开源模型应用落地-KnowLM模型小试-入门篇(一)
一、前言
你是否了解知识图谱?如果了解,你们的业务场景是否应用了知识图谱?实际上,知识图谱在各行各业都被广泛使用。例如,在搜索引擎优化方面,通过利用知识图谱,搜索引擎可以更好地理解网页内容之间的关系,从而提高搜索结果的准确性和相关性。在医药领域,知识图谱可以整合医学知识和临床数据,辅助医生进行诊断和治疗决策,并提供个性化的医疗建议和健康管理服务。
接下来我们将进一步探讨如何利用开源的大型语言模型,以更好地进行知识提取。
二、术语
2.1. 知识图谱
是一种结构化的知识表示方式,用于描述现实世界中的实体和它们之间的关系。它是一种用于组织和表示知识的图形模型,其中的实体和关系被表示为节点和边。
知识图谱使用的常见业务场景:
- 搜索引擎优化(SEO):知识图谱可以帮助搜索引擎理解网页内容之间的关系,提高搜索结果的准确性和相关性。
- 问答系统:知识图谱可以用于构建智能问答系统,使用户能够通过提问获取准确的答案,而不仅仅是关键词匹配。
- 个性化推荐:知识图谱可以分析用户的兴趣、喜好和行为,并为用户提供个性化的推荐内容,例如商品推荐、新闻推荐等。
- 智能客服:知识图谱可以用于构建智能客服系统,通过理解用户问题和上下文,提供准确的答案或引导用户解决问题。
- 企业知识管理:知识图谱可以整合和管理企业内部的大量知识和信息,提供快速的搜索、浏览和分享功能,促进知识的共享和协作。
- 智能助理:知识图谱可以作为智能助理的核心,帮助用户管理日程安排、获取有用信息、执行任务等。
- 数据分析和决策支持:知识图谱可以用于整合和分析大量的结构化和非结构化数据,帮助企业做出更准确的决策和预测。
- 医疗健康:知识图谱可以整合医学知识和临床数据,辅助医生进行诊断和治疗决策,提供个性化的医疗建议和健康管理服务。
- 金融风控:知识图谱可以整合各种金融数据和信息,帮助金融机构进行风险评估、欺诈检测和信用评级等业务。
- 社交网络分析:知识图谱可以分析社交网络中的关系和行为模式,帮助企业和组织发现潜在的合作伙伴、影响者和市场机会。
2.2. 实体
是知识图谱中的核心概念,代表现实世界中的具体或抽象事物。实体可以是人、地点、事件、概念等等。每个实体在知识图谱中通常由一个唯一的标识符表示。例如,在一个包含音乐相关知识的图谱中,歌手、专辑、歌曲可以作为实体。
2.3. 关系
指的是实体之间的连接或相互作用。关系描述了实体之间的某种关联、依赖、属性等。关系可以是有向的或无向的,可以是单值的或多值的。例如,在一个社交网络的知识图谱中,"朋友"关系可以连接一个人实体和另一个人实体,描述他们之间的友谊关系。
2.4. KnowLM
是由浙江大学NLP&KG团队的在读博士生研发并开源的项目,是一种将LLM与知识图谱结合的知识抽取大模型,主要包含的任务有命名实体识别(NER)、事件抽取(EE)、关系抽取(RE)。github 地址:https://github.com/zjunlp/KnowLM/blob/main/README_ZH.md
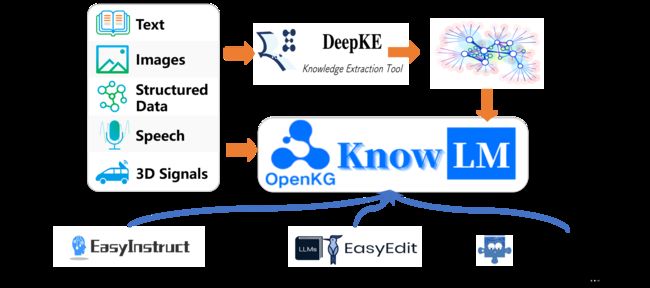
这是KnowLM框架的总览图。主要有三个技术特色:
1.知识提示:基于知识图谱等结构化数据的知识提示生成和知识增强约束技术,解决知识抽取和推理问题
2.知识编辑:基于知识编辑技术对齐大模型内过时、错误及价值观不正确的知识,解决知识谬误问题 (英文版Tutorial)
3.知识交互:基于知识动态交互和反馈实现工具组合学习及多智能体协作,解决大模型具身认知问题 (英文版Tutorial)
三、前置条件
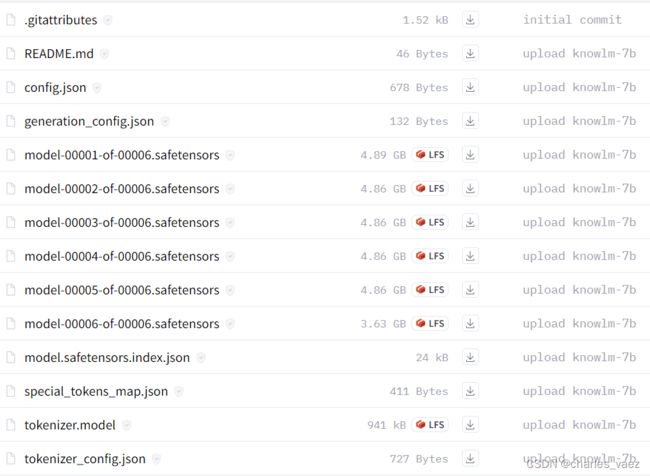
3.1. 下载模型文件
# 基础模型
https://huggingface.co/zjunlp/knowlm-7b-base/tree/main
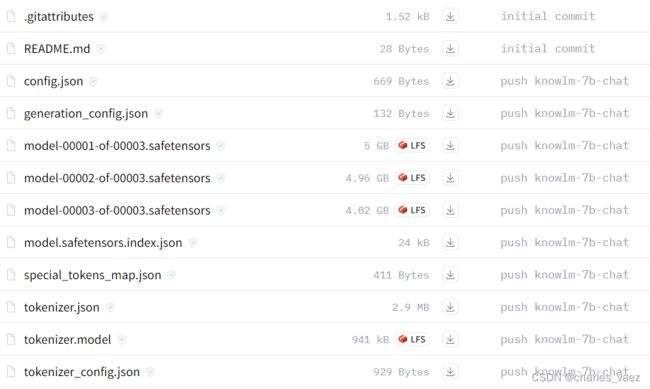
# 对话模型
https://huggingface.co/zjunlp/knowlm-7b-chat/tree/main
PS:
1) 从huggingface中下载
2) modelscope没有对应模型,需要下载其他版本,例如:git clone https://www.modelscope.cn/ZJUNLP/knowlm-13b-ie.git
3.2. windows操作系统(内存≥32GB)
3.3. 安装环境
1) conda create -n knowlm python=3.10 -y
2) conda activate knowlm
3) pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple
4) pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
PS:
1)requirements.txt文件内容如下(要安装特定版本,需要指定版本号):
bitsandbytes
datasets
sentencepiece
fire
accelerate
transformers
peft
四、技术实现
4.1. 加载tokenizer
tokenizer = LlamaTokenizer.from_pretrained(modelPath)4.2.加载model
model = LlamaForCausalLM.from_pretrained(modelPath, device_map="cpu",low_cpu_mem_usage=True).eval()4.3.推理(非流式输出)
generation_output = model.generate(
input_ids=input_ids,
generation_config=generation_config,
return_dict_in_generate=True,
output_scores=True,
max_new_tokens=8192,
)
s = generation_output.sequences[0]
output = tokenizer.decode(s)4.4.完整代码
# -*- coding = utf-8 -*-
import torch
from transformers import GenerationConfig, LlamaForCausalLM, LlamaTokenizer
import time
modelPath = "E:\\model\\knowlm-7b-chat"
response_split = "### Response:"
def get_response(output: str) -> str:
result = output.split(response_split)[1].strip()
result = result.replace('', '')
return result
def generate(model,tokenizer,message,generation_config):
s_format = "{'head':'', 'relation':'', 'tail':''}"
instruction = f"""
Please find the possible head entities (subjects) and tail entities (objects) in the text and give the corresponding relation triples. Please format your answer as a list of relation triples in the form of {s_format}.
"""
prompt = generate_prompt_input(instruction,message)
inputs = tokenizer(prompt, return_tensors="pt")
if torch.cuda.is_available():
input_ids = inputs["input_ids"].to('cuda')
else:
input_ids = inputs["input_ids"]
generation_output = model.generate(
input_ids=input_ids,
generation_config=generation_config,
return_dict_in_generate=True,
output_scores=True,
max_new_tokens=8192,
)
s = generation_output.sequences[0]
output = tokenizer.decode(s)
return get_response(output)
# Generate the prompt for the input of LM model
def generate_prompt_no_input(instruction):
return f"""
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Response:
"""
def generate_prompt_input(instruction,input):
return f"""
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
"""
def loadTokenizer():
tokenizer = LlamaTokenizer.from_pretrained(modelPath)
return tokenizer
def loadModel():
model = LlamaForCausalLM.from_pretrained(modelPath, device_map="cpu",low_cpu_mem_usage=True).eval()
return model
if __name__ == '__main__':
model = loadModel()
tokenizer = loadTokenizer()
start_time = time.time()
generation_config = GenerationConfig.from_pretrained(modelPath, trust_remote_code=True) # 可指定不同的生成长度、top_p等相关超参
message = "Zhang San and I are good friends. This Friday, we went to visit a museum together"
response = generate(model,tokenizer,message,generation_config)
print(f'response: {response}')
end_time = time.time()
print("执行耗时: {:.2f}秒".format(end_time-start_time))
4.5.程序输出
![]()
五、附带说明
5.1. KnowLM项目自带的prompt模板
relation_template = {
0:'已知候选的关系列表:{s_schema},请你根据关系列表,从以下输入中抽取出可能存在的头实体与尾实体,并给出对应的关系三元组。请按照{s_format}的格式回答。',
1:'我将给你个输入,请根据关系列表:{s_schema},从输入中抽取出可能包含的关系三元组,并以{s_format}的形式回答。',
2:'我希望你根据关系列表从给定的输入中抽取可能的关系三元组,并以{s_format}的格式回答,关系列表={s_schema}。',
3:'给定的关系列表是:{s_schema}\n根据关系列表抽取关系三元组,在这个句子中可能包含哪些关系三元组?请以{s_format}的格式回答。',
}
relation_int_out_format = {
0:['"(头实体,关系,尾实体)"', relation_convert_target0],
2:['"关系:头实体,尾实体\n"', relation_convert_target2],
3:["JSON字符串[{'head':'', 'relation':'', 'tail':''}, ]", relation_convert_target3],
}
en_relation_template = {
0: 'Identify the head entities (subjects) and tail entities (objects) in the following text and provide the corresponding relation triples from relation list {s_schema}. Please provide your answer as a list of relation triples in the form of {s_format}.',
1: 'Identify the subjects and objects in the text that are related, and provide the corresponding relation triples from relation {s_schema} in the format of {s_format}.',
2: 'From the given text, extract the possible head entities (subjects) and tail entities (objects) and give the corresponding relation triples. The relations are {s_schema}. Please format your answer as a list of relation triples in the form of {s_format}.',
3: 'Your task is to identify the head entities (subjects) and tail entities (objects) in the following text and extract the corresponding relation triples, the possible relation list is {s_schema}. Your answer should include relation triples, with each triple formatted as {s_format}.',
4: 'Given the text, extract the possible head entities (subjects) and tail entities (objects) and provide the corresponding relation triples, the possible relation list is {s_schema}. Format your answer as a list of relation triples in the form of {s_format}.',
5: 'Your goal is to identify the head entities (subjects) and tail entities (objects) in the text and give the corresponding relation triples. The given relation list is {s_schema}. Please answer with a list of relation triples in the form of {s_format}.',
6: 'Please extract the possible head entities (subjects) and tail entities (objects) from the text and provide the corresponding relation triples from candidate relation list {s_schema}. Your answer should be in the form of a list of relation triples: {s_format}.',
7: 'Your task is to extract the possible head entities (subjects) and tail entities (objects) in the given text and give the corresponding relation triples. The relations are {s_schema}. Please answer using the format of a list of relation triples: {s_format}.',
8: 'Given the {s_schema}, identify the head entities (subjects) and tail entities (objects) and provide the corresponding relation triples. Your answer should consist of relation triples, with each triple formatted as {s_format}',
9: 'Please find the possible head entities (subjects) and tail entities (objects) in the text based on the relation list {s_schema} and give the corresponding relation triples. Please format your answer as a list of relation triples in the form of {s_format}.',
10: 'Given relation list {s_schema}, extract the possible subjects and objects from the text and give the corresponding relation triples in the format of {s_format}.',
11: 'Extract the entities involved in the relationship described in the text and provide the corresponding triples in the format of {s_format}, the possible relation list is {s_schema}.',
12: 'Given relation list {s_schema}, provide relation triples for the entities and their relationship in the text, using the format of {s_format}.',
13: 'Extract the entities and their corresponding relationships from the given relationships are {s_schema} and provide the relation triples in the format of {s_format}.',
}
en_relation_int_out_format = {
0: "{'head':'', 'relation':'', 'tail':''}",
1: "(Subject, Relation, Object)",
2: "[Subject, Relation, Object]",
3: "{head, relation, tail}",
4: "",
}