又来更新啦,Android面试题《思考与解答》11月刊奉上。
说说View/ViewGroup的绘制流程
View的绘制流程是从ViewRoot的performTraversals开始的,它经过measure,layout,draw三个过程最终将View绘制出来。
performTraversals会依次调用performMeasure,performLayout,performDraw三个方法,他们会依次调用measure,layout,draw方法,然后又调用了onMeasure,onLayout,dispatchDraw。
- measure :
对于自定义的单一view的测量,只需要根据父 view 传递的MeasureSpec进行计算大小。
对于ViewGroup的测量,一般要重写onMeasure方法,在onMeasure方法中,父容器会对所有的子View进行Measure,子元素又会作为父容器,重复对它自己的子元素进行Measure,这样Measure过程就从DecorView一级一级传递下去了,也就是要遍历所有子View的的尺寸,最终得出出总的viewGroup的尺寸。Layout和Draw方法也是如此。
- layout :根据
measure子 View 所得到的布局大小和布局参数,将子View放在合适的位置上。
对于自定义的单一view,计算本身的位置即可。
对于ViewGroup来说,需要重写onlayout方法。除了计算自己View的位置,还需要确定每一个子View在父容器的位置以及子view的宽高(getMeasuredWidth和getMeasuredHeight),最后调用所有子view的layout方法来设定子view的位置。
- draw :把 View 对象绘制到屏幕上。
draw()会依次调用四个方法:
1)drawBackground(),根据在 layout 过程中获取的 View 的位置参数,来设置背景的边界。
2)onDraw(),绘制View本身的内容,一般自定义单一view会重写这个方法,实现一些绘制逻辑。
3) dispatchDraw(),绘制子View
4)onDrawScrollBars(canvas),绘制装饰,如 滚动指示器、滚动条、和前景
说说你理解的MeasureSpec
MeasureSpec是由父View的MeasureSpec和子View的LayoutParams通过简单的计算得出一个针对子View的测量要求,这个测量要求就是MeasureSpec。
- 首先,
MeasureSpec是一个大小跟模式的组合值,MeasureSpec中的值是一个整型(32位)将size和mode打包成一个Int型,其中高两位是mode,后面30位存的是size
// 获取测量模式
int specMode = MeasureSpec.getMode(measureSpec)
// 获取测量大小
int specSize = MeasureSpec.getSize(measureSpec)
// 通过Mode 和 Size 生成新的SpecMode
int measureSpec=MeasureSpec.makeMeasureSpec(size, mode);
- 其次,每个子View的
MeasureSpec值根据子View的布局参数和父容器的MeasureSpec值计算得来的,所以就有一个父布局测量模式,子视图布局参数,以及子view本身的MeasureSpec关系图:
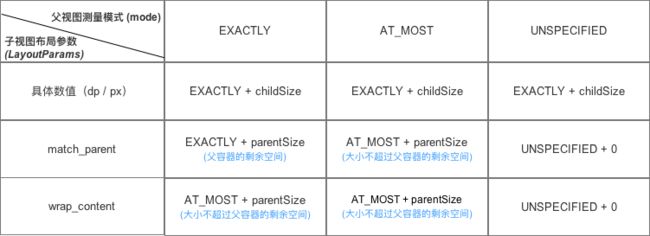
其实也就是getChildMeasureSpec方法的源码逻辑,会根据子View的布局参数和父容器的MeasureSpec计算出来单个子view的MeasureSpec。
- 最后是实际应用时:
对于自定义的单一view,一般可以不处理onMeasure方法,如果要对宽高进行自定义,就重写onMeasure方法,并将算好的宽高通过setMeasuredDimension方法传进去。
对于自定义的ViewGroup,一般需要重写onMeasure方法,并且调用measureChildren方法遍历所有子View并进行测量(measureChild方法是测量具体某一个view的宽高),然后可以通过getMeasuredWidth/getMeasuredHeight获取宽高,最后通过setMeasuredDimension方法存储本身的总宽高。
Scroller是怎么实现View的弹性滑动?
- 在
MotionEvent.ACTION_UP事件触发时调用startScroll()方法,该方法并没有进行实际的滑动操作,而是记录滑动相关量(滑动距离、滑动时间) - 接着调用
invalidate/postInvalidate()方法,请求View重绘,导致View.draw方法被执行 - 当View重绘后会在draw方法中调用
computeScroll方法,而computeScroll又会去向Scroller获取当前的scrollX和scrollY;然后通过scrollTo方法实现滑动;接着又调用postInvalidate方法来进行第二次重绘,和之前流程一样,如此反复导致View不断进行小幅度的滑动,而多次的小幅度滑动就组成了弹性滑动,直到整个滑动过成结束。
mScroller = new Scroller(context);
@Override
public boolean onTouchEvent(MotionEvent event) {
switch (event.getAction()) {
case MotionEvent.ACTION_UP:
// 滚动开始时X的坐标,滚动开始时Y的坐标,横向滚动的距离,纵向滚动的距离
mScroller.startScroll(getScrollX(), 0, dx, 0);
invalidate();
break;
}
return super.onTouchEvent(event);
}
@Override
public void computeScroll() {
// 重写computeScroll()方法,并在其内部完成平滑滚动的逻辑
if (mScroller.computeScrollOffset()) {
scrollTo(mScroller.getCurrX(), mScroller.getCurrY());
invalidate();
}
}
OKHttp有哪些拦截器,分别起什么作用
OKHTTP的拦截器是把所有的拦截器放到一个list里,然后每次依次执行拦截器,并且在每个拦截器分成三部分:
- 预处理拦截器内容
- 通过
proceed方法把请求交给下一个拦截器 - 下一个拦截器处理完成并返回,后续处理工作。
这样依次下去就形成了一个链式调用,看看源码,具体有哪些拦截器:
Response getResponseWithInterceptorChain() throws IOException {
// Build a full stack of interceptors.
List interceptors = new ArrayList<>();
interceptors.addAll(client.interceptors());
interceptors.add(retryAndFollowUpInterceptor);
interceptors.add(new BridgeInterceptor(client.cookieJar()));
interceptors.add(new CacheInterceptor(client.internalCache()));
interceptors.add(new ConnectInterceptor(client));
if (!forWebSocket) {
interceptors.addAll(client.networkInterceptors());
}
interceptors.add(new CallServerInterceptor(forWebSocket));
Interceptor.Chain chain = new RealInterceptorChain(
interceptors, null, null, null, 0, originalRequest);
return chain.proceed(originalRequest);
}
根据源码可知,一共七个拦截器:
-
addInterceptor(Interceptor),这是由开发者设置的,会按照开发者的要求,在所有的拦截器处理之前进行最早的拦截处理,比如一些公共参数,Header都可以在这里添加。 -
RetryAndFollowUpInterceptor,这里会对连接做一些初始化工作,以及请求失败的充实工作,重定向的后续请求工作。跟他的名字一样,就是做重试工作还有一些连接跟踪工作。 -
BridgeInterceptor,这里会为用户构建一个能够进行网络访问的请求,同时后续工作将网络请求回来的响应Response转化为用户可用的Response,比如添加文件类型,content-length计算添加,gzip解包。 -
CacheInterceptor,这里主要是处理cache相关处理,会根据OkHttpClient对象的配置以及缓存策略对请求值进行缓存,而且如果本地有了可⽤的Cache,就可以在没有网络交互的情况下就返回缓存结果。 -
ConnectInterceptor,这里主要就是负责建立连接了,会建立TCP连接或者TLS连接,以及负责编码解码的HttpCodec -
networkInterceptors,这里也是开发者自己设置的,所以本质上和第一个拦截器差不多,但是由于位置不同,所以用处也不同。这个位置添加的拦截器可以看到请求和响应的数据了,所以可以做一些网络调试。 -
CallServerInterceptor,这里就是进行网络数据的请求和响应了,也就是实际的网络I/O操作,通过socket读写数据。
OkHttp怎么实现连接池
- 为什么需要连接池?
频繁的进行建立Sokcet连接和断开Socket是非常消耗网络资源和浪费时间的,所以HTTP中的keepalive连接对于降低延迟和提升速度有非常重要的作用。keepalive机制是什么呢?也就是可以在一次TCP连接中可以持续发送多份数据而不会断开连接。所以连接的多次使用,也就是复用就变得格外重要了,而复用连接就需要对连接进行管理,于是就有了连接池的概念。
OkHttp中使用ConectionPool实现连接池,默认支持5个并发KeepAlive,默认链路生命为5分钟。
- 怎么实现的?
1)首先,ConectionPool中维护了一个双端队列Deque,也就是两端都可以进出的队列,用来存储连接。
2)然后在ConnectInterceptor,也就是负责建立连接的拦截器中,首先会找可用连接,也就是从连接池中去获取连接,具体的就是会调用到ConectionPool的get方法。
RealConnection get(Address address, StreamAllocation streamAllocation, Route route) {
assert (Thread.holdsLock(this));
for (RealConnection connection : connections) {
if (connection.isEligible(address, route)) {
streamAllocation.acquire(connection, true);
return connection;
}
}
return null;
}
也就是遍历了双端队列,如果连接有效,就会调用acquire方法计数并返回这个连接。
3)如果没找到可用连接,就会创建新连接,并会把这个建立的连接加入到双端队列中,同时开始运行线程池中的线程,其实就是调用了ConectionPool的put方法。
public final class ConnectionPool {
void put(RealConnection connection) {
if (!cleanupRunning) {
//没有连接的时候调用
cleanupRunning = true;
executor.execute(cleanupRunnable);
}
connections.add(connection);
}
}
3)其实这个线程池中只有一个线程,是用来清理连接的,也就是上述的cleanupRunnable
private final Runnable cleanupRunnable = new Runnable() {
@Override
public void run() {
while (true) {
//执行清理,并返回下次需要清理的时间。
long waitNanos = cleanup(System.nanoTime());
if (waitNanos == -1) return;
if (waitNanos > 0) {
long waitMillis = waitNanos / 1000000L;
waitNanos -= (waitMillis * 1000000L);
synchronized (ConnectionPool.this) {
//在timeout时间内释放锁
try {
ConnectionPool.this.wait(waitMillis, (int) waitNanos);
} catch (InterruptedException ignored) {
}
}
}
}
}
};
这个runnable会不停的调用cleanup方法清理线程池,并返回下一次清理的时间间隔,然后进入wait等待。
怎么清理的呢?看看源码:
long cleanup(long now) {
synchronized (this) {
//遍历连接
for (Iterator i = connections.iterator(); i.hasNext(); ) {
RealConnection connection = i.next();
//检查连接是否是空闲状态,
//不是,则inUseConnectionCount + 1
//是 ,则idleConnectionCount + 1
if (pruneAndGetAllocationCount(connection, now) > 0) {
inUseConnectionCount++;
continue;
}
idleConnectionCount++;
// If the connection is ready to be evicted, we're done.
long idleDurationNs = now - connection.idleAtNanos;
if (idleDurationNs > longestIdleDurationNs) {
longestIdleDurationNs = idleDurationNs;
longestIdleConnection = connection;
}
}
//如果超过keepAliveDurationNs或maxIdleConnections,
//从双端队列connections中移除
if (longestIdleDurationNs >= this.keepAliveDurationNs
|| idleConnectionCount > this.maxIdleConnections) {
connections.remove(longestIdleConnection);
} else if (idleConnectionCount > 0) { //如果空闲连接次数>0,返回将要到期的时间
// A connection will be ready to evict soon.
return keepAliveDurationNs - longestIdleDurationNs;
} else if (inUseConnectionCount > 0) {
// 连接依然在使用中,返回保持连接的周期5分钟
return keepAliveDurationNs;
} else {
// No connections, idle or in use.
cleanupRunning = false;
return -1;
}
}
closeQuietly(longestIdleConnection.socket());
// Cleanup again immediately.
return 0;
}
也就是当如果空闲连接maxIdleConnections超过5个或者keepalive时间大于5分钟,则将该连接清理掉。
4)这里有个问题,怎样属于空闲连接?
其实就是有关刚才说到的一个方法acquire计数方法:
public void acquire(RealConnection connection, boolean reportedAcquired) {
assert (Thread.holdsLock(connectionPool));
if (this.connection != null) throw new IllegalStateException();
this.connection = connection;
this.reportedAcquired = reportedAcquired;
connection.allocations.add(new StreamAllocationReference(this, callStackTrace));
}
在RealConnection中,有一个StreamAllocation虚引用列表allocations。每创建一个连接,就会把连接对应的StreamAllocationReference添加进该列表中,如果连接关闭以后就将该对象移除。
5)连接池的工作就这么多,并不负责,主要就是管理双端队列Deque,可以用的连接就直接用,然后定期清理连接,同时通过对StreamAllocation的引用计数实现自动回收。
OkHttp里面用到了什么设计模式
- 责任链模式
这个不要太明显,可以说是okhttp的精髓所在了,主要体现就是拦截器的使用,具体代码可以看看上述的拦截器介绍。
- 建造者模式
在Okhttp中,建造者模式也是用的挺多的,主要用处是将对象的创建与表示相分离,用Builder组装各项配置。
比如Request:
public class Request {
public static class Builder {
@Nullable HttpUrl url;
String method;
Headers.Builder headers;
@Nullable RequestBody body;
public Request build() {
return new Request(this);
}
}
}
- 工厂模式
工厂模式和建造者模式类似,区别就在于工厂模式侧重点在于对象的生成过程,而建造者模式主要是侧重对象的各个参数配置。
例子有CacheInterceptor拦截器中又个CacheStrategy对象:
CacheStrategy strategy = new CacheStrategy.Factory(now, chain.request(), cacheCandidate).get();
public Factory(long nowMillis, Request request, Response cacheResponse) {
this.nowMillis = nowMillis;
this.request = request;
this.cacheResponse = cacheResponse;
if (cacheResponse != null) {
this.sentRequestMillis = cacheResponse.sentRequestAtMillis();
this.receivedResponseMillis = cacheResponse.receivedResponseAtMillis();
Headers headers = cacheResponse.headers();
for (int i = 0, size = headers.size(); i < size; i++) {
String fieldName = headers.name(i);
String value = headers.value(i);
if ("Date".equalsIgnoreCase(fieldName)) {
servedDate = HttpDate.parse(value);
servedDateString = value;
} else if ("Expires".equalsIgnoreCase(fieldName)) {
expires = HttpDate.parse(value);
} else if ("Last-Modified".equalsIgnoreCase(fieldName)) {
lastModified = HttpDate.parse(value);
lastModifiedString = value;
} else if ("ETag".equalsIgnoreCase(fieldName)) {
etag = value;
} else if ("Age".equalsIgnoreCase(fieldName)) {
ageSeconds = HttpHeaders.parseSeconds(value, -1);
}
}
}
}
- 观察者模式
之前我写过一篇文章,是关于Okhttp中websocket的使用,由于webSocket属于长连接,所以需要进行监听,这里是用到了观察者模式:
final WebSocketListener listener;
@Override public void onReadMessage(String text) throws IOException {
listener.onMessage(this, text);
}
- 单例模式
这个就不举例了,每个项目都会有
- 另外有的博客还说到了策略模式,门面模式等,这些大家可以网上搜搜,毕竟每个人的想法看法都会不同,细心找找可能就会发现。
介绍一下你们之前做的项目的架构
这个问题大家就真实回答就好,重点是要说完后提出对自己项目架构的认同或不认同的观点,也就是要有自己的思考和想法。
MVP,MVVM,MVC 区别
MVC
- 架构介绍
Model:数据模型,比如我们从数据库或者网络获取数据
View:视图,也就是我们的xml布局文件
Controller:控制器,也就是我们的Activity
- 模型联系
View --> Controller,也就是反应View的一些用户事件(点击触摸事件)到Activity上。
Controller --> Model, 也就是Activity去读写一些我们需要的数据。
Controller --> View, 也就是Activity在获取数据之后,将更新内容反映到View上。
这样一个完整的项目架构就出来了,也是我们早期进行开发比较常用的项目架构。
- 优缺点
这种缺点还是比较明显的,主要表现就是我们的Activity太重了,经常一写就是几百上千行了。
造成这种问题的原因就是Controller层和View层的关系太过紧密,也就是Activity中有太多操作View的代码了。
但是!但是!其实Android这种并称不上传统的MVC结构,因为Activity又可以叫View层又可以叫Controller层,所以我觉得这种Android默认的开发结构,其实称不上什么MVC项目架构,因为他本身就是Android一开始默认的开发形式,所有东西都往Activity中丢,然后能封装的封装一下,根本分不出来这些层级。当然这是我个人看法,可以都来讨论下。
MVP
- 架构介绍
之前不就是因为Activity中有操作view,又做Controller工作吗。
所以其实MVP架构就是从原来的Activity层把view和Controller区分开,单独抽出来一层Presenter作为原来Controller的职位。
然后最后演化成,将View层写成接口的形式,然后Activity去实现View接口,最后在Presenter类中去实现方法。
Model:数据模型,比如我们从数据库或者网络获取数据。
View:视图,也就是我们的xml布局文件和Activity。
Presenter:主持人,单独的类,只做调度工作。
- 模型联系
View --> Presenter,反应View的一些用户事件到Presenter上。
Presenter --> Model, Presenter去读写操作一些我们需要的数据。
Controller --> View, Presenter在获取数据之后,将更新内容反馈给Activity,进行view更新。
- 优缺点
这种的优点就是确实大大减少了Activity的负担,让Activity主要承担一个更新View的工作,然后把跟Model交互的工作转移给了Presenter,从而由Presenter方来控制和交互Model方以及View方。所以让项目更加明确简单,顺序性思维开发。
缺点也很明显:
首先就是代码量大大增加了,每个页面或者说功能点,都要专门写一个Presenter类,并且由于是面向接口编程,需要增加大量接口,会有大量繁琐的回调。
其次,由于Presenter里持有了Activity对象,所以可能会导致内存泄漏或者view空指针,这也是需要注意的地方。
MVVM
- 架构介绍
MVVM的特点就是双向绑定,并且有Google官方加持,更新了Jetpack中很多架构组件,比如ViewModel,Livedata,DataBinding等等,所以这个是现在的主流框架和官方推崇的框架。
Model:数据模型,比如我们从数据库或者网络获取数据。
View:视图,也就是我们的xml布局文件和Activity。
ViewModel:关联层,将Model和View绑定,使他们之间可以相互绑定实时更新
- 模型联系
View --> ViewModel -->View,双向绑定,数据改动可以反映到界面,界面的修改可以反映到数据。
ViewModel --> Model, 操作一些我们需要的数据。
- 优缺点
优点就是官方大力支持,所以也更新了很多相关库,让MVVM架构更强更好用,而且双向绑定的特点可以让我们省去很多View和Model的交互。也基本解决了上面两个架构的问题。
具体说说你理解的MVVM
1)先说说MVVM是怎么解决了其他两个架构所在的缺陷和问题:
解决了各个层级之间耦合度太高的问题,也就是更好的完成了解耦。MVP层中,Presenter还是会持有View的引用,但是在MVVM中,View和Model进行双向绑定,从而使viewModel基本只需要处理业务逻辑,无需关系界面相关的元素了。解决了代码量太多,或者模式化代码太多的问题。由于双向绑定,所以UI相关的代码就少了很多,这也是代码量少的关键。而这其中起到比较关键的组件就是DataBinding,使所有的UI变动都交给了被观察的数据模型。解决了可能会有的内存泄漏问题。MVVM架构组件中有一个组件是LiveData,它具有生命周期感知能力,可以感知到Activity等的生命周期,所以就可以在其关联的生命周期遭到销毁后自行清理,就大大减少了内存泄漏问题。解决了因为Activity停止而导致的View空指针问题。在MVVM中使用了LiveData,那么在需要更新View的时候,如果观察者的生命周期处于非活跃状态(如返回栈中的 Activity),则它不会接收任何 LiveData 事件。也就是他会保证在界面可见的时候才会进行响应,这样就解决了空指针问题。解决了生命周期管理问题。这主要得益于Lifecycle组件,它使得一些控件可以对生命周期进行观察,就能随时随地进行生命周期事件。
2)再说说响应式编程
响应式编程,说白了就是我先构建好事物之间的关系,然后就可以不用管了。他们之间会因为这层关系而互相驱动。
其实也就是我们常说的观察者模式,或者说订阅发布模式。
为什么说这个呢,因为MVVM的本质思想就是类似这种。不管是双向绑定,还是生命周期感知,其实都是一种观察者模式,使所有事物变得可观察,那么我们只需要把这种观察关系给稳定住,那么项目也就稳健了。
3)最后再说说MVVM为什么这么强大?
我个人觉得,MVVM强大不是因为这个架构本身,而是因为这种响应式编程的优势比较大,再加上Google官方的大力支持,出了这么多支持的组件,来维系MVVM架构,其实也是官方想进行项目架构的统一。
优秀的架构思想+官方支持=强大
ViewModel 是什么,说说你所理解的ViewModel?
如果看过我上一篇文章的小伙伴应该都有所了解,ViewModel是MVVM架构的一个层级,用来联系View和model之间的关系。而我们今天要说的就是官方出的一个框架——ViewModel。
ViewModel 类旨在以注重生命周期的方式存储和管理界面相关的数据
官方是这么介绍的,这里面有两个信息:
- 注重生命周期的方式。
由于ViewModel的生命周期是作用于整个Activity的,所以就节省了一些关于状态维护的工作,最明显的就是对于屏幕旋转这种情况,以前对数据进行保存读取,而ViewModel则不需要,他可以自动保留数据。
其次,由于ViewModel在生命周期内会保持局部单例,所以可以更方便Activity的多个Fragment之间通信,因为他们能获取到同一个ViewModel实例,也就是数据状态可以共享了。
- 存储和管理界面相关的数据。
ViewModel层的根本职责,就是负责维护界面上UI的状态,其实就是维护对应的数据,因为数据会最终体现到UI界面上。所以ViewModel层其实就是对界面相关的数据进行管理,存储等操作。
ViewModel 为什么被设计出来,解决了什么问题?
- 在
ViewModel组件被设计出来之前,MVVM又是怎么实现ViewModel这一层级的呢?
其实就是自己编写类,然后通过接口,内部依赖实现View和数据的双向绑定。
所以Google出这个ViewModel组件,无非就是为了规范MVVM架构的实现,并尽量让ViewModel这一层级只触及到业务代码,不去关心VIew层级的引用等。然后配合其他的组件,包括livedata,databindingrang等让MVVM架构更加完善,规范,健硕。
- 解决了什么问题呢?
其实上面已经说过一些了,比如:
1)不会因为屏幕旋转而销毁,减少了维护状态的工作
2)由于在作用域内单一实例的特性,使得多个fragment之间可以方便通信,并且维护同一个数据状态。
3)完善了MVVM架构,使得解耦更加纯粹。
说说ViewModel原理。
- 首先说说是怎么保存生命周期
ViewModel2.0之前呢,其实原理是在Activity上add一个HolderFragment,然后设置setRetainInstance(true)方法就能让这个Fragment在Activity重建时存活下来,也就保证了ViewModel的状态不会随Activity的状态所改变。
2.0之后,其实是用到了Activity的onRetainNonConfigurationInstance()和getLastNonConfigurationInstance()这两个方法,相当于在横竖屏切的时候会保存ViewModel的实例,然后恢复,所以也就保证了ViewModel的数据。
- 再说说怎么保证作用域内唯一实例
首先,ViewModel的实例是通过反射获取的,反射的时候带上application的上下文,这样就保证了不会持有Activity或者Fragment等View的引用。然后实例创建出来会保存到一个ViewModelStore容器里面,其实也就是一个集合类,这个ViewModelStore 类其实就是保存在界面上的那个实例,而我们的ViewModel就是里面的一个集合类的子元素。
所以我们每次获取的时候,首先看看这个集合里面有无我们的ViewModel,如果没有就去实例化,如果有就直接拿到实例使用,这样就保证了唯一实例。最后在界面销毁的时候,会去执行ViewModelStore的clear方法,去清除集合里面的ViewModel数据。一小段代码说明下:
public T get(Class modelClass) {
// 先从ViewModelStore容器中去找是否存在ViewModel的实例
ViewModel viewModel = mViewModelStore.get(key);
// 若ViewModel已经存在,就直接返回
if (modelClass.isInstance(viewModel)) {
return (T) viewModel;
}
// 若不存在,再通过反射的方式实例化ViewModel,并存储进ViewModelStore
viewModel = modelClass.getConstructor(Application.class).newInstance(mApplication);
mViewModelStore.put(key, viewModel);
return (T) viewModel;
}
public class ViewModelStore {
private final HashMap mMap = new HashMap<>();
public final void clear() {
for (ViewModel vm : mMap.values()) {
vm.onCleared();
}
mMap.clear();
}
}
@Override
protected void onDestroy() {
super.onDestroy();
if (mViewModelStore != null && !isChangingConfigurations()) {
mViewModelStore.clear();
}
}
ViewModel怎么实现自动处理生命周期?为什么在旋转屏幕后不会丢失状态?为什么ViewModel可以跟随Activity/Fragment的生命周期而又不会造成内存泄漏呢?
这三个问题很类似,都是关于生命周期的问题,其实也就是问为什么ViewModel能管理生命周期,并且不会因为重建等情况造成影响。
- ViewModel2.0之前
利用一个无view 的HolderFragment来维持它的生命周期,我们知道ViewModel实例是存储到一个ViewModelStore容器里的,那么这个空的fragment就可以用来管理这个容器,只要Activity处于活动状态,HolderFragment也就不会被销毁,就保证了ViewModel的生命周期。
而且设置setRetainInstance(true)方法可以保证configchange时的生命周期不被改变,让这个Fragment在Activity重建时存活下来。总结来说就是用一个空的fragment来管理维护ViewModelStore,然后对应的activity销毁的时候就去把viewmodel的映射删除。就让ViewModel的生命周期保持和Activity一样了。这也是很多三方库用到的巧妙方法,比如Glide,也是建立空的Fragment来管理。
- 2.0之后,有了androidx支持
其实是用到了Activity的一个子类ComponentActivity,然后重写了onRetainNonConfigurationInstance()方法保存ViewModelStore,并在需要的时候,也就是重建的Activity中去通过getLastNonConfigurationInstance()方法获取到ViewModelStore实例。这样也就保证了ViewModelStore中的ViewModel不会随Activity的重建而改变。
同时由于实现了LifecycleOwner接口,所以能利用Lifecycles组件组件感知每个页面的生命周期,就可以通过它来订阅当Activity销毁时,且不是因为配置导致的destory情况下,去清除ViewModel,也就是调用ViewModelStore的clear方法。
getLifecycle().addObserver(new LifecycleEventObserver() {
@Override
public void onStateChanged(@NonNull LifecycleOwner source,
@NonNull Lifecycle.Event event) {
if (event == Lifecycle.Event.ON_DESTROY) {
// 判断是否因为配置更改导致的destroy
if (!isChangingConfigurations()) {
getViewModelStore().clear();
}
}
}
});
这里的onRetainNonConfigurationInstance方法再说下,是会在Activity因为配置改变而被销毁时被调用,跟onSaveInstanceState方法调用时机比较相像,不同的是onSaveInstanceState保存的是Bundle,Bundle是有类型限制和大小限制的,而且需要在主线程进行序列号。而onRetainNonConfigurationInstance方法都没有限制,所以更倾向于用它。
所以,到这里,第三个问题应该也可以回答了,2.0之前呢,都是通过他们创建了一个空的fragment,然后跟随这个fragment的生命周期。2.0之后呢,是因为不管是Activity或者Fragment,都实现了LifecycleOwner接口,所以ViewModel是可以通过Lifecycles感知到他们的生命周期,从而进行实例管理的。
ViewModelScope了解吗
这里主要就是考ViewModel和其他一些组件的关系了。关于协程,之前也专门说过一篇,主要用作线程切换。如果在多个协程中,需要停止某些任务,就必须对这些协程进行管理,一般是加入一个CoroutineScope,如果需要取消协程,就可以去取消这个CoroutineScope,他所跟踪的所有协程都会被取消。
GlobalScope.launch {
longRunningFunction()
anotherLongRunningFunction()
}
但是这种全局使用方法,是不被推荐使用的,如果要限定作用域的时候,一般推荐viewModelScope。
viewModelScope 是一个 ViewModel 的 Kotlin 扩展属性。它能在ViewModel销毁时 (onCleared() 方法调用时) 退出。所以只要使用了 ViewModel,就可以使用 viewModelScope在 ViewModel 中启动各种协程,而不用担心任务泄漏。
class MyViewModel() : ViewModel() {
fun initialize() {
viewModelScope.launch {
processBitmap()
}
}
suspend fun processBitmap() = withContext(Dispatchers.Default) {
// 在这里做耗时操作
}
}
LiveData 是什么?
LiveData 是一种可观察的数据存储器类。与常规的可观察类不同,LiveData 具有生命周期感知能力,意指它遵循其他应用组件(如 Activity、Fragment 或 Service)的生命周期。这种感知能力可确保 LiveData 仅更新处于活跃生命周期状态的应用组件观察者。
官方介绍如下,其实说的比较清楚了,主要作用在两点:
数据存储器类。也就是一个用来存储数据的类。可观察。这个数据存储类是可以观察的,也就是比一般的数据存储类多了这么一个功能,对于数据的变动能进行响应。
主要思想就是用到了观察者模式思想,让观察者和被观察者解耦,同时还能感知到数据的变化,所以一般被用到ViewModel中,ViewModel负责触发数据的更新,更新会通知到LiveData,然后LiveData再通知活跃状态的观察者。
var liveData = MutableLiveData()
liveData.observe(this, object : Observer {
override fun onChanged(t: String?) {
}
})
liveData.setVaile("xixi")
//子线程调用
liveData.postValue("test")
LiveData 为什么被设计出来,解决了什么问题?
LiveData作为一种观察者模式设计思想,常常被和Rxjava一起比较,观察者模式的最大好处就是事件发射的上游 和 接收事件的下游 互不干涉,大幅降低了互相持有的依赖关系所带来的强耦合性。
其次,LiveData还能无缝衔接到MVVM架构中,主要体现在其可以感知到Activity等生命周期,这样就带来了很多好处:
不会发生内存泄漏
观察者会绑定到Lifecycle对象,并在其关联的生命周期遭到销毁后进行自我清理。不会因 Activity 停止而导致崩溃
如果观察者的生命周期处于非活跃状态(如返回栈中的 Activity),则它不会接收任何 LiveData 事件。自动判断生命周期并回调方法
如果观察者的生命周期处于STARTED或RESUMED状态,则 LiveData 会认为该观察者处于活跃状态,就会调用onActive方法,否则,如果 LiveData 对象没有任何活跃观察者时,会调用onInactive()方法。
说说LiveData原理。
说到原理,其实就是两个方法:
- 订阅方法,也就是
observe方法。通过该方法把订阅者和被观察者关联起来,形成观察者模式。
简单看看源码:
@MainThread
public void observe(@NonNull LifecycleOwner owner, @NonNull Observer observer) {
assertMainThread("observe");
//...
LifecycleBoundObserver wrapper = new LifecycleBoundObserver(owner, observer);
ObserverWrapper existing = mObservers.putIfAbsent(observer, wrapper);
if (existing != null && !existing.isAttachedTo(owner)) {
throw new IllegalArgumentException("Cannot add the same observer"
+ " with different lifecycles");
}
if (existing != null) {
return;
}
owner.getLifecycle().addObserver(wrapper);
}
public V putIfAbsent(@NonNull K key, @NonNull V v) {
Entry entry = get(key);
if (entry != null) {
return entry.mValue;
}
put(key, v);
return null;
}
这里putIfAbsent方法是讲生命周期相关的wrapper和观察者observer作为key和value存到了mObservers中。
- 回调方法,也就是
onChanged方法。通过改变存储值,来通知到观察者也就是调用onChanged方法。从改变存储值方法setValue看起:
@MainThread
protected void setValue(T value) {
assertMainThread("setValue");
mVersion++;
mData = value;
dispatchingValue(null);
}
private void dispatchingValue(@Nullable ObserverWrapper initiator) {
//...
do {
mDispatchInvalidated = false;
if (initiator != null) {
considerNotify(initiator);
initiator = null;
} else {
for (Iterator, ObserverWrapper>> iterator =
mObservers.iteratorWithAdditions(); iterator.hasNext(); ) {
considerNotify(iterator.next().getValue());
if (mDispatchInvalidated) {
break;
}
}
}
} while (mDispatchInvalidated);
mDispatchingValue = false;
}
private void considerNotify(ObserverWrapper observer) {
if (!observer.mActive) {
return;
}
// Check latest state b4 dispatch. Maybe it changed state but we didn't get the event yet.
//
// we still first check observer.active to keep it as the entrance for events. So even if
// the observer moved to an active state, if we've not received that event, we better not
// notify for a more predictable notification order.
if (!observer.shouldBeActive()) {
observer.activeStateChanged(false);
return;
}
if (observer.mLastVersion >= mVersion) {
return;
}
observer.mLastVersion = mVersion;
//noinspection unchecked
observer.mObserver.onChanged((T) mData);
}
这一套下来逻辑还是比较简单的,遍历刚才的map——mObservers,然后找到观察者observer,如果观察者不在活跃状态(活跃状态,也就是可见状态,处于 STARTED 或 RESUMED状态),则直接返回,不去通知。否则正常通知到观察者的onChanged方法。
当然,如果想任何时候都能监听到,都能获取回调,调用observeForever方法即可。
依赖注入是啥?为什么需要她?
简单的说,依赖注入就是内部的类在外部实例化了。也就是不需要自己去做实例化工作了,而是交给外部容器来完成,最后注入到调用者这边,形成依赖注入。
举个例子:
Activity中有一个user类,正常情况下要使用这个user肯定是需要实例化它,不然他是个空值,但是用了依赖注入后,就不需要在Activity内部再去实例化,就可以直接使用它了。
@AndroidEntryPoint
class MainActivity : BaseActivity() {
@Inject
lateinit var user: User
}
这个user就可以直接使用了,是不是有点神奇,都不需要手动依赖了,当然代码没写完,后面再去完善。只是表达了这么一个意思,也就是依赖注入的含义。
那么这种由外部容器来实例化对象的方式到底有什么好处呢?最大的好处就是减少了手动依赖,对类进行了解耦。具体主要有以下几点:
- 依赖注入库会自动释放不再使用的对象,减少资源的过度使用。
- 在配置
scopes范围内,可重用依赖项和创建的实例,提高代码的可重用性,减少了很多模板代码。 - 代码变得更具可读性。
- 易于构建对象。
- 编写低耦合代码,更容易测试。
Hilt是啥,怎么用?
很明显,Hilt就是一个依赖注入库,一个封装了Dagger,在Dagger的基础上进行构建的一个依赖注入库。Dagger我们都知道是一个早期的依赖注入库,但确实不好用,需要配置很多东西,那么Hilt简单到哪了呢?我们继续完善上面的例子:
@HiltAndroidApp
public class MainApplication extends Application {
}
@AndroidEntryPoint
class HiltActivitiy : AppCompatActivity() {
@Inject
lateinit var user: UserData
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
showToast(user.name)
}
}
data class UserData(var name: String) {
@Inject
constructor() : this("bob")
}
说下几个注释的含义:
-
@HiltAndroidApp。所有使用Hilt的App必须包含一个使用 @HiltAndroidApp 注解的 Application,相当于Hilt的初始化,会触发Hilt代码的生成。 -
@AndroidEntryPoint。用于提供类的依赖,也就是代表这个类会用到注入的实例。 -
@Inject。这个注解是用来告诉 Hilt 如何提供该类的实例,它常用于构造函数、非私有字段、方法中。
Hilt支持哪些类的依赖注入。
1) 如果是 Hilt 支持的 Android组件,直接使用 @AndroidEntryPoint注解即可。比如Activity,Fragment,Service等等。
- 如果是
ComponentActivity的子类Activity,那么直接使用@AndroidEntryPoint就可以了,比如上面的例子。 - 如果是其他的Android类,必须在它依赖的Android类添加同样的注解,例如在 Fragment 中添加
@AndroidEntryPoint注解,必须在Fragment依赖的Activity上也添加@AndroidEntryPoint注解。
2)如果是需要注入第三方的依赖,可以使用@Module注解,使用 @Module注解的普通类,在其中创建第三方依赖的对象。比如获取okhttp的实例
@Module
@InstallIn(ApplicationComponent::class)
object NetworkModule {
/**
* @Provides
* @Singleton 提供单例
*/
@Provides
@Singleton
fun provideOkHttpClient(): OkHttpClient {
return OkHttpClient.Builder()
.build()
}
}
这里又有几个新的注解了:
-
@Module。用于创建依赖类的对象 -
@InstallIn。使用 @Module 注入的类,需要使用 @InstallIn 注解指定 module 的范围,例如使用 @InstallIn(ActivityComponent::class) 注解的 module 会绑定到 activity 的生命周期上。 -
@Provides。用于被 @Module注解标记类的内部的方法,并提供依赖项对象。 -
@Singleton。提供单例
3)为ViewModel提供的专门的注解
@ViewModelInject,在Viewmodel对象的构造函数中使用 @ViewModelInject 注解可以提供一个 ViewModel。
class HiltViewModel @ViewModelInject constructor() : ViewModel() {}
private val mHitViewModule: HiltViewModel by viewModels()
说说DNS,以及存在的问题
之前看过我说的网络问题应该知道DNS用来做域名解析工作的,当输入一个域名后,需要把域名转化为IP地址,这个转换过程就是DNS解析。
但是传统的DSN解析会有一些问题,比如:
域名缓存问题
本地做一个缓存,直接返回缓存数据。可能会导致全局负载均衡失败,因为上次进行的缓存,不一定是这次离客户最近的地方,可能会绕远路。域名转发问题
如果是A运营商将解析的请求转发给B运营商,B去权威DNS服务器查询的话,权威服务器会认为你是B运营商的,就返回了B运营商的网站地址,结果每次都会跨运营商。出口NAT问题
做了网络地址转化后,权威的DNS服务器,没法通过地址来判断客户到底是哪个运营商,极有可能误判运营商,导致跨运营商访问。域名更新问题
本地DNS服务器是由不同地区,不同运营商独立部署的,对域名解析缓存的处理上,有区别,有的会偷懒忽略解析结果TTL的时间限制,导致服务器没有更新新的ip而是指向旧的ip。解析延迟
DNS的查询过程需要递归遍历多个DNS服务器,才能获得最终结果。可能会带来一定的延时。域名劫持
DNS域名解析服务器有可能会被劫持,或者被伪造,那么正常的访问就会被解析到错误的地址。不可靠
由于DNS解析是运行在UDP协议之上的,而UDP我之前也说过是一种不可靠的协议,他的优势在于实时性,但是有丢包的可能。
这些问题不仅会让访问速度变慢,还有可能会导致访问异常,访问页面被替换等等。
怎么优化DNS解析
- 安全优化
总之DNS还是会有各种问题吧,怎么解决呢?就是用HTTPDNS。
HTTPDNS是一个新概念,他会绕过传统的运营商DNS服务器,不走传统的DNS解析。而是换成HTTP协议,直接通过HTTP协议进行请求某个DNS服务器集群,获取地址。
- 由于绕过了
运营商,所以可以避免域名被劫持。 - 它是基于访问的
来源ip,所以能获得更准确的解析结果 - 会有
预解析,解析缓存等功能,所以解析延迟也很小
所以首先的优化,针对安全方面,就是要替换成HTTPDNS解析方式,就要借用阿里云和腾讯云等服务,但是这些服务可不是免费的,有没有免费的呢?有的,七牛云的 happy-dns。添加依赖库,然后去实现okhttp的DNS接口即可,简单写个例子:
//导入库
implementation 'com.qiniu:happy-dns:0.2.13'
implementation 'com.qiniu.pili:pili-android-qos:0.8'
//实现DNS接口
public class HttpDns implements Dns {
private DnsManager dnsManager;
public HttpDns() {
IResolver[] resolvers = new IResolver[1];
try {
resolvers[0] = new Resolver(InetAddress.getByName("119.29.29.29"));
dnsManager = new DnsManager(NetworkInfo.normal, resolvers);
} catch (UnknownHostException e) {
e.printStackTrace();
}
}
@Override
public List lookup(String hostname) throws UnknownHostException {
if (dnsManager == null) //当构造失败时使用默认解析方式
return Dns.SYSTEM.lookup(hostname);
try {
String[] ips = dnsManager.query(hostname); //获取HttpDNS解析结果
if (ips == null || ips.length == 0) {
return Dns.SYSTEM.lookup(hostname);
}
List result = new ArrayList<>();
for (String ip : ips) { //将ip地址数组转换成所需要的对象列表
result.addAll(Arrays.asList(InetAddress.getAllByName(ip)));
}
//在返回result之前,我们可以添加一些其他自己知道的IP
return result;
} catch (IOException e) {
e.printStackTrace();
}
//当有异常发生时,使用默认解析
return Dns.SYSTEM.lookup(hostname);
}
}
//替换okhttp的dns解析
OkHttpClient okHttpClient = new OkHttpClient.Builder().dns(new HttpDns()).build();
- 速度优化
如果在测试环境,其实我们可以直接配置ip白名单,然后跳过DNS解析流程,直接获取ip地址。比如:
private static class TestDNS implements Dns{
@Override
public List lookup(@NotNull String hostname) throws UnknownHostException {
if ("www.test.com".equalsIgnoreCase(hostname)){
InetAddress byAddress=InetAddress.getByAddress(hostname,new byte[]{(byte)192,(byte)168,1,1});
return Collections.singletonList(byAddress);
}else {
return Dns.SYSTEM.lookup(hostname);
}
}
}
DNS解析超时怎么办
当我们在用OKHttp做网络请求时,如果网络设备切换路由,访问网络出现长时间无响应,很久之后会抛出 UnknownHostException。虽然我们在OkHttp中设置了connectTimeout超时时间,但是它其实对DNS的解析是不起作用的。
这种情况我们就需要在自定义的Dns类中做超时判断:
public class TimeDns implements Dns {
private long timeout;
public TimeDns(long timeout) {
this.timeout = timeout;
}
@Override
public List lookup(final String hostname) throws UnknownHostException {
if (hostname == null) {
throw new UnknownHostException("hostname == null");
} else {
try {
FutureTask> task = new FutureTask<>(
new Callable>() {
@Override
public List call() throws Exception {
return Arrays.asList(InetAddress.getAllByName(hostname));
}
});
new Thread(task).start();
return task.get(timeout, TimeUnit.MILLISECONDS);
} catch (Exception var4) {
UnknownHostException unknownHostException =
new UnknownHostException("Broken system behaviour for dns lookup of " + hostname);
unknownHostException.initCause(var4);
throw unknownHostException;
}
}
}
}
//替换okhttp的dns解析
OkHttpClient okHttpClient = new OkHttpClient.Builder().dns(new TimeDns(5000)).build();
注解是什么?有哪些元注解
注解,在我看来它是一种信息描述,不影响代码执行,但是可以用来配置一些代码或者功能。
常见的注解比如@Override,代表重写方法,看看它是怎么生成的:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.SOURCE)
public @interface Override {
}
可以看到Override被@interface所修饰,代表注解,同时上方还有两个注解@Target和@Retention,这种修饰注解的注解叫做元注解,很好理解吧,就是最基本的注解呗。java中一共有四个元注解:
-
@Target:表示注解对象的作用范围。 -
@Retention:表示注解保留的生命周期 -
@Inherited:表示注解类型能被类自动继承。 -
@Documented:表示含有该注解类型的元素(带有注释的)会通过javadoc或类似工具进行文档化。
具体说下这几个元注解都是怎么用的
- @Target
target,表示注解对象的作用范围,比如Override注解所标示的就是ElementType.METHOD,即所作用的范围是方法范围,也就是只能在方法头上加这个注解。另外还有以下几个修饰范围参数:
-
TYPE:类、接口、枚举、注解类型。 -
FIELD:类成员(构造方法、方法、成员变量)。 -
METHOD:方法。 -
PARAMETER:参数。 -
CONSTRUCTOR:构造器。 -
LOCAL_VARIABLE:局部变量。 -
ANNOTATION_TYPE:注解。 -
PACKAGE:包声明。 -
TYPE_PARAMETER:类型参数。 -
TYPE_USE:类型使用声明。
比如ANNOTATION_TYPE就是表示该注解的作用范围就是注解,哈哈,有点绕吧,看看Target注解的代码:
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.ANNOTATION_TYPE)
public @interface Target {
/**
* @return an array of the kinds of elements an annotation type
* can be applied to
*/
ElementType[] value();
}
带了一个ElementType类型的参数,也就是上面说到的作用范围参数,另外还被Target注解修饰了,传的参数就是ANNOTATION_TYPE,也就是我注解我自己,我设置我自己的作用范围是注解。大家自己绕一下。。
- @Retention
表示注解保留的生命周期,或者说表示该注解所保留的时长,主要有以下几个可选参数:
-
SOURCE:仅存在Java源文件,经过编译器后便丢弃相应的注解。适用于一些检查性的操作,比如@Override。 -
CLASS:编译class文件时生效,存在Java源文件,以及经编译器后生成的Class字节码文件,但在运行时VM不再保留注释。这个也是默认的参数。适用于在编译时进行一些预处理操作,比如ButterKnife的@BindView,可以在编译时生成一些辅助的代码或者完成一些功能。 -
RUNTIME:存在源文件、编译生成的Class字节码文件,以及保留在运行时VM中,可通过反射性地读取注解。适用于一些需要运行时动态获取注解信息,类似反射获取注解等。
- @Inherited
表示注解类型能被类自动继承。这里需要注意两点:
类。也就是说只有在类集成关系中,子类才会集成父类使用的注解中被@Inherited所修饰的那个注解。其他的接口集成关系,类实现接口关系中,都不会存在自动继承注解。自动继承。也就是说如果父类有@Inherited所修饰的那个注解,那么子类不需要去写这个注解,就会自动有了这个注解。
还是看个例子:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Inherited
public @interface MyInheritedAnnotation {
//注解1,有Inherited注解修饰
}
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface MyAnnotation {
//注解2,没有Inherited注解修饰
}
@MyInheritedAnnotation
@MyAnnotation
public class BaseClass {
//父类,有以上两个注解
}
public class ExtendClass extends BaseClass {
//子类会继承父类的MyInheritedAnnotation注解,
//而不会继承MyAnnotation注解
}
- @Documented
表示拥有该注解的元素可通过javadoc此类的工具进行文档化,也就是说生成JavaAPI文档的时候会被写进文档中。
注解可以用来做什么
主要有以下几个用处:
- 降低项目的耦合度。
- 自动完成一些
规律性的代码。 - 自动生成
java代码,减轻开发者的工作量。
序列化指的是什么?有什么用
序列化指的是讲对象变成有序的字节流,变成字节流之后才能进行传输存储等一系列操作。
反序列化就是序列化的相反操作,也就是把序列化生成的字节流转为我们内存的对象。
介绍下Android中两种序列化接口
- Serializable
是Java提供的一个序列化接口,是一个空接口,专门为对象提供序列化和反序列化操作。具体使用如下:
public class User implements Serializable {
private static final long serialVersionUID=519067123721561165l;
private int id;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
}
实现Serializable接口,声明一个serialVersionUID。
到这里可能有人就问了,不对啊,平时没有这个serialVersionUID啊。没错,serialVersionUID不是必须的,因为不写的话,系统会自动生成这个变量。它有什么用呢?当序列化的时候,系统会把当前类的serialVersionUID写入序列化的文件中,当反序列化的时候会去检测这个serialVersionUID,看他是否和当前类的serialVersionUID一致,一样则可以正常反序列化,如果不一样就会报错了。
所以这个serialVersionUID就是序列化和反序列化过程中的一个标识,代表一致性。不加的话会有什么影响?如果我们序列化后,改动了这个类的某些成员变量,那么serialVersionUID就会改变,这时候再拿之前序列化的数据来反序列化就会报错。所以如果我们手动指定serialVersionUID就能保证最大限度来恢复数据。
- Parcelable
Android自带的接口,使用起来要麻烦很多:需要实现Parcelable接口,重写describeContents(),writeToParcel(Parcel dest, @WriteFlags int flags),并添加一个静态成员变量CREATOR并实现Parcelable.Creator接口
public class User implements Parcelable {
private int id;
protected User(Parcel in) {
id = in.readInt();
}
@Override
public void writeToParcel(Parcel dest, int flags) {
dest.writeInt(id);
}
@Override
public int describeContents() {
return 0;
}
public static final Creator CREATOR = new Creator() {
@Override
public User createFromParcel(Parcel in) {
return new User(in);
}
@Override
public User[] newArray(int size) {
return new User[size];
}
};
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
}
-
createFromParcel,User(Parcel in) ,代表从序列化的对象中创建原始对象 -
newArray,代表创建指定长度的原始对象数组 -
writeToParcel,代表将当前对象写入到序列化结构中。 -
describeContents,代表返回当前对象的内容描述。如果还有文件描述符,返回1,否则返回0。
两者有什么区别,该怎么使用选择
Serializable是Java提供的序列化接口,使用简单但是开销很大,序列化和反序列化过程都需要大量I/O操作。
Parcelable是Android中提供的,也是Android中推荐的序列化方式。虽然使用麻烦,但是效率很高。
所以,如果是内存序列化层面,那么还是建议Parcelable,因为他效率会比较高。
如果是网络传输和存储磁盘情况,就推荐Serializable,因为序列化方式比较简单,而且Parcelable不能保证,当外部条件发生变化时数据的连续性。
- Serializable
Serializable的实质其实是是把Java对象序列化为二进制文件,然后就能在进程之间传递,并且用于网络传输或者本地存储等一系列操作,因为他的本质就存储了文件。可以看看源码:
private void writeObject0(Object obj, boolean unshared)
throws IOException
{
...
try {
Object orig = obj;
Class cl = obj.getClass();
ObjectStreamClass desc;
desc = ObjectStreamClass.lookup(cl, true);
if (obj instanceof Class) {
writeClass((Class) obj, unshared);
} else if (obj instanceof ObjectStreamClass) {
writeClassDesc((ObjectStreamClass) obj, unshared);
// END Android-changed: Make Class and ObjectStreamClass replaceable.
} else if (obj instanceof String) {
writeString((String) obj, unshared);
} else if (cl.isArray()) {
writeArray(obj, desc, unshared);
} else if (obj instanceof Enum) {
writeEnum((Enum) obj, desc, unshared);
} else if (obj instanceof Serializable) {
writeOrdinaryObject(obj, desc, unshared);
} else {
if (extendedDebugInfo) {
throw new NotSerializableException(
cl.getName() + "\n" + debugInfoStack.toString());
} else {
throw new NotSerializableException(cl.getName());
}
}
}
...
}
private void writeOrdinaryObject(Object obj,
ObjectStreamClass desc,
boolean unshared)
throws IOException
{
...
try {
desc.checkSerialize();
//写入二进制文件,普通对象开头的魔数0x73
bout.writeByte(TC_OBJECT);
//写入对应的类的描述符,见底下源码
writeClassDesc(desc, false);
handles.assign(unshared ? null : obj);
if (desc.isExternalizable() && !desc.isProxy()) {
writeExternalData((Externalizable) obj);
} else {
writeSerialData(obj, desc);
}
} finally {
if (extendedDebugInfo) {
debugInfoStack.pop();
}
}
}
public long getSerialVersionUID() {
// 如果没有定义serialVersionUID,序列化机制就会调用一个函数根据类内部的属性等计算出一个hash值
if (suid == null) {
suid = AccessController.doPrivileged(
new PrivilegedAction() {
public Long run() {
return computeDefaultSUID(cl);
}
}
);
}
return suid.longValue();
}
可以看到是通过反射获取对象以及对象属性的相关信息,然后将数据写到了一个二进制文件,并且写入了序列化协议版本等等。
而获取·serialVersionUID·的逻辑也体现出来,如果id为空则会生成计算一个hash值。
- Parcelable
Parcelable的存储是通过Parcel存储到内存的,简单地说,Parcel提供了一套机制,可以将序列化之后的数据写入到一个共享内存中,其他进程通过Parcel可以从这块共享内存中读出字节流,并反序列化成对象。
这其中实际又是通过native方法实现的。具体逻辑我就没有去分析了,如果有大神朋友可以在评论区解析下。
当然,Parcelable也是可以持久化的,涉及到Parcel中的unmarshall和marshall方法。 这里简单贴一下代码:
protected void saveParce() {
FileOutputStream fos;
try {
fos = getApplicationContext().openFileOutput(TAG,
Context.MODE_PRIVATE);
BufferedOutputStream bos = new BufferedOutputStream(fos);
Parcel parcel = Parcel.obtain();
parcel.writeParcelable(new ParceData(), 0);
bos.write(parcel.marshall());
bos.flush();
bos.close();
fos.flush();
fos.close();
} catch (Exception e) {
e.printStackTrace();
}
}
protected void loadParce() {
FileInputStream fis;
try {
fis = getApplicationContext().openFileInput(TAG);
byte[] bytes = new byte[fis.available()];
fis.read(bytes);
Parcel parcel = Parcel.obtain();
parcel.unmarshall(bytes, 0, bytes.length);
parcel.setDataPosition(0);
ParceData data = parcel.readParcelable(ParceData.class.getClassLoader());
fis.close();
} catch (Exception e) {
e.printStackTrace();
}
}
序列化总结
1)对于内存序列化方面建议用Parcelable,为什么呢?
- 因为
Serializable是存储了一个二进制文件,所以会有频繁的IO操作,消耗也比较大,而且用到了大量反射,反射操作也是耗时的。相比之下Parcelable就要效率高很多。
2)对于数据持久化还是建议用Serializable,为什么呢?
- 首先,
Serializable本身就是存储到二进制文件,所以用于持久化比较方便。而Parcelable序列化是在内存中操作,如果进程关闭或者重启的时候,内存中的数据就会消失,那么Parcelable序列化用来持久化就有可能会失败,也就是数据不会连续完整。而且Parcelable还有一个问题是兼容性,每个Android版本可能内部实现都不一样,知识用于内存中也就是传递数据的话是不影响的,但是如果持久化可能就会有问题了,低版本的数据拿到高版本可能会出现兼容性问题。 所以还是建议用Serializable进行持久化。
3)Parcelable一定比Serializable快吗?
- 有个比较有趣的例子是:当序列化一个超级大的对象图表(表示通过一个对象,拥有通过某路径能访问到其他很多的对象),并且每个对象有10个以上属性时,并且
Serializable实现了writeObject()以及readObject(),在平均每台安卓设备上,Serializable序列化速度大于Parcelable3.6倍,反序列化速度大于1.6倍.
具体原因就是因为Serilazable的实现方式中,是有缓存的概念的,当一个对象被解析过后,将会缓存在HandleTable中,当下一次解析到同一种类型的对象后,便可以向二进制流中,写入对应的缓存索引即可。但是对于Parcel来说,没有这种概念,每一次的序列化都是独立的,每一个对象,都当作一种新的对象以及新的类型的方式来处理。
LruCache介绍
LruCache 是Android3.1提供的一个缓存类,用于数据缓存,一般用于图片的内存缓存。Lru的英文是Least Recently Used,也就是近期最少使用算法,核心思想是当缓存满时,会优先淘汰那些近期最少使用的缓存对象。
当我们进行网络加载图片的时候,肯定要对图片进行缓存,这样下次加载图片就可以直接从缓存中取。三级缓存大家应该都比较熟悉,内存,硬盘和网络。所以一般要进行内存缓存和硬盘缓存,其中内存缓存就是用的LruCache。
LruCache使用
public class MyImageLoader {
private LruCache mLruCache;
public MyImageLoader() {
int maxMemory = (int) (Runtime.getRuntime().maxMemory())/1024;
int cacheSize = maxMemory / 8;
mLruCache = new LruCache(cacheSize) {
@Override
protected int sizeOf(String key, Bitmap value) {
return value.getRowBytes()*value.getHeight()/1024;
}
};
}
/**
* 添加图片缓存
*/
public void addBitmap(String key, Bitmap bitmap) {
mLruCache.put(key, bitmap);
}
/**
* 从缓存中获取图片
*
*/
public Bitmap getBitmap(String key) {
return mLruCache.get(key);
}
}
使用方法如上,只需要提供缓存的总容量大小并重写sizeOf方法计算缓存对象大小即可。这里总容量的大小也是通用方法,即进程可用内存的1/8,单位kb。然后就可以使用put方法来添加缓存对象,get方法来获取缓存对象。
LruCache原理
原理其实也很简单,就是用到了LRU算法,内部使用LinkedHashMap 进行存储。在缓存满了之后,会将最近最少使用的元素移除。怎么保证找到这个最近最少的元素呢?就是每次使用get方法访问了元素或者增加了一个元素,就把元素移动到LinkedHashMap的尾部,这样第一个元素就是最不经常使用的元素,在容量满了之后就可以将它移除。
简单看看源码:
public LruCache(int maxSize) {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
this.maxSize = maxSize;
this.map = new LinkedHashMap(0, 0.75f, true);
}
public final V put(K key, V value) {
if (key == null || value == null) {
throw new NullPointerException("key == null || value == null");
}
V previous; //查找是否已经存在key对应的元素
synchronized (this) {
putCount++;
//计算entry的大小
size += safeSizeOf(key, value);
previous = map.put(key, value);
if (previous != null) {
//如果之前存在,这先减去之前那个entry所占用的内存大小
size -= safeSizeOf(key, previous);
}
}
if (previous != null) {
//如果之前存在则调用entryRemoved回调子类重写的此方法,做一些处理
entryRemoved(false, key, previous, value);
}
//根据最大的容量,计算是否需要淘汰掉最不常使用的entry
trimToSize(maxSize);
return previous;
}
public final V get(K key) {
if (key == null) {
throw new NullPointerException("key == null");
}
V mapValue;
//根据key来查询符合条件的etnry
synchronized (this) {
mapValue = map.get(key);
if (mapValue != null) {
hitCount++;
return mapValue;
}
missCount++;
}
/*
* Attempt to create a value. This may take a long time, and the map
* may be different when create() returns. If a conflicting value was
* added to the map while create() was working, we leave that value in
* the map and release the created value.
*/
V createdValue = create(key);
if (createdValue == null) {
return null;
}
synchronized (this) {
createCount++;
//mapValue返回的是已经存在相同key的entry
mapValue = map.put(key, createdValue);
if (mapValue != null) {
// There was a conflict so undo that last put
map.put(key, mapValue);
} else {
size += safeSizeOf(key, createdValue);
}
}
if (mapValue != null) {
entryRemoved(false, key, createdValue, mapValue);
return mapValue;
} else {
trimToSize(maxSize);
return createdValue;
}
}
其实可以看到,LruCache类本身做的事情不多,限定了缓存map的大小,然后利用了LinkHashMap完成了LRU的缓存策略。所以主要的实现LRU逻辑部分还是在LinkHashMap中。LinkedHashMap是hashmap和链表的结合体,通过链表来记录元素的顺序和链接关系,通过HashMap来存储数据,它可以控制元素的被遍历时候输出的顺序。他是一个双向链表,上面说过他会把最近访问的元素放到队列的尾部,有兴趣的可以看看LinkHashMap的源码。
Activity从创建到我们看到界面,发生了哪些事
- 首先是通过
setContentView加载布局,这其中创建了一个DecorView,然后根据然后根据activity设置的主题(theme)或者特征(Feature)加载不同的根布局文件,最后再通过inflate方法加载layoutResID资源文件,其实就是解析了xml文件,根据节点生成了View对象。流程图:

- 其次就是进行view绘制到界面上,这个过程发生在
handleResumeActivity方法中,也就是触发onResume的方法。在这里会创建一个ViewRootImpl对象,作为DecorView的parent然后对DecorView进行测量布局和绘制三大流程。流程图:
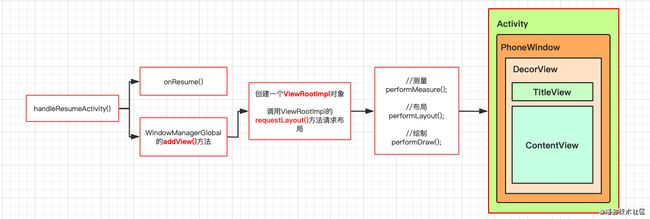
Activity、PhoneWindow、DecorView、ViewRootImpl 的关系?
PhoneWindow是Window 的唯一子类,每个Activity都会创建一个PhoneWindow对象,你可以理解它为一个窗口,但不是真正的可视窗口,而是一个管理类,是Activity和整个View系统交互的接口,是Activity和View交互系统的中间层。DecorView是PhoneWindow的一个内部类,是整个View层级的最顶层,一般包括标题栏和内容栏两部分,会根据不同的主题特性调整不同的布局。它是在setContentView方法中被创建,具体点来说是在PhoneWindow的installDecor方法中被创建。ViewRootImpl是DecorView的parent,用来控制View的各种事件,在handleResumeActivity方法中被创建。
requestLayout和invalidate
-
requestLayout方法是用来触发绘制流程,他会会一层层调用 parent 的requestLayout,一直到最上层也就是ViewRootImpl的requestLayout,这里也就是判断线程的地方了,最后会执行到performMeasure -> performLayout -> performDraw三个绘制流程,也就是测量——布局——绘制。
@Override
public void requestLayout() {
if (!mHandlingLayoutInLayoutRequest) {
checkThread();
mLayoutRequested = true;
scheduleTraversals();//执行绘制流程
}
}
其中performMeasure方法会执行到View的measure方法,用来测量大小。performLayout方法会执行到view的layout方法,用来计算位置。performDraw方法需要注意下,他会执行到view的draw方法,但是并不一定会进行绘制,只有只有 flag 被设置为 PFLAG_DIRTY_OPAQUE 才会进行绘制。
- invalidate方法也是用来触发绘制流程,主要表现就是会调用draw()方法。虽然他也会走到
scheduleTraversals方法,也就是会走到三大流程,但是View会通过mPrivateFlags来判断是否进行onMeasure和onLayout操作。而在用invalidate方法时,更新了mPrivateFlags,所以不会进行measure和layout。同时他也会设置Flag为PFLAG_DIRTY_OPAQUE,所以肯定会执行onDraw方法。
private void invalidateRectOnScreen(Rect dirty) {
final Rect localDirty = mDirty;
//...
if (!mWillDrawSoon && (intersected || mIsAnimating)) {
scheduleTraversals();//执行绘制流程
}
}
最后看一下scheduleTraversals方法中三大绘制流程逻辑,是不是我们之前说的那样,FORCE_LAYOUT标志才会onMeasure和onLayout,PFLAG_DIRTY_OPAQUE标志才会onDraw:
public final void measure(int widthMeasureSpec, int heightMeasureSpec) {
final boolean forceLayout = (mPrivateFlags & PFLAG_FORCE_LAYOUT) == PFLAG_FORCE_LAYOUT;
// 只有mPrivateFlags为PFLAG_FORCE_LAYOUT的时候才会进行onMeasure方法
if (forceLayout || needsLayout) {
onMeasure(widthMeasureSpec, heightMeasureSpec);
}
// 设置 LAYOUT_REQUIRED flag
mPrivateFlags |= PFLAG_LAYOUT_REQUIRED;
}
public void layout(int l, int t, int r, int b) {
...
//判断标记位为PFLAG_LAYOUT_REQUIRED的时候才进行onLayout方法
if (changed || (mPrivateFlags & PFLAG_LAYOUT_REQUIRED) == PFLAG_LAYOUT_REQUIRED) {
onLayout(changed, l, t, r, b);
}
}
public void draw(Canvas canvas) {
final int privateFlags = mPrivateFlags;
// flag 是 PFLAG_DIRTY_OPAQUE 则需要绘制
final boolean dirtyOpaque = (privateFlags & PFLAG_DIRTY_MASK) == PFLAG_DIRTY_OPAQUE &&
(mAttachInfo == null || !mAttachInfo.mIgnoreDirtyState);
mPrivateFlags = (privateFlags & ~PFLAG_DIRTY_MASK) | PFLAG_DRAWN;
if (!dirtyOpaque) {
drawBackground(canvas);
}
if (!dirtyOpaque) onDraw(canvas);
// 绘制 Child
dispatchDraw(canvas);
// foreground 不管 dirtyOpaque 标志,每次都会绘制
onDrawForeground(canvas);
}
参考文章中有一段总结挺好的:
虽然两者都是用来触发绘制流程,但是在measure和layout过程中,只会对 flag 设置为 FORCE_LAYOUT 的情况进行重新测量和布局,而draw方法中只会重绘flag为 dirty 的区域。requestLayout 是用来设置FORCE_LAYOUT标志,invalidate 用来设置 dirty 标志。所以 requestLayout 只会触发 measure 和 layout,invalidate 只会触发 draw。
系统为什么提供Handler
- 这点大家应该都知道一些,就是为了切换线程,主要就是为了解决在子线程无法访问UI的问题。
那么为什么系统不允许在子线程中访问UI呢?
- 因为
Android的UI控件不是线程安全的,所以采用单线程模型来处理UI操作,通过Handler切换UI访问的线程即可。
那么为什么不给UI控件加锁呢?
- 因为加锁会让
UI访问的逻辑变得复杂,而且会降低UI访问的效率,阻塞线程执行。
Handler是怎么获取到当前线程的Looper的
- 大家应该都知道
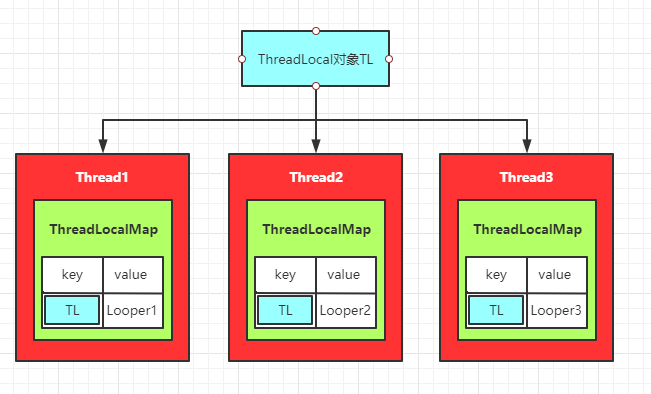
Looper是绑定到线程上的,他的作用域就是线程,而且不同线程具有不同的Looper,也就是要从不同的线程取出线程中的Looper对象,这里用到的就是ThreadLocal。
假设我们不知道有这个类,如果要完成这样一个需求,从不同的线程获取线程中的Looper,是不是可以采用一个全局对象,比如hashmap,用来存储线程和对应的Looper?所以需要一个管理Looper的类,但是,线程中并不止这一个要存储和获取的数据,还有可能有其他的需求,也是跟线程所绑定的。所以,我们的系统就设计出了ThreadLocal这种工具类。
ThreadLocal的工作流程是这样的:我们从不同的线程可以访问同一个ThreadLocal的get方法,然后ThreadLocal会从各自的线程中取出一个数组,然后再数组中通过ThreadLocal的索引找出对应的value值。具体逻辑呢,我们还是看看代码,分别是ThreadLocal的get方法和set方法:
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
首先看看set方法,获取到当前线程,然后取出线程中的threadLocals变量,是一个ThreadLocalMap类,然后将当前的ThreadLocal作为key,要设置的值作为value存到这个map中。
get方法就同理了,还是获取到当前线程,然后取出线程中的ThreadLocalMap实例,然后从中取到当前ThreadLocal对应的值。
其实可以看到,操作的对象都是线程中的ThreadLocalMap实例,也就是读写操作都只限制在线程内部,这也就是ThreadLocal故意设计的精妙之处了,他可以在不同的线程进行读写数据而且线程之间互不干扰。
画个图方便理解记忆:
当MessageQueue 没有消息的时候,在干什么,会占用CPU资源吗。
-
MessageQueue没有消息时,便阻塞在 loop 的queue.next()方法这里。具体就是会调用到nativePollOnce方法里,最终调用到epoll_wait()进行阻塞等待。
这时,主线程会进行休眠状态,也就不会消耗CPU资源。当下个消息到达的时候,就会通过pipe管道写入数据然后唤醒主线程进行工作。
这里涉及到阻塞和唤醒的机制叫做 epoll 机制。
先说说文件描述符和I/O多路复用:
在Linux操作系统中,可以将一切都看作是文件,而文件描述符简称fd,当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符,可以理解为一个索引值。
I/O多路复用是一种机制,让单个进程可以监视多个文件描述符,一旦某个描述符就绪(一般是读就绪或写就绪),能够通知程序进行相应的读写操作
所以I/O多路复用其实就是一种监听读写的通知机制,而Linux提供的三种 IO 复用方式分别是:select、poll 和 epoll 。而这其中epoll是性能最好的多路I/O就绪通知方法。
所以,这里用到的epoll其实就是一种I/O多路复用方式,用来监控多个文件描述符的I/O事件。通过epoll_wait方法等待I/O事件,如果当前没有可用的事件则阻塞调用线程。
Binder是什么
先借用神书《Android开发艺术探索》中的一段话:
直观的说,Binder是一个类,实现了IBinder接口。
从IPC(Inter-Process Communication,进程间通信)角度来说,Binder是Android中一种跨进程通信方式。
还可以理解为一种虚拟的物理设备,它的设备驱动是/dev/binder。
从Android FrameWork角度来说,Binder是ServiceManager连接各种Manager(ActivityManager,WindowManager等等)和响应ManagerService的桥梁。
从Android应用层来说,Binder是客户端和服务端进行通信的媒介。
挺多概念的是吧,其实就说了一件事,Binder就是用来进程间通信的,是一种IPC方式。后面所有的解释都是Binder实际应用涉及到的内容。
不管是获取其他的系统服务,亦或是服务端和客户端的通信,都是源于Binder的进程间通信能力。
Binder通信过程和原理
首先,还是看一张图,原图也是出自神书中:
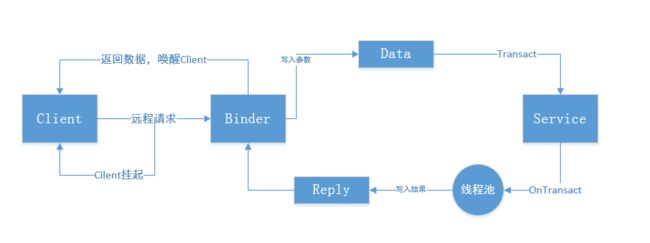
首先要明确的是客户端进程是无法直接操作服务端中的类和方法的,因为不同进程直接是不共享资源的。所以客户端这边操作的只是服务端进程的一个代理对象,也就是一个服务端的类引用,也就是Binder引用。
总体通信流程就是:
- 客户端通过代理对象向服务器发送请求。
- 代理对象通过
Binder驱动发送到服务器进程 - 服务器进程处理请求,并通过
Binder驱动返回处理结果给代理对象 - 代理对象将结果返回给客户端。
再看看在我们应用中常常用到的工作模型,上图:

这就是在应用层面我们常用的工作模型,通过ServiceManager去获取各种系统进程服务。这里的通信过程如下:
- 服务端跨进程的类都要继承
Binder类,所以也就是服务端对应的Binder实体。这个类并不是实际真实的远程Binder对象,而是一个Binder引用(即服务端的类引用),会在Binder驱动里还要做一次映射。 - 客户端要调用远程对象函数时,只需把数据写入到Parcel,在调用所持有的
Binder引用的transact()函数 -
transact函数执行过程中会把参数、标识符(标记远程对象及其函数)等数据放入到Client的共享内存,Binder驱动从Client的共享内存中读取数据,根据这些数据找到对应的远程进程的共享内存。 - 然后把数据拷贝到远程进程的共享内存中,并通知远程进程执行onTransact()函数,这个函数也是属于
Binder类。 - 远程进程
Binder对象执行完成后,将得到的写入自己的共享内存中,Binder驱动再将远程进程的共享内存数据拷贝到客户端的共享内存,并唤醒客户端线程。
所以通信过程中比较重要的就是这个服务端的Binder引用,通过它来找到服务端并与之完成通信。
看到这里可能有的人疑惑了,图中线程池怎么没用到啊?
- 可以从第一张图中看出,
Binder线程池位于服务端,它的主要作用就是将每个业务模块的Binder请求统一转发到远程Servie中去执行,从而避免了重复创建Service的过程。也就是服务端只有一个,但是可以处理多个不同客户端的Binder请求。
在Android中的应用
Binder在Android中的应用除了刚才的ServiceManager,你还想到了什么呢?
- 系统服务是用过
getSystemService获取的服务,内部也就是通过ServiceManager。例如四大组件的启动调度等工作,就是通过Binder机制传递给ActivityManagerService,再反馈给Zygote。而我们自己平时应用中获取服务也是通过getSystemService(getApplication().WINDOW_SERVICE)代码获取。 -
AIDL(Android Interface definition language)。例如我们定义一个IServer.aidl文件,aidl工具会自动生成一个IServer.java的java接口类(包含Stub,Proxy等内部类)。 - 前台进程通过
bindService绑定后台服务进程时,onServiceConnected(ComponentName name, IBinder service)传回IBinder对象,并且可以通过IServer.Stub.asInterface(service)获取IServer的内部类Proxy的对象,其实现了IServer接口。
Binder优势
在Linux中,进程通信的方式肯定不止Binder这一种,还有以下这些:
管道(Pipe)
信号(Signal)
消息队列(Message)
共享内存(Share Memory)
套接字(Socket)
Binder
而Binder在这之后主要有以下优点:
-
性能高,效率高:传统的IPC(套接字、管道、消息队列)需要拷贝两次内存、Binder只需要拷贝一次内存、共享内存不需要拷贝内存。 -
安全性好:接收方可以从数据包中获取发送发的进程Id和用户Id,方便验证发送方的身份,其他IPC想要实验只能够主动存入,但是这有可能在发送的过程中被修改。
熟悉Zygote的朋友可能知道,在fork()进程的时候,也就是向Zygote进程发出创建进程的消息的时候,用到的进程间通信方式就不是Binder了,而换成了Socket,这主要是因为fork不允许存在多线程,Binder通讯偏偏就是多线程。
所以具体的情况还是要去具体选择合适的IPC方式。
讲一下RecyclerView的缓存机制,滑动10个,再滑回去,会有几个执行onBindView。缓存的是什么?cachedView会执行onBindView吗?
RecyclerView预取机制
这两个问题都是关于缓存的,我就一起说了。
1)首先说下RecycleView的缓存结构:
Recycleview有四级缓存,分别是mAttachedScrap(屏幕内),mCacheViews(屏幕外),mViewCacheExtension(自定义缓存),mRecyclerPool(缓存池)
-
mAttachedScrap(屏幕内),用于屏幕内itemview快速重用,不需要重新createView和bindView -
mCacheViews(屏幕外),保存最近移出屏幕的ViewHolder,包含数据和position信息,复用时必须是相同位置的ViewHolder才能复用,应用场景在那些需要来回滑动的列表中,当往回滑动时,能直接复用ViewHolder数据,不需要重新bindView。 -
mViewCacheExtension(自定义缓存),不直接使用,需要用户自定义实现,默认不实现。 -
mRecyclerPool(缓存池),当cacheView满了后或者adapter被更换,将cacheView中移出的ViewHolder放到Pool中,放之前会把ViewHolder数据清除掉,所以复用时需要重新bindView。
2)四级缓存按照顺序需要依次读取。所以完整缓存流程是:
- 保存缓存流程:
- 插入或是删除
itemView时,先把屏幕内的ViewHolder保存至AttachedScrap中 - 滑动屏幕的时候,先消失的itemview会保存到
CacheView,CacheView大小默认是2,超过数量的话按照先入先出原则,移出头部的itemview保存到RecyclerPool缓存池(如果有自定义缓存就会保存到自定义缓存里),RecyclerPool缓存池会按照itemview的itemtype进行保存,每个itemType缓存个数为5个,超过就会被回收。
- 获取缓存流程:
- AttachedScrap中获取,通过pos匹配holder——>获取失败,从
CacheView中获取,也是通过pos获取holder缓存
——>获取失败,从自定义缓存中获取缓存——>获取失败,从mRecyclerPool中获取
——>获取失败,重新创建viewholder——createViewHolder并bindview。
3)了解了缓存结构和缓存流程,我们再来看看具体的问题
滑动10个,再滑回去,会有几个执行onBindView?
- 由之前的缓存结构可知,需要重新执行
onBindView的只有一种缓存区,就是缓存池mRecyclerPool。
所以我们假设从加载RecyclView开始盘的话(页面假设可以容纳7条数据):
- 首先,7条数据会依次调用
onCreateViewHolder和onBindViewHolder。 - 往下滑一条(position=7),那么会把position=0的数据放到
mCacheViews中。此时mCacheViews缓存区数量为1,mRecyclerPool数量为0。然后新出现的position=7的数据通过postion在mCacheViews中找不到对应的ViewHolder,通过itemtype也在mRecyclerPool中找不到对应的数据,所以会调用onCreateViewHolder和onBindViewHolder方法。 - 再往下滑一条数据(position=8),如上。
- 再往下滑一条数据(position=9),position=2的数据会放到
mCacheViews中,但是由于mCacheViews缓存区默认容量为2,所以position=0的数据会被清空数据然后放到mRecyclerPool缓存池中。而新出现的position=9数据由于在mRecyclerPool中还是找不到相应type的ViewHolder,所以还是会走onCreateViewHolder和onBindViewHolder方法。所以此时mCacheViews缓存区数量为2,mRecyclerPool数量为1。 - 再往下滑一条数据(position=10),这时候由于可以在
mRecyclerPool中找到相同viewtype的ViewHolder了。所以就直接复用了,并调用onBindViewHolder方法绑定数据。 - 后面依次类推,刚消失的两条数据会被放到
mCacheViews中,再出现的时候是不会调用onBindViewHolder方法,而复用的第三条数据是从mRecyclerPool中取得,就会调用onBindViewHolder方法了。
4)所以这个问题就得出结论了(假设mCacheViews容量为默认值2):
如果一开始滑动的是新数据,那么滑动10个,就会走10个
bindview方法。然后滑回去,会走10-2个bindview方法。一共18次调用。如果一开始滑动的是老数据,那么滑动10-2个,就会走8个
bindview方法。然后滑回去,会走10-2个bindview方法。一共16次调用。
但是但是,实际情况又有点不一样。因为Recycleview在v25版本引入了一个新的机制,预取机制。
预取机制,就是在滑动过程中,会把将要展示的一个元素提前缓存到mCachedViews中,所以滑动10个元素的时候,第11个元素也会被创建,也就多走了一次bindview方法。但是滑回去的时候不影响,因为就算提前取了一个缓存数据,只是把bindview方法提前了,并不影响总的绑定item数量。
所以滑动的是新数据的情况下就会多一次调用bindview方法。
5)总结,问题怎么答呢?
- 四级缓存和流程说一下。
- 滑动10个,再滑回去,
bindview可以是19次调用,可以是16次调用。 - 缓存的其实就是缓存item的view,在Recycleview中就是
viewholder。 -
cachedView就是mCacheViews缓存区中的view,是不需要重新绑定数据的。
如何实现RecyclerView的局部更新,用过payload吗,notifyItemChange方法中的参数?
关于RecycleView的数据更新,主要有以下几个方法:
-
notifyDataSetChanged(),刷新全部可见的item。
*notifyItemChanged(int),刷新指定item。 -
notifyItemRangeChanged(int,int),从指定位置开始刷新指定个item。 -
notifyItemInserted(int)、notifyItemMoved(int)、notifyItemRemoved(int)。插入、移动一个并自动刷新。 -
notifyItemChanged(int, Object),局部刷新。
可以看到,关于view的局部刷新就是notifyItemChanged(int, Object)方法,下面具体说说:
notifyItemChange有两个构造方法:
- notifyItemChanged(int position, @Nullable Object payload)
- notifyItemChanged(int position)
其中payload参数可以认为是你要刷新的一个标示,比如我有时候只想刷新itemView中的textview,有时候只想刷新imageview?又或者我只想某一个view的文字颜色进行高亮设置?那么我就可以通过payload参数来标示这个特殊的需求了。
具体怎么做呢?比如我调用了notifyItemChanged(14,"changeColor"),那么在onBindViewHolder回调方法中做下判断即可:
@Override
public void onBindViewHolder(ViewHolderholder, int position, ListRecyclerView嵌套RecyclerView滑动冲突,NestScrollView嵌套RecyclerView。
1)RecyclerView嵌套RecyclerView的情况下,如果两者都要上下滑动,那么就会引起滑动冲突。默认情况下外层的RecycleView可滑,内层不可滑。
之前说过解决滑动冲突的办法有两种:内部拦截法和外部拦截法。
这里我提供一种内部拦截法,还有一些其他的办法大家可以自己思考下。
holder.recyclerView.setOnTouchListener { v, event ->
when(event.action){
//当按下操作的时候,就通知父view不要拦截,拿起操作就设置可以拦截,正常走父view的滑动。
MotionEvent.ACTION_DOWN,MotionEvent.ACTION_MOVE -> v.parent.requestDisallowInterceptTouchEvent(true)
MotionEvent.ACTION_UP -> v.parent.requestDisallowInterceptTouchEvent(false)
}
false}
2)关于ScrclerView的滑动冲突还是同样的解决办法,就是进行事件拦截。
还有一个办法就是用Nestedscrollview代替ScrollView,Nestedscrollview是官方为了解决滑动冲突问题而设计的新的View。它的定义就是支持嵌套滑动的ScrollView。
所以直接替换成Nestedscrollview就能保证两者都能正常滑动了。但是要注意设置RecyclerView.setNestedScrollingEnabled(false)这个方法,用来取消RecyclerView本身的滑动效果。
这是因为RecyclerView默认是setNestedScrollingEnabled(true),这个方法的含义是支持嵌套滚动的。也就是说当它嵌套在NestedScrollView中时,默认会随着NestedScrollView滚动而滚动,放弃了自己的滚动。所以给我们的感觉就是滞留、卡顿。所以我们将它设置为false就解决了卡顿问题,让他正常的滑动,不受外部影响。
参考
https://www.jianshu.com/p/1dab927b2f36
https://juejin.im/post/6844903748574117901
https://juejin.im/post/6844903729414537223
https://blog.csdn.net/quwei3930921/article/details/85336552
https://www.jianshu.com/p/aac6fcfae1e8
https://mp.weixin.qq.com/s/wy9V4wXUoEFZ6ekzuLJySQ
https://www.cnblogs.com/hustcser/p/10228843.html
拜拜
有一起学习的小伙伴可以关注下我的公.众.号——码上积木❤️❤️
为了新朋友,老朋友方便查看,我把面试题《思考与解答》以往期刊整理成PDF了。大家到公.众.号主页回复消息"111"即可获得下载链接。