【爬虫实战】python文本分析库——Gensim
文章目录
-
- 01、引言
- 02、主题分析以及文本相似性分析
- 03、关键词提取
- 04、Word2Vec 嵌入(词嵌入 Word Embeddings)
- 05、FastText 嵌入(子词嵌入 Subword Embeddings)
- 06、文档向量化
01、引言
Gensim是一个用于自然语言处理和文本分析的 Python 库,提供了许多强大的功能,包括文档的相似度计算、关键词提取和文档的主题分析,要开始使用Gensim,您需要安装它,再进行文本分析和NLP任务,安装Gensim可以使用pip:
pip install gensim
02、主题分析以及文本相似性分析
Gensim是一个强大的Python库,用于执行主题建模和文本相似性分析等自然语言处理任务。使用Gensim进行主题建模(使用Latent Dirichlet Allocation,LDA)和文本相似性分析(使用 similarities 模块中的 MatrixSimilarity 或 SparseMatrixSimilarity 来计算文档相似度),代码如下:
from gensim import corpora, models, similarities
# 创建一个简单的文本数据集作为示例
documents = [
"This is the first document.",
"This document is the second document.",
"And this is the third one.",
"Is this the first document?",
]
# 预处理文本数据:
# 切分文档为单词
text = [document.split() for document in documents]
# 创建一个词典,将每个单词映射到一个唯一的整数ID
dictionary = corpora.Dictionary(text)
# 使用词典将文本转化为文档-词袋(document-term)表示
corpus = [dictionary.doc2bow(doc) for doc in text]
#训练LDA模型并执行主题建模:
# 训练LDA模型
lda_model = models.LdaModel(corpus, num_topics=2, id2word=dictionary, passes=15)
# 输出主题及其词汇
for topic in lda_model.print_topics():
print(topic)
#文本相似性分析:
from gensim import similarities
# 创建一个索引
index = similarities.MatrixSimilarity(lda_model[corpus])
# 定义一个查询文本
query = "This is a new document."
# 预处理查询文本
query_bow = dictionary.doc2bow(query.split())
# 获取查询文本与所有文档的相似性得分
sims = index[lda_model[query_bow]]
# 按相似性得分降序排列文档
sims = sorted(enumerate(sims), key=lambda item: -item[1])
# 输出相似文档及其得分
for document_id, similarity in sims:
print(f"Document {document_id}: Similarity = {similarity}")
结果如下:
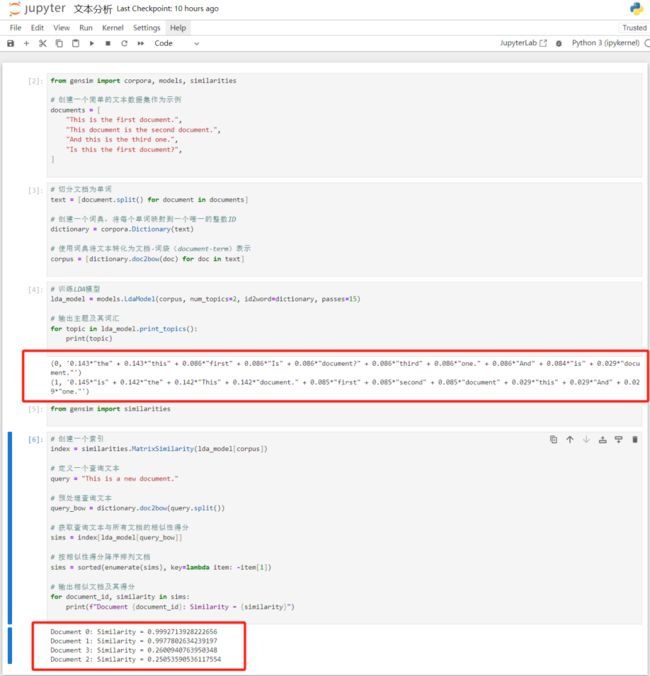
另一种方法,在gensim下用 Wasserstein 距离方法计算文档相似度,代码如下:
from gensim import corpora
from scipy.stats import wasserstein_distance
import numpy as np
# 示例文档
documents = [
"This is the first document.",
"This document is the second document.",
"And this is the third one.",
"Is this the first document?",
]
# 预处理文本和创建词典
text = [document.split() for document in documents]
dictionary = corpora.Dictionary(text)
# 创建文档的词袋表示
corpus = [dictionary.doc2bow(doc) for doc in text]
# 创建文档的概率分布
document_distributions = [np.array([0] * len(dictionary)) for _ in range(len(corpus))]
for i, doc_bow in enumerate(corpus):
for word_id, count in doc_bow:
document_distributions[i][word_id] = count / len(doc_bow)
# 计算Wasserstein距离
# 这里示例计算第一个文档和其他文档之间的Wasserstein距离
for i in range(1, len(document_distributions)):
wasserstein_dist = wasserstein_distance(document_distributions[0], document_distributions[i])
print(f"Wasserstein Distance between Document 0 and Document {i}: {wasserstein_dist}")
结果如下:
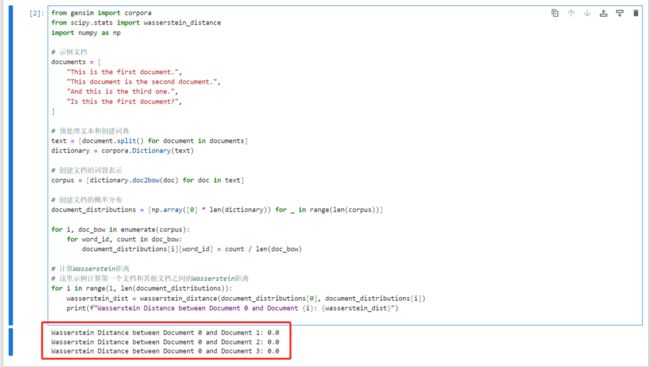
03、关键词提取
Gensim 允许你使用 TF-IDF 权重和其他算法来提取文档中的关键词。你可以使用 models.TfidfModel 来计算 TF-IDF 权重,然后使用 model.get_document_topics 来获取文档的主题分布,代码如下:
from gensim import corpora, models
from gensim.parsing.preprocessing import preprocess_string, strip_punctuation
# 示例文档
documents = [
"This is the first document. It contains important information.",
"This document is the second document. It also has important content.",
"And this is the third one. It may contain some relevant details.",
"Is this the first document? Yes, it is."
]
# 预处理文本
def preprocess(text):
# 使用Gensim的文本预处理工具进行处理,包括去除标点符号
custom_filters = [strip_punctuation]
processed_text = preprocess_string(text, custom_filters)
return processed_text
# 预处理文档并创建词袋表示
text = [preprocess(document) for document in documents]
dictionary = corpora.Dictionary(text)
corpus = [dictionary.doc2bow(doc) for doc in text]
# 计算TF-IDF模型
tfidf_model = models.TfidfModel(corpus)
lda_model=models.LdaModel(corpus)
# 获取TF-IDF加权
for i, doc in enumerate(corpus):
tfidf_weights = tfidf_model[doc]
print(f"TF-IDF Weights for Document {i}: {tfidf_weights}")
# 获取文档的主题分布
for i, doc in enumerate(corpus):
document_topics = lda_model.get_document_topics(doc)
print(f"Topic Distribution for Document {i}: {document_topics}")
最终结果如下:
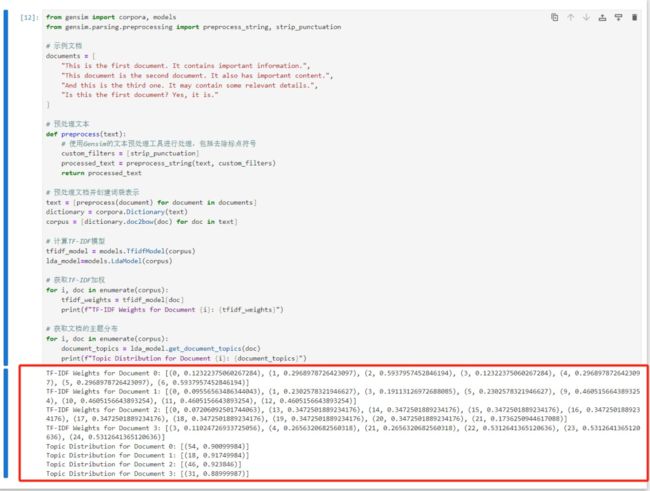
04、Word2Vec 嵌入(词嵌入 Word Embeddings)
gensim支持训练和使用 Word2Vec 模型,以将单词映射到低维向量空间。Word2Vec是一种词嵌入技术,它可以捕捉单词之间的语义关系,使得词汇可以在向量空间中表示。这对于词义相似度计算、单词聚类和其他自然语言处理任务非常有用,代码如下:
from gensim.models import Word2Vec
# 示例文本数据
sentences = [
["this", "is", "a", "sample", "sentence"],
["word2vec", "is", "used", "to", "create", "word", "embeddings"],
["it", "maps", "words", "to", "low-dimensional", "vectors"],
["these", "vectors", "capture", "semantic", "meaning", "of", "words"],
]
# 训练Word2Vec模型
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, sg=0)
# 保存模型
model.save("word2vec.model")
# 加载模型
model = Word2Vec.load("word2vec.model")
# 获取单词的向量表示
word_vector = model.wv["word2vec"]
print("Vector representation for 'word2vec':", word_vector)
# 查找与单词最相似的单词
similar_words = model.wv.most_similar("word2vec", topn=3)
print("Most similar words to 'word2vec':", similar_words)
最终结果如下:

05、FastText 嵌入(子词嵌入 Subword Embeddings)
Gensim支持 FastText 模型,这是一个基于子词的嵌入模型,可以捕获单词的内部结构和形态,FastText在许多自然语言处理任务中表现出色,尤其在处理具有丰富形态变化的语言时非常有用,代码如下:
from gensim.models.fasttext import FastText
# 示例文本数据
sentences = [
["this", "is", "a", "sample", "sentence"],
["fasttext", "is", "used", "to", "capture", "word", "subword", "embeddings"],
["it", "can", "handle", "morphological", "variations", "in", "words"],
["fasttext", "embeddings", "are", "useful", "for", "NLP", "tasks"],
]
# 训练FastText模型
model = FastText(sentences, vector_size=100, window=5, min_count=1, sg=0)
# 保存模型
model.save("fasttext.model")
# 加载模型
model = FastText.load("fasttext.model")
# 获取单词的向量表示
word_vector = model.wv["fasttext"]
print("Vector representation for 'fasttext':", word_vector)
# 查找与单词最相似的单词
similar_words = model.wv.most_similar("fasttext", topn=3)
print("Most similar words to 'fasttext':", similar_words)
最终结果如下:

06、文档向量化
使用Gensim将文档表示为词袋模型和TF-IDF向量,从而将文档转化为数值表示形式,以便用于文本分类、文本检索和文本聚类等任务代码如下:
from gensim import corpora
# 示例文档
documents = [
"This is the first document. It contains important information.",
"This document is the second document. It also has important content.",
"And this is the third one. It may contain some relevant details.",
"Is this the first document? Yes, it is.",
]
# 预处理文本并创建词袋表示
text = [document.split() for document in documents]
dictionary = corpora.Dictionary(text)
corpus = [dictionary.doc2bow(doc) for doc in text]
# 文档向量表示
document_vectors = [dict(doc) for doc in corpus]
# 输出文档向量
for i, doc_vector in enumerate(document_vectors):
print(f"Document {i} Vector: {doc_vector}")
from gensim import corpora, models
# 示例文档
documents = [
"This is the first document. It contains important information.",
"This document is the second document. It also has important content.",
"And this is the third one. It may contain some relevant details.",
"Is this the first document? Yes, it is.",
]
# 预处理文本并创建词袋表示
text = [document.split() for document in documents]
dictionary = corpora.Dictionary(text)
corpus = [dictionary.doc2bow(doc) for doc in text]
# 计算TF-IDF模型
tfidf_model = models.TfidfModel(corpus)
corpus_tfidf = tfidf_model[corpus]
# 文档TF-IDF向量表示
tfidf_vectors = [dict(doc) for doc in corpus_tfidf]
# 输出TF-IDF文档向量
for i, tfidf_vector in enumerate(tfidf_vectors):
print(f"TF-IDF Vector for Document {i}: {tfidf_vector}")
最终结果如下:

以上就是本文对Gensim库文本分析的 方法介绍,希望能够帮助大家处理解决文本分析问题,感兴趣的小伙伴可以亲自去试试!
感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试宝典


简历模板
若有侵权,请联系删除