第四篇:python网络爬虫
文章目录
- 一、什么是爬虫
- 二、Python爬虫架构
- 三、安装第三方库
-
- 1. request(网页下载器)
- 2. Beautiful Soup(网页解析器)
- 四、URL管理器
- 五、练习
- 六、小结
一、什么是爬虫
爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。
二、Python爬虫架构
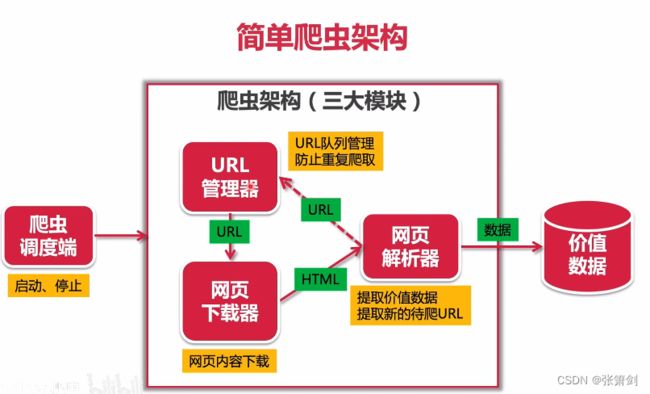
Python 爬虫架构主要由五个部分组成,分别是调度器、URL管理器、网页下载器、网页解析器、应用程序(爬取的有价值数据)。
- 调度器:相当于一台电脑的CPU,主要负责调度URL管理器、下载器、解析器之间的协调工作。
- URL管理器:包括待爬取的URL地址和已爬取的URL地址,防止重复抓取URL和循环抓取URL,实现URL管理器主要用三种方式,通过内存、数据库、缓存数据库来实现。
- 网页下载器:通过传入一个URL地址来下载网页,将网页转换成一个字符串,网页下载器有urllib2(Python官方基础模块)包括需要登录、代理、和cookie,requests(第三方包)
- 网页解析器:将一个网页字符串进行解析,可以按照我们的要求来提取出我们有用的信息,也可以根据DOM树的解析方式来解析。网页解析器有正则表达式(直观,将网页转成字符串通过模糊匹配的方式来提取有价值的信息,当文档比较复杂的时候,该方法提取数据的时候就会非常的困难)、html.parser(Python自带的)、beautifulsoup(第三方插件,可以使用Python自带的html.parser进行解析,也可以使用lxml进行解析,相对于其他几种来说要强大一些)、lxml(第三方插件,可以解析 xml 和 HTML),html.parser 和 beautifulsoup 以及 lxml 都是以 DOM 树的方式进行解析的。
- 应用程序:就是从网页中提取的有用数据组成的一个应用。
下面用一张图片来解释爬虫架构(图片源自bilibili博主python爬虫):
三、安装第三方库
1. request(网页下载器)
- requests:用于下载url的网页代码
下载方式:
pip install requests

发送request请求:
requests.get/post(url,params,data,headers,timeout,verify,allow_redirects,cookies)
- url:要下载的目标网页的URL
- params:字典形式,设置URL后面的参数,比如?id=123sname=xiaoming
- data:字典或者字符串,一般用于PoST方法时提交数据
- headers:设置user-agent、refer等请求头
- timeout:超时时间,单位是秒
- verify:True/False,是否进行HTTPS证书验证,默认是,需要自己设置证书地址
- allow_redirects:True/False是否让requests做重定向处理,默认是
- cookies:附带本地的cookies数据
接收response响应:
r = requests.get/post(url)
// 查看状态码,如果等于200代表请求成功
r.status_code
// 可以查看当前编码,以及变更编码
// (重要!requests会根据Headers推测编码,推测不到则设置为IS0-8859-1可能导致乱码)
r.encoding
查看返回的网页内容
r.text
查看返回的HTTP的headers
r.headers
//查看实际访问的URL
r.url
// 以字节的方式返回内容,比如用于下载图片
r.content
//服务端要写入本地的cookies数据
r.cookies
例如:
2. Beautiful Soup(网页解析器)
Beautiful Soup : 用于从HTML中提取数据
官网:http://www.crummy.com/software/BeautifulSoup/
安装:
pip install BeautifulSoup
语法(图片源自bilibili博主python爬虫):

- 创建BeautifulSoup对象:
from bs4 import BeautifulSoup
# 根据Html网页字符串创建BeautifulSoup对象
soup = BeautifulSoup(
html_doc, # HTML 文档字符串
'html.parser', #HTML 解析器
from_encoding='utf-8' #HTML文档的编码
)
- 搜索节点(find_all)
# 方法: find_all(name,attrs,string)
# 查找所有标签为a的节点
soup.find_all("a")
# 查找所有标签为a,链接符合/view/123.html形式的节点
soup.find_all("a",href='/view/123.html')
# 查找所有标签为div,class为abc,文字为python的节点
soup.find_all("div",class_='abc',string='python')
- 访问节点信息
# 得到节点: python
# 获取查找到的节点的标签名称
node.name # a
# 获取查找到的a节点的href属性
node['href'] # 1.html
#获取查找到的a节点的链接文字获取文本()
node.get_text() # python
四、URL管理器
对爬取URL进行管理,防止重复和循环爬取,支持新增URL和取出URL
- 图片来源bilibili 博主python爬虫

如何实现url管理器
首先创建文件夹 utils
创建python文件,命名为url_manger.py
具体代码如下:
class UrlManger():
'''
url管理器
'''
def __init__(self):
# 待爬取
self.new_urls = set()
# 已爬取
self.old_urls = set()
# 单个url添加
def add_new_url(self,url):
# 判url是否合格
if url is None or len(url) == 0:
return
# 判断url是否存在于 新的url 或者 老的url
if url in self.new_urls or url in self.old_urls:
return
self.new_urls.add(url)
# 批量添加url
def add_new_urls(self,urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
def get_url(self):
# 判断是否有待爬取的url true 或 false
if self.has_new_url():
# 有,取出url
url = self.new_urls.pop()
# 然后放入 爬取过的
self.old_urls.add(url)
return url
else:
return None
# 新的待爬取url
def has_new_url(self):
# 如果有 未爬取 的,返回true
return len(self.new_urls) > 0
测试:
if __name__ =="__main__":
url_manger = UrlManger()
# 传入测试数据
url_manger.add_new_url("url1")
url_manger.add_new_urls(["url1","url2"])
print(url_manger.new_urls,url_manger.old_urls)
print("-"*30)
print(url_manger.has_new_url())
# 运行一遍get_url 方法
print("-"*30)
new_url = url_manger.get_url()
print(url_manger.new_urls,url_manger.old_urls)
# 第二遍运行get_url方法
print("-"*30)
new_url = url_manger.get_url()
print(url_manger.new_urls,url_manger.old_urls)
# 检查是否还有 待爬取 url
print("-"*30)
print(url_manger.has_new_url())
运行结果如下:

五、练习
爬取天气预告网站十年内新乡的天气
涉及技术:
- headers中设置user agent 反爬机制
- 通过network抓包,分析ajax的请求和参数
- 通过for循环,请求不同的参数的数据
- 利用pandas实现excel的合并与保存
实现代码:
import requests
from bs4 import BeautifulSoup
import pandas as pd
from io import StringIO
# url地址
url="https://tianqi.2345.com/Pc/GetHistory"
# 请求头
headers = {
"User-Agent":"""Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0"""
}
def craw_table(year,month):
# 提供年份和月份,爬取对应的表格数据
params = {
"areaInfo[areaId]":53986,
"areaInfo[areaType]":2,
"date[year]":year,
"date[month]":month
}
# 响应
resp = requests.get(url,headers=headers,params=params)
# 展示HTML代码(是表格标签)
data = resp.json()["data"]
# 把表格标签转化为表格
# df = pd.read_html(data)[0]
df = pd.read_html(StringIO(str(data)))[0]
return df
df_list = []
for year in range (2012,2023):
for month in range(1,13):
print("爬取:",year,month)
df_list.append(craw_table(year,month))
# print(df.head())
pd.concat(df_list).to_excel("新乡的十年天气数据.xlsx",index=False)
实现效果:

六、小结
写本文主要是为了分享我的学习过程,也是给自己记个笔记,哪里忘记了,回来再看一眼,也可以很快的回想起来
注:本文主要供自己学习练习使用,大部分内容是从第三方平台截图复制而来(究极缝合怪),如有侵权请联系删除