Linux环境编程
1.__sync_fetch_and_add和__sync_bool_compare_and_swap
gcc从4.1.2提供了__sync_*系列的built-in函数,用于提供加减和逻辑运算的原子操作。
其声明如下:
type __sync_fetch_and_add (type *ptr, type value, ...)
type __sync_fetch_and_sub (type *ptr, type value, ...)
type __sync_fetch_and_or (type *ptr, type value, ...)
type __sync_fetch_and_and (type *ptr, type value, ...)
type __sync_fetch_and_xor (type *ptr, type value, ...)
type __sync_fetch_and_nand (type *ptr, type value, ...)
type __sync_add_and_fetch (type *ptr, type value, ...)
type __sync_sub_and_fetch (type *ptr, type value, ...)
type __sync_or_and_fetch (type *ptr, type value, ...)
type __sync_and_and_fetch (type *ptr, type value, ...)
type __sync_xor_and_fetch (type *ptr, type value, ...)
type __sync_nand_and_fetch (type *ptr, type value, ...)
这两组函数的区别在于第一组返回更新前的值,第二组返回更新后的值。
type可以是1,2,4或8字节长度的int类型,即:
int8_t / uint8_t
int16_t / uint16_t
int32_t / uint32_t
int64_t / uint64_t
后面的可扩展参数(...)用来指出哪些变量需要memory barrier,因为目前gcc实现的是full barrier(类似于linux kernel 中的mb(),表示这个操作之前的所有内存操作不会被重排序到这个操作之后),所以可以略掉这个参数。
bool __sync_bool_compare_and_swap (type *ptr, type oldval type newval, ...)
type __sync_val_compare_and_swap (type *ptr, type oldval type newval, ...)
这两个函数提供原子的比较和交换,如果*ptr == oldval,就将newval写入*ptr,
第一个函数在相等并写入的情况下返回true.
第二个函数在返回操作之前的值。
__sync_synchronize (...)发出一个full barrier.
关于memory barrier,cpu会对我们的指令进行排序,一般说来会提高程序的效率,但有时候可能造成我们不希望得到的结果,举一个例子,比如我们有一个硬件设备,它有4个寄存器,当你发出一个操作指令的时候,一个寄存器存的是你的操作指令(比如READ),两个寄存器存的是参数(比如是地址和size),最后一个寄存器是控制寄存器,在所有的参数都设置好之后向其发出指令,设备开始读取参数,执行命令,程序可能如下:
write1(dev.register_size,size);
write1(dev.register_addr,addr);
write1(dev.register_cmd,READ);
write1(dev.register_control,GO);
如果最后一条write1被换到了前几条语句之前,那么肯定不是我们所期望的,这时候我们可以在最后一条语句之前加入一个memory barrier,强制cpu执行完前面的写入以后再执行最后一条:
write1(dev.register_size,size);
write1(dev.register_addr,addr);
write1(dev.register_cmd,READ);
__sync_synchronize();
write1(dev.register_control,GO);
memory barrier有几种类型:
acquire barrier : 不允许将barrier之后的内存读取指令移到barrier之前(linux kernel中的wmb())。
release barrier : 不允许将barrier之前的内存读取指令移到barrier之后 (linux kernel中的rmb())。
full barrier : 以上两种barrier的合集(linux kernel中的mb())。
还有两个函数:
type __sync_lock_test_and_set (type *ptr, type value, ...)
将*ptr设为value并返回*ptr操作之前的值。
void __sync_lock_release (type *ptr, ...)
将*ptr置0
#include <stdio.h>
#include <pthread.h>
#include <stdlib.h>
static int count = 0;
void *test_func(void *arg)
{
int i=0;
for(i=0;i<20000;++i){
__sync_fetch_and_add(&count,1);
}
return NULL;
}
int main(int argc, const char *argv[])
{
pthread_t id[20];
int i = 0;
for(i=0;i<20;++i){
pthread_create(&id[i],NULL,test_func,NULL);
}
for(i=0;i<20;++i){
pthread_join(id[i],NULL);
}
printf("%d\n",count);
return 0;
}
编译# cc __sync_fetch_and_add.c
/tmp/ccse5ep7.o: In function `main':
__sync_fetch_and_add.c:(.text+0x86): undefined reference to `pthread_create'
__sync_fetch_and_add.c:(.text+0xb3): undefined reference to `pthread_join'
参考:http://www.linuxidc.com/Linux/2011-06/37403.htm
2.undefined reference to 'pthread_create'问题解决
pthread 库不是 Linux 系统默认的库,连接时需要使用静态库 libpthread.a,所以在使用pthread_create()创建线程,以及调用 pthread_atfork()函数建立fork处理程序时,需要链接该库。
问题解决:在编译中要加 -lpthread参数
重新编译上述代码#cc __sync_fetch_and_add.c -o add -lpthread
3.汇编中为什么会有NOP指令
1).”NOP"指令即空指令,nop并不是汇编指令,只是一条汇编伪指令,编译器会将这条指令替换成像mov r7,r7之类的没什么用处的操作,通常用于延时或等待。
2). 运行该指令时单片机什么都不做,但是会占用一个指令的时间。也就是做精确延时,这和for的延时程序比时间短,易控制。
3). 当指令间需要有延时(给外部设备足够的响应时间;或是软件的延时等),可以插入“NOP”指令。
4)就是通过nop指令的填充(nop指令一个字节),使指令按字对齐,从而减少取指令时的内存访问次数。(一般用来内存地址偶数对齐,比如有一条指令,占3字节,这时候使用nop指令,cpu 就可以从第四个字节处读取指令了。)
5)通过nop指令产生一定的延迟,但是对于快速的CPU来说效果不明显,可以使用rep前缀,多延迟几个时钟;-->具体应该说是占用了3个时钟脉冲!
6)i/o传输时,也会用一下 nop,等待缓冲区清空,总线恢复;
7)清除由上一个算术逻辑指令设置的flag位;
8).NOP通常在破解软件时有特殊用途,例如检查序列号,特定硬件或软件需求,加密狗等的软件。这是通过更改函数和/或子程序以跳过安全检查,直接返回期望的检测值实现的。由于大多数安全检查子程序中的指令会被废弃,它们会被NOP所代替。
更多参考:http://blog.csdn.net/erazy0/article/details/6071281 http://zh.wikipedia.org/wiki/NOP
4.__asm__ ("pause" )和__asm__ ("nop" )
_asm pause 的反汇编代码如下
00401480 . F2: prefix repne:
00401481 . 90 nop
00401482 . C3 retn
__asm nop 的反汇编代码也如下
00401481 . 90 nop
00401482 . C3 retn
1).pause的编码如上,是NOP加F3前缀,这条指令是为支持超线程的CPU做优化用的,不支持超线程的CPU也能用,具体看INTEL手册。
2).asm("NOP");是汇编语言,执行空操作。通过一定次数的空操作达到延时的目的。具体次数通常经过测试获得。
参考:http://bbs.pediy.com/archive/index.php?t-88477.html
1.pause指令提升了自旋等待循环(spin-wait loop)的性能。当执行一个循环等待时,Intel P4或Intel Xeon处理器会因为检测到一个可能的内存顺序违规(memory order violation)而在退出循环时使性能大幅下降。PAUSE指令给处理器提了个醒:这段代码序列是个循环等待。处理器利用这个提示可以避免在大多数情况下的内存顺序违规,这将大幅提升性能。因为这个原因,所以推荐在循环等待中使用PAUSE指令。
2.pause的另一个功能就是降低Intel P4在执行循环等待时的耗电量。Intel P4处理器在循环等待时会执行得非常快,这将导致处理器消耗大量的电力,而在循环中插入一个pause指令会大幅降低处理器的电力消耗。
3.pause指令虽然是在Intel P4处理器开始出现的,但是它可以向后与所有的IA32处理器兼容。在早期的IA32 CPU中,pause就像NOP指令。Intel P4和Intel Xeon处理器将pause实现成一个预定义的延迟(pre-defined delay)。这种延迟是有限的,而且一些处理器可以为0。pause指令不改变处理器的架构状态(也就是说,它实际上只是执行了一个延迟——并不做任何其他事情——的操作)。
参考:http://blog.csdn.net/kofshower/article/details/7432612
5.按8字节对齐
希望malloc分配的数据区是按8字节对齐,所以在size不为8的倍数时,我们需要将size调整为大于size的最小的8的倍数
size_t align8(size_t s) {
if(s & 0x7 == 0)
return s;
return ((s >> 3) + 1) << 3;
}
参考:http://blog.codinglabs.org/articles/a-malloc-tutorial.html
6.大小写字符转换
#define ngx_tolower(c) (u_char) ((c >= 'A' && c <= 'Z') ? (c | 0x20) : c)
#define ngx_toupper(c) (u_char) ((c >= 'a' && c <= 'z') ? (c & ~0x20) : c)
参考:http://blog.csdn.net/21aspnet/article/details/41251915
7.多线程和原子操作
原子操作就是执行时不会被中断的指令。
两个原子操作不可能同时作用于同一个变量,这个是原子操作的一个保证,至于处理器或者操作系统如何实现那是另外一回事。
原子操作是指某些操作的不可中断。分为bitops和atomic_t两类,bitops用于标志的设置;而atomic_t用于原子性的加减之类的运算。
在原子操作中运用了很多的volatile声明。这样系统会阻止编译器对volatile声明的变量进行优化,确保变量使用用户定义的精确地址,而不是使用有着同一信息的别名。
参考:
http://blog.sina.com.cn/s/blog_6237dcca0100fjgl.html
http://www.cppblog.com/woaidongmao/archive/2009/10/19/98965.html
http://preshing.com/20130618/atomic-vs-non-atomic-operations/
http://hedengcheng.com/?p=803#more-803
8.负数变正数
负数&0x7fffffff -1&0x7fffffff=2147483647 -2&0x7fffffff=2147483646
-1的二进制是1111 1111 1111 1111 1111 1111 1111 1111
2147483647是0111 1111 1111 1111 1111 1111 1111 1111 用+N标记
-2147483648是1000 0000 0000 0000 0000 0000 0000 0000 用 -N标记
+N +1溢出=-N
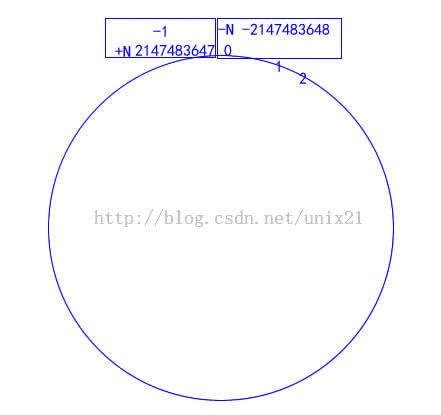
最大正数溢出就是-1,0对应最小负数 ,见上图。