知识图谱——知识补全算法综述
知识图谱——知识补全综述
1、知识图谱补全概念
目标:预测出三元组中缺失的部分,从而使得知识图谱变得更加完整。
背景:对于一个知识图谱G而言,其基本的组成部分包括实体集 E = e 1 , e 2 , . . . e m E={e_1,e_2,...e_m} E=e1,e2,...em(m表示实体的个数)。关系集 R = r 1 , r 2 , . . . . r N R={r_1,r_2,....r_N} R=r1,r2,....rN(N表示关系的数目),以及对应的三元组 T = { ( e i , r k . e j ) } T=\{(e_i,r_k.e_j)\} T={(ei,rk.ej)}(其中 e i , e j ∈ E , r k ∈ R e_i,e_j∈E,r_k∈R ei,ej∈E,rk∈R)。由于知识图谱中的实体E和关系R的数量都是有限的,因此,可能会存在一些实体和关系不在G中。根据我们要补全的内容,我们可以将知识补全分成三个子任务。
- 给定部分三元组( _ , r k , e j \_,r_k,e_j _,rk,ej),我们来预测头实体。
- 给定部分三元组( , e i , r k , _ ,e_i,r_k,\_ ,ei,rk,_),我们来预测尾实体。
- 给定部分三元组( , e i , _ , e j ,e_i,\_,e_j ,ei,_,ej),我们来头实体和尾实体之间的关系。
分类:根据三元组中的实体和关系是否属于知识图谱中原有的实体和关系,我们可以把知识图谱补全分成静态知识图谱补全(static KGC)和动态知识图谱补全(Dynamic KGC)两个大类。其中,静态知识图谱补全所涉及的实体以及关系均在原始的知识图谱G中出现,动态知识图谱补全涉及的是不在原始知识图谱中出现的关系以及实体。从而通过知识图谱的补全,可以扩大原有的知识图谱的实体以及关系的集合。
2、知识图谱补全的前期工作
为了进行知识图谱的补全,首先要做的就是对知识图谱中的实体和关系进行合适的表示,这也称为知识表示,通过知识表示,我们可以构建出对于实体和关系恰当的编码表示。关于表示的方法,主要可以分为人工和通过学习的方式。通过学习的方式也称为知识表示学习,通过机器学习的算法自动的从数据中获得知识表示,能够根据具体的任务学习到合适的特征。目前,最常见的知识表示学习方法是基于深度学习的知识表示。但是,这种方法适用于特征连续且处于较低层次的领域,深度学习能够根据较低层次的特征构建出适合任务的较高层次的语义特征。
3 、静态知识图谱补全(Static KGC)
对于一个知识图谱而言,我们可以将其抽象成一个有向图的结构,其中实体表示节点,关系表示边。对于静态知识图谱补全而言,其实就是给知识图谱中的不同节点寻找有向边的过程。例如下图所示:
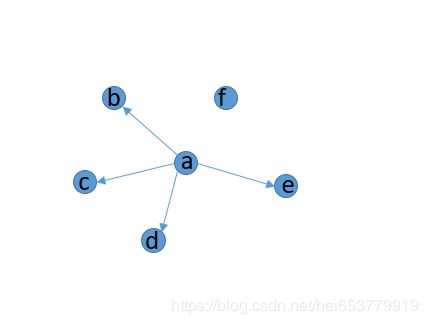
在上图中,一共包含a,b,c,d,e,f六个节点,我们补全的目标就是找到a和f中的对应关系,而且,这个关系是a与{b,c,d,e}对应关系中的一个。
3.1 前期工作
对于静态知识补全中的知识表示方法,最经典的模型是于2013年提出来的TransE模型,该模型的核心假设如下:
对于正确的三元组而言(h,r,t)而言,需要满足的是h+r=t,也就是尾实体是头实体通过关系r的平移而得到的。
对于TransE模型而言,其缺点在于,其无法应用到N-1的关系中,假如有两个三元组(张三,籍贯,黑龙江),(李四,籍贯,黑龙江),如果利用TransE模型,会有Vector(黑龙江)=V(张三)+V(籍贯)=V(李四)+V(籍贯),这会使得张三和李四的向量表示过于相似。TransE模型很难在这些复杂的关系上进行区分。
随后,又有TransH,TransD,TransR等相关改进的模型被提出,在之后的文章中,我们会进行陆续的介绍。
3.2 知识补全工作
通过我们前期的TransE模型,我们可以将知识图谱中的关系和实体转换成编码的方式,在通过核心公式:
t = h + r t=h+r t=h+r
来得到缺失的关系编码表示,最终通过相似度比较的方式来确定实际的关系。
4 动态知识图谱补全(Dynamic KGC)
对于之前所提出来的动态知识图谱的补全任务中,我们能够确定的是知识图谱中已经存在的相关实体和关系,我们最终补全的关系也是知识图谱中存在的关系。而对于动态知识图谱补全的任务中,我们所涉及的会是没有在知识图谱中出现的关系和实体。
实际上,向知识图谱中添加新的实体或者新的关系的场景其实可以抽象为迁移学习中的零数据学习问题,原有的知识图谱中的实体和关系为源域,新的实体和实体关系为目标域。实现迁移学习的基本前提是源域和目标域之间存在相关性,即要共享相同或者类似的信息,否则迁移效果会比较差。为了能够提高新添加的实体或者新的关系场景的准确率,就需要寻找两个域之间的额外的共享信息。然后,在结合源域中的实体和关系进行建模,得到目标域中实体的向量,从而实现动态知识图谱补全。
从目前来看,动态知识图谱补全主要针对的是知识图谱中的实体的的补全,所以,大部分的工作都是围绕着如何向知识图谱中添加新的实体展开的。对于添加的新实体,其所拥有的额外信息可以分为两类场景。
- 实体拥有丰富的文本信息,如实体名,实体描述,类型等等。
- 新的实体和原知识图谱中的实体以及关系有显性的三元组关系,这些三元组通常被称为辅助三元组。
对于场景1,相关工作是建立实体与额外关系的映射类挖掘以及增强源域和目标域之间的关联。如对于A的描述包括“人口总量”,“国土面积”等等,那么说明A可能代表的是一个国家。如果对于B也存在这些描述,那么很可能说明B也是一个国家的实体。
对于场景2,最近提出了一种基于图神经网络的模型,改模型可以分为传输模型和输出模型,其中传输模型负责,在图中的节点之间传播信息,而输出模型则根据具体任务定义了一个目标函数。根据知识补全任务将图谱中相邻的实体的向量进行组合,从而形成最终的向量。对于输出模型,则使用TransE模型。给出三种测试,第一种是仅仅有头实体是新实体,第二种是仅仅尾实体是新实体,第三中是头实体和尾实体均是新实体。此外,给每一个新实体设计了相应的辅助三元组,用于获取新的实体的向量。
5、参考文献
- 丁建辉, 贾维嘉. 知识图谱补全算法综述[J]. 信息通信技术.