《A++ 敏捷开发》- 7 估算工作量
这几年大数据很火,很多高科技公司都推相关的工具或者方案,很多软件开发项目经理觉得应该也用数据分析,分析历史数据,准确预估项目工作量、工期。
但实际上,虽然预测模型已经有超过50年的历史,过千份研究报告、教材、指南,但使用在项目中不多。更多研究发现如果用专家估算可能更准确。
以上是2009年IEEE杂志中的文章,Jorgensen先生的结论。在文章里,Jorgensen与Boehm两位专家讨论模型与专家估算法的长短:

北欧学者Magne Jorgensen(左)过去10多年集中研究软件估算,发现专家估算法虽然很常用,但相关研究却不多。
Barry Boehm(右)81年出版Software Engineering Economics,后面又推出COCOMO预测模型,是模型估算的经典人物。
估算:靠模型,还是靠专家
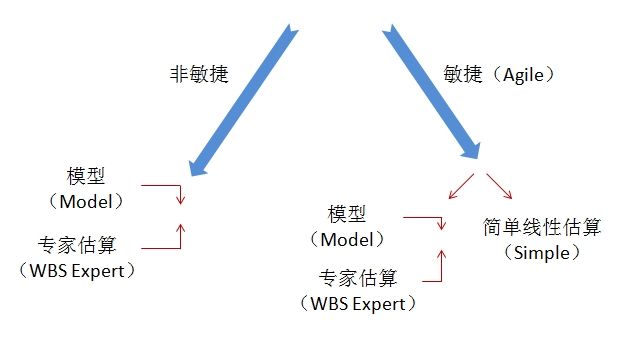
什么是专家估算?最典型的例子就是WBS估算,我们先把所有的任务,系统地分解出来,再召集团队和专家估算工作量(或工期)。
模型则是反过来:利用一些参数模型,如利用功能点数来做其中的一个输入,也包括其他因素,如复杂度、人员能力、平台等。
这两种方法的主要区分在于最后估算工作量的步骤:模型(例如COCOMO)通常是利用方程式根据输入自动估算出结果,如下图:

或基于国际功能点的ABC模型,依据功能点数、非功能点数,和其他(例如项目管理),ABC三部分综合估算总工作量(或成本):

另一方面,专家估算法,例如WBS估算,是以专家主观判断为主(例如判断活动完成的最可能人天数)。模型估算一般比较客观、具有可重复性,不像第一种(专家估算)那样主要依赖人的主管判断,且依赖估算专家的能力。
Jorgensen先生批评模型派,40多年这么多研究,为什么模型估算还不准确,甚至不如用WBS估算。反过来,Boehm先生说如果没有模型,整个估算就像个黑盒,无法知道规模、工作量、进度之间的关系,永远靠专家,尤其是在开发的初期,模型特别有用,因为早期需求模糊,无法很准确估算WBS工作量。
| 专家估算也有不同的变种,有些纯依赖专家主观判断,有些也会依赖历史数据和检查单,并非仅依赖挑选最佳的专家。有些估算方法,例如我们一般把扑克牌估算(Planning Poker)归属于专家估算,但如果最后估算主要依据上一轮冲刺的速度(Velocity)或生产率(Productivity),它就更类似模型估算了。 所以虽然模型估算和专家估算看起来有明显差异,但有时候不容易明确区分。下表通过比较专家与模型估算,总结了两种方式的主要区分:
|
所以当我们了解了模型与专家估算两者各有好处,没有绝对的对与错,就能理解为什么不能单靠模型预测,而是两者都要参考。比如模型可以更好地在早期判断,估计整个项目成本,还可以帮我们了解哪些因素会影响工作量(进度),需要关注。
为什么估算开发工作量/工期这么困难
你可能会质疑以上只是大学教授基于学术研究的结论, 实际上数学模型的估算不一定比专家估算差。 我们可以回顾美国SIT的 项目管理估算模拟实验。
软件项目管理学生用各种方法估计完成某乐高积木的时长,利用项目数据得出的预算模型的估算准确度还不如戴尔菲法专家估算。(详见附件)
由于软件开发主要靠人来做,非常依赖人,这导致影响生产率的因素很多,如积极性、经验、工具、团队合作等等。用数据挖掘、机器学习、更适合研究一些科学的问题(物理/化学/生物,如药品的化学成分),相关因素、效用等都好衡量。但是人的因素就没有这么简单。所以过去几十年虽然有不少关于工作量的估算模型被建立,但准确度一直不太理想。反过来,也不能单靠专家估算,它非常依赖专家的选择,因为人是主观的。虽然主观判断有可能帮助专家做好估算,但也正因为人的主观性,导致估算的偏差。例如某人做某类软件开发很有经验,他能更准确地估出这类开发的工作量,但如问她能否用一条方程式表达出来,他肯定不知道。
所以想做好软件开发的工作量估算,首先要理解估算本身的偏差会很大,影响因素很多,也因为无法预测所有(尤其是跟人相关的)因素的影响,个人经验就可以补充估算的不足。
估算软件开发的困难
我们有哪个软件开发像玩乐高积木这么直接简单?例如:
- 有明确固定的答案,也有明确的步骤,可以照着,按部就班完成。
- 如果中间过程有错,很容易立马看出来。
但软件开发往往是:
- 需求和规范经常有变动(有哪个项目从需求制订到最后开发完成,中间没有变化?)。
- 软件开发写错一句代码可能影响全盘。
因软件开发的需求往往是不确定的,所以敏捷大师们反对传统项目估算方式——需求(规模)是固定,估算出对应的工期与工作量,并制订整个项目计划与进度表,然后监控,确保项目没有超出计划工期/工时。他们觉得这种以计划驱动的传统管理模式直接影响了软件开发团队的生产效率,太多项目因为经理都只是管是否按期完成,是否没有超人时,而不考虑软件开发的质量是否给客户提供了价值,这反而影响到很多软件项目都被用户诟病。
| 在香港讲敏捷课时,某学员听完敏捷精益的概念后,说她的经理要求她输出一份3个月的详细工作任务分解,且要求活动的颗粒度细到5天之内,因为她的经理按计划管理的思路很重。她很困惑,软件开发变化这么多,怎么可以做出这种详细计划呢? 这其实有点像我们要在一个足球赛还没开始之前,要预先写赛后报告一样没意义,都是猜。 |
然后我跟她了说下面两个谷歌故事:
| 谷歌(Google) 公司是由两位史丹福大学研究生Larry Page , Sergey Brin 创办。在2000年,Eric Schmidt 加入当 CEO (他之前是 Novell CEO,以前在 SUN Microsystems 工作), Jonathan Rosenberg 也加入当产品经理 (他之前在 Apple 当产品经理)。 当时谷歌(Google)还是很小的公司,但因在搜索引擎上有所突破, 预计会被微软攻击和收购。董事会主席 Mike Moritz 便请刚进公司的CEO Eric和产品经理Jonathan准备了一份详细的商业计划书来应对。俩人经过两个多月细心准备,约创始人Larry开会解释计划详细内容,Larry拿到计划书快速看了一下,便立马问他们俩:“你们以往有试过超出你们的计划吗? 如果没有,建议还是先跟我们那些工程师聊聊吧。” 这些优秀人才被统称为谷歌内的聪明创意人(Smart Creatives)。 |
| 河马(Hippopotamuses)是攻击力很强,非常危险的动物。 谷歌公司用河马的英文简称 HiPPO (Highest Paid Person's Opinion),比喻企业类内的"大王"按自己的主观判断,雷厉风行也是非常危险。 |
学员下午做互动练习时便说自己公司里确实有不少“河马”横行。
从以上两故事看到,优秀的公司高层,无论东西方,都理解公司的发展依赖“大家的力量”和各人的智慧,同心协力,“大王”文化会妨碍公司持续改进,难以改善。
2000年时,谷歌在快速成长期。我通常会在敏捷培训课的第一天借用谷歌的故事说明团队敏捷开发的成败依赖于公司文化。
如果团队有能力,应让团队自主创新,传统计划反而会局限团队发挥是敏捷开发核心思想。
- 因为每次只估算后面迭代(2~4周)的工作量,偏差不会太大。
- 因为只估算本迭代需求相关工作,减少需求变更的风险。
因为按范围估算软件开发工作量很困难,所以只能根据有限的资源和时间,识别出那些对客户最重要的功能,评估能否在项目交付期限内完成。如果不能,再按功能对客户的价值,选择那些较低的功能可以先不做。
传统项目管理假定规模是固定的,敏捷开发则反过来,时间和资源是固定的,但生产率是根据团队前面的迭代速度得到的数据。
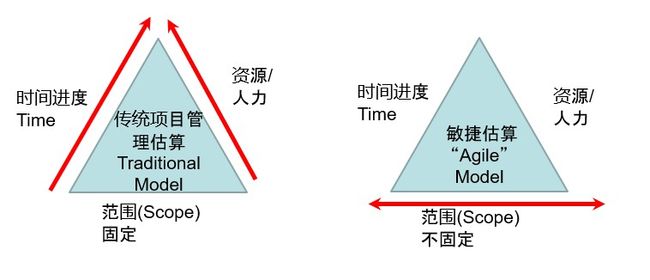
这个时间固定,但范围可变的思路,不仅仅适用于软件开发。例如,计划必须在月底前将整本书全部交稿,但草稿中有不少小错误,如果要全部都修正好,肯定不能按月底期限交付,所以就需要把一些可以删掉的部分删掉,确保书的质量,也把影响降到最低。与软件开发不同,书可以比较轻松删掉一两段,但软件之间的耦合性比较大,可能删掉一行语句整个程序就跑不通,所以更需要在交付前规划好开发的范围,最终才有机会可以按期交付。
敏捷是依据精益MVP概念、时间(资源)固定、范围可变,如果估计不能在交付期限前完成所有客户需求,便要尽早跟客户协商,选择哪些功能放在这次交付之内,哪些放在后面,希望在有限的时间和资源条件下,能给客户提供最高价值。
很多敏捷团队会用以下方式逐步做估算:
先把所有客户的需求写成故事卡片,作为整个项目的交付物(Backlog),然后按每次迭代(例如从第一次迭代):
- 先挑选最重要的故事,放在本次迭代,估计相关的故事点,故事点是一个简单的规模概念,团队按照类似的模块的工作量,估计每故事的故事点数(例如,可以用扑克牌举牌方式多轮估算,最终得出一个团队都赞同的故事点数)。
- 按本迭代可允许的人天数估计本迭代可以完成多少个故事点。
- 然后每次迭代结束后记录完成多少故事点,形成燃烧图(Burndown chart),看功能点的降低速度来预估整个项目最终完成的时间,需要多少个迭代。从燃烧图,故事点减少的速度计算项目速度(Velocity)。
+ + +
有些敏捷大师甚至反对估算,觉得估算只是凭个人经验拍脑袋,没有科学的依据,反而导致团队只关心进度不能延误,从而影响开发人员,使得开发人员反而不能专心专业地做好软件开发。
他们反对使用故事点估算,故事点按个人经验来估算,不同人的理解不一样,可能导致差异很大。同样,他们也反对敏捷(Velocity)速度的概念,觉得这只是另一个形式的传统策划思维,会导致团队只是关注在一个冲刺迭代后交付了多少个故事点,反而忽视了交付的软件是否对确实客户有价值。
但他们也理解到团队还是要预估可否在客户定的期限内交付,或者交付多少,因为这是客户关注的。他们建议直接把backlog里要交付的所有需求细分成小故事,每个故事最好是一人天左右,这样就很简单,可以按完成故事的速度,更客观地预计客户要最后交付的日期(例如10周后),可以完成多少故事。
例如共要求300个故事,按团队速度,10周后只能总共完成200,就要提前按优先级、重要性跟客户协商,挑选哪些在这个期间前交付,哪些放到下一次再做。(前提是:团队必须已经做了一些开发,知道每次两种迭代大概可以完成多少故事。)
结束语
选择哪种方法估算软件开发工作量,跟选择最合适的项目生命周期方法类似,取决于项目的特性和团队的能力。如果需求很明确且固定,也没有客户代表在每个迭代(2~4周)后进行确认,例如政府投标定制开发项目,就不一定选择精益思路的敏捷估算方法,而应依据范围(Scope)和规模(Size),估算工期与工作量,除了使用WBS分解从下而上靠专家/团队估算工作量与工期外,也要利用规模(功能点数),利用基于历史数据的估算模型从上而下估算(千万不要认为哪种估算最准确,其实都不准,但综合考虑可以减少偏差)。
对于需求很可能会变,客户参与较多,团队能力强的产品性开发项目,则采用时间/资源固定,范围可变的精益敏捷思路,就更能为干系人创造价值。如果可以把范围细分到很小的估算(每故事 ~1人天),可以依据以往历史速度,估算要完成所有需求一共要多少次迭代(或周)。但如果项目复杂,之间相互依赖,有些模块要多人合作,难以细分,就难以用前面的简单线性估算,需要团队估算工作量,但不应只依赖从下而上按任务估计工作量,也要参考规模大小,利用估算模型从上而下估算,然后综合考虑。
附件
估算砌乐高积木时长/2015年学生实验数据
2015年,17位有工作经验的兼读学生参加SIT的软件估算与度量课程(一个学期共13节课)。 为了让学员亲身感受软件估算的困难,老师要求学员用以下各种方式估算要完成乐高“Sopwith Camel”积木(详见下图)的时长:

- 每位学员独自做估算(I)。
- 使用戴尔菲法(Wideband Delphi),多轮后更新(个人)估算(II)。
- 分成3组,每组也使用戴尔菲法,制订本组的(团队)估算(II(团队))。
- 依据实验数据(注2)调整、更新(个人)估算(III)。
- 团队也依据实验数据调整、更新(团队)估算(III(团队))。
- 完成以上4、5步后,立马告知会选那位学员实际做LOGO积木(注3),让个人调整、更新(个人)估算(IV)。
- 也让团队调整、更新(团队)估算(IV(团队))。
| 注1:
注2: 让学员自己做乐高实验(因有些学员可能从未玩过乐高积木),提供4对同样的积木:
注3:
|

实验结果与讨论

- 那学员用了213分钟(差不多3.55个小时)完成,他自述困难主要在于颜色都很类似,很多时候找不到合适的积木。(跟其他体验组比较,其他2~3 组都在210~220分钟范围之内完成)。
- 戴尔菲法显著减少了个人估算的偏差,用戴尔菲的团队估算其实是最接近实际的,估得最好的,偏差不超过15分钟。开始时,尤其个人都会多估,但后面数据越来越多,反而开始有点偏低了。
- 可能导致后面估算偏低的原因:之前实验用的4组积木都是建筑物,复杂度与颜色搭配都较简单。
经验教训
- 学生经过这个过程可以从实验亲身感受到估算的局限,没有想象这么准确,因太多因素影响,也很难建立一个预测模型,比如偏差可能到了0.3以上。
- 从这个过程里面也让他们感受到主观判断的重要性,不要以为仅仅客观用一些数据、用数学方程式就可以准确估出正确的答案。
- 了解复杂度和人对生产力的影响,比如积极性跟经验都是很重要的因素。例如,有一个学生经验很少,但竞争力和积极性非常高,所以有好的成绩。有两个团队也是完成同一套模型,发现本来自己判断为高经验的团队反而比中经验的团队花多一倍时间,最慢的团队是一个两人团队,因为基本没有经验,所以就很小心,一步一步去做,尽量减少错误,导致用的时间最长。
- 团队规模大小也有影响,团队人数越多其实是对整个生产力有负面影响,人数少反而会好一些。(其他关于软件开发的研究也有类似的发现)。
很多人以为软件项目估算与其他项目(如土木)类似。以上实验,虽然不是真正做软件开发,学生自己做估算,从亲身体验学习,更好了解软件项目估算的常见误解:
- 以为软件估算可以精确到正负几个百分点。
- 以为在项目时间不够的时候,增加人员对项目的进度会有帮助。
- 以为团队人越多,工期就按比例缩短,像建筑工程一样。
- 以为估算是可以单靠一些预测模型简单地估出一个数值。
学生都没有软件项目的经验,我们也不可能在上课的时候做软件项目,于是用乐高积木,让他们做估算,比如我们让他们依据一个结果图,估算要多少人时来完成积木,也要看人的乐高经验,首先第一步是他们单独做估算。我们在课程中用了戴尔菲估算法,每个人多轮估算。确实找人来建乐高,看看实际用了多少时间。然后我们在课程中加了一些估算模型,用一些历史数据给他们进行参考,下面就是我们的一些发现:很多人在没有经验的时候都会高估,用了戴尔菲法的方式会确实比较准确。后面有了实际数据,要求学生利用软件项目估算模型方式来估,他们就发现这不容易,很多时候,有学生直接改用简单方程式做估算。学生自己动手来估算,才会有感觉,真正了解软件估算的各种困难。
| 学生ID | 经验水平(自估) | I | II | III | IV |
|---|---|---|---|---|---|
| 1 | 0 | 14.3 | 3.7 | 2.25 | 2.25 |
| 2 | Low | 10 | 4 | 2.5 | 2.5 |
| 3 | Low | 20 | 4.5 | 3.75 | 3.75 |
| 4 | Medium | 3 | 5 | 4.5 | 3 |
| 5 | Medium | 2.5 | 4 | 3.2 | 3.2 |
| 6 | Low | 8 | 4.1 | 4.1 | 3 |
| 7 | 0 | 20 | 7 | 5 | 3.5 |
| 8 | Medium | 20 | 5 | 4 | 2.75 |
| 9 | Medium | 4.5 | 5 | 4.5 | 3.5 |
| 10 | Medium | 3 | 3 | 3 | 2.5 |
| 11 | High | 4.6 | 3.8 | 2.8 | 2.4 |
| 12 | Medium | 2 | 2.5 | 2.7 | 2.3 |
| 13 | Low | 6.5 | 3.5 | 2.5 | 2.5 |
| 14 | 0 | 18 | 6 | 5 | 3 |
| 15 | Low | 20 | 3 | 3 | 3 |
| 16 | High | 5 | 5.5 | 2.3 | 2.5 |
| 17 | High | 15 | 3.8 | 2.7 | 2.4 |
| Mean 均值 | - | 10.4 | 4.3 | 3.4 | 2.8 |
| Median | - | 8 | 4 | 3 | 2.8 |
| SD 标准差 | - | 7 | 1.1 | 0.9 | 0.4 |
注:上面 I、II、III、IV 与下面 II、III、IV的定义,对应哪种场景,已经在上面本文里说明。
| 团队 ID | II(团队) | III(团队) | IV(团队) |
|---|---|---|---|
| 1 | 3.8 | 2.7 | 2.4 |
| 2 | 3.7 | 3.4 | 3.16 |
| 3 | 4 | 4.3 | 2.85 |
| Mean 均值 | 3.8 | 3.5 | 2.8 |
| Median | 3.8 | 3.4 | 2.9 |
| SD 标准差 | 0.1 | 0.7 | 0.3 |
| Team ID | # Pieces | 对象人群岁数 | 团队人数 | 实际总工作量(分钟) | 模型估计总工作量 (分钟) | 偏差 MRE |
|---|---|---|---|---|---|---|
| 1 | 346 | 12+ | 1 | 37 | 46.21 | 0.25 |
| 2 | 321 | 12+ | 1 | 48 | 45.39 | 0.05 |
| 3 | 261 | 7 to 12 | 1 | 32 | 43.19 | 0.35 |
| 4 | 345 | 12+ | 1 | 45 | 46.18 | 0.03 |
| 5 | 261 | 7 to 12 | 1 | 59 | 43.19 | 0.27 |
| 6 | 345 | 12+ | 2 | 114 | 73.48 | 0.36 |
| 7 | 346 | 12+ | 3 | 84 | 96.48 | 0.15 |
| 8 | 321 | 12+ | 4 | 104 | 114.90 | 0.10 |
注:偏差 MRE(Magnitude of Relative Error) = | (实际 - 估算) | / 实际
参考References
- Jorgensen, Magne, with B. Boehm. "Software Development Effort Estimation: Formal Models or Expert Judgment? " , IEEE SOFTWARE, March/April 2009
- Laird, Linda,with Y. Yang. "Engaging Software Estimation Education using LEGOs: A Case Study." 2016 IEEE/ACM International Conference on Software Engineering Companion
- Duarte,Vasco. NO ESTIMATES: How to Measure Project Progress without Estimating. (2016)