导论
云计算
云计算(Cloud Computing)是基于互联网的一种计算方式,通过这种方式,共享的软硬件资源和信息可以按需提供给计算机和其它设备。分布式计算(Distributed Computing)、并行计算(Parallel Computing)、效用计算(Utility Computing)、网络存储(Network Storage Technologies)、虚拟化(Virtualization)、负载均衡(Load Balance)等传统计算机和网络技术发展融合的产物。
应用:Google、Amazon 等
Hadoop
起源于Apache Nutch,核心:分布式文件系统子项目(HDFS)和支持MapReduce分布式计算的软件框架。
数据完整性
保证数据在传输的过程中不损坏,常见的保证数据完整性采用技术:
- 奇偶校验技术
- ECC 校验纠错技术
- CRC-32 循环冗余校验技术(HDFS)
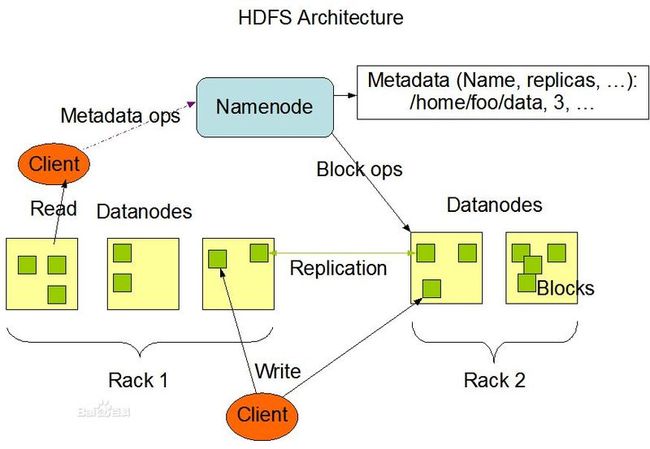
HDFS
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。HDFS有着高容错性(fault-tolerant)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的 数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以实现流的形式访问(streaming access)文件系统中的数据。HDFS开始是为开源的apache项目nutch的基础结构而创建,HDFS是Hadoop项目的一部分,而Hadoop又是Lucene的一部分。
Metadata(元数据)
元数据是用来描述数据的数据(Data that describes other data),比如描述一个人提及的“年龄”、“身高”、“相貌”、“性格”等一些信息,就是元数据。
Block(数据块)
NameNode(命名节点)
命名节点可以看作是分布式文件系统中的管理者,主要负责管理文件系统的命令空间、集群配置信息、存储块的复制。命名节点会存储文件系统的Metadata在内存中,这些信息主要包括了文件信息、每一个文件所对应的的文件块信息及每一个文件块在数据节点的信息。
- NameNode 主要功能提供名称查询服务,它是一个 jetty 服务器。
- NameNode 保存 metadata 信息包括:1、文件 owership 和 permissions。2、文件包含哪些块。3、block 保存在哪个 DataNode (由 DataNode 启动时上报)
- NameNode 的 metadata 信息在启动后会加载到内存中
- metadata 存储到磁盘文件名为 fsimage,block 的位置信息不会保存到 fsimage。($dfs.data.name/images)
DataNode(数据节点)
数据节点是文件存储的基本单位,它存储 Block 在本地文件系统中,保存了 Block 的Metadata,同时周期性地发送所有存在的 Block 的报告给命名节点。
- 保存 Block
- 启动 DataNode 线程的时候会向NodeName汇报 Block 信息
- 通过向 NodeName 发送心跳与其保持联系(3秒一次),如果 NodeName 10分钟没有收到 DataName 的心跳,则认为其已经 lost,并 copy 其上的 Block 到其它 DataName。
Block 的副本放置策略
- 第一个副本:放置在上传文件的 DataNode,如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。
- 第二个副本:放置在与第一个副本不同的机架的节点上。
- 第三个副本:与第二个副本相同的集群的节点
- 更多副本:随机节点
Block 存储
- 设置一个Block 64M,如果上传文件小于该值,仍然会占用一个Block的命名空间(NameNode metadata),但物理存储上不会占用 64M 的空间。
- Block 大小和副本数由 Client 端上传到 HDFS 时设置,其中副本数可以变更,Block 是不可以再上传后变更的。
数据损坏处理
- 当DN读取block的时候,它会计算checksum。
- 如果计算checksum,发现与block创建时值不一样,说明该block已经损坏。
- client读取其它DN上的block,NN标记该块已经损坏,然后复制block达到预期设置的文件备份数。
- DN在其文件创建后三周验证其checksum。
Client(客户端)
需要获取分布式文件系统文件的应用程序。
写入文件步骤:
- 客户端向命名数据发起文件写入请求。
- 命名节点根据文件大小和文件配置情况,返回给客户端所管理部分数据节点的信息。
- 客户端将文件划分为多个Block,根据数据节点的地址信息,按顺序写入每一个数据节点块中。
读取文件步骤:
- 客户端向命名节点发起文件读取的请求。
- 命名节点返回文件存储的数据节点信息。
- 客户端读取文件信息。
Block 复制文件步骤:
- 命名节点发现部分文件的Block不符合最小复制数或部分数据节点失效。
- 通知数据节点相互复制Block。
- 数据节点开始直接相互复制。
HDFS以透明的方式校验所有写入它的数据,在往HDFS写入文件时,并在默认的设置下,会在读取数据时验证校验和。针对数据的每个io.bytes.per.checksum(在core-site.xml中配置,默认512字节。),都会创建一个单独的校验和(crc校验码)。
数据节点(DataNode)负责在存储数据及其校验和之前验证它们收到的数据。 从客户端和其它数据节点复制过来的数据。客户端写入数据并且将它发送到一个数据节点管线中,在管线的最后一个数据节点验证校验和。
客户端读取数据节点上的数据时,会验证校验和,将其与数据节点上存储的校验和进行对比。每个数据节点维护一个连续的校验和验证日志,因此它知道每个数据块 最后验证的时间。每个数据节点还会在后台线程运行一个DataBlockScanner(数据块检测程序),定期验证存储在数据节点上的所有块,为了防止 物理存储介质中位衰减锁造成的数据损坏。
Hadoop 是 Apache 下的一个项目,由 HDFS、MapReduce、HBase、Hive 和 ZooKeeper 等成员组成。其中,HDFS 和 MapReduce 是两个最基础最重要的成员。
关系型数据库 与 MapRecue 比较
| 传统关系型数据库 | MapReduce | |
| 数据大小 | GB | PB |
| 访问 | 交互式和批处理 | 批处理 |
| 更新 | 多次读写 | 一次写入多次读取 |
| 结构 | 静态模式 | 动态模式 |
| 完整性 | 高 | 低 |
| 横向扩展 | 非线性 | 线性 |
MapRecude 与 关系型数据库的另一个区别在于:它们所操作的数据集的结构化程度。
- 结构化数据:具有概定格式的实体化数据,如 XML、满足预定义格式的数据库表。
- 半结构数据
- 非结构化数据
Hadoop能解决的问题
- 海量数据需要及时分析和处理。
- 海量数据需要深入分析和挖掘。
- 数据需要长期保存。
问题
- 磁盘IO成为一种瓶颈,而非CPU资源。
- 网络宽带是一种稀缺资源。
- 硬件故障成为影响稳定的一大因素。
Hadoop生态系统介绍
1)Hbase
- Nosql数据库,Key-Value存储。
- 最大化利用内存。
2)HDFS
- 分布式文件系统
- 最大化利用磁盘
3)MapReduce
- 编程模型,主要用来数据分析。
- 最大化利用CPU。