十一、分词器的核心类
Analyzer :
SimpleAnalyzer、StopAnalyzer、WhitespaceAnalyzer、StandardAnalyzer
public static void displayToken(String str,Analyzer a) {
try {
TokenStream stream = a.tokenStream ("content",new StringReader (str));
//创建一个属性,这个属性会添加流中,随着这个TokenStream增加
CharTermAttribute cta = stream.addAttribute(CharTermAttribute.class);
while(stream.incrementToken()) {
System.out.print("["+cta+"]");
}
System.out.println();
} catch (IOException e) {
e.printStackTrace();
}
}
@Test
public void test01() {
Analyzer a1 = new StandardAnalyzer(Version.LUCENE_35);
Analyzer a2 = new StopAnalyzer(Version.LUCENE_35);
Analyzer a3 = new SimpleAnalyzer(Version.LUCENE_35);
Analyzer a4 = new WhitespaceAnalyzer(Version.LUCENE_35);
String txt = "this is my house,I am come from yunnang zhaotong,"
+ "My email is [email protected],My QQ is 64831031";
AnalyzerUtils.displayToken(txt, a1);
AnalyzerUtils.displayToken(txt, a2);
AnalyzerUtils.displayToken(txt, a3);
AnalyzerUtils.displayToken(txt, a4);
}
输出结果如下:
[my][house][i][am][come][from][yunnang][zhaotong][my][email][ynkonghao][gmail.com][my][qq][64831031]
[my][house][i][am][come][from][yunnang][zhaotong][my][email][ynkonghao][gmail][com][my][qq]
[this][is][my][house][i][am][come][from][yunnang][zhaotong][my][email][is][ynkonghao][gmail][com][my][qq][is]
[this][is][my][house,I][am][come][from][yunnang][zhaotong,My][email][is][[email protected],My][QQ][is][64831031]
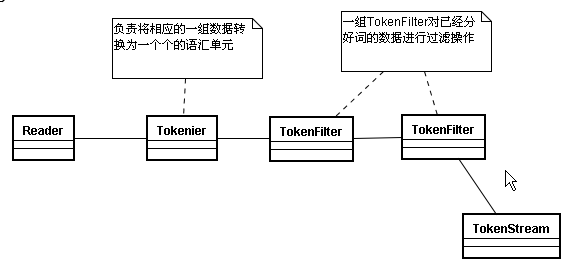
TokenStream :
分词器做好处理之后得到的一个流,这个流中存储了分词的各种信息,可以通过TokenStream有效的获取到分词单元信息
TokenStream生成的流程
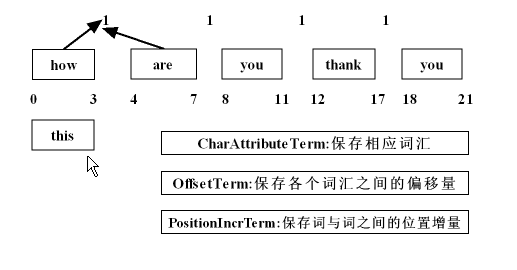
在这个流中所需要存储的数据
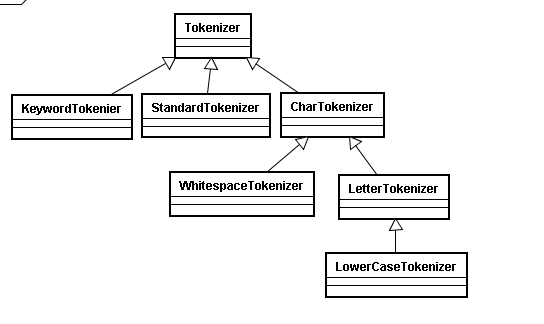
Tokenizer :
主要负责接收字符流Reader,将Reader进行分词操作。有如下一些实现类
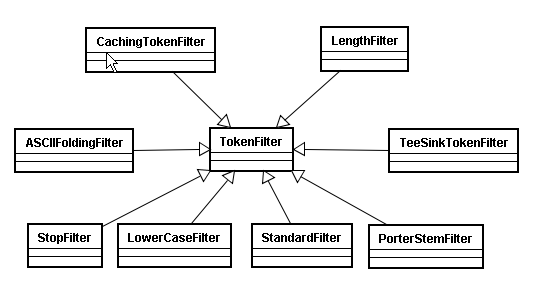
TokenFilter :
将分词的语汇单元,进行各种各样过滤