pd.concat() Pandas 数据的拼接
pd.concat() python API 官方参考链接 参考链接一 参考链接二
pandas.concat( objs,
axis=0,
join='outer',
join_axes=None,
ignore_index=False,
keys=None,
levels=None,
names=None,
verify_integrity=False,
copy=True)参数含义:
- objs:Series,DataFrame或Panel对象的序列或映射。如果传递了dict,则排序的键将用作键参数,除非它被传递,在这种情况下,将选择值(见下文)。任何无对象将被静默删除,除非它们都是无,在这种情况下将引发一个ValueError。
- axis:{0,1,...},默认为0。沿着连接的轴。axis = 0, 表示在水平方向(row)进行连接 axis = 1, 表示在垂直方向(column)进行连接
- join:{'inner','outer'},默认为“outer”。如何处理其他轴上的索引。outer为联合/inner为交集。outer, 表示index全部需要; inner,表示只取index重合的部分
- ignore_index:boolean,default False。如果为True,请不要使用并置轴上的索引值。结果轴将被标记为0,...,n-1。如果要连接其中并置轴没有有意义的索引信息的对象,这将非常有用。注意,其他轴上的索引值在连接中仍然受到尊重。
- join_axes:Index对象列表。用于其他n-1轴的特定索引,而不是执行内部/外部设置逻辑。
- keys:序列,默认值无。使用传递的键作为最外层构建层次索引。如果为多索引,应该使用元组。
- levels:序列列表,默认值无。用于构建MultiIndex的特定级别(唯一值)。否则,它们将从键推断。
- names:list,default无。结果层次索引中的级别的名称。
- verify_integrity:boolean,default False。检查新连接的轴是否包含重复项。这相对于实际的数据串联可能是非常昂贵的。
- copy:boolean,default True。如果为False,请勿不必要地复制数据。
实践案例:
import pandas as pd
import tushare as ts # 一个关于股票的公开数据集
横向连接,axis = 0 比如说,当我们需要某只股票1月和7月前几天的交易数据
report1 = ts.get_k_data('600036', start='2017-01-01', end='2017-01-05')
report2 = ts.get_k_data('600036', start='2017-07-01', end='2017-07-05')report1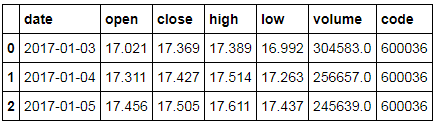
report2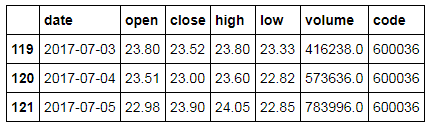
pd.concat([report1, report2], axis=0)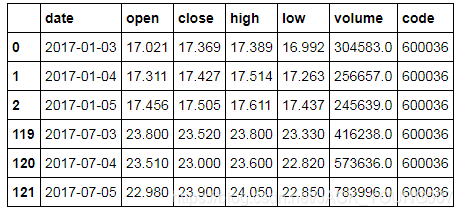
纵向连接,axis = 1 比如说,我们需要观察8月份某只股票与上证指数的走势对比
stock = ts.get_k_data('600036', start='2017-08-01', end='2017-08-31')
sh = ts.get_k_data('sh', start='2017-08-01', end='2017-08-31')
trend = pd.concat([stock, sh], axis=1)
trend.head()
column name 有重复,似乎不是很好处理
trend = pd.concat([stock, sh], axis=1, keys=['zsyh', 'sh'])
trend.head()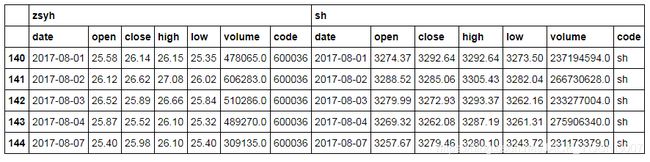
import matplotlib.pyplot as plt
% matplotlib inline
# %matplotlib inline是一个魔法函数(Magic Functions)。
# 官方给出的定义是:IPython有一组预先定义好的所谓的魔法函数(Magic Functions),
# 你可以通过命令行的语法形式来访问它们。
# 比如在Jupyter Notebook中进行操作,由于 %matplotlib inline 的存在,
# 当输入plt.plot(x,y_1)后,不必再输入 plt.show(),图像将自动显示出来
trend.loc[:, [('zsyh', 'close'), ('sh', 'close')]].plot(kind='line', secondary_y=[('sh', 'close')])
上面使用了keys来创建了MultiIndexing,感觉还挺麻烦。现在换一种方法,来看看ignore_index的作用
trend = pd.concat([stock, sh], axis=1, ignore_index=True)
trend.head()
trend.rename(columns={2: 'zsyh_close', 9: 'sh_close'}, inplace=True)
trend.head()
trend.loc[:, ['zsyh_close', 'sh_close']].plot(kind='line', secondary_y=['sh_close'])