周报(202402018)
日期:2024.2.12 - 2024.2.18
本周工作:
1. 了解Mamba
1.1 Mamba
Mamba模型是一个创新的线性时间序列建模方法,巧妙地结合了递归神经网络(RNN)和卷积神经网络(CNN)的特点,解决了处理长序列时的计算效率问题。它通过状态空间模型(SSM)的框架,实现了RNN的逐步处理能力和CNN的全局信息处理能力的融合。在训练阶段,Mamba使用卷积模式来一次性处理整个输入序列,而在推理阶段则采用递归模式,逐步处理输入,这样的设计使得Mamba既能充分利用CNN的高效并行处理能力,又能保持RNN在序列数据处理上的灵活性。
Mamba模型的核心创新在于引入了选择性机制,这一机制通过使SSM参数依赖于输入,使得模型可以根据不同的输入动态调整其行为。这类似于RNN中的门控机制,但在SSM的框架下提供了更广泛的应用可能性。通过这种方式,Mamba能够有效地过滤掉无关信息,同时保留和加强与任务相关的信息,提高了对长序列数据的处理能力。
为了优化计算效率,Mamba采用了硬件感知算法,特别是利用GPU的内存层次结构来提高扫描操作的计算速度和降低内存需求。这种方法结合了RNN的递归计算效率和CNN的并行处理优势,使得Mamba在处理长序列数据时更加高效。
在架构设计上,Mamba简化了传统的SSM架构,通过合并H3和MLP块,形成了一个均匀堆叠的结构。这不仅简化了模型的结构,还提高了模型的灵活性和效率。
Mamba模型通过结合RNN和CNN的优点,并引入创新的选择性机制和硬件感知算法,成功地解决了传统Transformer模型在处理长序列数据时的计算效率问题,展现了在处理各种序列数据,尤其是语言、音频和基因组学数据时的出色性能和效率。
1.2 视觉Mamba
Mamba 的提出带动了研究者对状态空间模型(state space model,SSM)兴趣的增加,不同于 Transformer 中自注意力机制的计算量会随着上下文长度的增加呈平方级增长,由于 SSM 擅长捕捉远程依赖关系,因而开始受到大家追捧。
在此期间,一些基于 SSM 的方法如线性状态空间层(LSSL)、结构化状态空间序列模型(S4)、对角状态空间(DSS)和 S4D 都被研究者提出来,用于处理各种序列数据,特别是在建模远程依赖关系方面。
Mamba 将时变参数纳入 SSM 中,并提出了一种硬件感知算法来实现高效的训练和推理。Mamba 卓越的扩展性能表明它在语言建模方面是 Transformer 有前途的替代品。
然而,到目前为止,研究者还尚未在视觉任务中探索出通用的基于纯 SSM 的骨干网络。
受 Mamba 在语言建模方面成功的激励,研究者开始设想能否将这种成功从语言转移到视觉,即用先进的 SSM 方法设计通用且高效的视觉主干。然而,由于 Mamba 特有的架构,需要解决两个挑战,即单向建模和缺乏位置感知。
为了应对这些问题,研究者提出了 Vision Mamba (Vim) 块,它结合了用于数据依赖的全局视觉上下文建模的双向 SSM 和用于位置感知视觉识别的位置嵌入。
与其他基于 SSM 的视觉任务模型相比,Vim 是一种基于纯 SSM 的方法,并以序列方式对图像进行建模。与基于 Transformer 的 DeiT 相比,Vim 在 ImageNet 分类上取得了优越的性能。此外,Vim 在 GPU 内存和高分辨率图像的推理时间方面更加高效。
2. 阅读论文
2.1 《Mamba-UNet: UNet-Like Pure Visual Mamba for Medical Image Segmentation》

背景
提出了Mamba UNet,这是一种将医学图像分割中的U-Net与Mamba的能力协同的新架构。
Mamba UNet采用了纯基于视觉Mamba(VMamba)的编码器-解码器结构,融入了跳跃连接,以保存网络不同规模的空间信息。这种设计有助于全面的特征学习过程,捕捉医学图像中复杂的细节和更广泛的语义上下文。
在VMamba块中引入了一种新的集成机制,以确保编码器和解码器路径之间的无缝连接和信息流,从而提高分割性能。
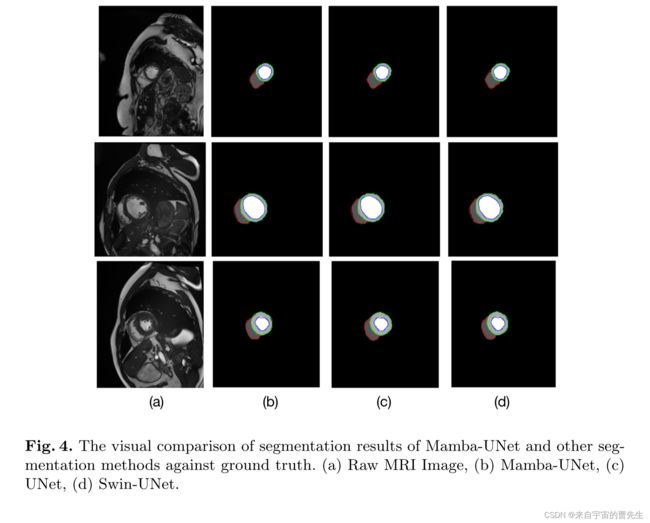
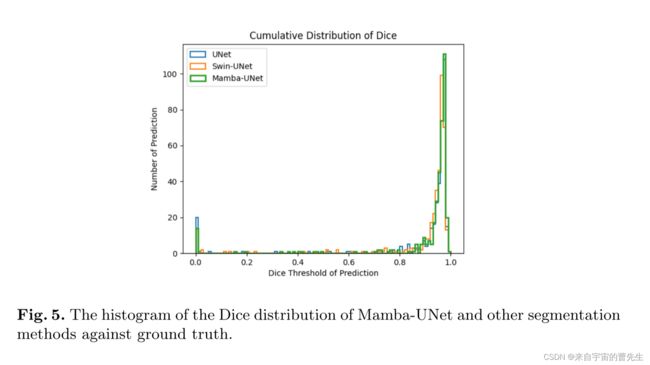
在公开的MRI心脏多结构分割数据集上进行了实验。结果表明,在相同的超参数设置下,Mamba UNet在医学图像分割方面优于UNet、SwinUNet。
关于UNet的最新发展图总结
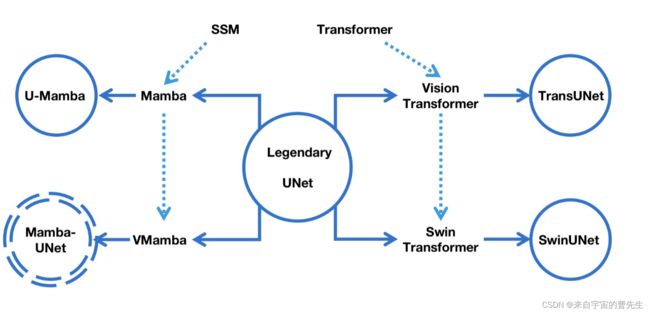
针对当前研究问题提出新的方法
Transformers擅长捕捉长程依赖关系,但由于自注意机制与输入大小的二次缩放,其高计算成本带来了挑战,尤其是对于高分辨率生物医学图像。
状态空间模型(SSM),特别是结构化SSM(S4)的最新发展,以其在处理长序列方面的高效性能提供了一种有前途的解决方案。
Mamba模型通过选择性机制和硬件优化增强了S4,在密集数据域中显示出卓越的性能。
在视觉状态空间模型(VMamba)中引入交叉扫描模块(CSM),通过实现空间域的遍历并将非因果视觉图像转换为有序的补丁序列,进一步增强了Mamba对计算机视觉任务的适用性。受这些功能的启发,在U-Net架构中利用Visual Mamba块(VSS)来改进医学图像分析中的长期依赖性建模,从而产生Mamba UNet。
方法
-
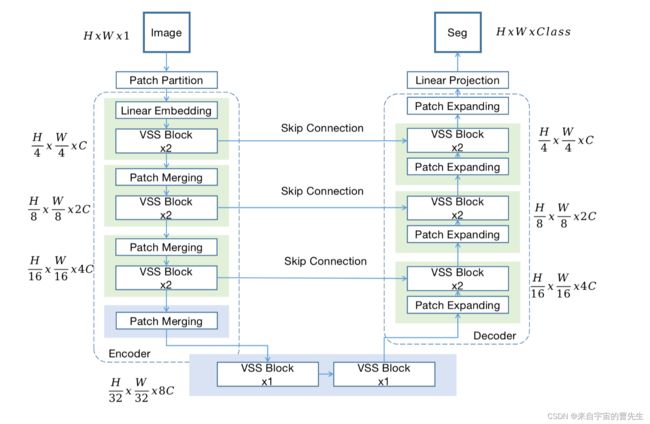
体系结构概述
上图概述了Mamba UNet的架构,其动机是UNet和Swin UNet。输入的H×W×1的二维灰度图像首先被吐出类似于ViT和VMamba的块,然后被吐出尺寸为H/4×W/4×16的一维序列。初始线性嵌入层将特征维度调整为任意大小,表示为C。然后通过多个VSS块和补丁合并层处理这些补丁令牌,创建分层特征。面片合并层处理下采样和维度增加,而VSS块专注于学习特征表示。各级编码器的输出分辨率分别为H/4×W/4×C、H/8×W/8×2C、H/16×W/16×4C和H/32×W/32×8C。解码器包括VSS块和遵循编码器风格的补丁扩展层,能够实现完全相同的特征大小输出,从而增强通过跳过连接进行下采样时丢失的空间细节。在编码器和解码器的每一个中,使用2个VSS块,并在编码器中加载预训练的VMamba Tiny,遵循与Swin UNet加载预训练SwinViT Tiny相同的过程。以下小节将讨论VSS块、编码器的补丁合并和解码器的补丁扩展的细节。 -
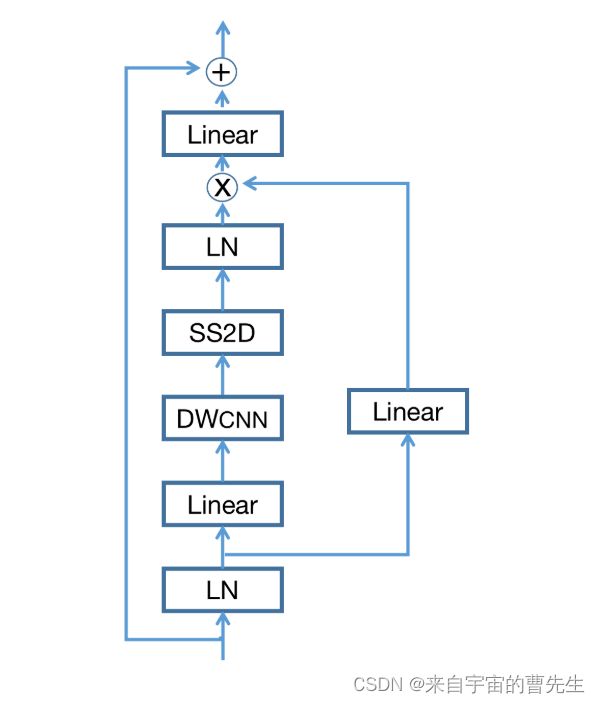
VSS块
VSS网络块如图所示,主要基于Visual Mamba。在VSS块中,输入特征首先遇到线性嵌入层,然后分叉为双路径。一个分支经历深度卷积和SiLU激活,继续到SS2D模块,以及层后归一化,与SiLU激活后的备用流合并。与典型的视觉转换器不同,这种VSS块避免了位置嵌入,选择了无MLP阶段的流线型结构,从而在相同的深度预算内实现了更密集的块堆叠。
-
编码器
在编码器中,分辨率降低的C维标记化输入经过两个连续的VSS块进行特征学习,保持尺寸和分辨率。在Mamba UNet的编码器中,补丁合并作为下采样过程被使用了三次,通过将输入分割成4个象限,将它们连接起来,然后每次通过层形式对维度进行归一化,将令牌计数减少了1/2,同时将特征维度增加了2倍。 -
解码器
与编码器类似,解码器利用两个连续的VSS块进行特征重构,采用补丁扩展层而不是合并层来放大深度特征[3]。这些层提高了分辨率(2×放大),同时将特征尺寸减半12,例如,初始层在重组和缩小特征尺寸以提高分辨率之前将特征尺寸加倍。 -
瓶颈和跳过连接
两个VSS块用于Mamba UNet的瓶颈。每一级编码器和解码器都采用跳跃连接,将多尺度特征与放大输出相融合,通过合并浅层和深层来增强空间细节。随后的线性层保持了该集成特征集的维度,确保了与放大分辨率的一致性。
实验
使用MICCAI 2017挑战赛中公开的ACDC MRI心脏分割数据集进行了实验。
为了满足ViT分割骨干网络的输入要求,将所有图像的大小调整为224×224。对数据集进行分区,将20%的图像分配给测试集,其余图像用于训练(包括验证)。
该实现是在Ubuntu 20.04系统上执行的,使用Python 3.8.8、PyTorch 1.10和CUDA 11.3。硬件设置包括一个Nvidia GeForce RTX 3090 GPU和一个Intel Core i9-10900K CPU。平均运行时间约为5小时,包括数据传输、模型训练和推理过程。该数据集专门用于2D图像分割。Mamba UNet模型接受了10000次迭代的训练,批量大小为24。采用随机梯度下降(SGD)优化器[2],学习率为0.01,动量为0.9,权重衰减设置为0.0001。每200次迭代在验证集上评估网络性能,只有在验证集获得新的最佳性能后,才能保存模型权重。

总结
介绍了Mamba UNet,它是一种纯粹基于视觉Mamba块的UNet风格的医学图像分割网络。
性能表明,与UNet和Swin UNet等经典的类似网络相比,Mamba UNet具有优越的性能。
作者团队的目标是从不同的模式和目标对更多的医学图像分割任务进行更深入的探索,并与更多的分割骨干进行比较。
此外,作者的目标是将Mamba UNet扩展到3D医学图像,以及半/弱监督学习,以进一步促进医学成像的发展。