SIGIR22:Bilateral Self-unbiased Learning from Biased Implicit Feedback
Bilateral Self-unbiased Learning from Biased Implicit Feedback
摘要
本文中,作者提出了一个新的无偏推荐学习模型,称为双边自无偏推荐(Bilateral Self-unbiased Recommender,BISER),用以消除项目的曝光偏差。BISER由自逆倾向权重(Self-inverse Propensity Weighting,SIPW)和双向无偏学习(Bilateral unbiased learning, BU)两个部分组成,SIPW逐步消除项目偏差,BU用于弥补基于用户的以及基于项目的两个自动编码器之间的差距,消除SIPW的高方差。
1 简介
协同过滤是目前构建推荐系统最流行的技术。协同过滤经常使用两种用户反馈:显式和隐式反馈。显式反馈提供了更加丰富的用户偏好,因为用户精确地评估了他们有多喜欢或者不喜欢项目。然而,在多样的真实世界应用中收集精确反馈是很困难的,因为很少的用户会在体验了项目之后会提供反馈。另一方面,隐式反馈很容易通过记录很多的用户行为来进行收集,例如点击链接、购买产品或者浏览网页。
在协同过滤中使用隐式反馈存在着一些挑战:(i)现存的研究将观测的用户交互仅当作正反馈,例如点击一个项目或者查看一个页面,并不表示用户是否喜欢该项目。(ii)用户反馈是被一致地进行观察,而不是随机的。例如,用户倾向于与流行的项目进行交互,所以项目越流行,在训练数据集中该数据收集得越多。因为隐式用户-项目交互的内生特点,推荐系统在排序的时候更倾向于给流行的项目更高的优先级。
现有的研究提出了一些无偏推荐学习方法来从隐式反馈中估计真实的用户偏好,这些方法都是基于非随机缺失(missing-not-at-random, MNAR)假设。这些工作使用逆倾向得分来形式化了一个新的损失函数来消除项目的偏差。此外,最近的研究将因果图纳入来表示推荐中的因果效应联系,然后移除项目流行度的效应。
这些方法主要分成两个方向。第一种是探索一种启发式函数来消除项目的流行度偏差。虽然项目流行度是训练数据偏差的一个重要因素,但是这里还有其他的重要因素,例如曝光偏差。为了克服这些问题,第二个方式提出了基于学习的方法来考虑多样的偏差因素。联合学习方法首先提出了使用从一个额外的模型中得出的伪标记或者倾向得分。Zhu等人[63]对训练数据集的不同子集施加了多个模型来推断倾向得分。Saito[37]采用了两个预训练模型以及其他参数初始化,并且生成了一个伪标签来作为两个模型预测之间的差异。他们通过训练多个模型来利用一致的预测。然而,由于多个模型会收敛到相似的输出,会导致估计重叠的问题。最近,提出了基于因果图训练的方法 [54, 61] 来克服 IPW 策略的敏感性。Wei等人 [54] 利用物品流行度和用户一致性建立因果图来预测真实相关性。Zhang等人 [61] 通过因果图分析物品流行度的负面影响,并通过因果干预消除偏见。然而,它们并没有解决推荐模型导致的曝光偏差问题。
为了消除曝光偏差,作者提出了一种新型的无偏推荐学习方法,称为双边自无偏推荐(BIlateral SElf-unbiased Recommender, BISER),该模型由两个关键部分组成:自逆倾向加权(SIPW)以及双边无偏学习(BU)。受到自蒸馏(self-distillation)[30, 58]的启发,作者首先使用一个自逆倾向加权,随着训练的深入,重用之前训练迭代的模型预测,迭代地减弱项目的曝光偏差。注意到,SIPW由两个关键的优势:(i)快速地处理由推荐模型产生的曝光偏差,(ii)并不需要额外的模型来进行倾向分数估计。
IPW常常有高方差的问题,比如在[54,61]中提到的。为了解决这一问题,首先假设真实的用户偏好应该与不同模型的预测一致。然后设计了一个使用两个推荐模型的双向无偏学习(BU),使用基于用户的以及基于项目的自编码器[41]。由于它们捕捉了用户和物品方面不同的隐藏模式,因此不需要我们从整个训练集中分割训练和估计子集[63]或使用具有不同参数初始化的多个模型[37]。我们利用一个模型的预测值作为另一个模型的伪标签。因此,我们解决了估计SIPW时高方差问题。
总结下来,论文的主要贡献如下:
- 回顾了现有无偏推荐学习的研究并且分析了他们消除模型产生的曝光偏差的局限性。
- 提出了一个新的无偏推荐学习模型,称为双向自无偏推荐,使用了(i)一个基于学习的倾向分数估计方法,即自逆倾向加权(SIPW)以及,(ii)双边无偏学习学习(BU),使用具有互补关系的基于用户和项目的自编码器。
- 证明了BISER的优越性
2 背景
形式上,用 U \mathcal{U} U来表示m个用户的集合,用 I \mathcal{I} I表示n个项目的集合。给定一个用户-项目矩阵 Y ∈ { 0 , 1 } m × n Y\in \{0,1\}^{m\times n} Y∈{0,1}m×n,
y u i = { 1 如果用户 u 和项目 i 进行了交互; 0 其他情况。 y_{ui}=\begin{cases}1&如果用户u和项目i进行了交互;\\0&其他情况。\end{cases} yui={10如果用户u和项目i进行了交互;其他情况。
对 y u i y_{ui} yui建模为一个伯努利随机变量,表示用户 u u u对项目 i i i的交互。对于隐式反馈数据,用户交互是观测以及偏好的结果。也就是说在(i)项目被展示给用户并且用户感知到了项目(曝光),(ii)用户是真的喜欢该项目(相关)的情况下,用户可能点击一个项目,现有的研究[6,33,38-40,63]将该思想形式化如下:
P ( y u i = 1 ) = P ( o u i = 1 ) ⋅ P ( r u i = 1 ) = ω u i ⋅ ρ u i , (2) P(y_{ui}=1)=P(o_{ui}=1)\cdot P(r_{ui}=1)=\omega_{ui}\cdot \rho_{ui},\tag{2} P(yui=1)=P(oui=1)⋅P(rui=1)=ωui⋅ρui,(2)
其中的 o u i o_{ui} oui是观测矩阵 O ∈ { 0 , 1 } m × n O\in\{0,1\}^{m\times n} O∈{0,1}m×n的一个分量,表示用户 u u u已经观测到项目 i i i( o u i = 1 o_{ui}=1 oui=1)或者没有( o u i = 0 o_{ui}=0 oui=0),这里的 r u i r_{ui} rui是相关矩阵 R ∈ { 0 , 1 } m × n R\in \{0,1\}^{m\times n} R∈{0,1}m×n的一个分量,表示在观测下的真实关联。如果用户 u u u喜欢项目 i i i,那么 r u i = 1 r_{ui}=1 rui=1,否则的话 r u i = 0 r_{ui}=0 rui=0。为了简化,将 P ( o u i = 1 ) P(o_{ui}=1) P(oui=1)以及 P ( r u i = 1 ) P(r_{ui}=1) P(rui=1)分别表示为 ω u i \omega_{ui} ωui以及 ρ u i \rho_{ui} ρui。有偏用户行为的交互矩阵 Y Y Y被分解成观察分量和相关分量的逐元素相乘。
无偏推荐学习
我们的目标是从MNAR假设下的隐式反馈中学习一个无偏的排序函数。尽管有各种各样的损失函数可以用于训练推荐模型,例如点对点、成对和列表损失[34],但本文使用点对点损失函数。给定一个用户-项目对的集合 D = U × I \mathcal{D}=\mathcal{U}\times\mathcal{I} D=U×I,偏差交互的损失函数为
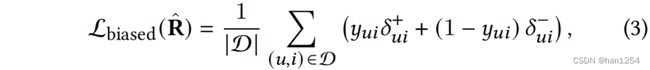
这里的 R ^ \hat{R} R^为 R R R的预测矩阵, δ u i + \delta_{ui}^+ δui+和 δ u i − \delta_{ui}^- δui−分别为用户 u u u对项目 i i i的正负偏好的损失。在点对点损失设定下,采用交叉熵或者平方和损失。例如使用交叉熵,那么 δ u i + = − log ( r ^ u i ) \delta_{ui}^+=-\log (\hat{r}_{ui}) δui+=−log(r^ui), δ u i − = − log ( 1 − r ^ u i ) \delta_{ui}^-=-\log (1-\hat{r}_{ui}) δui−=−log(1−r^ui)
相似地,理想的损失函数仅仅依赖相关性,表示如下:
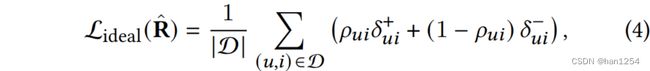
这里的存偏观测 y u i y_{ui} yui别替换成纯相关性 ρ u i = P ( r u i = 1 ) \rho_{ui}=P(r_{ui}=1) ρui=P(rui=1)。
因为用户交互数据常常是稀疏的,并且是在MNAR假设下收集的,所以需要弥合点击和相关性之间的差距。Saito等人[39]提出了一个使用逆倾向得分的损失函数:
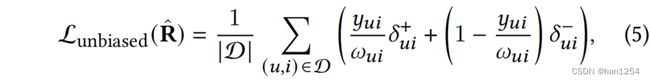
这里的 ω u i \omega_{ui} ωui是表示通过用户 u u u观测到项目 i i i的概率的逆倾向得分。在[39]中证明,等式(5)中无偏损失函数的期望值与等式(4)中的理想损失函数等价:
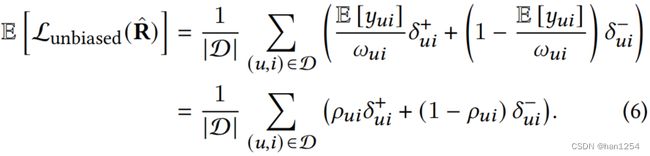
重要的问题是,如何从观测反馈中估计该倾向得分 ω u i \omega_{ui} ωui。之前的研究[23,33,38,39]已经发展出一些估计 ω u i \omega_{ui} ωui的方法。第一种[23,38,39]引入了一个启发式函数来估计项目的流行度,并没有使用一个额外的模型。虽然符合直觉,但是该方法仅仅集中于消除项目的流行度,因此,无法处理由于推荐系统本身造成的曝光偏差。第二种,使用额外的模型来估计倾向分数[33,63]。然而,这导致了很高的计算损失,因为它们大部分都使用了三个或者更多的模型。
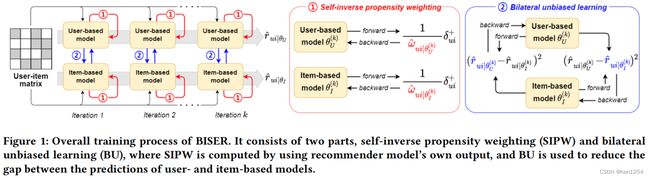
3 BISER
为了推动无偏推荐系统的建模,作者首先从一个传统的推荐模型,例如MF和AE,在MovieLens-100K数据集上研究了偏差。图二(a)和(c)中描述了一个对点击项目的评级预测分数和训练集中的评分数量之间的正相关关系,即流行度。从该案例研究中,作者确认,在传统的推荐模型中,流行的项目倾向于被推荐给更多的用户。更糟糕的是,存偏的推荐会恶化训练数据集的偏差,因为用户反馈是被持续收集的。
为了解决这一问题,消除由推荐系统造成的曝光偏差是很重要的。现有的研究[38,39]大都集中于对项目的流行度偏差进行建模。因为用户体验大都会对推荐的项目有所偏向,作者旨在消除由推荐模型产生的曝光偏差。首先估计项目的倾向分数并且在模型训练时期来消除曝光偏差。图二(b)和(d)展示了提出的无偏学习方法的有效性。很明显地看到,提出的模型中预测评分和项目的流行度之间的联系比传统的模型之间更弱。点分析表示作者提出的模型可以有效地减少由推荐模型产生的曝光偏差。

3.1 模型架构
模型分为两个部分,一个自逆倾向加权和一个双边无偏学习,如图一所示。自蒸馏在模型训练期间,从模型的预测中抽取知识,受到自蒸馏[30,58]的启发,作者使用一种迭代的方法来估计逆倾向加权。因此,提出的模型在模型训练期间逐渐消除项目的曝光偏差。这种方式是有效的,因为其既不需要一个预定义的倾向评分函数,也不需要一个额外的倾向估计模型。
在该过程中,作者采用了两个具有互补特性的推荐模型——基于用户的和基于项目的自编码器,分别从用户和项目的角度来捕获异构语义和联系信息。这种方式避免了当多个具有相同结构并在相同训练集上训练的模型的输出收敛相似时发生的估计重叠问题。此外,作者还强调了他们提出的方法是模型不可知的;可以使用两个或更多个模型,只要它们从用户-项目交互数据中传递异构信号。
自逆倾向加权(SIPW)
现有的消除曝光偏差的研究主要有两种方法,(i)只对项目流行度进行建模,因为项目的流行度影响用户的点击行为,不适用额外的估计器[38, 39];(ii)采用额外的模型通过交替进行相关性和观测估计来估计曝光偏差[63]。Zhu等人[63]将整个数据集分成多个训练和估计子集,导致了高昂的计算成本。
本文中,作者形式化了一个新的偏差估计方法,称为自逆倾向加权(self-inverse propensity weighting,SIPW)。首先,引入一个使用交互数据的理想无偏推荐模型。给定一个用户 u u u的推荐列表 π u \pi_{u} πu,则用户与一个项目 i i i交互的概率表示为:
P ∗ ( y u i = 1 ∣ π u ) = P ∗ ( o u i = 1 ∣ π u ) ⋅ P ( r u i = 1 ∣ π u ) (7) P^*(y_{ui}=1|\pi_{u})=P^*(o_{ui}=1|\pi_{u})\cdot P(r_{ui}=1|\pi_{u})\tag{7} P∗(yui=1∣πu)=P∗(oui=1∣πu)⋅P(rui=1∣πu)(7)
这里的 P ∗ ( o u i = 1 ∣ π ) P^*(o_{ui}=1|\pi) P∗(oui=1∣π)是理想的观测到项目 i i i的概率,即完全随机分布。此外,估计存偏模型中用户 u u u和项目 i i i交互的概率如下:
P ^ ( y u i = 1 ∣ π u ) = P ^ ( o u i = 1 ∣ π u ) ⋅ P ( r u i = 1 ∣ π u ) (8) \hat{P}(y_{ui}=1|\pi_{u})=\hat{P}(o_{ui}=1|\pi_{u})\cdot P(r_{ui}=1|\pi_{u})\tag{8} P^(yui=1∣πu)=P^(oui=1∣πu)⋅P(rui=1∣πu)(8)
这里的 P ^ ( o u i = 1 ∣ π u ) \hat{P}(o_{ui}=1|\pi_u) P^(oui=1∣πu)是对观测到项目 i i i的估计概率。
通过结合它们,可以将IPS估计为两个交互概率分布之间的比例。注意到该公式和无偏学习排序算法(unbiased learning-to-rank)[49]。
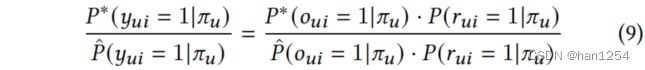
假设 P ∗ ( o u i = 1 ∣ π u ) P^*(o_{ui}=1|\pi_u) P∗(oui=1∣πu)遵守均匀分布, π u \pi_u πu中的每个项目的概率被简单地认为是一个常数,因此估计一个倾向分数 ω ^ u i \hat{\omega}_{ui} ω^ui为:
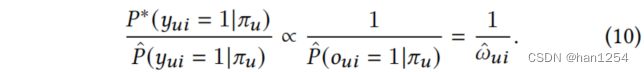
剩余的问题是,如何估计用户 u u u观测到项目 i i i的概率 ω ^ u i \hat{\omega}_{ui} ω^ui。受到自蒸馏[35, 58]的启发,在模型训练的过程中使用模型预测的知识,重用模型预测作为 ω ^ u i \hat{\omega}_{ui} ω^ui。虽然简单,可自倾向还有很多好处:(i)SIPW方法通过正则化先验知识稳地估计 ω ^ u i \hat{\omega}_{ui} ω^ui,逐渐移除偏差;(ii)该方法不需要一个额外的推理过程来估计倾向分数;(iii)由于模型不可知的特点,该模型可以被用于不同的推荐系统,如MF或者AE。
作者将使用了SIPW的无偏损失函数总结如下:
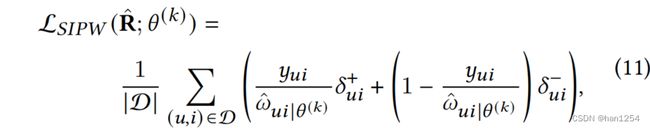
这里的 θ ( k ) \theta^{(k)} θ(k)是第k次迭代时的模型参数, ω ^ u i ∣ θ ( k ) \hat{\omega}_{ui|\theta^{(k)}} ω^ui∣θ(k)是第k次迭代时的自倾向分数。
双边无偏学习(BU)
虽然IPW是基于可靠的理论证明的一种方法,但是在实际应用中往往会由于其高方差问题[11, 44, 51]导致次优的性能。一个现有的研究[37]训练多模型,每个模型的预测被用作其他模型的伪标签。伪标签然后被用来正则化原始模型。
ChatGPT: 在机器学习中,正则化(regularization)是一种常用的技术,它的目的是为了减少模型的过拟合(overfitting)风险。正则化通过对模型的复杂性进行惩罚(penalty),来控制模型的复杂度,从而避免过拟合。
正则化方法通常会在目标函数中添加一个惩罚项,该项对模型中的某些参数进行限制,以降低模型复杂度。例如,L1正则化通过添加参数向量的L1范数惩罚项来促使某些参数变为0,从而实现特征选择的目的。而L2正则化通过添加参数向量的L2范数惩罚项来缩小参数的值,防止参数过大而导致过拟合。
正则化是机器学习中常用的一种技术,它可以帮助提高模型的泛化能力,从而使得模型能够更好地适应新的数据。
虽然该方法帮助消除了高方差问题,但是多模型可能在训练时表现出相似的趋向。
为了解决这一问题,作者使用了两个特性不同的推荐模型。联合基于用户以及基于项目的推荐模型来改进传统推荐模型[47,57,64]中的预测。因为两部分倾向于捕获用户和项目模式的不同方面,采用异构模型来帮助缓解估计重叠问题。
更精确地讲,作者使用基于用户和基于向的自编码器来从复杂的用户项目交互中挖掘特有的补偿模式。
ChatGPT: 在机器学习中,"compensating patterns"指的是在数据集中存在的一些相互抵消的模式,这些模式可以导致模型出现错误的结论。当存在相互抵消的模式时,模型可能会出现过拟合,从而导致在测试数据上表现较差。
举例来说,假设有一个二分类问题,数据集中的正类样本具有属性A和属性B,而负类样本只有属性A。如果模型过于关注属性A,那么它可能会出现过拟合,导致在测试集上表现较差。但是,如果模型过于关注属性B,那么它可能会错误地将负类样本分类为正类。在这种情况下,属性A和属性B之间存在一种相互抵消的关系,这就是"compensating patterns"。
为了避免"compensating patterns"对模型的影响,通常需要对数据进行预处理、特征选择或使用正则化等技术来降低模型的复杂度,并避免过拟合。
受到标签迁移[3, 26]的启发,两个模型应该收敛到相同的值来正确地估计真实联系:
P ( r u i = 1 ∣ y u i = 1 , θ U ) = P ( r u i = 1 ∣ y u i = 1 , θ I ) (12) P(r_{ui}=1|y_{ui}=1,\theta_U)=P(r_{ui}=1|y_{ui}=1,\theta_I)\tag{12} P(rui=1∣yui=1,θU)=P(rui=1∣yui=1,θI)(12)
这的 θ U \theta_U θU和 θ I \theta_I θI分别是基于用户和基于项目的自编码器的参数[41]。最终,使用两个模型预测来表示双边无偏学习的损失函数。
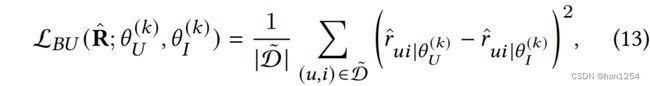
这里的 r ^ u i ∣ θ U ( k ) \hat{r}_{ui|\theta_U^{(k)}} r^ui∣θU(k)以及 r ^ u i ∣ θ I ( k ) \hat{r}_{ui|\theta_I^{(k)}} r^ui∣θI(k)分别是每个模型第k次迭代的预测, D ~ \tilde{\mathcal{D}} D~是观测到的用户-项目对的集合。
3.2 训练和推理
给定基于用户和基于项目的自编码器,每个模型都使用SIPW从头开始训练。每一步通过最小化等式(11)中的损失来更新模型参数。然后利用损失函数来最小化两个模型预测之间的差异。以 θ U ( k ) \theta_U^{(k)} θU(k)为参数的基于用户的模型使用以 θ I ( k ) \theta_I^{(k)} θI(k)为参数的基于项目的模型预测作为伪标签,反之亦然。因此,可以通过使用两个模型的预测来减少SIPW的高方差问题。
基于等式(11)和(13),推导最终的损失函数来在第k次迭代同时训练两个模型:
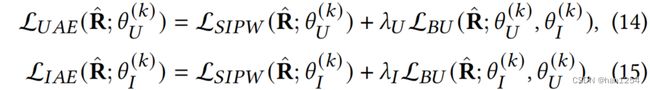
这里的 λ U \lambda_U λU和 λ I \lambda_I λI都是用来控制 L B U \mathcal{L}_{BU} LBU重要性的超参数。
一旦模型训练终止,两个模型的偏差从用户以及项目的角度都被消除了。从不同的角度统一用户偏好,可以改进模型的预测[47, 57, 64]。最终,使用两个模型预测的平均分来进行最终的评分。
r ^ u i = r ^ u i ∣ θ U + r ^ u i ∣ θ I 2 (16) \hat{r}_{ui}=\frac{\hat{r}_{ui|\theta_U} + \hat{r}_{ui|\theta_I}}{2}\tag{16} r^ui=2r^ui∣θU+r^ui∣θI(16)
BISER的伪代码在算法一中展示。在学习过程中,模型首先初始化 θ U \theta_U θU和 θ I \theta_I θI。然后使用之前循环的模型预测, θ U \theta_U θU和 θ I \theta_I θI通过等式(14)和等式(15)分别进行更新。每一次迭代,计算所有用户项目点击对的预测分数。在两个模型的训练终止后,使用模型的预测获得预测矩阵 R ^ \hat{R} R^。