LSM-Tree(一):初识
写在前面:本篇博客为综述《LSM-based Storage Techniques: A Survey》的学习笔记(一),该综述介绍了 LSM-Tree 的前世今生、思想本质、性能权衡、面临问题、优化方案等等,也是我正式接触 LSTM-Tree 的入门导师。综述对 leveling、tiering、partition 等核心观念进行了较为详细的介绍,对 LSM-Tree 的本质理解还是很有帮助的。不过,毕竟只是一篇综述,想要看清 LSM-Tree 光靠这一篇肯定是不够的,所以还参考了其他的博客。
好了,我们开始。
文章目录
-
- LSM-Tree 诞生之前
- 早期 LSM-Tree
- LSM-Tree 基本结构
-
- leveling & tiering
- partition
-
- partitioned leveling
- partitioned tiering
-
- vertical grouping
- horizontal grouping
- 为什么要分区
- 优化问题
都知道,现在的存储体系大多分为 SQL 和 NoSQL,后者即 K-V 存储,LSM-Tree 就是为它服务的一种底层数据结构。现行的大部分 K-V 存储,比如 Rocksdb、Badger 等底层用的都是 LSM-Tree,虽然进行了一定的优化与变式,但本质还是 LSM。所以,LSM-Tree 是什么?为什么要用到 LSM-Tree,要搞清楚这个问题,就需要先明白在 LSM-Tree 出现之前,K-V 存储是什么样的。
LSM-Tree 诞生之前
一般来讲,K-V 存储在更新时有两种方案供选择,一种叫就地更新(in-place),一种叫地外更新(out-of-place)。所谓就地更新,就是直接将原来的记录改了,换成新的记录,比如把
于此相反,地外更新不会直接更改原来的

地外更新随后成为主流,它为记录的存储提供了一种新的思路:顺序日志。比如早期的 Postgres 项目,会把所有的写操作附件到一个顺序日志中去,只有当原记录过时后才由垃圾回收机制清理,而不是当场覆盖原记录。
但是很明显,如果日志的结构仅仅是顺序的,那必然不是最优的,因为记录之间潜在的联系没有被利用,大家都像栈元素一样一个一个 push 进日志,肯定是不行的。所以就引出了新的问题,如何进行合理的日志结构化?这就是 LSM 中的 LS 所指的含义,Log-Structured。
那 Merge 指什么呢?实际上,对于某一个 key,除了最新的那条记录外,其他的记录都是冗余无用的,但是仍然占用了存储空间,所以需要不定期的去进行 Merge 来清除掉冗余的记录,而这就是 LSM-Tree 的核心内容。
早期 LSM-Tree
为了解决上面说的问题,LSM-Tree 诞生。就像其名字一样,LSM-Tree 设计的初衷,就是对日志进行一定的合并(merge),来进行冗余记录的清除,并利用合适的日志结构与合并策略来提高写性能。
最开始的 LSM-Tree,由一系列的组件构成,我们把它们记作 C0、C1 … Ck。每一个组件内部都是一个 B+ 树,(当然,到后期就不是了,不过这里先不管)。C0 驻留在内存中,为传入的写操作提供服务,而其余的所有 C 均驻留在磁盘中,进行真正的数据存储。所有的组件之间都是递进的,当且仅当 Ci 存满的时候,会触发合并进程,将 Ci 中的一系列叶页面(leaf page)合并到 Ci+1 中,然后 Ci 继续等待来自 Ci-1 的合并,以此类推。这种策略叫作滚动合并。
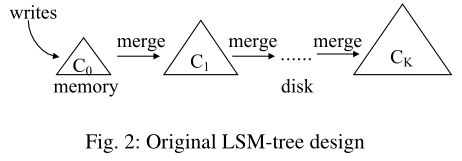
值得注意的是,只有当所有组件之间的大小比 Ti = |Ci + 1|/|Ci| 相同时,写入性能才得到优化。我不知道为什么,在 LSM-Tree 的原始论文中有推导,不过我没看,私以为记个结论就行。这一个结论,直接影响到后续有关 LSM-Tree 的实现与优化。
LSM-Tree 基本结构
如今的 LSM-Tree 实现仍然应用地外更新来减少随机 I/O。所有写操作都附加到内存组件中。插入或更新操作只是添加一个新条目,而删除操作则添加一个反事项条目,表明某个键已被删除。当组件满时,多个组件会合并为一个新的组件,而无需修改现有组件,这是前面提到的滚动合并是不一样的。
那么磁盘组件是如何组织并且合并的呢?LSM-Tree 提供了两种合并策略:leveling 和 tiering 。这两种策略都将磁盘组件组织为逻辑级别,级别之间的关系由一个 size ratio 控制,该参数名为 T。
leveling & tiering
leveling 策略中,每一层只有一个磁盘组件 ,每一个 SSTable 的空间容量满足比率 T,且保持不变。当位于级别 L 的组件被填满时,它就会和位于级别 L+1 的组件合并,注意,是覆盖性合并,即直接更改原 L+1 级的组件。用图来表示,如下:

与此相反,tiering 策略中每一层都有 T 个组件,意味着每层的组件数目都相同。同时,一层中的各个组件大小相同。当级别 L 被填满时(该级别出现了 T 个组件),该层的 T 个组件会合并为一个新的组件,进入级别 L+1。这也就解释了为什么每一层都只能有 T 个组件,因为只有这样才能保证层与层之间的空间容量比为 T。该策略用图来表示,如下:

通常,leveling 策略会优化读性能,因为每一层只有一个组件,搜索的组件数就会少。而 tiering 策略的则优化写性能,因为它降低了合并频率。
下面给出两种策略的各种操作复杂度,有些项的具体推导我暂时还没懂,个人觉得综述里写的推导有点泛,某些我还没看明白。都看懂了我再回来更新。

其中,T 如上文所述,L 表示层级的数量,B 表示页面大小(一页中存有多少个条目),P 表示一个磁盘组件中有多少个页面(虽然最后的结论中没有P)。Long/Short Range Query 指范围查询的长短,由范围中的唯一键数目决定。记查询范围中唯一键的数目为 s,如果 S/B > 2L,那么就称为 Long,反之为 short。此外,在单点查询中为什么 Zero-Result 和 Non-Zero-Result 差别会这么大,这是应为运用了布隆过滤器,这是用来快速判断某个 key 是否存在的工具,但是具有假阳性的概率。在另一篇博客中我会介绍它:布隆过滤器。
定性总结一下:
- leveling:读优化、空间优化、写放大;
- tiering:写优化、读放大、空间放大;
但实际上,我们现在用的并不是这两种策略,而是采用了分区(partition)的优化。
partition
在阐述 LSM-Tree 的分区策略之前,现简要提一嘴现在各个组件的常用数据结构,直接以 Rocksdb 为例。LSM-Tree有三个重要组成部分:MemTable、Immutable MemTable、SSTable。
-
MemTable:
MemTable 是在内存中的数据结构,直接服务传入的写操作,并暂存最近更新的数据,即上述提及的组件
C0。它会按照 key 有序地组织这些数据,但具体如何组织,不同的存储引擎用的方式不一样。在 Rocksdb 中,采用跳表(skip-list)来保证内存中的 key 有序。因为数据暂存在内存中,没有持久化,因此通常使用
WAL(Write-ahead logging)的方式来保证数据的可靠性。ps.)跳表,是个超级牛逼的查找数据结构,可以理解为一个能够实现二分查找的链表。我本来打算写一篇博客记录的,但搜到了一篇非常详细的跳表解析博客,增删查都写的很清晰,尤其是增加操作中的随机索引建立过程,写的很明白,所以这里就直接引用了:skip-list 详细分析
-
Immutable MemTable:
当 MemTable 达到一定大小后,会转变成 Immutable MemTable。这个东西是将 MemTable 转变为 SSTable 的一种中间状态。在转存过程中,新来的写操作由新的 MemTable 处理,并不会阻塞数据更新。
-
SSTable:
在 Rocksdb 中,每一个磁盘组件被分为若干个 SSTable。简要说一下,SSTable 包含数据块列表和索引块,数据块存储按 key 排序的键值对,索引块存储所有数据块的 key 范围 。对 SSTable 的学习与分析,我也写在了另一篇博客中:SSTable 数据结构分析。
再来看一下,LSM-Tree 的基本结构如下图所示:

注意到,在红框中,已经不是磁盘组件了,而是被分为了多个 SSTable。分区也分为两种,分别针对 leveling 与 tiering,但是在开始介绍两种分区策略之前,请先记住分区的核心思想:
只合并带有重叠键的 SSTable
partitioned leveling
在 partitioned leveling 策略中,每一层依然只有一个磁盘组件,层与层之间的大小比率依然是 T,但是每个磁盘组件都被分为若干个互不重叠且大小相近的 SSTable,这就意味着每个 key 在一层中只会出现一次,不存在冗余。该策略的合并步骤为:
- L1 的总大小超过自身空间限制。
- 从 L1 中至少选择一个 SSTable,然后把它跟 L2 中有重叠的部分进行合并。
- 合并后生成的新 SSTable 先不着急直接至于 L2 中。因为要保证每一个 SSTable 的大小相近,所以合并后需要先分化成多个小点的 SSTable,然后再置于 L2 中。
- 如果 L2 合并后的大小超过了自身限制,那么重复上述过程,向 L3 合并。
用一张图来表示,如下:
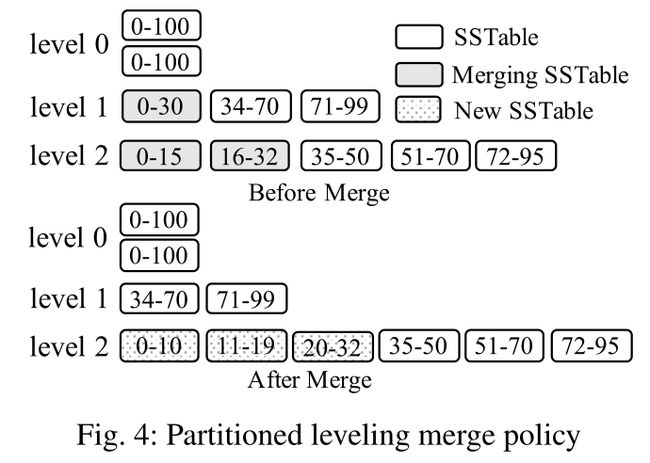
需要注意的是,L0 的磁盘组件没有分区,因为它们是直接从内存中刷新的。这种设计还可以帮助系统吸收写突发,因为它可以容忍 L0 上的多个未分区组件。
partitioned tiering
不同于 p-leveling,p-tiering 策略允许层级中包含多个键范围重叠的 SSTable,但是这些 SSTable 必须要通过一定的方式组织起来。在该策略中,有两种组织方式可供选择,分别为垂直分组(vertical grouping)与水平分组(horizontal grouping)。
vertical grouping
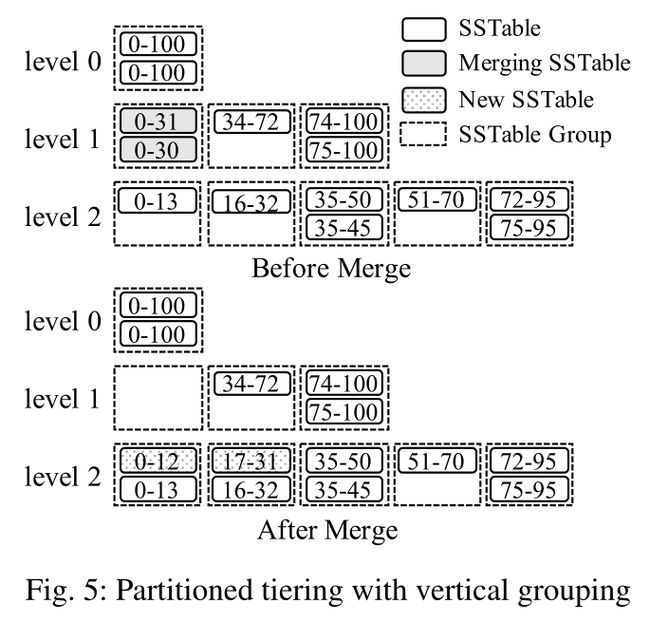
在垂直分组中,每一层级中具有重叠范围的 SSTable 会被分为一组,使得组与组之间不会产生重叠,这样看来,垂直分组像是 p-leveling 的一种变式。其合并流程为:
- L1 的总大小超过自身空间限制。
- 从 L1 中至少选择一组,然后将该组内的所有 SSTable 合并。
- 合并后,根据 L2 的分组情况,将合并后的内容分为了多个不重叠的 SSTable。
- 每一个 SSTable 分别插入 L2 中对应范围的组。
- 如果 L2 合并后的大小超过了自身限制,那么重复上述过程,向 L3 合并。
用一张图来表示,如下:
horizontal grouping
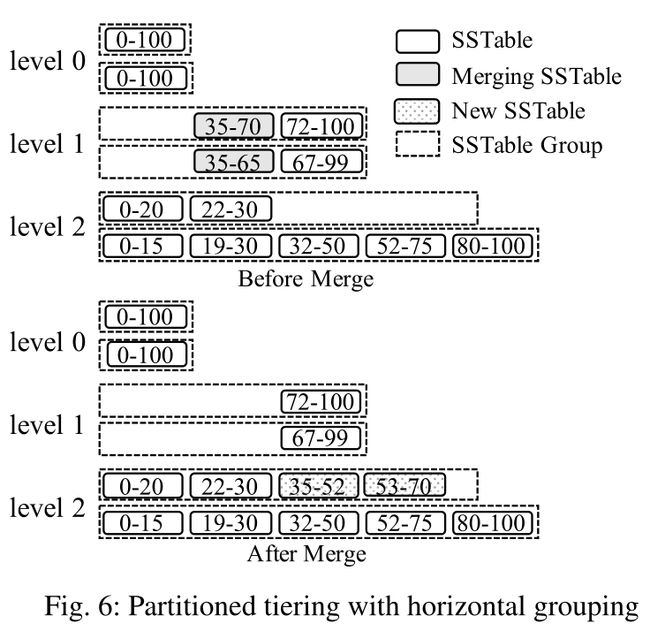
在水平分组中,每一个磁盘组件都自成一组,组与组之间允许有重叠,但是组内的 SSTable 不会有重叠。其合并流程为:
- L1 的总大小超过自身空间限制。
- 在 L1 的所有组中选择具有重叠键的 SSTable,将它们合并。
- 将合并后的内容分为了多个不重叠的 SSTable,然后放入 L2 中的某一个组中。
- 如果 L2 合并后的大小超过了自身限制,那么重复上述过程,向 L3 合并。
用一张图来表示,如下:
为什么要分区
无论是哪种分区策略,都有如下两大优点:
- 分区将一个大型组件拆分成多个较小的 SSTable,就意味着将原来的大型合并操作拆分为多个较小的合并操作,从而限制了每个合并操作的处理时间以及创建新组件所需的临时磁盘空间。
- 分区可以通过只合并具有重叠键的 SSTable 来优化顺序创建 key 的工作负载。对于按顺序创建的 key,基本上不执行合并,因为没有具有重叠键的 SSTable。
优化问题
可以看到,LSM-Tree 是一种可调性比较高的结构,但却没有一种合并策略能够同时满足读优化与写优化。上面提到的 leveling 和 tiering,前者牺牲了写换取了读,后者牺牲了读换取了写。实际上,现在所做的很多优化工作,都是在 leveling 和 tiering 中进行变式与结合,也面临着读/写/空间的权衡问题。
综述里一共提到了 7 种优化思路,分别为:
- 减少写放大
- 优化合并操作
- 更大的内存空间
- 更好的硬件支持
- 针对特殊的工作负载进行优化
- 自调和
- 二级索引
在下一篇博客(学习笔记(二))中,我会按照归类将综述中提到的各种优化办法都整理一遍。