【7】知识融合
知识融合(也称本体对齐、本体匹配、实体对齐),即合并两个知识图谱(本体),基本的问题都是研究怎样将来自多个来源的关于同一个实体或概念的描述信息融合起来。
需要确认的是:
等价实例:实体的匹配,左右两个人是同一个人
等价类/子类:摇滚歌手是歌手的子类
等价属性/子属性:出生于出生日期是等价的属性
一、主要任务
1、实体链接
实体链接(entity linking)是指对于从文本中抽取得到的实体对象,将其链接到知识库中对应的正确实体对象的操作。
其基本思想是首先根据给定的实体指称项,从知识库中选出一组候选实体对象,然后通过相似度计算将指称项链接到正确的实体对象。
流程:
从文本中通过实体抽取得到实体指称项;
进行实体统一和实体消歧,判断知识库中的同名实体与之是否代表不同的含义以及知识库中是否存在其他命名实体与之表示相同的含义;
在确认知识库中对应的正确实体对象之后,将该实体指称项链接到知识库中对应实体。
2、实体统一(共指消解):
多源异构数据在集成的过程中,通常会出现一个现实世界实体对应多个表象的现象,导致这种现象发生的原因可能是:拼写错误、命名规则不同、名称变体、缩写等等。
分辨多个实体表象是否对应同一个实体的问题即为实体统一。
原因:RDF将数据以<资源,属性,属性值>的形式去表示,并不保证某一实体或者资源的唯一性,所以在RDF数据中会存在实体共指的现象。
解决方法
①实体共指消解
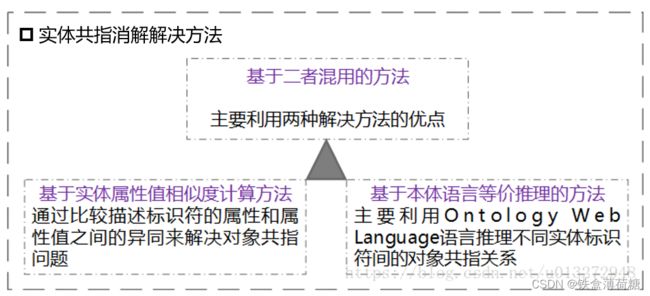
②模式匹配:主要是发现不同关联数据源中属性之间的映射关系,主要解决三元组中谓词之间的冲突问题;另一种解释:解决不同关联数据源对相同属性采用不同标识符的问题,从而实现异构数据源的集成

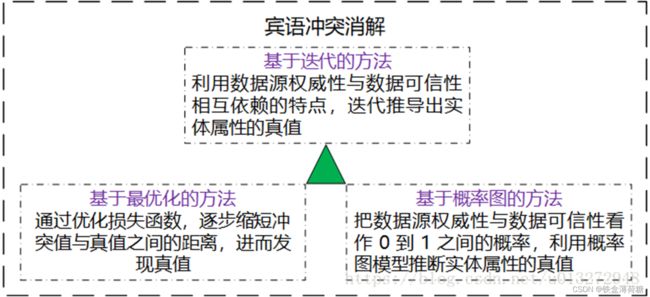
③宾语冲突消解:是解决多源关联数据宾语不一致问题。
3、实体消歧
实体消歧的本质在于一个词有很多可能的意思,也就是在不同的上下文中所表达的含义不太一样。
词义消歧的研究通常需要语义词典的支持,因为词典描述了词语的义项区分。
解决方法:
①基于词典的词义消歧
给定某个待消解词及其上下文,该工作的思想是计算语义词典中各个词义的定义与上下文之间的覆盖度,选择覆盖度最大的作为待消解词在其上下文下的正确词义。但由于词典中词义的定义通常比较简洁,这使得与待消解词的上下文得到的覆盖度为0,造成消歧性能不高。
②有监督词义消歧
使用词义标注语料来建立消歧模型,研究的重点在于特征的表示。常见的上下文特征可以归纳为三个类型:
1)词汇特征通常指待消解词上下窗口内出现的词及其词性;
2)句法特征利用待消解词在上下文中的句法关系特征,如动-宾关系、是否带主/宾语、主/宾语组块类型、主/宾语中心词等;
3)语义特征在句法关系的基础上添加了语义类信息,如主/宾语中心词的语义类,甚至还可以是语义角色标注类信息。
③无监督和半监督词义消歧
虽然有监督的消歧方法能够取得较好的消歧性能,但需要大量的人工标注语料,费时费力。为了克服对大规模语料的需要,半监督或无监督方法仅需要少量或不需要人工标注语料。一般说来,虽然半监督或无监督方法不需要大量的人工标注数据,但依赖于一个大规模的未标注语料,以及在该语料上的句法分析结果。
4.知识合并
实体链接(对半结构化数据和非结构化数据的信息提取)
知识合并(对结构化数据的处理)
主要分为两种:合并外部知识库、合并关系数据库
①合并外部知识库:
需要处理两个层面的问题:
数据层的融合,包括实体的指称、属性、关系以及所属类别等,主要的问题是如何避免实例以及关系的冲突问题,造成不必要的冗余
模式层的融合,将新得到的本体融入已有的本体库中
包括以下步骤:1.获取知识 2.概念匹配 3.实体匹配 4.知识评估
②合并关系数据库:
在知识图谱构建过程中,一个重要的高质量知识来源是企业或者机构自己的关系数据库。为了将这些结构化的历史数据融入到知识图谱中,可以采用资源描述框架(RDF)作为数据模型。这一数据转换过程称为RDB2RDF,其实质就是将关系数据库的数据换成RDF的三元组数据。(工具:D2RQ)