深度学习分类问题之Logistic Regression
逻辑回归模型,虽然名字是回归,但是是解决分类问题。
在线性回归里面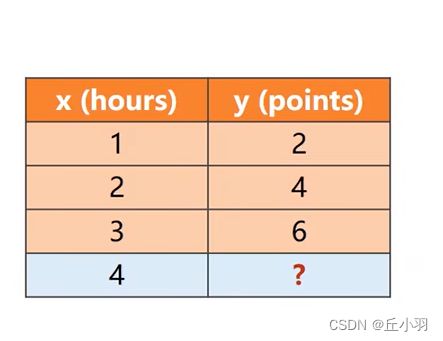 ,我们根据有效信息,预测下一个由已知信息得到的数值,叫做回归问题,但是在机器学习里面,常见的是分类问题。最常见的就是MNIST数据集里面的手写数字问题。
,我们根据有效信息,预测下一个由已知信息得到的数值,叫做回归问题,但是在机器学习里面,常见的是分类问题。最常见的就是MNIST数据集里面的手写数字问题。
在这个问题里面:我们给出了六万多张训练集对我们的模型进行训练,然后给出一张手写数字,模型可以帮我们判断出这个手写数字是几,这叫做分类问题。通过训练(喂数据),训练模型,而后给出数据,模型基于前面的训练将数据进行归类。
这与线性模型不同,我们得到的是数据属于各个类的概率值,我们输出的是一个概率,所有概率之和是1。我们算出概率值,通过找到概率最大的类,得到预测结果。
MNIST:pytorch里面的torchvision包里面提供了相应的(比较流行的)数据集。

第一个参数表示数据集的位置,第二个参数是是否作为训练集,第三个参数表示是否要从网上进行下载。如果已经下载过了,可以设置为False。建议直接选择True,如果发现已经下载,则不需要再次下载了。
仍然以之前的那个模型为例:
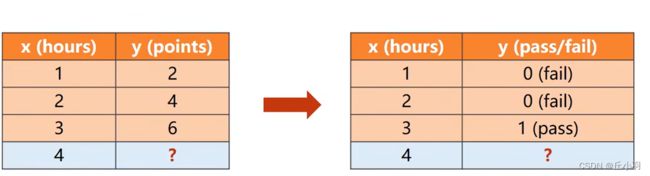
如果我们考虑由前面数据的规律得到的x=4时y的值,我们得到的是一个点数,这是线性回归问题,如果说x=1,2是得到的y=0表示不能通过考试,而当x=3时得到的y=1表示可以通过考试,你们当我们的x=4时得到的y应该表示的是能否通过考试,在这里我们使用分类问题,将我们得到的结果映射为对应的分类。(可以这样理解,每周学习一两个小时的都没有通过,而学习三个小时的通过了,预测学习四个小时的是否能够通过)。
只有两个类别的分类问题,我们称之为二分类。
有多个类别的分类问题,我们称之为多分类问题。
我们要计算的是y=0(没有通过)的概率,和y=1(通过)的概率。二分类其实只需要计算一个值就可以了,因为二分类问题隶属于两个类别的概率值和是1,所以当我们求出一个的概率,可以用1减去这个概率值,得到隶属于另一个类别的概率。
当我们的学习器计算出来隶属于各种类的比例差不多的时候,我们有信心判断,我们的模型对每种类别都没有相应的把握,这个时候就需要质疑学习器的实用性了。我们要做相应的处理,比如我们想输出A种类,但是发现隶属于A种类的概率不足50%,我们就输出“不确定”。或者在二分类问题中,我们隶属于某一种类的概率在0.4到0.6之间,我们也输出“不确定”。

线性回归方程输出的是一个实数,而分类问题输出的是概率,概率值要在0到1之间,所以我们要将线性模型的输出值由实数空间映射到0到1。换句话说,我们需要找到一个函数,将实数的值x转化为概率值0到1,我们通常使用Logistic函数,明显函数的图形超过某个阈值之后,增长非常缓慢。这种函数称为饱和函数,(导数在分界线一边是越来越小,另一边是越来越大)。明显Logistic函数的导数类似正态分布。
看一下其他的sigmoid函数:
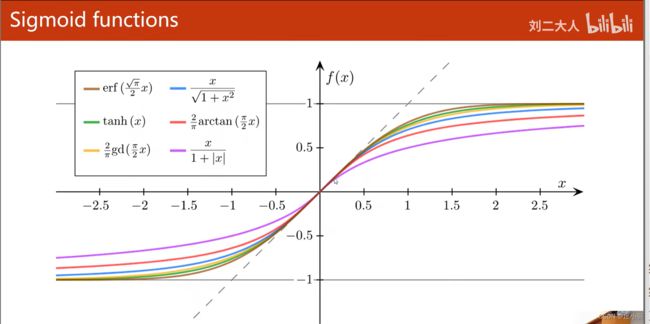
关于这些sigmoid函数,请看链接:点击这里。
这些函数里面最出名的就是Logistic函数,所以在大多数情况下,我们说的sigmoid函数指的是Logistic函数。

在最初的模型中,我们不进行非线性处理,但是在Logistic模型中,我们在进行线性处理后,结果做Logistic函数处理,Logistic函数的函数名,我们直接写成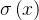 ,以后当我们看到这个符号,就默认是Logistic函数。
,以后当我们看到这个符号,就默认是Logistic函数。
但是我们用到的非线性函数并不一定是把结果映射到0到1之间,有时候我们需要均值是0,那么要映射到-1到1之间。
同理,这时我们需要计算 ,从而才能反向传播算出损失对权重的梯度。很明显,分类问题的回归和线性回归的最大区别就是加了一个Logistic函数(或说是激活函数)。
,从而才能反向传播算出损失对权重的梯度。很明显,分类问题的回归和线性回归的最大区别就是加了一个Logistic函数(或说是激活函数)。
在我们线性回归问题中,残差项表示预测值和真实值在数轴上的距离,是刻画便宜程度的一个量。那么这显然不试用与分类问题。分类问题要怎么计算损失呢?
分类问题的损失不能用几何之间的度量空间来表示,我们要计算分布的差异。
我们可以使用KL散度和交叉熵来计算。
下面来个例子:
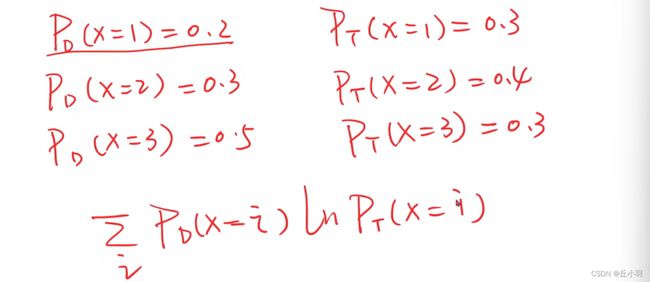
交叉熵越大说明匹配程度越高,所以我们加一个负号表示损失,这时就是交叉熵越大(匹配程度越高),损失越小。
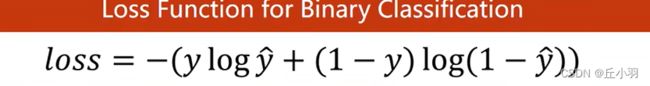
二分类里面所用到的损失函数(即上图函数),我们将其称之为BCE。
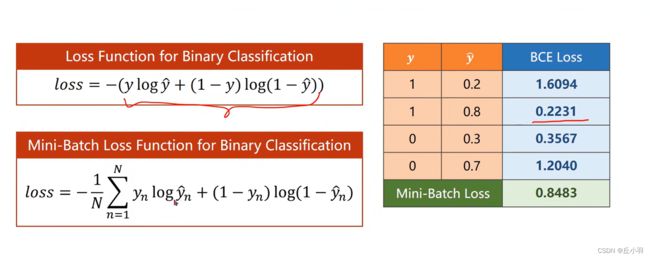
很明显,预测结果和真实结果越接近,其损失就越小,Mini-Batch Loss计算的是小批量损失的均值。
在代码的实现中:调用sigmiod函数(默认是Logistic函数。当然不止有Logistic函数,也有tanh函数,relu函数。)


损失也有不同,在线性模型中,我们使用的是MSE,现在我们使用的是BCE。CE是什么意思呢,就是我们刚刚写的cross-entropy(交叉熵)。

代码中数据输入由数据变成了表分类的映射:

那么我们编写网络模型的时候要做哪些任务呢:
1,准备数据
2,模型构造
3,构造损失和优化器
4,进行训练
数据可视化处理:
首先先在0到10之间选择200个数据点
然后将其转化为200行1列的数组
送进模型中
将结果用数组的方式表示出来
最后将其画出来

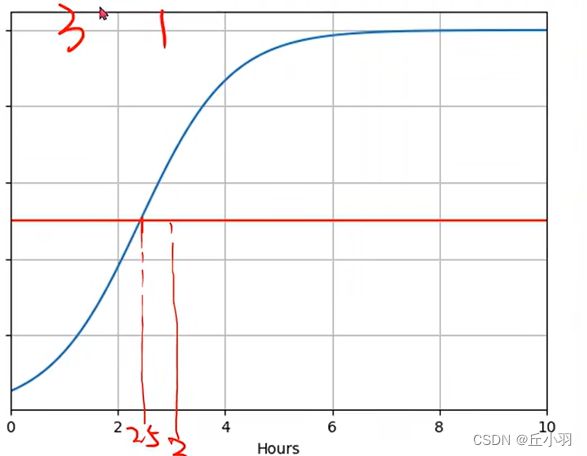
为什么在2.5的时候通过率达到了0.5,因为我们在x=2的时候通过率为0,在x=3的时候通过率是1,那么由线性规则可知,在x=2.5的时候,应该是通过与不通过的分界线。符合我们的生活认知。