机器人中的数值优化(十五)——PHR增广拉格朗日乘子法
本系列文章主要是我在学习《数值优化》过程中的一些笔记和相关思考,主要的学习资料是深蓝学院的课程《机器人中的数值优化》和高立编著的《数值最优化方法》等,本系列文章篇数较多,不定期更新,上半部分介绍无约束优化,下半部分介绍带约束的优化,中间会穿插一些路径规划方面的应用实例
二十四、PHR增广拉格朗日乘子法
如何对一个更一般化的带约束的问题求解呢?比如f(x)、g(x)、h(x)非凸的时候如何求解?
1、KKT条件
如下式所示的更一般的带约束的优化问题
min x f ( x ) s . t . h i ( x ) ≤ 0 , i = 1 , … , m ℓ j ( x ) = 0 , j = 1 , … , r \begin{array}{rl}\min_x&f(x)\\\mathrm{s.t.}&h_i(x)\leq0,i=1,\ldots,m\\&\ell_j(x)=0,j=1,\ldots,r\end{array} minxs.t.f(x)hi(x)≤0,i=1,…,mℓj(x)=0,j=1,…,r
如果它不是退化的(如它是凸的但没有严格可行点),则它的最优解满足以下表达式
0 ∈ ∂ x [ f ( x ) + ∑ i = 1 m u i h i ( x ) + ∑ j = 1 r v j ℓ j ( x ) ] u i ⋅ h i ( x ) = 0 , i = 1 , … , m h i ( x ) ≤ 0 , ℓ j ( x ) = 0 , i = 1 , … , m , j = 1 , … , r u i ≥ 0 , i = 1 , … , m \begin{aligned} &0\in\partial_x[f(x)+\sum_{i=1}^mu_ih_i(x)+\sum_{j=1}^rv_j\ell_j(x)] \\ &u_i\cdot h_i(x)=0,i=1,\ldots,m \\ &h_i(x)\leq0,~\ell_j(x)=0,~i=1,\ldots,m,~j=1,\ldots,r \\ &u_i\geq0,~i=1,\ldots,m \end{aligned} 0∈∂x[f(x)+i=1∑muihi(x)+j=1∑rvjℓj(x)]ui⋅hi(x)=0,i=1,…,mhi(x)≤0, ℓj(x)=0, i=1,…,m, j=1,…,rui≥0, i=1,…,m
其中,上述第一行是稳定性条件,第二行表达式是互补松弛条件,不等式约束的对偶变量和不等式约束的乘积等于0,第三行表达式表示可行解一定满足等式或不等式约束,第四行表示不等式约束的对偶变量要大于0

对于简单的问题,我们可以直接拿KKT条件把简单的约束优化的问题写出它最优解满足的一些必要条件,不含有不等式约束时,甚至直接把对应的等式方程组直接求解出来。KKT条件用来度量约束算法解的精度
下图中的例子中,仅含有等式约束,最优解一定满足下式所示的线性方程组,Q是严格正定的

2、PHR的含义
Powell-Hestenes-Rockafellar (PHR)是三个关于拉格朗日乘子法最起源的文章的作者的第一个字母,前两个作者在等式约束中提出了对应的方法,第三个作者将其推广到不等式约束上。
3、带等式约束的情况
min x ∈ R n f ( x ) s . t . h ( x ) = 0 \begin{aligned}\min_{x\in\mathbb{R}^n}&f(x)\\\mathrm{s.t.~}&h(x)=0\end{aligned} x∈Rnmins.t. f(x)h(x)=0
前文介绍的Uzawa的方法是对二重函数进行二重的梯度上升,如下所示
d ( λ ) : = min x f ( x ) + λ T h ( x ) d(\lambda):=\min_xf(x)+\lambda^\mathrm{T}h(x) d(λ):=xminf(x)+λTh(x)
如果拉格朗日函数关于x不是严格凸的,则对偶函数是非光滑的。在这种情况下,它的梯度可能不存在,使二重梯度上升成为问题。即使是严格凸的,其效率也可能存在问题。
∇ d ( λ ) does not necessarily exist! \nabla d(\lambda)\text{ does not necessarily exist!} ∇d(λ) does not necessarily exist!
在PHR方法中,基本思想是把不连续的问题变成连续的问题,在右边项中加一个二次项,如下式中的红色部分所示, 我们不知道最优的 λ {\lambda} λ在哪,但我们有一个先验的估值 λ ˉ ( ρ > 0 ) \bar{\lambda} (\rho>0) λˉ(ρ>0),我们利用它来作一个惩罚项 − 1 2 ρ ∥ λ − λ ˉ ∥ 2 -\frac1{2\rho}\|\lambda-\bar{\lambda}\|^2 −2ρ1∥λ−λˉ∥2。内层变成了一个严格凹的函数,对于该严格凹函数,可以求得其唯一的最优解,极大极小值被一个“近端点”项平滑,
min x max λ f ( x ) + λ T h ( x ) − 1 2 ρ ∥ λ − λ ˉ ∥ 2 \min_x\max_\lambda\left.f(x)+\lambda^\mathrm{T}h(x)-\color{red}{\frac1{2\rho}}\|\lambda-\bar{\lambda}\|^2\right. xminλmaxf(x)+λTh(x)−2ρ1∥λ−λˉ∥2
现在我们可以直接优化极大极小问题了,而不需要交换顺序。当 ρ \rho ρ趋于inf时,上式跟原问题越接近,精度越高
那么如何求解以上问题呢?,带上述正则项的子问题如下式所示
max λ f ( x ) + λ T h ( x ) − 1 2 ρ ∥ λ − λ ˉ ∥ 2 \max_{\lambda}\left.f(x)+\lambda^\mathrm{T}h(x)-\color{red}\frac1{2\rho}\|\lambda-\bar{\lambda}\|^2\right. λmaxf(x)+λTh(x)−2ρ1∥λ−λˉ∥2
对于这样一个严格凹的函数求最大值,我们可以对其求导,第一项对 λ \lambda λ求导是0,第二项对 λ \lambda λ求导是h(x),第三项对 λ \lambda λ求导是 − 1 ρ ( λ − λ ˉ ) -\frac{1}{\rho}(\lambda-\bar{\lambda}) −ρ1(λ−λˉ),可得到以下关系式:
0 + h ( x ) − 1 ρ ( λ − λ ˉ ) = 0 0+h(x)-\frac{1}{\rho}(\lambda-\bar{\lambda}) =0 0+h(x)−ρ1(λ−λˉ)=0
可以解得 λ \lambda λ最大值如下所示,其中 λ ˉ \bar{\lambda} λˉ是一个常数,随着 λ ˉ \bar{\lambda} λˉ的值的改变, λ ∗ ( λ ˉ ) \lambda^*(\bar{\lambda}) λ∗(λˉ)也随之改变。
λ ∗ ( λ ˉ ) = λ ˉ + ρ h ( x ) \lambda^*(\bar{\lambda})=\bar{\lambda}+\rho h(x) λ∗(λˉ)=λˉ+ρh(x)
把上述内层问题的最优解代入到,我们要求解的问题中,如下所示:
min x max λ f ( x ) + λ T h ( x ) − 1 2 ρ ∥ λ − λ ˉ ∥ 2 = min x f ( x ) + λ ∗ ( λ ˉ ) T h ( x ) − 1 2 ρ ∥ λ ∗ ( λ ˉ ) − λ ˉ ∥ 2 = min x f ( x ) + ( λ ˉ + ρ h ( x ) T h ( x ) − ρ 2 ∥ h ( x ) ∥ 2 = ⋅ min x f ( x ) + λ ˉ T h ( x ) + ρ 2 ∥ h ( x ) ∥ 2 \begin{aligned} & \min_{x}\max_{\lambda}f(x)+\lambda^{\text{T}}h(x)-\frac1{2\rho}\|\lambda-\bar{\lambda}\|^2\\ & =\min_{x}f(x)+\lambda^{*}(\bar{\lambda})^{\mathrm{T}}h(x)-\frac1{2\rho}\|\lambda^{*}(\bar{\lambda})-\bar{\lambda}\|^2\\ & =\min_{x}f(x)+(\bar{\lambda}+\rho h(x)^{\mathrm{T}}h(x)-\frac\rho2\|h(x)\|^2\\ & \overset{\color{red}{\cdot}}{\operatorname*{=}}\min_{x}\left.f(x)+\bar{\lambda}^{\mathrm{T}}h(x)+\frac\rho2\|h(x)\|^2\right.\end{aligned} xminλmaxf(x)+λTh(x)−2ρ1∥λ−λˉ∥2=xminf(x)+λ∗(λˉ)Th(x)−2ρ1∥λ∗(λˉ)−λˉ∥2=xminf(x)+(λˉ+ρh(x)Th(x)−2ρ∥h(x)∥2=⋅xminf(x)+λˉTh(x)+2ρ∥h(x)∥2
通过上式,我们成功将带等式约束的优化问题转换为无约束的优化问题,由于先验估值 λ ˉ \bar{\lambda} λˉ不一定准确,导致求出的最优解,跟原问题的最优解可能有偏差,但是利用该先验估值求出的 λ ∗ {\lambda}^* λ∗,是向原最优解靠拢的,因此,我们可以把上述利用差的先验估值得出的 λ ∗ {\lambda}^* λ∗,作为新的 λ ˉ \bar{\lambda} λˉ,再求解出一个更高精度的 λ ∗ {\lambda}^* λ∗
1. Reduce the approx. weight 1 / ρ 2. Update the prior value λ ˉ ← λ ∗ ( λ ˉ ) \begin{aligned}1.\quad&\text{Reduce the approx. weight}\quad1/\rho\\2.\quad&\text{Update the prior value}\quad\bar{\lambda}\leftarrow\lambda^*(\bar{\lambda})\end{aligned} 1.2.Reduce the approx. weight1/ρUpdate the prior valueλˉ←λ∗(λˉ)
总的来说,我们可以增大权重 ρ \rho ρ/2,或者通过利用差的先验估值得出的 λ ∗ {\lambda}^* λ∗,作为新的 λ ˉ \bar{\lambda} λˉ,再求解出一个更高精度的 λ ∗ {\lambda}^* λ∗,这两种方法来提高最优解的精度。但 ρ \rho ρ过大可能出现不容易解的问题,所以这两种方法可以配合使用。
求解过程如下所示,首先给一个先验估值 λ ˉ \bar{\lambda} λˉ和一个 ρ \rho ρ,两者都是常量,然后求解这样一个无约束优化问题,比如利用L-BFGS算法、牛顿法等求解,得到最优的x,然后利用这个x去更新先验估值 λ ˉ \bar{\lambda} λˉ,然后再利用新的先验估值,求解这个无约束优化问题。 ρ \rho ρ值可以不用取得很大,比如10、100、1000,循环5~8轮就可以得到精度很高的解
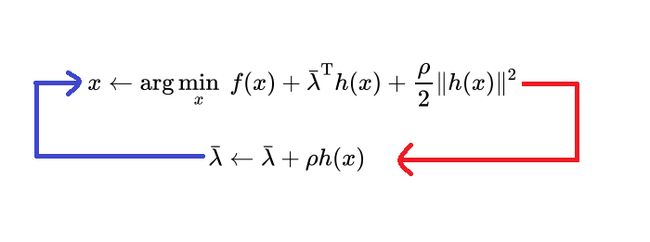
x ← arg min x f ( x ) + λ ˉ T h ( x ) + ρ 2 ∥ h ( x ) ∥ 2 λ ˉ ← λ ˉ + ρ h ( x ) \color{red}\begin{aligned}&x\leftarrow\arg\min_x\left.f(x)+\bar{\lambda}^\mathrm{T}h(x)+\frac\rho2\|h(x)\|^2\right.\\&\bar{\lambda}\leftarrow\bar{\lambda}+\rho h(x)\end{aligned} x←argxminf(x)+λˉTh(x)+2ρ∥h(x)∥2λˉ←λˉ+ρh(x)
与之前介绍的Uzawa’s相比,PHR方法多了一个增广项 ρ 2 ∥ h ( x ) ∥ 2 \frac\rho2\|h(x)\|^2 2ρ∥h(x)∥2,并且 λ ˉ \bar{\lambda} λˉ的更新步长为 ρ \rho ρ ,在Uzawa’s的视角下,上述问题可表示为,即将PHR方法的增广项 ρ 2 ∥ h ( x ) ∥ 2 \frac\rho2\|h(x)\|^2 2ρ∥h(x)∥2视为目标函数的一部分。
min x ∈ R n f ( x ) + ρ 2 ∥ h ( x ) ∥ 2 s . t . h ( x ) = 0 \begin{aligned}\min_{x\in\mathbb{R}^n}f(x)+\frac\rho2\|h(x)\|^2\\\mathrm{s.t.~}h(x)=0\end{aligned} x∈Rnminf(x)+2ρ∥h(x)∥2s.t. h(x)=0
即使优化是非凸的,这个问题也完全等价于原来的问题。它的拉格朗日量,也称为原问题的增广拉格朗日量,如下所示
L ( x , λ ; ρ ) : = f ( x ) + λ T h ( x ) ⏟ L a g r a n g i a n + ρ 2 ∥ h ( x ) ∥ 2 ⏟ A u g m e n t a t i o n \mathcal{L}(x,\lambda;\rho):=\underbrace{f(x)+\lambda^\mathrm{T}h(x)}_{\mathrm{Lagrangian}}+\underbrace{\color{red}{\frac\rho2}\|h(x)\|^2}_{\mathrm{Augmentation}} L(x,λ;ρ):=Lagrangian f(x)+λTh(x)+Augmentation 2ρ∥h(x)∥2
与Uzawa’s方法相比,PHR方法加了一个正则项,使得新的对偶函数是平滑的,且不改变其极值。PHR方法中对偶变量的更新,实际上是一个平滑对偶函数的最大化。

所以,对于如下式所示的一般的非凸等式约束优化问题,
min x ∈ R n f ( x ) s . t . h ( x ) = 0 \begin{aligned}\min_{x\in\mathbb{R}^n}&f(x)\\\mathrm{s.t.~}&h(x)=0\end{aligned} x∈Rnmins.t. f(x)h(x)=0
它的PHR增广拉格朗日函数的一个更常用的等价形式,如下式所示,灰色部分可以省略
L ρ ( x , λ ) : = f ( x ) + ρ 2 ∥ h ( x ) + λ ρ ∥ 2 − 1 2 ρ ∥ λ ∥ 2 \color{red}\mathcal{L}_\rho(x,\lambda):=f(x)+\frac\rho2\begin{Vmatrix}h(x)+\frac\lambda\rho\end{Vmatrix}^2\color{grey}-\frac1{2\rho}\|\lambda\|^2 Lρ(x,λ):=f(x)+2ρ h(x)+ρλ 2−2ρ1∥λ∥2
满足KKT条件的解可通过以下流程获取:
{ x k + 1 = argmin x L ρ k ( x , λ k ) λ k + 1 = λ k + ρ k h ( x k + 1 ) ρ k + 1 = min [ ( 1 + γ ) ρ k , β ] \color{red} \begin{cases}x^{k+1}=\operatorname{argmin}_x\mathcal{L}_{\rho^k}(x,\lambda^k)\\\lambda^{k+1}=\lambda^k+\rho^kh(x^{k+1})\\\rho^{k+1}=\min[(1+\gamma)\rho^k,\beta]&\end{cases} ⎩ ⎨ ⎧xk+1=argminxLρk(x,λk)λk+1=λk+ρkh(xk+1)ρk+1=min[(1+γ)ρk,β]
首先,我们随便给一个 ρ k \rho_k ρk、 λ k \lambda^k λk,然后优化这个增广拉格朗日函数对于x的最优解,得到 x k + 1 x^{k+1} xk+1,然后利用 λ k \lambda^k λk的更新表达式更新得到 λ k + 1 \lambda^{k+1} λk+1,然后利用第三个表达式增大 ρ k \rho_k ρk,得到 ρ k + 1 \rho^{k+1} ρk+1,其中 γ ≥ 0 , β > 0 , ρ 0 > 0 \gamma\geq0,\beta>0,\rho^0>0 γ≥0,β>0,ρ0>0,循环执行以上三个步骤,直至得到所需精度的解。

4、带不等式约束的情况
对于下式所示的非凸的不等式约束问题,
min x ∈ R n f ( x ) s . t . g ( x ) ≤ 0 \begin{aligned}\min_{x\in\mathbb{R}^n}&f(x)\\\mathrm{s.t.~}&g(x)\leq0\end{aligned} x∈Rnmins.t. f(x)g(x)≤0
我们可以采用增加决策变量维度的方法,即增加m个优化变量s,把不等式约束变成等式约束,如下式所示,
min x ∈ R n , s ∈ R m f ( x ) s . t . g ( x ) + [ s ] 2 = 0 \begin{aligned}\min_{x\in\mathbb{R}^n,s\in\mathbb{R}^m}f(x)\\\mathrm{s.t.}\quad g(x)+[s]^2=0\end{aligned} x∈Rn,s∈Rmminf(x)s.t.g(x)+[s]2=0
其中
[ ⋅ ] 2 implies element-wise squaring [\cdot]^2\text{ implies element-wise squaring} [⋅]2 implies element-wise squaring
下面的例子可以帮助理解以上转换,也就是满足 g ( x ) + [ s ] 2 = 0 g(x)+[s]^2=0 g(x)+[s]2=0 的 g ( x ) g(x) g(x)必然满足 g ( x ) ≤ 0 g(x)\leq0 g(x)≤0
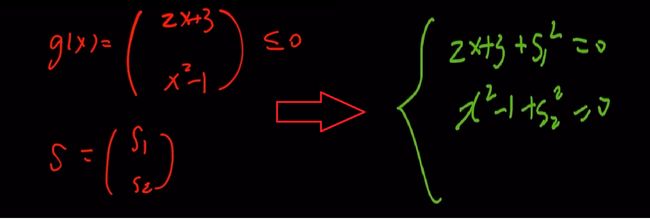
这样我们就把不等式约束问题转换为等式约束问题,然后我们可以直接拿前面的PHR增广拉格朗日乘子法求解,但当m较大时,比如n=100,m=1000,转换后优化变量的维度就变成了1100,此时,有没有更好的处理方法呢?
增广拉格朗日的最初下降意味着:
min x ∈ R n , s ∈ R m f ( x ) + ρ 2 ∥ g ( x ) + [ s ] 2 + λ ρ ∥ 2 = min x ∈ R m min s ∈ R m f ( x ) + ρ 2 ∥ g ( x ) + [ s ] 2 + λ ρ ∥ 2 = min x ∈ R n f ( x ) + ρ 2 ∥ max [ g ( x ) + λ ρ , 0 ] ∥ 2 \min_{x\in\mathbb{R}^n,s\in\mathbb{R}^m}f(x)+\frac\rho2\left\|g(x)+[s]^2+\frac\lambda\rho\right\|^2=\min_{x\in\mathbb{R}^m}\min_{s\in\mathbb{R}^m}f(x)+\frac\rho2\left\|g(x)+[s]^2+\frac\lambda\rho\right\|^2=\color{red}{\min_{x\in\mathbb{R}^n}f(x)+\frac\rho2}\left\|\max\left[g(x)+\frac\lambda\rho,0\right]\right\|^2 x∈Rn,s∈Rmminf(x)+2ρ g(x)+[s]2+ρλ 2=x∈Rmmins∈Rmminf(x)+2ρ g(x)+[s]2+ρλ 2=x∈Rnminf(x)+2ρ max[g(x)+ρλ,0] 2
因此,我们可以直接定义不等式约束问题的增广拉格朗日量为:(下式是更常用的写法),其中灰色部分可以省略,此外,为了与等式约束区分,等式约束中的 λ \lambda λ在这里用 μ \mu μ表示。
L ρ ( x , μ ) : = f ( x ) + ρ 2 ∥ max [ g ( x ) + μ ρ , 0 ] ∥ 2 − 1 2 ρ ∥ μ ∥ 2 \color{red}\mathcal{L}_{\rho}(x,\mu):=f(x)+\frac\rho2\left\|\max\left[g(x)+\frac\mu\rho,0\right]\right\|^2\color{grey}-\frac1{2\rho}\|\mu\|^2 Lρ(x,μ):=f(x)+2ρ max[g(x)+ρμ,0] 2−2ρ1∥μ∥2
对偶变量的更新方式如下式所示:
μ k + 1 = max [ μ k + ρ g ( x k + 1 ) , 0 ] \color{red}\mu^{k+1}=\max\left[\mu^k+\rho g(x^{k+1}),\mathrm{~}0\right] μk+1=max[μk+ρg(xk+1), 0]

5、带等式和不等式约束的情况
对于下式所示的带等式约束和不等式约束的优化问题,
min x ∈ R n f ( x ) s . t . h ( x ) = 0 g ( x ) ≤ 0 \begin{aligned}\min_{x\in\mathbb{R}^n}f(x)\\\begin{array}{rl}\mathrm{s.t.}&h(x)=0\\&g(x)\leq0\end{array}\end{aligned} x∈Rnminf(x)s.t.h(x)=0g(x)≤0
把上面的带等式约束、不等式约束的表达式加在一起,如下式所示:(灰色部分可以省略)
L ρ ( x , λ , μ ) : = f ( x ) + ρ 2 { ∥ h ( x ) + λ ρ ∥ 2 + ∥ max [ g ( x ) + μ ρ , 0 ] ∥ 2 } − 1 2 ρ { ∥ λ ∥ 2 + ∥ μ ∥ 2 } \color{red}\mathcal{L}_\rho(x,\lambda,\mu):=f(x)+\frac\rho2\left\{\left\|h(x)+\frac\lambda\rho\right\|^2+\left\|\max\left[g(x)+\frac\mu\rho,0\right]\right\|^2\right\}\color{grey}-\frac1{2\rho}\left\{\|\lambda\|^2+\|\mu\|^2\right\} Lρ(x,λ,μ):=f(x)+2ρ{ h(x)+ρλ 2+ max[g(x)+ρμ,0] 2}−2ρ1{∥λ∥2+∥μ∥2}
其中
ρ > 0 , μ ⪰ 0 \rho>0,\mu\succeq0 ρ>0,μ⪰0
求解流程如下所示,循环执行以下流程,直至得到符合要求精度的解
{ x ← argmin x L ρ ( x , λ , μ ) λ ← λ + ρ h ( x ) μ ← max [ μ + ρ g ( x ) , 0 ] ρ ← min [ ( 1 + γ ) ρ , β ] \color{red}\begin{cases}x\leftarrow\operatorname{argmin}_x\mathcal{L}_\rho(x,\lambda,\mu)\\\lambda\leftarrow\lambda+\rho h(x)\\\mu\leftarrow\max[\mu+\rho g(x),0]\\\rho\leftarrow\min[(1+\gamma)\rho,\mathrm{~}\beta]&\end{cases} ⎩ ⎨ ⎧x←argminxLρ(x,λ,μ)λ←λ+ρh(x)μ←max[μ+ρg(x),0]ρ←min[(1+γ)ρ, β]
ρ i n i = 1 , λ i n i = μ i n i = 0 , γ = 1 , β = 1 0 3 \rho_{\mathrm{ini}}=1,\lambda_{\mathrm{ini}}=\mu_{\mathrm{ini}}=0,\gamma=1,\beta=10^3 ρini=1,λini=μini=0,γ=1,β=103
首先,我们随便给一个 ρ \rho ρ、 λ \lambda λ, μ \mu μ、比如 ρ = 1 \rho=1 ρ=1, λ = 0 \lambda=0 λ=0, μ = 0 \mu=0 μ=0,然后优化这个增广拉格朗日函数对于x的最优解,得到 x x x,然后分别利用 λ \lambda λ和 μ \mu μ的更新表达式更新 λ \lambda λ和 μ \mu μ,然后利用最后一个表达式增大 ρ \rho ρ,根据实际需求,也可不增大,循环执行以上四个步骤,当kkT的残差小于设定的值,增广拉格朗日对x的梯度尽可能的小时,如下所示,外层循环停止循环迭代。
max [ ∥ h ( x ) ∥ ∞ , ∥ max [ g ( x ) , − μ ρ ] ∥ ∞ ] < ϵ c o n s , ∥ ∇ x L ρ ( x , λ , μ ) ∥ ∞ < ϵ p r e c \max\left[\|h(x)\|_\infty,\left\|\max\left[g(x),-\frac{\mu}{\rho}\right]\right\|_\infty\right]<\epsilon_{\mathrm{cons}},\left.\left\|\nabla_x\mathcal{L}_\rho(x,\lambda,\mu)\right\|_\infty<\epsilon_{\mathrm{prec}}\right. max[∥h(x)∥∞, max[g(x),−ρμ] ∞]<ϵcons,∥∇xLρ(x,λ,μ)∥∞<ϵprec
同样,当满足下式时,即增广拉格朗日关于x的梯度小于迭代的KKT残差的常数倍的衰减时,内层循环停止
∥ ∇ x L ρ ( x , λ , μ ) ∥ ∞ < ξ k min [ 1 , max [ ∥ h ( x ) ∥ ∞ , ∥ max [ g ( x ) , − μ ρ ] ∥ ∞ ] ] with positive ξ k converging to 0 \left.\|\nabla_x\mathcal{L}_\rho(x,\lambda,\mu)\|_\infty<\xi^k\min\left[1,\max\left[\|h(x)\|_\infty,\right\|\max\left[g(x),-\frac\mu\rho\right]\|_\infty\right]\right]\text{ with positive }\xi^k\text{ converging to }0 ∥∇xLρ(x,λ,μ)∥∞<ξkmin[1,max[∥h(x)∥∞,∥max[g(x),−ρμ]∥∞]] with positive ξk converging to 0

参考资料:
1、数值最优化方法(高立 编著)
2、机器人中的数值优化