BEVFusion:Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation 论文笔记
原文链接:https://arxiv.org/abs/2205.13542
1.引言
为找到多传感器数据的统一表达,最直接的方法是将激光雷达点云投影到图像上,但这样做会带来严重的几何扭曲(如下图(a)所示),对于3D物体识别等几何导向任务而言不那么有效。
最近的融合方法将图像语义信息、CNN特征或是来自图像的虚拟点附加到激光雷达点云,然后使用现有的激光雷达方法进行3D检测。这些方法对BEV分割等语义导向的任务而言不那么有效,因为相机到激光雷达的投影会损失语义信息(如下图(b)所示),且点云越稀疏,损失越多。

本文使用统一的多模态BEV表达,同时保留几何结构和语义密度(如上图(c)所示),实现任务无关的学习。为解决视图转换的低效问题,提出了预先计算和区间规约方法。最后使用全卷积BEV编码器融合统一的BEV特征,并添加不同的任务头。
BEVFusion在3D检测和BEV分割任务下能达到目前最好的性能,且相比于单一模态方法有着极大的性能提升。此外,BEVFusion比现有方法计算复杂度更低。
3.方法
BEVFusion主要关注多传感器融合的多任务学习。如下图所示,首先使用各自的编码器提取各模态特征,然后将多模态特征转换到统一的BEV表达,以保留几何和语义信息。对于视图变换这一效率瓶颈,本文使用预先计算和区间规约来加速BEV池化操作。使用基于卷积的BEV编码器处理统一BEV特征,以减轻特征的局部失调。最后使用多个任务头以解决3D任务。
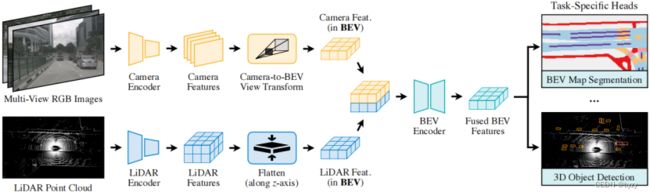
3.1 统一表达
统一表达的两个要求:所有传感器的特征容易转换且不丢失信息;适合不同类型的任务。
相机:激光雷达到图像的投影是有几何损失的,例如3D空间中间隔较远的点在图像平面可能相邻,这对关注物体/场景几何的任务如3D检测不太有效。
激光雷达:图像到激光雷达的投影是有语义损失的,因为数据密度不同,只有很少的像素能与激光雷达点匹配。对于关注语义的任务如BEV分割来说,丢失大量图像语义特征是不利的。
鸟瞰图:该视图适合多数感知任务,且能同时保留激光雷达的几何信息(压缩高度维不会产生几何扭曲)和图像的密集语义特征(像素以射线的方式投影回BEV)。
3.2 高效的相机到BEV转换
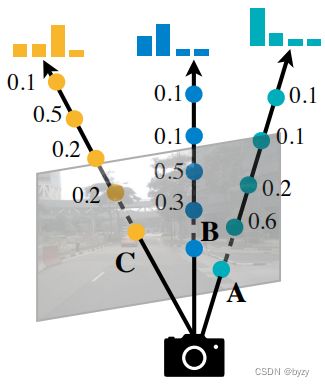
与LSS类似,本文显式地预测离散深度分布,然后将每个像素沿相机射线分散出 个离散点,离散点特征根据相应的深度概率缩放(见下左图)。这样
个离散点,离散点特征根据相应的深度概率缩放(见下左图)。这样 视图图像得到含有
视图图像得到含有![]() 个点的点云。最后离散化点云并进行BEV池化聚合每个BEV网格中的特征。
个点的点云。最后离散化点云并进行BEV池化聚合每个BEV网格中的特征。

但由于点数很多,BEV池化操作非常低效,网络的大多数时间都在进行BEV池化。本文通过使用预先计算和区间规约来优化BEV池化操作。
预先计算:因为在相机内外参不变的情况下,图像特征点云的各点位置是固定的,可预先为每个相机特征点云关联一个BEV网格,并预先排好序,推断时仅需根据序号重排各点。
区间规约:上一步完成后,同一网格中的所有点在张量中是连续的。接下来仅需使用对称函数聚合这些点的特征。LSS中使用的方法需要计算前序累加和,该方法要求在GPU上进行树规约,并产生许多未用到的部分和(见上右图)。本文使用专门的GPU核,直接在BEV网格上并行处理:为每个网格分配一个GPU线程,计算区间和。核移除了输出之间的依赖性(无需多尺度树规约),并避免在DRAM上写入部分和,使特征聚合效率大大提升。
3.3 全卷积融合
将激光雷达BEV和图像BEV拼接后,由于视图转换器不精确的深度估计,可能存在空间失调,因此使用基于卷积的BEV编码器(带若干残差块)进行补偿。
3.4 多任务头
本文使用3D检测头(类似CenterPoint方法)和BEV分割头(由于类别之间可能有交叉,视为多个二值分割任务;使用focal损失),分别代表几何导向的任务和语义导向的任务。
4.实验
模型:图像主干是Swin-T,并使用FPN融合多尺度特征;激光雷达主干是VoxelNet。由于3D检测和BEV分割任务需要的BEV分辨率不同,在任务头前使用双线性插值进行网格采样以得到不同分辨率的BEV特征图。
训练:本文没有对图像主干进行预训练,而是端到端地进行训练。图像和激光雷达均使用了数据增广以避免过拟合。
4.1 3D目标检测
相比TransFusion以及逐点融合方法PointPainting/MVP,BEVFusion能以更快的速度(接近实时)达到更好的性能。
4.2 BEV地图分割
与3D检测不同的是,仅使用图像的BEVFusion性能能大幅超过基于激光雷达的方法;使用多模态融合能够进一步提高性能。这说明在语义导向任务中,图像是特征融合中更有效的模态。
5.分析
天气和光照:由于激光雷达点云在雨天会有显著噪声,而相机在不同天气下的鲁棒性较好,BEVFusion的性能要高于CenterPoint。基于图像的方法在黑暗或过曝的情况下会有显著的性能下降;对于分割任务,此时通过BEVFusion融合激光雷达带来的性能提升甚至会大于正常光照条件下的性能提升。这说明在相机失效时,激光雷达的几何信息也很重要。
尺寸和距离:相比激光雷达方法,BEVFusion对不同大小的物体带来一致的性能提升;对于小物体或远距离物体的性能提升稍大,因为这些物体通常有更少的激光雷达点,密集图像信息的作用更大。
更稀疏的激光雷达:在1线激光雷达下,BEVFusion的性能大幅超过MVP,因为本文的BEV融合不像逐点融合方法,不是强依赖激光雷达的。
多任务学习:联合学习比独立学习的性能低,这就是众所周知的“负迁移”;使用不同的BEV编码器能带来更好的结果,但仍低于独立学习的性能。
消融研究:BEVFusion相比激光雷达方法和图像方法均有较大性能提升,说明BEV特征融合对几何导向和目标导向任务均有利;BEVFusion对不同体素/图像分辨率的可放缩性较强,且FPN特征分辨率为输入的1/8时性能达到峰值;BEVFusion适合不同的主干,且联合训练图像主干的模型在分割性能上会比预训练固定参数的模型好很多,而在3D检测性能上仅略有提升。