次Young GC过后存活的对象太多进入Survivor,特别是超过了Survivor 50%的空间,很可能下次Young GC的时候就会让一些对象触发动态年龄判定规则进入老年代中。
(7)代码实例03
(1)代码实例
public static void main(String[] args) {
// 一个数组占2M内存
byte[] array1 = new byte[2 * 1024 * 1024];
array1 = new byte[2 * 1024 * 1024];
array1 = new byte[2 * 1024 * 1024];
byte[] array2 = new byte[128 * 1024];
array2 = null;
byte[] array3 = new byte[2 * 1024 * 1024];
}
(1)首先分配了3个2MB的数组和一个128K的数组
首先分配了3个2MB的数组,然后最后让array1变量指向了第三个2MB数组接着创建了一个128K的数组,但是确让array2指向了null,同时我们一直都知道,Eden区里会有500KB左右的未知对象
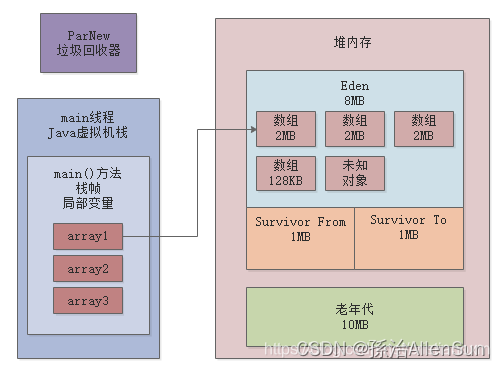
(2)byte[] array3 = new byte[2 * 1024 * 1024];
此时想要在Eden区里再创建一个2MB的数组,肯定是不行的,所以此时必然触发一次Young GC。
(8)GC日志03
(1)GC之后的情况
ParNew: 7260K->573K(9216K), 0.0024098 secs。
这里清晰说明了,本次GC过后,年轻代里就剩下了500多KB的对象,这是为什么呢?此时明明array1变量是引用了一个2MB的数组的啊!其实道理很简单,大家可以想一下,这次GC的时候,会回收掉上图中的2个2MB的数组和1个128KB的数组,然后留下一个2MB的数组和1个未知的500KB的对象,如下图所示:
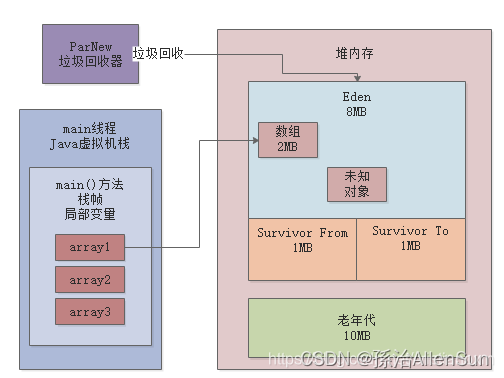
那么此时剩下来的2MB的数组和500KB的未知对象能放入From Survivor区吗?答案是:不能
因为Survivor区仅仅只有1MB。根据我们之前说过的规则,此时是不是要把这些存活对象全部放入老年代?答案:也不是
(2)堆内存结果
eden space 8192K, 26% used [0x00000000fec00000, 0x00000000fee14930, 0x00000000ff400000)
首先Eden区内一定放入了一个新的2MB的数组,就是刚才最后想要分配的那个数组,由array3变量引用,如下图:
其次,看下面的日志:
from space 1024K, 55% used [0x00000000ff500000, 0x00000000ff58f570, 0x00000000ff600000)
大家发现此时From Survivor区中有500KB的对象,其实就是那500KB的未知对象!
所以在这里并不是让2MB的数组和500KB的未知对象都进入老年代,而是把500KB的未知对象放入From Survivor区中!但是现在结合GC日志,大家可以清晰的看到,在这种情况下,是会把部分对象放入Survivor区的。
接着我们看如下日志:
concurrent mark-sweep generation total 10240K, used 2050K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)
此时老年代里确有2MB的数组,因此可以认为,Young GC过后,发现存活下来的对象有2MB的数组和500KB的未知对象。此时把500KB的未知对象放入Survivor中,然后2MB的数组直接放入老年代,如下图。
【4】准备触发Full GC的代码
(1)配置JVM参数
-XX:NewSize=10485760
-XX:MaxNewSize=10485760
-XX:InitialHeapSize=20971520
-XX:MaxHeapSize=20971520
-XX:SurvivorRatio=8
-XX:MaxTenuringThreshold=15
-XX:PretenureSizeThreshold=3145728
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-Xloggc:gc.log
这里最关键一个参数,就是“-XX:PretenureSizeThreshold=3145728”。这个参数要设置大对象阈值为3MB,也就是超过3MB,就直接进入老年代。
(2)代码实例
public static void main(String[] args) {
byte[] array1 = new byte[4 * 1024 * 1024];
array1 = null;
byte[] array2 = new byte[2 * 1024 * 1024];
byte[] array3 = new byte[2 * 1024 * 1024];
byte[] array4 = new byte[2 * 1024 * 1024];
byte[] array5 = new byte[128 * 1024];
byte[] array6 = new byte[2 * 1024 * 1024];
}
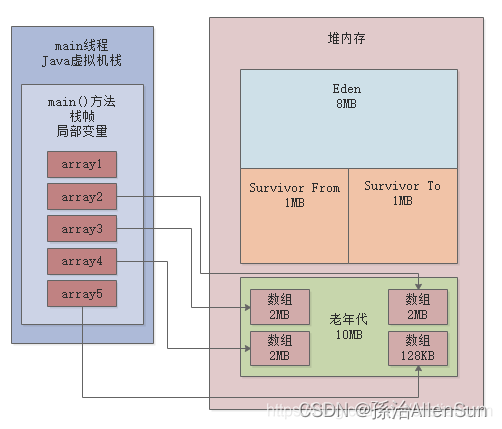
(1)byte[] array1 = new byte[4 * 1024 * 1024];
这行代码直接分配了一个4MB的大对象,此时这个对象会直接进入老年代,接着array1不再引用这个对象

(2)创建3个2MB的数组,1个128KB的数组
全部会进入Eden区域中

(3)byte[] array6 = new byte[2 * 1024 * 1024];
此时还能放得下2MB的对象吗?不可能了,因为Eden区已经放不下了。因此此时会直接触发一次Young GC。
(3)GC日志
(1)GC日志实例
“0.308: [GC (Allocation Failure) 0.308: [ParNew (promotion failed): 7260K->7970K(9216K), 0.0048975 secs]0.314: [CMS: 8194K->6836K(10240K), 0.0049920 secs] 11356K->6836K(19456K), [Metaspace: 2776K->2776K(1056768K)], 0.0106074 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
Heap
par new generation total 9216K, used 2130K [0x00000000fec00000, 0x00000000ff600000, 0x00000000ff600000)
eden space 8192K, 26% used [0x00000000fec00000, 0x00000000fee14930, 0x00000000ff400000)
from space 1024K, 0% used [0x00000000ff500000, 0x00000000ff500000, 0x00000000ff600000)
to space 1024K, 0% used [0x00000000ff400000, 0x00000000ff400000, 0x00000000ff500000)
concurrent mark-sweep generation total 10240K, used 6836K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)
Metaspace used 2782K, capacity 4486K, committed 4864K, reserved 1056768K
class space used 300K, capacity 386K, committed 512K, reserved 1048576K”
(2)第一段
ParNew (promotion failed): 7260K->7970K(9216K), 0.0048975 secs
这行日志显示了,Eden区原来是有7000多KB的对象,但是回收之后发现一个都回收不掉,因为上述几个数组都被变量引用了。
所以此时大家都知道,一定会直接把这些对象放入到老年代里去,但是此时老年代里已经有一个4MB的数组了,还能放的下3个2MB的数组和1个128KB的数组吗?
明显是不行的,此时一定会超过老年代的10MB大小。
(3)第二段
[CMS: 8194K->6836K(10240K), 0.0049920 secs] 11356K->6836K(19456K), [Metaspace: 2776K->2776K(1056768K)], 0.0106074 secs]
大家可以清晰看到,此时执行了CMS垃圾回收器的Full GC,我们之前讲过Full GC其实就是会对老年代进行Old GC,同时一般会跟一次Young GC关联,还会触发一次元数据区(永久代)的GC。在CMS Full GC之前,就已经触发过Young GC了,此时大家可以看到此时Young GC就已经有了,接着就是执行针对老年代的Old GC,也就是如下日志:
CMS: 8194K->6836K(10240K), 0.0049920 secs
这里看到老年代从8MB左右的对象占用,变成了6MB左右的对象占用,这是怎么个过程呢?
很简单,一定是在Young GC之后,先把2个2MB的数组放入了老年代,如下图

此时要继续放1个2MB的数组和1个128KB的数组到老年代,一定会放不下,所以此时就会触发CMS的Full GC然后此时就会回收掉其中的一个4MB的数组,因为他已经没人引用了,如下图所示

接着放入进去1个2MB的数组和1个128KB的数组,如下图所示
所以再看CMS的垃圾回收日志,是从回收前的8MB变成了6MB,就是上图所示。最后在CMS Full GC执行完毕之后,其实年轻代的对象都进入了老年代,此时最后一行代码要在年轻代分配2MB的数组就可以成功了,如下图
(四)怎么查看Dump文件
【1】dump文件的作用
当系统性能出现问题,如果觉得是内存泄漏,想从代码层面解决问题,那么最有效的方法就是查看相关dump文件。
java内存dump是jvm运行时内存的一份快照,利用它可以分析是否存在内存浪费,可以检查内存管理是否合理,当发生OOM的时候,可以找出问题的原因。
一般当服务器挂起,崩溃或者性能低下时,就需要抓取服务器的线程堆栈(Thread Dump)用于后续的分析。在实际运行中,往往一次 dump的信息,还不足以确认问题。为了反映线程状态的动态变化,需要接连多次做 thread dump,每次间隔10-20s,建议至少产生三次 dump信息,如果每次 dump都指向同一个问题,我们才确定问题的典型性。
提供了当前活动线程的快照,及 JVM中所有 Java线程的堆栈跟踪信息,堆栈信息一般包含完整的类名及所执行的方法,如果可能的话还有源代码的行数。
【2】获取dump文件
(1)JVM启动参数获取
JVM启动时增加两个参数
//出现 OOME 时生成堆 dump:
-XX:+HeapDumpOnOutOfMemoryError
//生成堆文件地址
-XX:HeapDumpPath=/opt/logs/myService/HeapDumpOnOutOfMemoryError/
是一种后置动作,只有等当前JVM出现问题后才会触发生成dump文件。也可以直接在VisualVM里直接看
(2)操作系统命令获取 ThreadDump
ps –ef | grep java
kill -3
(3)JVM 自带的工具获取线程堆栈
#jps 或 ps –ef | grep java (获取PID)
jstack [-l ] | tee -a jstack.log(获取ThreadDump)
(4)Arthas命令生成
//生成dump文件,底层就是使用jmap -dump命令,只不过这里更简单好用
heapdump /tmp/dump-1.hprof
(五)JVM调优工具的介绍、安装及使用
【1】VisualVM
(1)打开监测工具并且安装插件
JDK为我们提供了监测工具VisualVM,我们直接在 终端或者cmd 中输入 jvisualvm 命令就可以进入
(2)idea中安装visualvm插件,并且配置路径
(3)重启idea,点击运行进入

(4)下载插件

因为插件是在github上面下载的,所以下载的时候可能会有网络的问题,开代理可能也装不上。那就手动下载插件的文件
下载地址:https://visualvm.github.io/pluginscenters.html
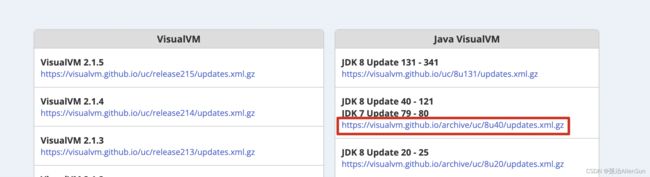
然后点击安装

完成安装以后就有了入口了
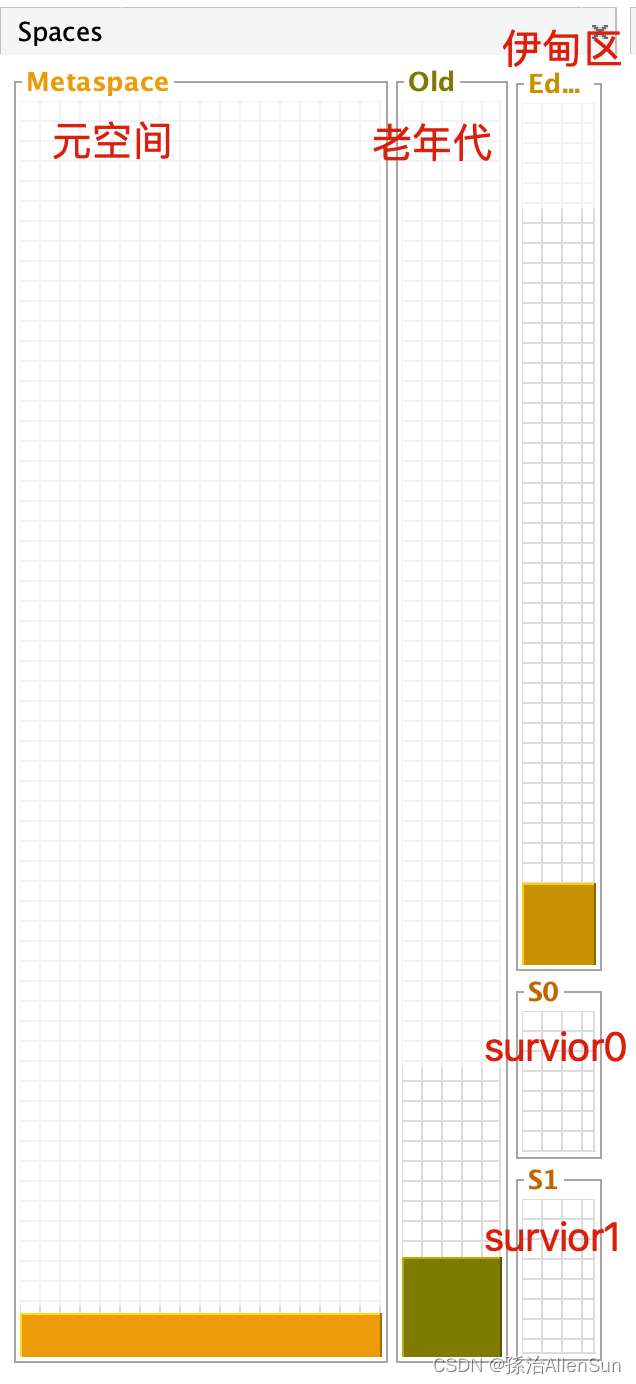
(4)页面介绍
(1)Spaces
有颜色的区域是占用的空间,空白的部分是指剩余的空间
(2)Graphs
(1)Compile Time

编译时间表示虚拟机的JIT编译器编译热点代码的耗时。
Java语言为了实现跨平台特性,Java代码编译出来后形成的class文件中存储的事byte code,jvm通过解释的方法是形成字节码命令。为了解决程序解释执行的速度问题,jvm中内置了两个运行时编译器,如果一段java代码被动调用达到一定次数,就会判定这段代码为热点代码,并且把这段代码交给JIT编译器编译成本地代码,从而提高运行速度。所以随着代码被编译的越来越彻底,运行速度应当是越来越快。
而Java运行器编译的最大缺点就是它运行编译时需要消耗程序正常的运行时间,也就是compile time
(2)Class Loader Time
表示class的load和unload时间

(3)GC Time

25 collections:表示自监视以来一共经历了25次GC,包括Minor GC和Full GC
270.023ms:表示GC一共花费了270.023ms
Last Cause:Allocation Failure:表示上次发生GC的原因是“内存分配失败”
(4)Eden Space

1-Eden Space (84.000M, 33.000M): 3.222M, 30 collections, 250.271ms
Eden Space最大可分配空间84.000M
Eden Space当前分配空间33.000M
Eden Space当前占用空间3.222M
当前新生代发生GC的次数为21次,共耗时250.271ms
(5)Survivor 0 and Survivor 1

S0和S1肯定有一个是空闲的,这样才能方便执行minor GC的操作,但是两者的最大分配空间是相同的,并且在minor GC时,会发生S0和S1之间的切换
S0最大分配空间28.000M,当前分配空间18.500M,已占用空间17.578M
(6)Old Gen

参数分析如同上
(7)Metaspace

(3)GC优化的原则和目的
(1)原则
1-多数的java应用不需要在服务器山进行GC优化
2-多数导致GC问题的Java应用,都不是因为我们参数设置错误,而是代码问题
3-在应用上线之前,先考虑把机器的JVM参数设置到最优
4-减少创建对象的数量
5-减少使用全局变量额大对象
6-GC优化是到最后不得已才采用的手段
7-在实际使用中,分析GC情况优化代码比优化GC参数要多得多
(2)目的
1-把转移到老年代的对象数量降低到最小
2-减少full GC的执行时间
3-减少使用全局变量和大对象
3-调整新生代的大小到最合适
4-设置老年代的大小为最合适
5-选择合适的GC收集器
(3)标准
1-Minor GC执行时间不到50ms,Minor GC执行不频繁,约10s一次
2-Full GC执行时间不到1s,Full GC执行频率不算频繁,不低于10min一次
(5)VisualVM分析优化案例
(1)准备代码
无限循环,循环中会创建对象放进list中
public class jvmUpdate01 {
static class StaticObject {
}
public static void main(String[] args) {
List<StaticObject> list = new ArrayList<StaticObject>();
int i=1;
while (true) {
list.add(new StaticObject());
i++;
System.out.println(i);
System.out.println(list.size());
}
}
}
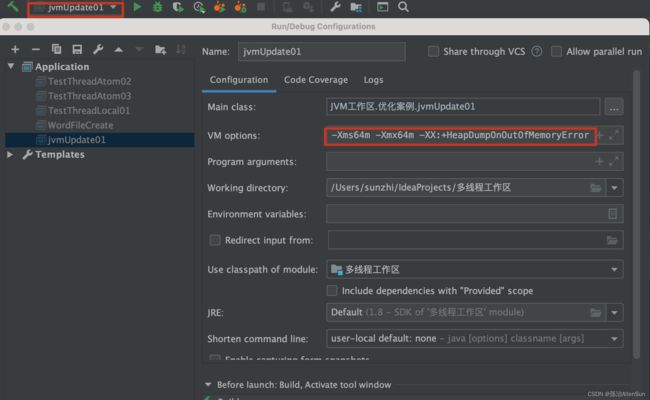
(2)设置JVM参数
给堆分配的最大最小的值都是64M(很小的堆大小):-Xms64m -Xmx64m -XX:+HeapDumpOnOutOfMemoryError
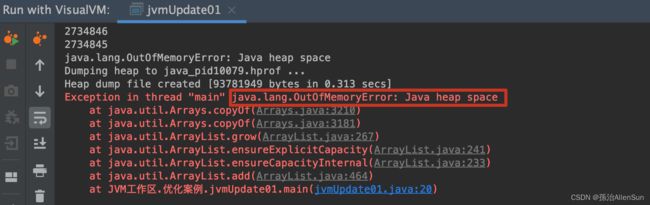
(3)运行结果
运行一段时间后结果报出异常:OutOfMemoryError: Java heap space(堆内存溢出)
(4)看一下VisualGC的监视情况
监视界面情况,可以看到堆内存已经用完了

再看看VisualGC的监视情况,可以分析出来的信息
1-伊甸区GC了49次,耗时450ms:说明新生代堆内存分配的空间太小了,导致一创建对象就把新生代填满了,然后就要频繁的GC。
2-survivor区没有任何GC:说明创建的都是大对象,从伊甸区直接就进入老年代了,没有经过survivor区
3-老年代GC了27次,耗时10s:大对象进入老年代后不会被杀死,所以会占满内存
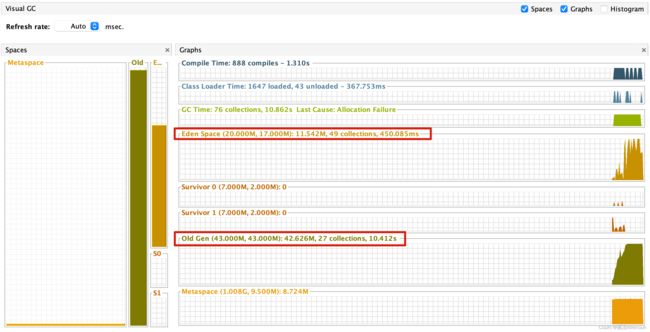
(5)什么是堆内存溢出OOM
当老年代满了以后,底层会触发Full GC,就会对老年代的垃圾进行收集,但是在收集垃圾的时候发现老年代里面的对象都是有用的,那么GC就不会删除任何对象也不会释放任何内存,再往老年代里存对象就会出现空间不够用的情况,也就是堆内存溢出。
(6)解决步骤一:增加堆内存参数
通过上面的分析,解决思路就是加大新生代和老年代堆内存的大小,同时减少创建大对象
优化参数:-Xms512m -Xmx512m -Xmn128m -XX:+HeapDumpOnOutOfMemoryError
运行一段时间后看结果
1-首先没有再出现堆内存溢出
2-伊甸区新生代进行了68次GC,使用时间5.048s,
3-老年代进行了7次GC,耗时26.232s,需要再优化,减少创建大对象

(7)分析堆Dump文件
参数加上:-Xshare:off,按钮就可以用了
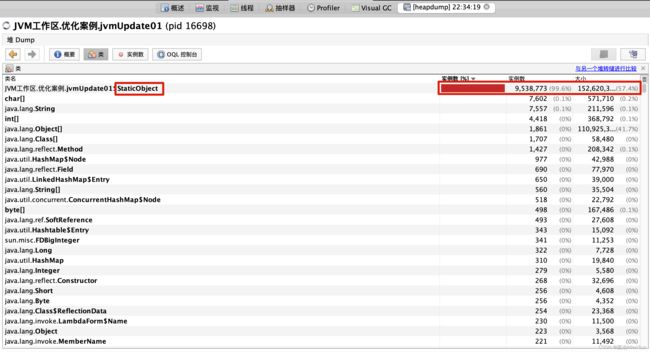
可以看到StaticObject类的对象实例数太多了,占用的内存太多了
(8)解决步骤二:减少创建大对象
不要循环创建StaticObject类的对象,即可
【2】国产idea插件VisualGC
(1)在idea的插件市场下载
(2)插件下载完成后重启idea就可以看到下方悬停的入口了
运行程序后点击进去查看
如果页面上没有显示侧边栏,在这里设置
【3】Alibaba出品线上JVM监控诊断利器:Arthas插件
(1)安装idea的Arthas插件
这样就可以使用插件来生成命令了,就不需要自己手动的写命令了

重启之后的效果

(2)本地安装arthas
终端命令
安装:curl -O https://alibaba.github.io/arthas/arthas-boot.jar
启动:java -jar arthas-boot.jar

(3)arthas的功能特点
(1)有没有一个全局JVM运行时监控?CPU、线程、内存、堆栈信息等等
(2)CPU飙高,是什么造成的?
(3)接口没反应、卡住了,是不是死锁了?
(4)CTO说你们这个接口太慢了,要优化一下?如何准确找出耗时的代码
(5)我写的代码没有执行,是部署的分支不对,还是我压根没有提交?
(6)线上有一个低级错误,改起来很简单,能不能在不重启应用的情况下,进行类替换,热部署
(4)使用案例
(1)准备测试的案例代码(死锁、内存泄漏多种情况、死循环)
public class jvmUpdate02 {
private static HashSet hashSet = new HashSet();
public static void main(String[] args) {
//模拟死锁
deadThread();
//创建对象
addHashSetThread();
//模拟高CPU
cpuHigh();
}
/** 模拟死锁
* @MethodName: deadThread
* @Author: AllenSun
* @Date: 2022/11/9 上午12:59
*/
private static void deadThread() {
Object lock1 = new Object();
Object lock2 = new Object();
new Thread(()->{
synchronized (lock1) {
try {
System.out.println("线程1启动");
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lock2) {
System.out.println("线程1结束");
}
}
}).start();
new Thread(()->{
synchronized (lock2) {
try {
System.out.println("线程2启动");
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lock1) {
System.out.println("线程2结束");
}
}
}).start();
System.out.println("主线程结束");
}
/**不断的向HashSet集合添加数据
* @MethodName: addHashSetThread
* @Author: AllenSun
* @Date: 2022/11/9 上午1:03
*/
public static void addHashSetThread() {
new Thread(()->{
int count = 0;
while (true) {
try {
hashSet.add("count"+count);
Thread.sleep(10000);
count++;
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
/** 模拟CPU飙升
* @MethodName: cpuHigh
* @Author: AllenSun
* @Date: 2022/11/9 上午1:05
*/
public static void cpuHigh() {
new Thread(()->{
while (true) {
}
}).start();
}
}
(2)运行代码,启动arthas
先运行代码,然后启动arthas:java -jar arthas-boot.jar
(3)排查定位CPU飙高问题(死循环)
(1)输入dashboard:仪表盘,内存使用情况综合界面
可以看出来下面线程id为14的线程占用的CPU较高,接下来对其进行分析
(2)thread 线程id:查看问题线程的具体情况
ctrl+c退出仪表盘
thread 14查看对应线程的情况

找到92行,果然看到方法体中有一个无限循环,导致了CPU飙高
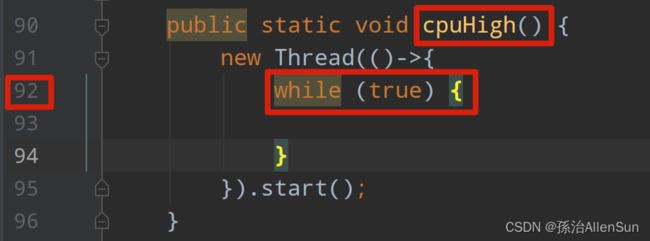
(3)thread -n 1:列出CPU占用前1的线程

(4)排查定位死锁问题(死锁)
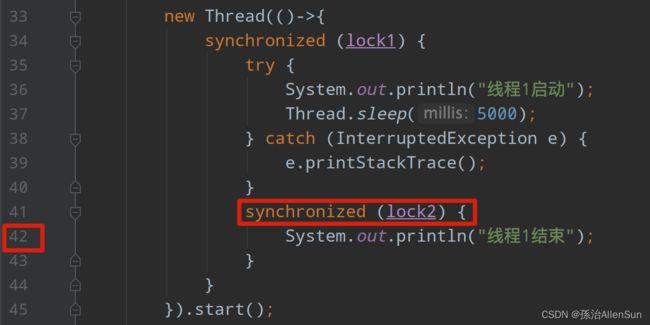
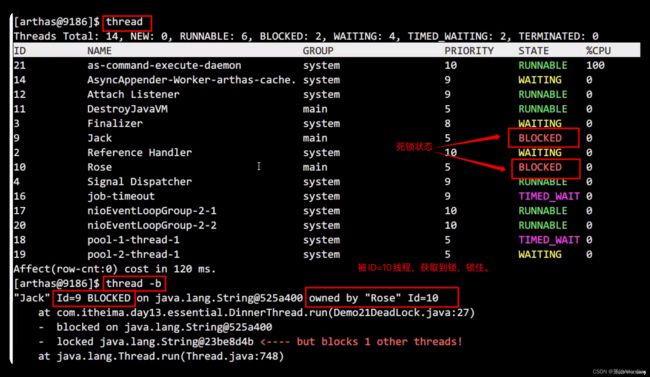
(1)thread -b:定位死锁问题出现的位置

定位到42行,这个lock2在下面被尝试获取失败导致产生的死锁
(2)thread,获取所有线程的情况
根据状态State的字段【BLOCKED】可以找到具体产生死锁的方法
(5)monitor - 方法执行监控
一个方法被调用了多少次,平均耗时,成功率多少,在对方法进行压测的时候可以用到
(6)stack - 输出当前方法被调用的调用路径
比如有很多if判断或者switch,可以确定方法在哪个地方被调用了
(7)trace - 方法内部调用路径,并输出方法路径上的每个节点上耗时
对耗时做一个观测,耗时较高的会有高亮标记
(8)tt - 方法执行数据的时空隧道
记录下指定方法每次调用的入参和返回信息,并能对这些不同的时间下调用进行观测
有一个接口,测试连接的时候,需要对方调用你的接口进行测试,那么tt可以记住这个进程,请求一次以后,就可以自己反复的进行调用测试了,就不用麻烦别人来帮你调用测试了
(9)watch - 方法执行数据观测
检测某个类的某个方法
(六)Arthas命令详细介绍
【1】核心监视功能
(1)monitor:监控方法的执行情况
监控指定类中方法的执行情况,用来监视一个时间段中指定方法的执行次数,成功次数,失败次数,耗时等这些信息。
监控demo.MathGame类,并且每5S更新一次状态。
monitor demo.MathGame primeFactors -c 5

(2)watch:检测函数返回值
方法执行数据观测,让你能方便的观察到指定方法的调用情况。能观察到的范围为:返回值、抛出异常、入参,通过编写OGNL 表达式进行对应变量的查看。
(1)通过watch命令可以查看函数的参数/返回值/异常信息。
# 查看方法执行的返回值
watch demo.MathGame primeFactors returnObj
# 观察demo.MathGame类中primeFactors方法出参和返回值,结果属性遍历深度为2。
# params:表示所有参数数组(因为不确定是几个参数)。
# returnObject:表示返回值
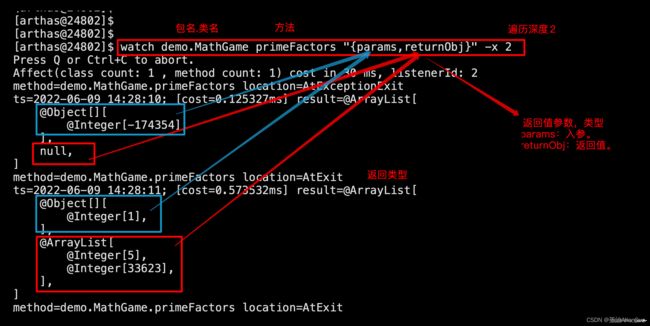
watch demo.MathGame primeFactors "{params,returnObj}" -x 2
(2)查看执行前参数:
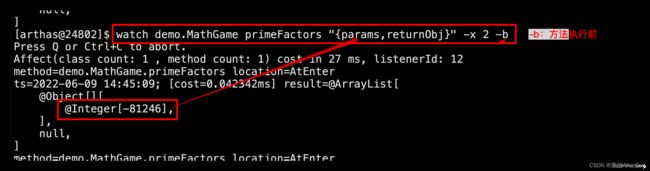
# -b 方法执行前的参数
watch demo.MathGame primeFactors "{params,returnObj}" -x 2 -b
# 查看方法中的属性
watch demo.MathGame primeFactors "{target}" -x 2 -b

(3)查看某一属性的值
watch demo.MathGame primeFactors "{target.illegalArgumentCount}" -x 2 -b
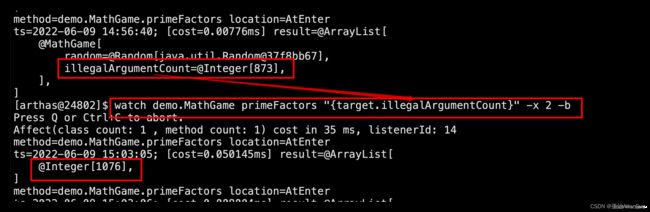
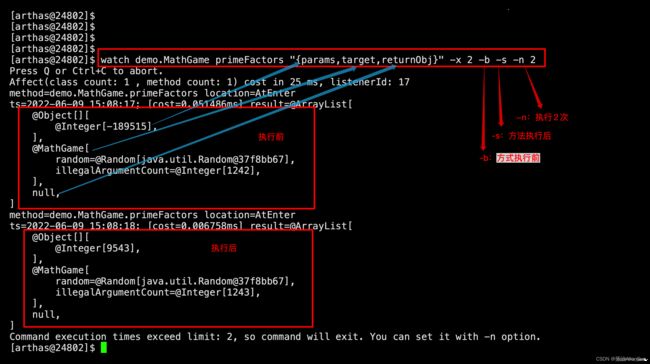
(4)检测方法在执行前-b、执行后-s的入参params、属性target和返回值returnObj
watch demo.MathGame primeFactors "{params,target,returnObj}" -x 2 -b -s -n 2
(5)输入参数小于0的情况
watch demo.MathGame primeFactors "{params[0],target}" "params[0]<0"

(3)trace:根据路径追踪,并记录消耗时间
对方法内部调用路径进行追踪,并输出方法路径上的每个节点上耗时。
(1)trace 命令能主动搜索 class-pattern/method-pattern 对应的方法调用路径,渲染和统计整个调用链路上的所有性能开销和追踪调用链路。
(2)观察表达式的构成主要由ognl 表达式组成,所以你可以这样写"{params,returnObj}",只要是一个合法的 ognl 表达式,都能被正常支持。
(3)很多时候我们只想看到某个方法的rt大于某个时间之后的trace结果,现在Arthas可以按照方法执行的耗时来进行过滤了,例如trace *StringUtils isBlank '#cost>100’表示当执行时间超过100ms的时候,才会输出trace的结果。
(4)watch/stack/trace这个三个命令都支持#cost耗时条件过滤。
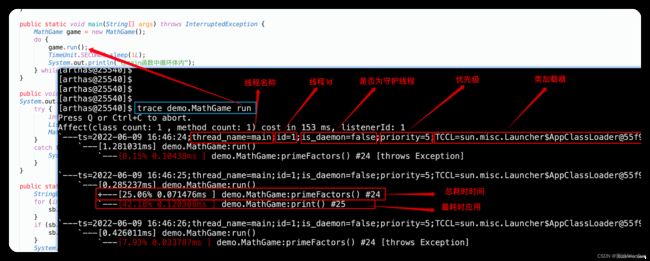
(1)trace函数指定类的指定方法
# trace函数指定类的指定方法
trace demo.MathGame run
 (2)执行1次后退出
(2)执行1次后退出
# 执行1次后退出
trace demo.MathGame run -n 1
 (3)如果希望trace jdk里的函数
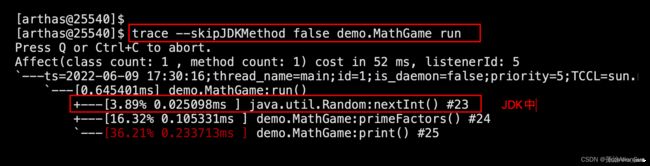
(3)如果希望trace jdk里的函数
# 默认情况下,trace不会包含jdk里的函数调用,如果希望trace jdk里的函数。
# 需要显式设置--skipJDKMethod false。
trace --skipJDKMethod false demo.MathGame run
(4)trace大于0.5ms的调用路径
# 据调用耗时过滤,trace大于0.5ms的调用路径
trace demo.MathGame run '#cost > .5'

(5)多层trace的效果
# 可以用正则表匹配路径上的多个类和函数,一定程度上达到多层trace的效果。
trace -E com.test.ClassA|org.test.ClassB method1|method2|method3
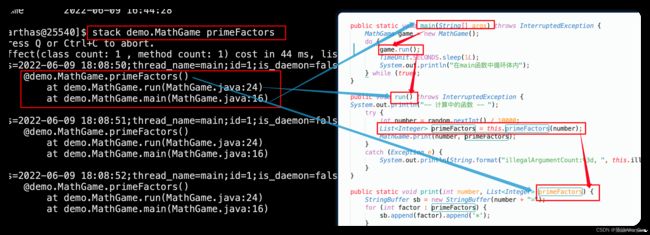
(4)stack:输出当前方法被调用的调用路径
输出当前方法被调用的调用路径。很多时候我们都知道一个方法被执行,但这个方法被执行的路径非常多,或者你根本就不知道这个方法是从那里被执行了,此时你需要的是 stack 命令。
(1)获取primeFactors的调用路径
# 获取primeFactors的调用路径
stack demo.MathGame primeFactors
(2)条件表达式来过滤
# 条件表达式来过滤,第0个参数的值小于0,-n表示获取2次
stack demo.MathGame primeFactors 'params[0]<0' -n 2

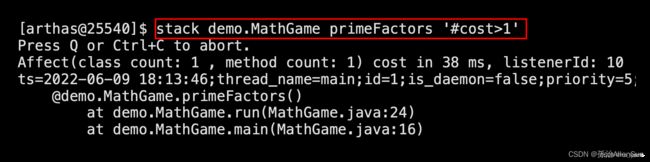
(3)据执行时间来过滤
# 据执行时间来过滤,耗时大于0.5毫秒
stack demo.MathGame primeFactors '#cost>0.5'
(5)tt:时间隧道,记录多个请求
time-tunnel 时间隧道。记录下指定方法每次调用的入参和返回信息,并能对这些不同时间下调用的信息进行观测
watch 虽然很方便和灵活,但需要提前想清楚观察表达式的拼写,这对排查问题而言要求太高,因为很多时候我们并不清楚问题出自于何方,只能靠蛛丝马迹进行猜测。
这个时候如果能记录下当时方法调用的所有入参和返回值、抛出的异常会对整个问题的思考与判断非常有帮助。
于是乎,TimeTunnel 命令就诞生了。
作用:记录指定方法每次调用的入参和返回值,并后期还可以对这些信息进行观测
(6)项目中使用
 (1)trace:查询最耗时应用
(1)trace:查询最耗时应用
# 在浏览器上进行登录操作,检查最耗时的方法
trace *.DispatcherServlet *

# 可以分步trace,请求最终是被DispatcherServlet#doDispatch()处理了
trace *.FrameworkServlet doService

(2)jad:反编译耗时代码
# trace结果里把调用的行号打印出来了,我们可以直接在IDE里查看代码(也可以用jad命令反编译)
jad --source-only *.DispatcherServlet doDispatch

(3)trace:查询最耗时应用
watch *.DispatcherServlet getHandler 'returnObj'
查看返回的结果,得到使用到了2个控制器的方法

(4)watch:捕获耗时应用入参、返回值
watch com.itheima.controller.* * {params,returnObj} -x 2

(5)结论
通过trace, jad, watch最后得到这个操作由2个控制器来处理,分别是:
com.itheima.controller.UserController.login()
com.itheima.controller.StudentController.findAll()
【2】JVM相关命令
(1)dashboard:实时数据面板
查看当前系统的实时数据面板。
dashboard
输入 q 或者 Ctrl+C 可以退出dashboard命令
数据说明:
ID:Java级别的线程ID,注意这个ID不能跟jstack中的nativeID一一对应
NAME:线程名
GROUP:线程组名
PRIORITY:线程优先级, 1~10之间的数字,越大表示优先级越高
STATE:线程的状态
CPU%:线程消耗的cpu占比,采样100ms,将所有线程在这100ms内的cpu使用量求和,再算出每个线程的cpu使用占比。
TIME:线程运行总时间,数据格式为分:秒
INTERRUPTED:线程当前的中断位状态
DAEMON:是否是daemon线程
(2)Thread:线程相关堆栈信息
线程相关堆栈信息。
(1)Arthas支持管道,可以用 thread 1 | grep ‘main(’ 查找到main class。
thread 1 | grep 'main('
thread # 显示所有线程的信息
thread 1 # 显示1号线程的运行堆栈
thread -b # 查看阻塞的线程信息
thread -n 3 # 查看最忙的3个线程,并打印堆栈
thread -i 1000 -n 3 # 指定采样时间间隔,每过1000毫秒采样,显示最占时间的3个线程
查看处于等待状态的线程(WAITING、BLOCKED)
thread --state WAITING
(2)死锁线程查看
thread # 查看线程状态
thread -b # 查看阻塞的线程信息
(3)jvm
 THREAD相关
THREAD相关
COUNT:JVM当前活跃的线程数
DAEMON-COUNT: JVM当前活跃的守护线程数
PEAK-COUNT:从JVM启动开始曾经活着的最大线程数
STARTED-COUNT:从JVM启动开始总共启动过的线程次数
DEADLOCK-COUNT:JVM当前死锁的线程数
文件描述符相关
MAX-FILE-DESCRIPTOR-COUNT:JVM进程最大可以打开的文件描述符数
OPEN-FILE-DESCRIPTOR-COUNT:JVM当前打开的文件描述符数
(4)sysprop:查看/修改属性
sysprop # 查看所有属性
sysprop java.version # 查看单个属性,支持通过tab补全
修改某个属性
sysprop user.country
user.country=US
(5)sysenv:查看JVM环境属性
查看当前JVM的环境属性(System Environment Variables)
# 查看所有环境变量
sysenv
# 查看单个环境变量
sysenv USER
(6)vmpotion:查看JVM中选项
查看JVM中选项,可以修改
# 查看所有的选项
vmoption
# 查看指定的选项
vmoption PrintGCDetails
# 更新指定的选项
vmoption PrintGCDetails true
 更新某一个值
更新某一个值

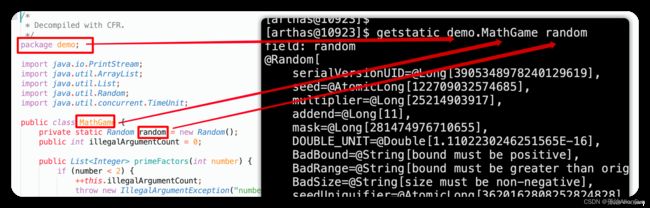
(7)getstatic:获取静态成员变量
获取静态成员变量
# 语法
getstatic 类名 属性名
# 显示demo.MathGame类中静态属性random
getstatic demo.MathGame random
(8)ognl:执行ognl表达式
执行ognl表达式,这是从3.0.5版本新增的功能。
(1)调用静态函数
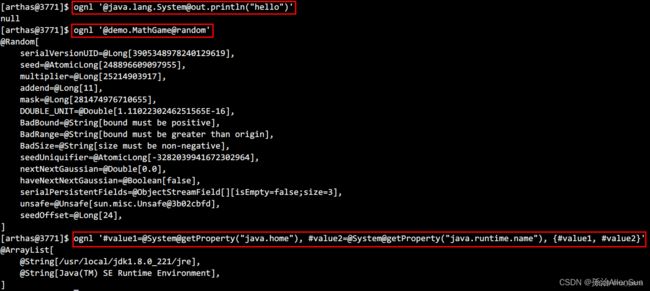
# 获取系统变量中值,并且打印(只会打印有返回值函数)
ognl '@[email protected]("hello")'
(2)获取静态类的静态字段
# 获取代码中的运行返回值
ognl '@demo.MathGame@random'
(3)执行多行表达式,赋值给临时变量,返回一个List
# 计算value1、value2值,并存在List集合中
ognl '#value1=@System@getProperty("java.home"), #value2=@System@getProperty("java.runtime.name"), {#value1, #value2}'
【3】类和类加载器(class/classLoader)
(1)sc:查看类信息
查看类的信息(sc: Search Class)
查看JVM已加载的类信息,“Search-Class” 的简写,这个命令能搜索出所有已经加载到 JVM 中的 Class 信息
sc 默认开启了子类匹配功能,也就是说所有当前类的子类也会被搜索出来,想要精确的匹配,请打开options disable-sub-class true开关。
# 模糊搜索,demo包下所有的类
sc demo.*
# 打印类的详细信息
sc -d demo.MathGame

(2)sm:查看已加载方法信息
查看已加载方法信息(“Search-Method” )
查看已加载类的方法信息“Search-Method” 的简写,这个命令能搜索出所有已经加载了 Class 信息的方法信息。
sm 命令只能看到由当前类所声明 (declaring) 的方法,父类则无法看到。
# 显示String类加载的方法
sm java.lang.String
# 查看方法信息
sm demo.MathGame
# 查看方法信息(详细信息-d)
sm -d demo.MathGame

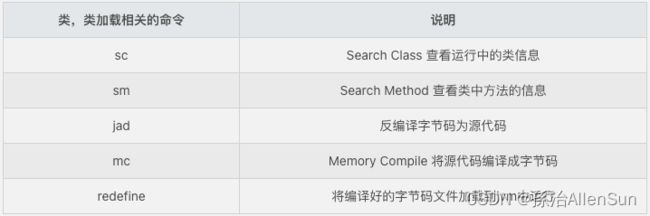
(3)编译与反编译jad、mc、redefine
(1)jad:反编译已加载类源码
反编译指定已加载类源码,jad 命令将 JVM 中实际运行的 class 的 byte code 反编译成 java 代码,便于你理解业务逻辑;在 Arthas Console 上,反编译出来的源码是带语法高亮的,阅读更方便。当然,反编译出来的 java 代码可能会存在语法错误,但不影响你进行阅读理解。
# 反编译MathGame方法
jad demo.MathGame
# 反编绎时只显示源代码(排除ClassLoader信息)。
# 默认情况下,反编译结果里会带有ClassLoader信息,通过--source-only选项,可以只打印源代码。方便和mc/redefine命令结合使用。
jad --source-only demo.MathGame
# 反编译到指定文件中
jad --source-only demo.MathGame > Hello.java
# 只反编译mathGame类型中main方法
jad demo.MathGame main

(2)mc:编译Java代码
内存编译,Memory Compiler/内存编译器,编译.java文件生成.class
# 在内存中编译Hello.java为Hello.class
mc /root/Hello.java
# 可以通过-d命令指定输出目录
mc -d /root/bbb /root/Hello.java

(3)redefine:加载外部.class文件
加载外部的.class文件,redefine到JVM里。
注意, redefine后的原来的类不能恢复,redefine有可能失败(比如增加了新的field)。
reset命令对redefine的类无效。如果想重置,需要redefine原始的字节码。
redefine命令和jad/watch/trace/monitor/tt等命令会冲突。执行完redefine之后,如果再执行上面提到的命令,则会把redefine的字节码重置。
redefine的限制
(1)不允许新增加field/method
(2)正在跑的函数,没有退出不能生效,比如下面新增加的System.out.println,只有run()函数里的会生效。
# 1. 使用jad反编译demo.MathGame输出到/root/MathGame.java
jad --source-only demo.MathGame > /root/MathGame.java
# 2.按上面的代码编辑完毕以后,使用mc内存中对新的代码编译
mc /root/MathGame.java -d /root
# 3.使用redefine命令加载新的字节码
redefine /root/demo/MathGame.class
(4)dump:保存已加载字节码文件到本地
将已加载类的字节码文件保存在特定目录:logs/arthas/classdump。不同的类加载器放在不同的目录下。dump作用:将正在JVM中运行的程序的字节码文件提取出来,保存在logs相应的目录下
# 把String类的字节码文件保存到~/logs/arthas/classdump/目录下
dump java.lang.String
# 把demo包下所有的类的字节码文件保存到~/logs/arthas/classdump/目录下
dump demo.*
(5)classloader:获取类加载器的信息
获取类加载器的信息
作用:
(1)classloader 命令将 JVM 中所有的classloader的信息统计出来,并可以展示继承树,urls等。
(2)可以让指定的classloader去getResources,打印出所有查找到的resources的url。对于ResourceNotFoundException异常比较有用。
# 默认按类加载器的类型查看统计信息
classloader

# 按类加载器的实例查看统计信息,可以看到类加载的hashCode
classloader -l

# 查看ClassLoader的继承树
classloader -t

# 通过类加载器的hash,查看此类加载器实际所在的位置
classloader -c 680f2737

# 使用ClassLoader去查找指定资源resource所在的位置
classloader -c 680f2737 -r META-INF/MANIFEST.MF

# 使用ClassLoader去查找类的class文件所在的位置
classloader -c 680f2737 -r java/lang/String.class
![]()
# 使用ClassLoader去加载类
classloader -c 70dea4e --load java.lang.String

classloader命令主要作用有哪些?
(1)显示所有类加载器的信息
(2)获取某个类加载器所在的jar包
(3)获取某个资源在哪个jar包中
(4)加载某个类