第3.2章:Doris数据导入——Compaction机制(1)
目录
一、Compaction机制
1.1 compaction概述
1.2 compaction优点
1.3 compaction类型
二、Compaction的问题
2.1 compaction速度低于数据写入速度
2.2 写放大问题
三、数据版本的产生
四、base & cumulative compaction
注:本篇文章阐述的是Doris 1.2.2版本之前的compaction机制
一、Compaction机制
1.1 compaction概述
Doris的数据写入模型使用了LSM-Tree结构,数据以追加(append)的方式写入磁盘的。LSM-Tree数据结构可以将随机写变成顺序写,极大增强了系统的写入吞吐。但是读取时合并多次写入的数据(merge-on-read模式)。为了降低读取时需要合并的数据量,基于LSM-Tree的系统会引入后台数据合并的逻辑,以一定策略定期的对数据进行合并,Doris中这种机制被称为compaction。 Doris中每批次的数据写入会生成一个数据版本,因此compaction机制就是将多个数据版本合并成一个更大的版本。
Doris 通过类似 LSM-Tree 的结构写入数据,在后台通过 Compaction 机制不断将小文件合并成有序的大文件。对于单一的数据分片(tablet),数据会按照顺序写入内存(写缓存memstore),达到阈值后刷写到磁盘,形成一个个不可变更的数据文件,而这些文件保存在一个rowset中。在Doris中,Compaction机制根据一定的策略对这些rowset合并成有序的大文件,极大地提升查询性能。
每一个rowset都对应一个版本信息,表示当前rowset的版本范围,版本信息中包含了两个字段first和second,first表示当前rowset的起始版本(start version),end表示当前rowset的结束版本(endversion)。每一次数据导入都会生成一个新的数据版本,且保存在一个rowset中。未发生过compaction的rowset的版本信息中first和second字段相同。执行compaction时,相邻的多个rowset会进行合并,生成一个版本范围更大的rowset,合并生成的rowset版本信息会包含合并前的所有rowset的版本信息。
ps: Doris中数据组织如下图:
一个tablet中包含若干连续的rowset(rowset是逻辑概念),rowset代表tablet中一次数据变更的数据集合(数据变更包括了数据新增,更新或删除等)。rowset按版本信息进行记录,版本信息中包含了两个字段first和second,first表示当前rowset的起始版本(start version),end表示当前rowset的结束版本(endversion)。每一次数据导入都会生成一个新版本的rowset。

1.2 compaction优点
- 使得数据更加有序
每个数据版本内的数据是按主键有序的,但是版本之间的数据是无序的。compaction后形成的大版本将多个小版本的数据变成有序数据,在有序数据中进行数据检索的效率更高。
-
消除数据变更
数据都是以追加的方式写入的,因此delete,update等操作都是写入一个标记,compaction操作可以处理这些标记,进行真正的数据删除或更新,从而在读取时,不再需要根据这些标记来过滤数据。
- 增加数据聚合度
在聚合模型下,compaction能进一步聚合不同数据版本中相同key的数据行,从而增加数据聚合度,减少读取时需要实时进行的聚合计算。
1.3 compaction类型
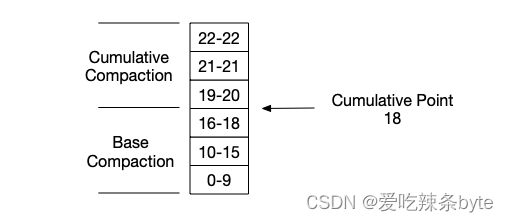
compaction可以分为两种类型:base compaction和cumulative compaction。其中cumulative compaction(简称CC)负责将多个最新导入的增量数据进行合并,当增量数据合并后的大小达到一定阈值后,base compaction(简称BC)将基线版本(起始版本start version为0的数据)和与该增量数据版本合并。BC操作因为涉及到基线数据,而基线数据通常比较大,所以操作耗时会比CC长。这两种compaction的边界通过cumulative point (简称cp)来确定。c是一个动态变化的版本号,比cp小的数据版本只能触发BC,而比cp大的数据版本,只会触发CC。
二、Compaction的问题
用户可能需要根据实际的使用场景来调整compaction的策略,否则可能遇到如下问题:
2.1 compaction速度低于数据写入速度
在高频写入场景下,短时间内生成的rowset版本太快,如果compaction不及时,就会造成大量版本堆积,导致累计版本超过了上限个数,进而触发阈值报错。例如:频繁执行insert into导致报错:close index channel failed。
理论上,每次导入操作,不论是只导入一条还是十万、百万条,对于Doris来说,都是只生成一个新的roswet版本。那么在compaction效率有限的情况下,完全可以通过“攒微批+降频率”来规避roswet版本过多的问题。
2.2 写放大问题
compaction本质上是将已经写入的数据读取后,重新写回的过程(读取多个小文件,合并成有序的大文件后再写回),这种重复的数据写入被称为写放大。一个好的compaction策略应该在保证效率的前提下,尽量降低写放大系数,因为过多的compaction会占用大量的内存及磁盘io资源,影响Doris集群的稳定性及查询性能。
三、数据版本的产生
将数据表按照分区分桶规则,切分成若干个数据分片(tablet)存储在不同的be节点上。每个tablet都有多个副本(默认是3副本)。compaction是在每个be上独立进行的,compaction逻辑处理的就是一个be节点上所有的数据分片tablet。
Doris的数据写入是以微批的方式进行的,每一个批次的数据针对每个tablet都会形成一个rowset。而一个tablet是由多个rowset组成的,每个rowset都有一个相应的起始版本和终止版本。对于新增的rowset,起始版本和终止版本是一样的,表示为[ 6-6]、[ 7-7]等。多个 rowset经过compaction会形成一个大的rowset。合并后的起始版本和终止版本是多个版本的并集,如[ 6-6]、[ 7-7]、[8-8]合并后变成 [6-8]。
rowset的数量直接影响到compaction是否能及时完成,那么一个批次的数据导入会生成多少个rowset呢? 结论:rowset的数量直接取决表的分片数据Tablet。(一个表的Tablet总数量等于 = Partition num * Bucket num* Replica Num )。即:当表的tablet数量是num时,一个批次的数据导入会新增num个rowset,也就意味着当前同时存在的rowset(数据变更的集合)就有num个。
有个疑问:单个tablet中的rowset版本个数过多会什么影响?
主要影响两个方面,一个是be存储节点的内存占用,当rowset的版本过多时,be节点的table_meta部分(主要是其中的rowset元数据部分)占用的内存可能非常多。同时compaction合并会消耗大量内存,开销较大容易引起oom,影响集群稳定性;二是查询会变慢,查询过程需要对tablet中的数据进行解压处理,当rowset版本很多时,数据解压会变慢,导致查询scan的耗时增加。
四、base & cumulative compaction
Doris中有两种compaction操作,分别是base compaction(BC) 和cumulative compaction
(CC)。其中cumulative compaction(简称CC)负责将多个最新导入的增量数据进行合并,当增量数据合并后的大小达到一定阈值后,base compaction(简称BC)将基线版本(起始版本start version为0的数据)和与该增量数据版本合并。BC操作因为涉及到基线数据,而基线数据通常比较大,所以操作耗时会比CC长。
如果只有base compaction,则每次增量数据都要和全量的基线数据合并,写放大问题会非常严重,每次 Compaction 都相当耗时。因此引入了cumulative compaction的概念。这块与一个通用的compaction的调优策略:在合理范围内,尽量减少base compaction操作。
BC和CC之间的分界线是cumulative point (cp),它是一个动态变化的版本号,比cp小的数据版本只能触发BC,而比CP大的数据版本,只会触发CC。
参考文章:
Doris 最佳实践-Compaction调优(1)