cs231n作业-assignment1
assignment 1 (cs231n)
文章目录
- assignment 1 (cs231n)
-
- KNN基础
-
- 计算distances 方法一:双层循环
- 计算distances 方法二:单层循环
- 计算distances 方法三:无循环
- 根据dists找到每个测试样本的种类
- KNN模型汇总
- 交叉验证
KNN基础
计算distances 方法一:双层循环
- dists矩阵是(num_test, num_train)500 * 5000
def compute_distances_two_loops(self, X):
# 双层嵌套循环
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
for i in range(num_test):
for j in range(num_train):
# 对每个测试样本求其与每个训练集的欧式距离(低效very inefficient)
dists[i][j] = np.sum( (X[i,:] - self.X_train[j,:]) ** 2 ) ** 0.5 # array ** 2得到的是每个元素的2次方的array
# 等价于 dist[i][j] = np.sum((X[i]-self.X_train[j]) **2 ) ** 0.5
return dists
计算distances 方法二:单层循环
- 广播机制,X[i]向量和self.X_train矩阵作差会有广播效应
- 利用np.sum(,axis=1)求出矩阵每行的sum值,得到5000个结果。
def compute_distances_one_loop(self, X):
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
for i in range(num_test):
# 对每个测试样本一下求出其与训练集中所有样本的距离(按行求和很重要)
dists[i] = np.sum((X[i] - self.X_train) ** 2, axis = 1) ** 0.5
return dists
计算distances 方法三:无循环
-
要得到一个(num_test, num_train) 500*5000的距离矩阵
-
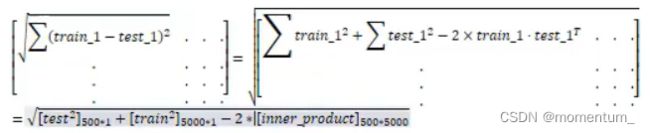
-
用2*3示例,num_test=2,num_train=3

展开后,观察到每行的 ∑ X t e s t \sum X_{test} ∑Xtest相等,每列的 ∑ X t r a i n \sum X_{train} ∑Xtrain相等。

这就可以将 X t e s t X_{test} Xtest视作两行一列 ( M , 1 ) (M,1) (M,1),(按行对平方求和), 在横向广播,将 X t r a i n X_{train} Xtrain视作一行三列 ( 1 , N ) (1,N) (1,N),在竖向广播

def compute_distances_no_loops(self, X):
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
xx = np.sum(X**2, axis=1, keepdims=True) # 按行求和并保持维数(2)不变; 维度为(500,1),若不加keepdims则shape为(500,)
yy = np.sum(self.X_train**2, axis=1) # (1,5000) 实际是(5000,), 此处二者等价(可证实,底层ru)
# 自我认为最好 yy = np.sum(self.X_train**2, axis=1).reshape(1,5000) # 将此处的秩为1的数组(5000,)转为行向量(1,5000)
_2xy = -2 * X.dot(self.X_train.T) # (500,3072) * (5000,3072).T = (500,5000)
dists = (xx + yy ++ _2xy) ** 0.5 # (500,5000)
# 做法二,直接了当,reshape就完了
# xx = np.sum(X**2, axis=1).reshape(500,1) # (1,500) 等价于reshape(-1,1)
# yy = np.sum(self.X_train**2, axis=1).reshape(1,5000) # (1,5000) 等价于reshape(1,-1)
# _2xy = -2 * X.dot(self.X_train.T) # X:(500,3072) * Y:(5000,3072).T = (500,5000)
# dists = (xx + yy + _2xy) ** 0.5
return dists
为啥方法二比方法一还慢?因为广播占用了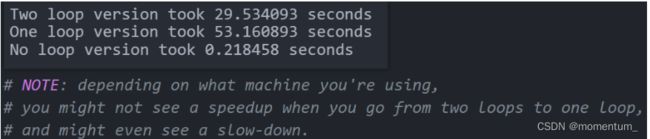
一定的资源
根据dists找到每个测试样本的种类
-
根据dists矩阵找到与各个测试样本前k小的训练样本,将其类别存入closest_y
- 利用np.argsort()返回一个list,第一个元素表示第一小的数据的索引值
- 利用列表推导式生成一个k长的closest_y列表,而非用append函数
- 利用Counter对closest_y进行计数,然后利用most_common(1)[0][0]得到该类别
def predict_labels(self, dists, k=1): closest_y = [] num_test = dists.shape[0] y_pred = np.zeros(num_test) # 初始化一个array for i in range(num_test): # 先根据dists矩阵找到距离测试样本k最近的训练样本,并保存其标签到closest_y idx = np.argsort(dists[i]) # 从小到大给dist排序,返回索引 closest_y = [self.y_train[x] for x in idx][:k] # 取出该列表生成器的前k个 # 方法二 #for j in range(k): # closest_y.append(self.y_train[idx[j]]) # 第一小的是idx[0] # 方法三 #closest_y = [self.y_train[idx[x]] for x in range(k)] # 接着找到closest_y中k个频次最多的标签 # closest_y: 类似[1,4,7,1,...,..]共k个结果 c = Counter(closest_y) # 传入list y_pred[i] = c.most_common(1)[0][0] # 查看最常见的1个种类,获取列表第一个元组的第一个元素 return y_pred
KNN模型汇总
class KNN:
def __init__(self,X_train,y_train,k=3,p=2):
# k邻近取k=3, 距离度量p=2
self.k = k
self.p = p
self.X_train = X_train
self.y_train = y_train
def predict(self,X): # X为待预测点
# 以下两个for循环找到了训练集中各点距离点X最小的k个点
knn_list = []
for i in range(self.k):
dist = np.linalg.norm(X-self.X_train[i], ord=self.p) #范数ord等于self.p
knn_list.append((dist,self.y_train[i])) # 将距离和该样本的分类结果 组合成元组存入list
for i in range(self.k,len(self.X_train)): #训练集中排除前k个之外的样本
''' 每次取出k个点列表中的最大距离的点 用剩下训练集中小于该距离的训练样本替换掉,
以期找到训练集中距离最近的k个样本'''
max_index = knn_list.index(max(knn_list,key=lambda x: x[0]))
# index是取索引; key参数可用匿名函数控制取最大值的方式,此处为按第一位取最大值
dist = np.linalg.norm(X-self.X_train[i], ord=self.p) #训练集k之外的距离
if knn_list[max_index][0] > dist:
knn_list[max_index] = (dist,self.y_train[i]) # 替换
# 统计
knn = [k[-1] for k in knn_list] # knn是k个集合的类别
count_pairs = Counter(knn) # Counter是统计knn中各类别的个数
# count_pairs.iterms()将字典转换为 第二维是value(各类别的次数)
max_count = sorted(count_pairs.items(),key=lambda x:x[-1])[-1] # 得到类别样本数最多的dict
max_count_label = max_count[0] # 得到类别
return max_count_label
def score(self,X_test,y_test):
right_count = 0
n = 10
for X,y in zip(X_test,y_test):
pre_label = self.predict(X)
if pre_label == y:
right_count+=1
return right_count/len(X_test) # 返回正确率
交叉验证
把训练集分成训练集和验证集。使用验证集来对所有超参数调优。最后只在测试集上跑一次并报告结果。
交叉验证适合训练集数量较小时使用,但是比较麻烦,耗费更多的资源,所以现实中不是很常用。
# k折交叉验证
num_folds = 5 # 折叠次数
k_choices = [1, 3, 5, 8, 10, 12, 15, 20, 50, 100] # KNN中k的选择
X_train_folds = []
y_train_folds = []
X_train_folds = np.array_split(X_train, num_folds) # 将二者划分为num_folds段,得到一个含有5个array的list
y_train_folds = np.array_split(y_train, num_folds) # len 均为5
k_to_accuracies = {} # 该字典存储不同k值的准确度
for kc in k_choices:
k_to_accuracies[kc] = [] # 给字典输入key为kc,value为[]
for i in range(num_folds):
# 因为此时的训练集与原来(5000,3072)不同,所以需要重新训练模型
# 先拿出验证集,因为5次中,验证集分别不同,剩下的是训练集
_X_val = X_train_folds[i]
_y_val = y_train_folds[i]
# 拿出训练集
# vstack将四段训练集竖向拼接起来,使样本数量增加
# 此列表推导式返回的是一个ndarray的list!!!然后vstack将这个含有4个array(1000,3072)的list 竖向拼接起来 -> (4000,3072)(因为一行是一个训练样本)
_X_train = np.vstack([X_train_folds[j] for j in range(num_folds) if j != i])
_y_train = np.hstack([y_train_folds[j] for j in range(num_folds) if j != i]) # 将4个array(1000,)横向拼起来 -> (4000,)
# 训练
classifier = KNearestNeighbor()
classifier.train(_X_train, _y_train)
dists = classifier.compute_distances_no_loops(_X_val) # 验证集(1000,3072) 与 训练集(4000,3072) -> (1000,4000)
y_val_pred = classifier.predict_labels(dists, k=kc) # (1000,)
num_correct = np.sum(y_val_pred == _y_val) # sum中True即为1
accuracy = float(num_correct) / len(_y_val)
k_to_accuracies[kc].append(accuracy)
# k是key,即1,3,5,8,10...,每个key对应的value是一个列表,存的就是5个accuracy
# Print out the computed accuracies
for k in sorted(k_to_accuracies):
for accuracy in k_to_accuracies[k]:
print('k = %d, accuracy = %f' % (k, accuracy))