代码随想录算法训练营第六天|242.有效的字母异位词、349.两个数组的交集、202.快乐数、1.两数之和
文档讲解
哈希表 哈希碰撞 STL
当遇到需要查询一个集合中是否出现过某个元素的时候,通常会想到哈希表这种数据结构。那么什么是哈希表呢?存储位置=hash_fun(key),其与数组和链表这种结构都是不同的,它的存储位置是通过一个哈希函数来得到的。
哈希函数:h(key)=key%capacity;那如果这个key是负数呢?h(key)就是<0,那么显然是不正确的。故采用h(key)=(key%capacity+capacity)%capacity,而对于这个capacity,我们为了每次都落在hash_table中,取大于capacity的最小质数m,举个例子,capacity=10,此时m就该取值为11,若key=-103,h(-103)=(-103%11+11)%11=7。
其实呢,数组也是一种哈希表,但在使用数组当哈希表用的时候,会遇到一个问题?那就是哈希碰撞!哈希碰撞简单来讲,就是不同的key通过hash_fun之后,指向同一个存储位置,那么这个时候该位置应该存放哪个key呢?所以对于处理哈希碰撞,又有两种方法,分别是拉链法与开放寻址法,接下来就分别介绍一下这两种方法:
1.开放寻址法
其实这个方法很简单,就是如果发生哈希碰撞之后,在hash_table中挨着找,直到找到空位置,把该值放下,故这种情况你需要数组的大小开的是数据量的2~3倍。写一个例子来看看:
#include2.拉链法
拉链法:其就是以指向的位置为链表的头节点,以一个链表来存储指向同一位置的所有key,(所以掌握每种数据结构都是十分重要的)!写一个例子来看看:
#include拉链式最难理解的一个点就是插入操作,其是使用了一种方法叫做链式前向星,这里谈谈我自己的理解:举个例子:key1=-103,key2=7,capacity=10,h(k1)=7,h(k2)=7,故发生了哈希碰撞,这个时候考虑insert()是怎么运行的,
首先是插入-103的时候,idx=0,index=7,val[0]=-103,ne[0]=-1,h[7]=0,idx=1;
然后插入-7,idx=1,index=7,val[1]=7,ne[1]=0,h[7]=1,idx=2;
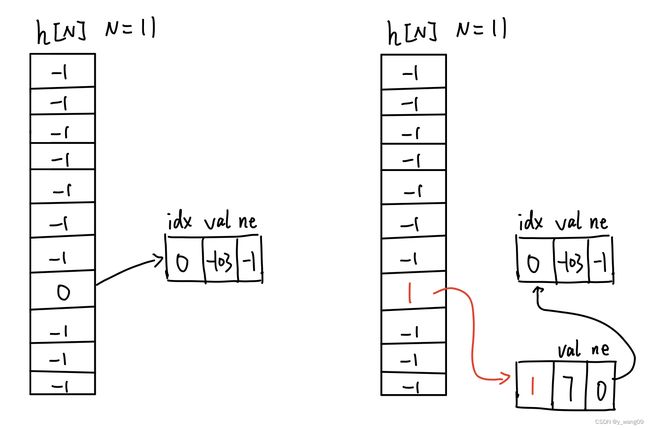
我认为理解这里的重点是千万不要val,ne,idx这三个数据分开去想。接下来的搜索是否存在的代码的思路就很清晰了,首先是找到h[hash_fun(x)],然后搜索完这个链表,看看是否存在这个value,不存在则返回false,存在就返回true;
那么我们在leetcode遇到哈希表的问题都是怎么样处理的呢?下面是几个题目:
242.有效的字母异位词
思路:针对哈希表的问题,首先选择对应的数据结构,1.数组;2.set;3.map,很明显这道题需要的数据结构的大小是已知的,故可以使用数组来充当哈希表!
时间复杂度:O(n)
空间复杂度:O(1)
class Solution {
public:
bool isAnagram(string s, string t) {
int record[26]={0};
for(int i=0;i<s.size();i++)
{
record[s[i]-'a']++;
}
for(int i=0;i<t.size();i++)
{
record[t[i]-'a']--;
}
for(int i=0;i<26;i++)
{
if(record[i]!=0)
{
return false;
}
}
return true;
}
};
349.两个数组的交集
思路:其实这道题和上面一道题思路差不多,区别在于1.数据量的大小未知;2.不允许重复。基于这两个特性,那么使用数组是不可能的,在剩下的set和map中选择,map是由key和value对应的,明显只需要一个就行了,故选择set,其中有三种set,我们要求不能重复且可以无序,故选择
unordered_set。
时间复杂度:O(n)
空间复杂度:O(n)
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> result;
unordered_set<int> s;
for(int i=0;i<nums1.size();i++)
{
s.insert(nums1[i]);
}
for(int i=0;i<nums2.size();i++)
{
if(s.count(nums2[i]))
{
result.insert(nums2[i]);
}
}
return vector<int>(result.begin(),result.end());
}
};
202.快乐数
思路:这道题最开始拿到的时候,其实没反应过来关键在哪里,首先将n转换成sum,去判断这个sum是否为1,但是还有一种情况,那就是这个数已经出现过了,陷入无限循环,此时应该立即返回false,故需要使用哈希表去处理这种重复的情况!
时间复杂度:O(logn)
空间复杂度:O(logn)
class Solution {
public:
int getsum(int n)
{
int sum=0;
while(n)
{
sum+=(n%10)*(n%10);
n/=10;
}
return sum;
}
bool isHappy(int n) {
unordered_set<int> myset;
while(1)
{
int sum=getsum(n);
if(sum==1)
{
return true;
}
else if(myset.find(sum)!=myset.end())
{
return false;
}
else
{
myset.insert(sum);
}
n=sum;
}
}
};
1.两数之和
思路:这道题一拿到,暴力爽啊!但是想到是哈希表能做,先找到一个数,在这时看看哈希表中有无能和它组成target的值,如果没有,这把这个数插入到哈希表中,这样就降低了时间复杂度!
时间复杂度:O(n)
空间复杂度:O(n)
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int,int> mymap;
for(int i=0;i<nums.size();i++)
{
auto iter=mymap.find(target-nums[i]);
if(iter!=mymap.end())
{
return vector<int>{iter->second,i};
}
mymap.insert(pair<int,int>(nums[i],i));
}
return {};
}
};