word embedding是什么,word embedding之前需要做什么?
我们知道自然语言处理是让机器能够看懂并理解人类所说的语言,能够像人类一样进行交互,和人对话。从自然语言的角度看,NLP可以大致分为自然语言处理和自然语言生成这两部分,就是理解文本和文本生成。具体应用领域几乎覆盖日常生活,如提取文章摘要,文本情感分析,淘宝京东上机器人客服的智能问答,实体命名识别,知识图谱,信息检索等等。又比如说现在已经有方言的语音转文字技术。
那具体实现起来该怎么样呢?我们总不能直接把一堆文字或者一段英文直接倒给计算机,计算机只能处理数字,那么我们就得把词给转换成可以供计算机计算的数。
1. 词表示
1.1 词表示的目的
我们对词用计算机可计算的数替代,进而能够完成词语间的相似度计算,词语之间的关系等。
1.2 词表示的方法
1.2.1 Word ID or One-hot representation
E.g.
| word | ID | one-hot vector |
|---|---|---|
| star | 2 | [0, 0, 1, 0, 0, 0,...] |
| sun | 3 | [0, 0, 0, 1, 0, 0,...] |
在这里我们也可以看出这种独热码的词表示方式不能够完成词相似度计算,因为任意词之间都是相互正交的,为了解决这个问题又提出了另外一种表示方式,词向量。
1.2.2 Distribution representation
词向量是将词转化成一种分布式表示。分布式表示将词表示成一个定长的连续的稠密向量,这就是word embedding。任何一个词都可以用它出现的频率或者重要性去进行表示,因此,就可以在这个空间里面利用稠密向量来计算两个词之间的相似度。
随之而来的问题是,其一是,词表变大,存储需求也会随之变大;其二是,有些词出现频率特别少,这种词不好表示。
1.2.3 Word2Vec
建立低维的稠密的向量空间,尝试把每一个词都学到这个空间里,用这个空间里的某一个位置所对应的向量来表示这个词。下图所示:
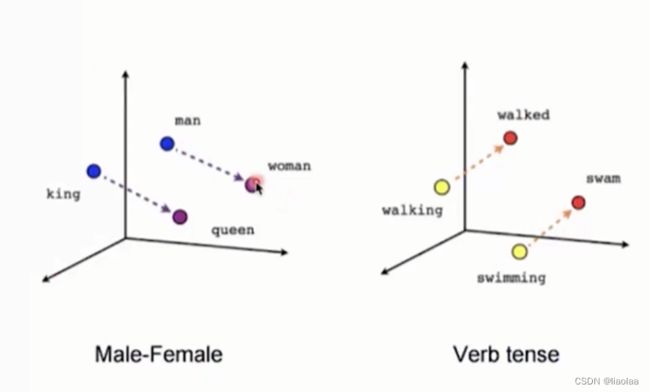
在这个空间中queen-king 和 woman-man 近似平行,他们之间的关系是类似的或相同的。
2. 如何构建word2vec
2.1 滑动窗口
窗口中心的词是目标词(target word),其余词是上下文(context words)。例句:never too late to learn,如下图:
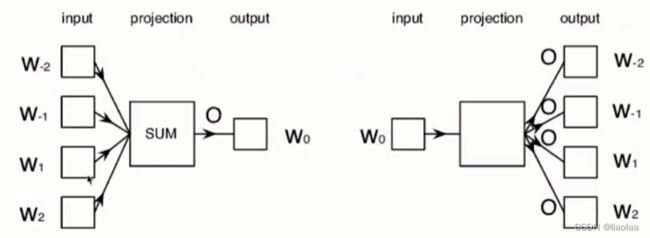
左边是CBOW,我们用上下文来预测目标词;右边是skip-gram,用目标词预测上下文。
CBOW:(input:never too late to learn)(Window=3)
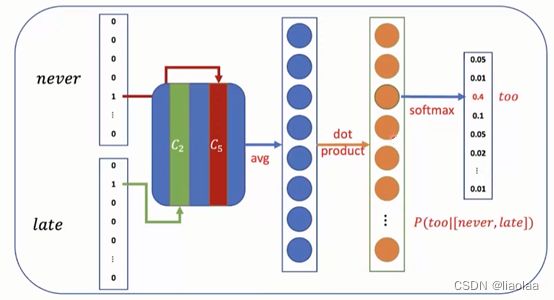
skip-gram:(input:never too late to learn)(Window=3)

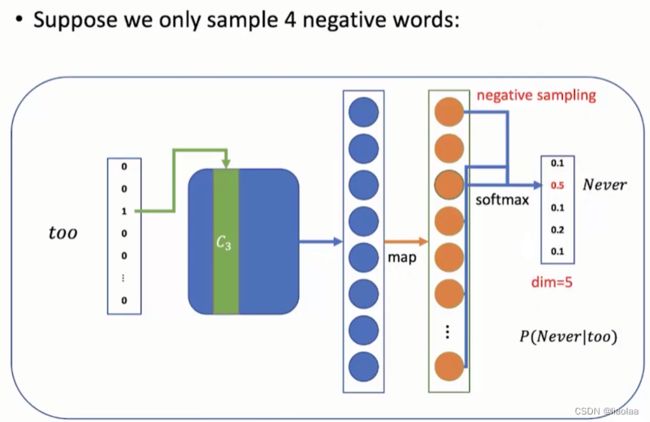
我们在上面的两个例子中也可以发现,在softmax之前我们会将词向量拼接成词表大小的向量,计算量非常大。如何解决呢?负采样,如何进行负采样呢,具体可以参考这篇文章(NLP 之 word2vec 以及负采样原理详解_word2vec 负采样应该是用每个位置的当前值而不是累计值 除以所有位置值的和,为什-CSDN博客),这篇文章对这里出现的模型都有理论的详解。
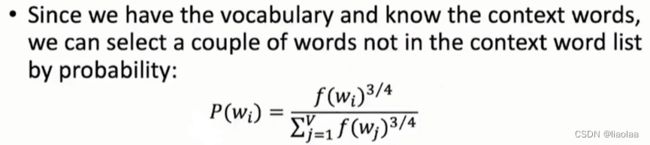
在softmax之前负采样出几个词向量,词出现的频率越大被采样的概率越大,3/4是一个经验值,低频词被采样的概率稍微提高一点。
2.2 变长滑动窗口
在滑动窗口的基础上,我们更多使用的是不固定大小的滑动窗口,因为我们认为离目标词与更近的上下文比更远的上下文更相关,所以我们离目标词更近的上下文更容易出现在窗口里。
2.3 Sub-sampling
平衡常见词和罕见词,我们认为常见词包含的语义比较少,而罕见词的语义比较丰富。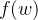 越高越容易被丢弃。
越高越容易被丢弃。

3. Neural Language Model
在提神经语言模型之前,我们先看下N-aram model,在N-gram Model里面每一个词都是一个符号,在一个大规模数据里面统计连续出现的序列的频率。考虑的长度通长较短,N大多是2或者3。(遵守Markov的假设:只考虑前面的有限的几个词)
![]()
它假设所有词相互之间都是独立的,上下文基于符号去做统计,不能理解词与词之间的相似度。
而在Neural Language Model中,
用分布式的表示建构前文和当前词的预测条件概率。通过对上下文的表示完成,相似的词会有一个相似的向量,就可能在相似的语境中发挥相似的作用。如下图,每一个词都会被表示成一个低维的向量。然后把他们拼在一起形成一个更高的上下文的向量。然后再经过非线性的转换,用向量去预测下一个词是什么。
4. Word embedding具体操作
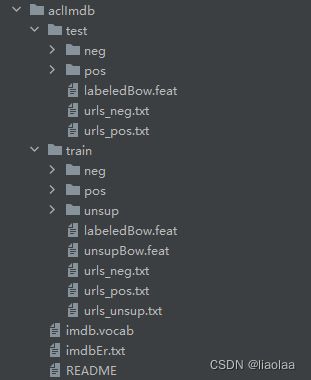
4.1 数据集
这数据集包含了50000条偏向明显的评论,其中25000条作为训练集,25000作为测试集。label为pos(positive)和neg(negative)。(Sentiment Analysis (stanford.edu))。数据集中的评论都是长短不一的句子,所以在构建Dataset时候还得先词元化。
4.2 Word embedding

如上,在embedding之前,我们先有一个词表(vocabulary),其中,假设我们的词表大小为10000个词,即(vocab_size = 10000)。一个词的稠密向量为30,即(embedding_dim = 30),一个batch有4个句子(sentence),经过word embedding后我们有得到了右边的形状。
torch.nn.Embedding(num_embeddings, embedding_dim)
"""参数"""
num_embeddings:词典的大小
embedding_dim:embedding的维度
"""例子"""
每个句子有10个词语,经过词表大小为10000,即形状为 [10000,30] 的word embedding之后,
变成每个词用长度为30的向量表示,变成 [batch_size, 10000, 30] 的形状。4.3 构建Dataset、Dataloader
def tokenize(content):
content = re.sub("<.*?>", " ", content)
fileters = [':','\t','\n','\x97','\x96','#','$','%','&']
content = re.sub("|".join(fileters), " ", content)
tokens = [i.strip() for i in content.split()]
return tokens
class ImdbDataset(Dataset):
def __init__(self,train=True):
super(ImdbDataset,self).__init__()
self.train_data_path = r"./aclImdb/train"
self.test_data_path = r"./aclImdb/test"
data_path = self.train_data_path if train else self.test_data_path
#把所有的文件名放入列表
temp_data_path = [os.path.join(data_path,"pos"), os.path.join(data_path,"neg")]
self.total_file_path = [] #所有评论文件的完整路径
for path in temp_data_path:
file_name_list = os.listdir(path)
file_path_list = [os.path.join(path,i) for i in file_name_list if i.endswith(".txt")]
self.total_file_path.extend(file_path_list)
def __getitem__(self, item):
cur_path = self.total_file_path[item]
# 获取label
label_str = cur_path.split("\\")[-2]
# print(label_str)
label = 0 if label_str == "neg" else 1
# 获取内容
content = open(cur_path).read()
tokens = tokenize(content)
return tokens, label
def __len__(self):
return len(self.total_file_path)
def collate_fn(batch):
"""
默认的collate_fn会让batch操作出错.
当Dataset中数据返回的是文本数据就会出这样的错
:param batch: (一个getitem的结果, 一个getitem的结果) 即 ([tokens, label], [tokens, label], )
:return:
"""
content, label = list(zip(*batch))
return content, label
def get_dataloader(train=True):
dataset = ImdbDataset(train)
dataloader = DataLoader(dataset=dataset, batch_size=2,shuffle=True, collate_fn=collate_fn)
return dataloader在调试,编写代码的时候可以用这个看看数据具体是什么样的,如下,可以先用dataloader拿一次数据来看看。
if __name__ == '__main__':
for idx,(input,target) in enumerate(get_dataloader()):
print("idx:", idx)
print("input:", input)
print("target:", target)
break输出如下:


4.4 文本序列化
我们目前拿到的数据是词元,我们需要把文本中每个词语和其对应的数字,使用字典保存,同时实现方法把句子通过字典映射为包含数字的列表。
可能有两个问题,遇到词表中没出现过的词元怎么办?用UNK这个特殊词元代替;
每个句子的长度都不一样怎么办?用PAD这个特殊词元填充句子,超出的长度直接截断。
"""
实现的是:构建词典,实现方法把句子转化为数字序列和其反转字典
"""
class Word2Seq:
UNK_TAG = "UNK" # 未知词元
PAD_TAG = "PAD" # 填充词元
UNK = 0
PAD = 1
def __init__(self):
self.dict = {self.UNK_TAG:self.UNK,
self.PAD_TAG:self.PAD}
self.count = {} # 统计词频
def fit(self,sentence):
"""
把句子保存到字典
:param sentence:
:return:
"""
for word in sentence:
self.count[word] = self.count.get(word,0)+1
def build_vocab(self,min=4,max=None,max_features=None):
"""
构建词典
:param min: 最小词频
:param max: 最大词频
:param max_features: 词典最大容纳词元数量
:return:
"""
# 保留符合要求的词元
if min is not None:
self.count = { word:val for word,val in self.count.items() if val>=min }
if max is not None:
self.count = { word:val for word,val in self.count.items() if val>=max }
if max_features is not None:
# 字典不能排序,
# {1:0, 2:0, 3:0} ---.item()---> [(1,0),(2,0),(3,0)]
tmp = sorted(self.count.items(), key=lambda x:x[-1], reverse=True)[:max_features]
self.count = dict(tmp)
for word in self.count:
self.dict[word] = len(self.dict) # 第一次进来的时候 self.dict 的长度是2,所以进来的词对应着2,3,4...
# 反转字典{数字序列:词元}
self.inverse_dict = dict(zip(self.dict.values(),self.dict.keys()))
def transform(self,sentence,max_len=None):
"""
把句子转为序列
:param sentence: [词元,词元,词元...]
:param max_len: 规定最大句子长度,完成填充,让每个句子一样长
:return:
"""
if max_len is not None:
if max_len > len(sentence):
sentence = sentence + (max_len-len(sentence))*[self.PAD_TAG]
else:
sentence = sentence[:max_len]
return [self.dict.get(word,self.UNK) for word in sentence] # 没在字典中的词元用未知词元替代
def inverse_transform(self,indices):
"""
把序列转为句子
:param indices:
:return:
"""
return [self.dict.get(idx) for idx in indices]测试一下,也可以拿其他文本做测试。
if __name__ == '__main__':
ws = Word2Seq()
for idx,(input,target) in enumerate(get_dataloader()):
print("idx:", idx)
print("input:", input)
print("target:", target)
ws.fit(input[0])
ws.build_vocab(min=3)
print(ws.dict)
break输出如下:
![]()
至此我们完成了对文本序列化,大家可以尝试构建词表,构建完词表后,就可以对所有的词元embedding。可以通过以上的代码实现结合注释来加深对这个word embedding部分理论和实际具体操作的理解。后续会将。ipynb的代码,以及文章中提及的对IMDB评论文本数据情感分析项目上传至仓库。