机器人中的数值优化(十三)——QP二次规划
本系列文章主要是我在学习《数值优化》过程中的一些笔记和相关思考,主要的学习资料是深蓝学院的课程《机器人中的数值优化》和高立编著的《数值最优化方法》等,本系列文章篇数较多,不定期更新,上半部分介绍无约束优化,下半部分介绍带约束的优化,中间会穿插一些路径规划方面的应用实例
二十、低维度严格凸的QP二次规划
1、低维度严格凸的QP二次规划数学描述
低维度严格凸二次规划,其数学描述如下式所示,其中 M Q M_Q MQ是严格正定的对称矩阵,目标函数是严格凸函数,维度n是低维的
min x ∈ R n 1 2 x T M Q x + c Q T x , s.t. A Q x ≤ b Q \operatorname*{min}_{x\in\mathbb{R}^{n}}\frac{1}{2}x^{\mathrm{T}}M_{\mathcal{Q}}x+c_{\mathcal{Q}}^{\mathrm{T}}x\text{, s.t. }A_{\mathcal{Q}}x\leq b_{\mathcal{Q}} x∈Rnmin21xTMQx+cQTx, s.t. AQx≤bQ
M Q M_Q MQ是严格正定的,因此可以对其进行Cholesky分解,Cholesky 分解是把一个对称正定的矩阵表示成一个下三角矩阵L和其转置的乘积的分解。它要求矩阵的所有特征值必须大于零,故分解的下三角的对角元也是大于零的。
M Q = L Q L Q T M_{\cal Q}=L_{\cal Q}L_{\cal Q}^{\mathrm{T}} MQ=LQLQT
这个QP问题等价于关于y的最小二范数问题:
y = L Q T x + L Q − 1 c Q o r x = L Q − T y − ( L Q L Q T ) − 1 c Q y=L_{\cal Q}^{\mathrm T}x+L_{\cal Q}^{-1}c_{\cal Q}\quad\mathrm{or}\quad x=L_{\cal Q}^{-\mathrm T}y-\left(L_{\cal Q}L_{\cal Q}^{\mathrm T}\right)^{-1}c_{\cal Q} y=LQTx+LQ−1cQorx=LQ−Ty−(LQLQT)−1cQ
我们可以把上面x关于y的表达式代入到目标函数中,整理后得到等价的表达式如下所示:
min y ∈ R n 1 2 y T y , s . t . E y ≤ f \min_{y\in\mathbb{R}^n}\frac12y^\mathrm{T}y,\mathrm{~s.t.~}Ey\leq f y∈Rnmin21yTy, s.t. Ey≤f
其中 E = A Q L Q − T , f = A Q ( L Q L Q T ) − 1 c Q + b Q E=A_{\mathcal{Q}}L_{\mathcal{Q}}^{-\mathrm{T}},f=A_{\mathcal{Q}}\big(L_{\mathcal{Q}}L_{\mathcal{Q}}^{\mathrm{T}}\big)^{-1}c_{\mathcal{Q}}+b_{\mathcal{Q}} E=AQLQ−T,f=AQ(LQLQT)−1cQ+bQ
对上述表达式求解得到最优的y后(在多面体中找一个范数最小的点,也即离原点最近的点),再将得到的y代入到上面x关于y的表达式,即可得到最优的x。
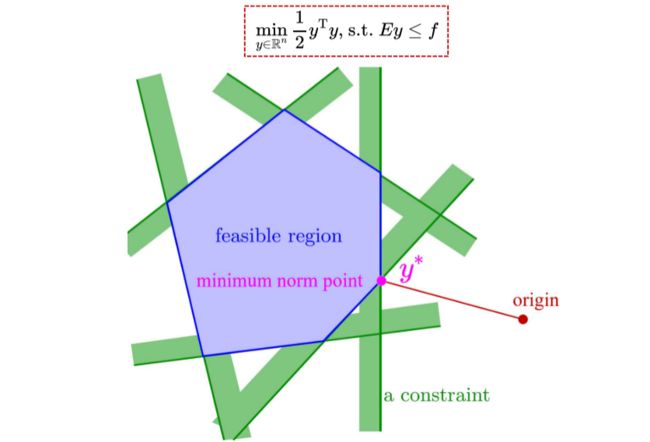
线性不等式约束 E y ≤ f Ey\leq f Ey≤f构成了如下图所示的可行域,在该可行域内找一个使得下式最小的解,即y的二范数的平方的最小的解,也就是可行域中离原点最近的点。
min y ∈ R n 1 2 y T y = 1 2 ∣ ∣ y ∣ ∣ 2 2 \min_{y\in\mathbb{R}^n}\frac12y^\mathrm{T}y=\frac12{||y||_2}^2 y∈Rnmin21yTy=21∣∣y∣∣22
2、一维的QP二次规划
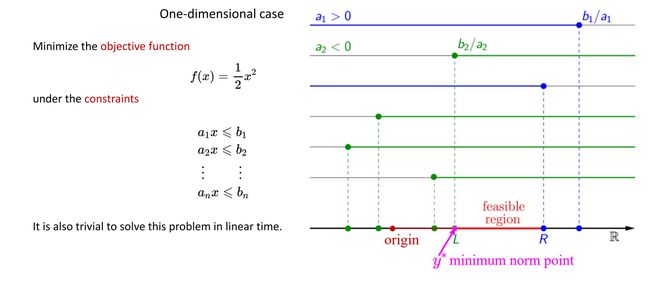
与之前介绍的LP线性规划类似,一维情况下的数学描述及可行域的计算如下图所示,所不同的是,确定了可行域后,QP更容易得到最优解,只需要找到可行域中距离原点最近的点即可,若原点位于可行域左侧,则可行域左端点即为最优解,同理,若原点位于可行域右侧,则可行域右端点即为最优解,若原点位于可行域内部,则原点即为最优解。
3、二维的QP二次规划
与之前介绍的LP线性规划类似,二维情况下的解决思路依然是,在加入新的约束后,若之前的最优解依然在可行域中,则最优解不变,若之前的最优解已经不在可行域中了,则需要将之前的约束边界投影到当前新加入的约束边界上,转化得到一维的可行域,再在这个一维的可行域上寻找新的最优解,与LP不同的是,得到一维的可行域后,只需要将原点也投影到新加入的约束边界上,然后找到一维可行域中与原点的投影点距离最近的点即可
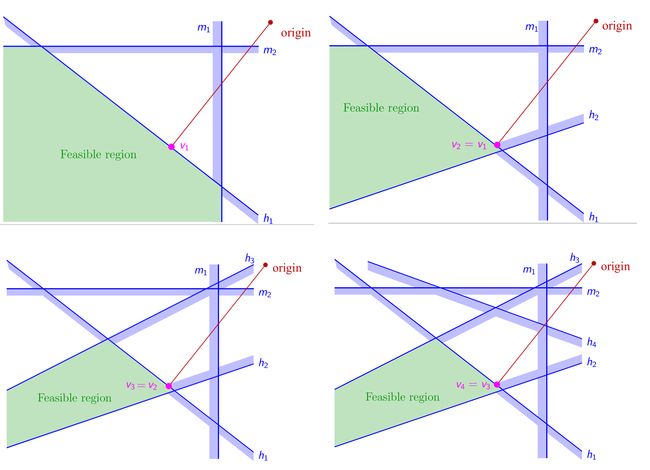
4、更一般的d维QP二次规划
与前文介绍的d维的LP线性规划的主要思想类似,d维的二次规划在当前最优解不满足新加入的约束时,也将其转换成d-1维的二次规划,这跟上面2维二次规划时转换成1维二次规划的思想是相同的,这种思想有点像递归的思想。

上图中给出的伪代码中,输入参数H即不等式约束 a T y < = b a^\mathrm{T}y<=b aTy<=b,也即一系列半空间,如果此时H的维度是一维的,则直接采用上文中介绍的一维情况的解决方法求解,若此时c不是一维的,则初始化一个空集 I I I,可以提前用Fisher-Yates算法对H的序列进行打乱,打乱后进行for循环时,每次依次从H中取一个h,然后判断:
情况1:若当前最优解属于h,则当前最优解满足约束h,不需要计算新的最优解,直接将h添加到集合 I I I中,继续进行下一轮for循环,处理下一个约束h
情况2:若当前的最优解不属于h,则需要计算一个新的最优解x,将已经加入到集合 I I I中的约束投影到约束h的边界上,得到低一个维度的H’,将原点也投影到h上,得到低一个维度的原点v,M是h的一个正交基,然后将低一个维度的H’作为参数递归调用LowDimMinNorm()函数本身进行降维处理,直至降为1维情况。然后就可以得到新的y’,运用关系式 y ← M y ′ + v y\leftarrow My^{\prime}+v y←My′+v得到新的最优解y,此时约束h已经满足,将其添加到集合 I I I中,本轮循环结束,继续进行下一轮for循环,处理下一个约束h。
for循环结束后,即可得到满足所有约束hi的最优解y,然后再带入到x关于y的表达式,得到满足所有约束的最优解x。
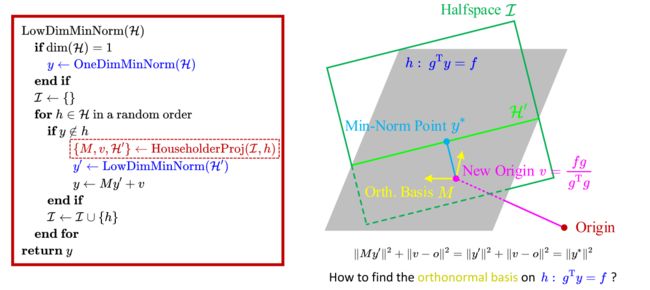
在前文介绍的LP线性规划中,把d维的问题转换成d-1维的问题,并逐步转换为1维问题是通过高斯消元法完成的,接下来介绍在QP二次规划中,如何把高维问题转换成低维问题。
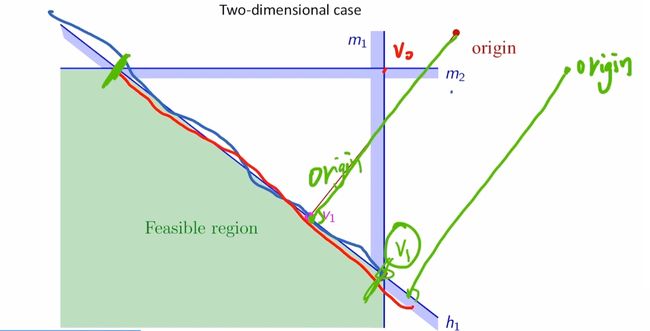
在上图中的例子中,之前的约束构成的空间如绿色区域所示,新加入的约束h如图中灰色区域所示,新的最优解 y ∗ y^* y∗必然位于约束h所确定的平面上且位于之前的约束构成的区域的内部,原点o在约束h所确定的平面上的投影点为v,由勾股定理可得他们满足以下表达式
∥ y ∗ − o ∥ 2 = ∥ y ∗ − v ∥ 2 + ∥ v − o ∥ 2 \|y^*-o\|^2= \|y^*-v\|^2+\|v-o\|^2 ∥y∗−o∥2=∥y∗−v∥2+∥v−o∥2
假设,我们已知约束h所确定的平面中以v为原点的一组标准正交基M,然后,约束h所确定的灰色平面中所有点均可表示为该组标准正交基的坐标,因此 y ∗ y^* y∗满足如下表达式,其中 y 1 ′ y_1^{\prime} y1′和 y 2 ′ y_2^{\prime} y2′是 y ∗ − v y^*-v y∗−v在标准正交基下的坐标:
y ∗ − v = y 1 ′ M 1 + y 2 ′ M 2 = M y ′ y^*-v=y_1^{\prime}M_1+y_2^{\prime}M_2=My^{\prime} y∗−v=y1′M1+y2′M2=My′
将上式代入到 ∥ y ∗ − o ∥ 2 = ∥ y ∗ − v ∥ 2 + ∥ v − o ∥ 2 \|y^*-o\|^2= \|y^*-v\|^2+\|v-o\|^2 ∥y∗−o∥2=∥y∗−v∥2+∥v−o∥2中可得以下表达式(因为M是标准正交基,所以 M T M = I M^TM=I MTM=I所以求范数后可以约去 )
∥ M y ′ ∥ 2 + ∥ v − o ∥ 2 = ∥ y ′ ∥ 2 + ∥ v − o ∥ 2 = ∥ y ∗ ∥ 2 \|My'\|^2+\|v-o\|^2=\|y'\|^2+\|v-o\|^2=\|y^*\|^2 ∥My′∥2+∥v−o∥2=∥y′∥2+∥v−o∥2=∥y∗∥2
因为,v-o是常量,所以求最小的y*可以转换为求最小的y’,把一个线性等式约束上的最小范数问题转化为一个无约束的最小范数问题。
接下来看一下,上面提到的点v和标准正交基M如何求,约束h= g T y = f g^Ty=f gTy=f,可知当 y = f g g T g y=\frac{\color{red}{fg}}{\color{red}{g^Tg}} y=gTgfg必然满足该约束,所以v可取为: v = f g g T g v=\frac{\color{red}{fg}}{\color{red}{g^Tg}} v=gTgfg
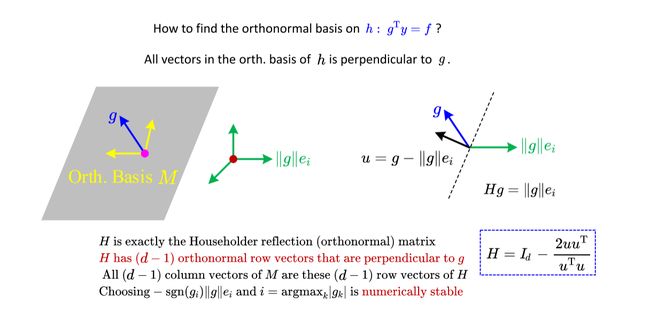
g是h约束所确定平面的法向量,那么平面的标准正交基均垂直于g,我们可以先构造下图中绿色的这样一组正交基,其某一个维度的模长为||g||,然后再通过旋转把模长为||g||的那个基变得跟g同方向,其他的绿色基,自然也就变成了我们想要的图中黄色的基M。其相关数学表达式如下所示:
u = g − ∥ g ∥ e i u=g-\|g\|e_i u=g−∥g∥ei
H = I d − 2 u u T u T u H=I_d-\frac{2uu^\mathrm{T}}{u^\mathrm{T}u} H=Id−uTu2uuT
先根据g和ei计算出u,再代入上式计算出H(注意这里的H不是约束的意思),然后把H转置一下,得到 H T H^T HT后去掉第i列,就得到我们想要的M了,M中的d-1个列向量是由H中的d-1个行向量构成的

参考资料:
1、数值最优化方法(高立 编著)
2、机器人中的数值优化