Java基础-集合框架
集合框架:
内存层面可考虑的数据存储容器:数组,集合
数组的特点:长度,存储元素类型确定,既可以放基本数据类型,也可以放引用数据类型
缺点:长度不可变,存储元素特点单一,属性方法少,删除插入性能差
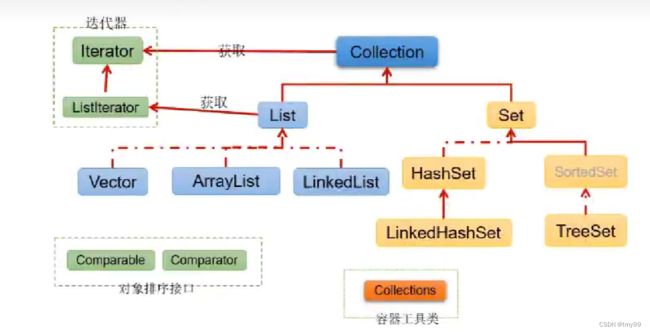
集合体系:
java.util.Collection:存储一个一个的数据
|-----子接口:List:存储有序的、可重复的数据 ("动态"数组)
|---- ArrayList(主要实现类)、LinkedList、Vector
|-----子接口:Set:存储无序的、不可重复的数据(高中学习的集合)
|---- HashSet(主要实现类)、LinkedHashSet、TreeSet
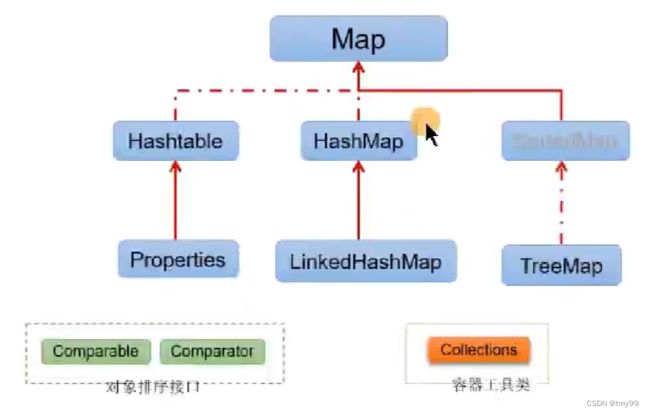
java.util.Map:存储一对一对的数据(key-value键值对,(x1,y1)、(x2,y2) --> y=f(x),类似于高中的函数)
|---- HashMap(主要实现类)、LinkedHashMap、TreeMap、Hashtable、Properties
collection下的方法:
add(Object obj) addAll(Collection coll) clear() isEmpty() size()
contains(Object obj) containsAll(Collection coll) retainAll(Collection coll)
remove(Object obj) removeAll(Collection coll) hashCode()
equals() toArray()
iterator()说明:
1. 迭代器(Iterator)的作用:用来遍历集合元素的。
2. 获取迭代器(Iterator)对象:Iterator iterator = coll.iterator();
3. 如何实现遍历(代码实现)
while(iterator.hasNext()){
System.out.println(iterator.next()); //next():①指针下移 ② 将下移以后集合位置上的元素返回
}
4. 增强for循环(foreach循环)的使用(jdk5.0新特性)
作用:用来遍历数组、集合。
格式:for(要遍历的集合或数组元素的类型 临时变量 : 要遍历的集合或数组变量){
操作临时变量的输出
}
说明:
> 针对于集合来讲,增强for循环的底层仍然使用的是迭代器。
> 增强for循环的执行过程中,是将集合或数组中的元素依次赋值给临时变量,注意,循环体中对临时变量的修改,可能不会导致原有集合或数组中元素的修改。(涉及对象属性则会改变)
集合与数组的相互转换:
集合 ---> 数组:toArray()
数组 ---> 集合:调用Arrays的静态方法asList(Object ... objs)
向Collection中添加元素的要求:要求元素所属的类一定要重写equals()!
原因:因为Collection中的相关方法(比如:contains() / remove())在使用时,要调用元素所在类的equals()。
list接口中常用方法:(包含collection中)
- 插入元素
- `void add(int index, Object ele)`:在index位置插入ele元素
- boolean addAll(int index, Collection eles):从index位置开始将eles中的所有元素添加进来
- 获取元素
- `Object get(int index)`:获取指定index位置的元素
- List subList(int fromIndex, int toIndex):返回从fromIndex到toIndex位置的子集合
- 获取元素索引
- int indexOf(Object obj):返回obj在集合中首次出现的位置
- int lastIndexOf(Object obj):返回obj在当前集合中末次出现的位置
- 删除和替换元素
- `Object remove(int index)`:移除指定index位置的元素,并返回此元素
- `Object set(int index, Object ele)`:设置指定index位置的元素为ele
小结:
增:add(Object obj);addAll(Collection coll)
删:remove(Object obj);remove(int index)
list中remove参数优先选择是索引,存在数据和索引冲突时(显式将其包装为对象)
eg:list.remove(2)-删除索引2的元素,list.remove(integer.valueof(2))-删除list中数据2
改:set(int index, Object ele)
查:get(int index)
插:add(int index, Object ele);addAll(int index, Collection eles)
长度:size()
遍历:iterator() :使用迭代器进行遍历;增强for循环;一般的for循环
List及其实现类特点
java.util.Collection:存储一个一个的数据
|-----子接口:List:存储有序的、可重复的数据 ("动态"数组)
|---- ArrayList:List的主要实现类;线程不安全的、效率高;底层使用Object[]数组存储
在添加数据、查找数据时,效率较高;在插入、删除数据时,效率较低
|---- LinkedList:底层使用双向链表的方式进行存储;在对集合中的数据进行频繁的删除、插入操作时,建议使用此类
在插入、删除数据时,效率较高;在添加数据、查找数据时,效率较低;
|---- Vector:List的古老实现类;线程安全的、效率低;底层使用Object[]数组存储
Set及其实现类特点
java.util.Collection:存储一个一个的数据
|-----子接口:Set:存储无序的、不可重复的数据
|---- HashSet:主要实现类;底层使用的是HashMap,即使用数组+单向链表+红黑树结构进行存储。(jdk8中)
|---- LinkedHashSet:是HashSet的子类;在现有的数组+单向链表+红黑树结构的基础上,又添加了一组双向链表,用于记录添加元素的先后顺序。即:我们可以按照添加元素的顺序实现遍历。便于频繁的查询操作。
|---- TreeSet:底层使用红黑树存储。可以按照添加的元素的指定的属性的大小顺序进行遍历。
使用场景:> 用来过滤重复数据
eg:对arraylist中重复对象去重-使用set
HashSet set = new HashSet(list);
List list1 = new ArrayList(set);
return list1;Set中常用方法:即为Collection中声明的15个抽象方法。没有新增的方法。
Set中无序性、不可重复性的理解(以HashSet及其子类为例说明)-理解为存放位置的不确定
>无序性: != 随机性。
添加元素的顺序和遍历元素的顺序不一致,是不是就是无序性呢? No!
到底什么是无序性?与添加的元素的位置有关,不像ArrayList一样是依次紧密排列的。
这里是根据添加的元素的哈希值,计算的其在数组中的存储位置。此位置不是依次排列的,表现为无序性。
>不可重复性:添加到Set中的元素是不能相同的。
比较的标准,需要判断hashCode()得到的哈希值以及equals()得到的boolean型的结果。
哈希值相同且equals()返回true(先比哈希再比equals),则认为元素是相同的。放入集合后,对对象的元素进行修改不会重新计算哈希值(map的底层逻辑)
添加到HashSet/LinkedHashSet中元素的要求:
要求元素所在的类要重写两个方法:equals() 和 hashCode()。
同时,要求equals() 和 hashCode()要保持一致性!我们只需要在IDEA中自动生成两个方法的重写即可,即能保证两个方法的一致性。
TreeSet的使用;底层的数据结构:红黑树; 添加数据后的特点:可以按照添加的元素的指定的属性的大小顺序进行遍历。
向TreeSet中添加的元素的要求:
> 要求添加到TreeSet中的元素必须是同一个类型的对象,否则会报ClassCastException.
> 添加的元素需要考虑排序:① 自然排序 ② 定制排序
注意: 判断数据是否相同的标准
> 不再是考虑hashCode()和equals()方法了,也就意味着添加到TreeSet中的元素所在的类不需要重写hashCode()和equals()方法了
> 比较元素大小的或比较元素是否相等的标准就是考虑自然排序或定制排序中,compareTo()或compare()的返回值。如果compareTo()或compare()的返回值为0,则认为两个对象是相等的。由于TreeSet中不能存放相同的元素,则后一个相等的元素就不能添加到TreeSet中。
Map及其实现类对比
java.util.Map:存储一对一对的数据(key-value键值对,(x1,y1)、(x2,y2) --> y=f(x),映射)
|---- HashMap:主要实现类;线程不安全的,效率高;可以添加null的key和value值;底层使用数组+单向链表+红黑树结构存储(jdk8)
|---- LinkedHashMap:是HashMap的子类;在HashMap使用的数据结构的基础上,增加了一对双向链表,用于记录添加的元素的先后顺序,进而我们在遍历元素时,就可以按照添加的顺序显示。开发中,对于频繁的遍历操作,建议使用此类。
|---- TreeMap:底层使用红黑树存储;可以按照添加的key-value中的key元素的指定的属性的大小顺序进行遍历。需要考虑使用①自然排序 ②定制排序。
|---- Hashtable:古老实现类;线程安全的,效率低;不可以添加null的key或value值;底层使用数组+单向链表结构存储(jdk8)
|---- Properties:其key和value都是String类型。常用来处理属性文件。
HashMap的底层实现(① new HashMap() ② put(key,value))
HashMap中元素的特点
> HashMap中的所有的key彼此之间是不可重复的、无序的。所有的key就构成一个Set集合。--->key所在的类要重写hashCode()和equals()
> HashMap中的所有的value彼此之间是可重复的、无序的。所有的value就构成一个Collection集合。--->value所在的类要重写equals()
> HashMap中的一个key-value,就构成了一个entry。
> HashMap中的所有的entry彼此之间是不可重复的、无序的。所有的entry就构成了一个Set集合。
Map中的常用方法(所有实现类都有)
- 添加、修改操作:
- Object put(Object key,Object value):将指定key-value添加到(或修改)当前map对象中,key可以为null
- void putAll(Map m):将m中的所有key-value对存放到当前map中
- 删除操作:
- Object remove(Object key):移除指定key的key-value对,并返回value
- void clear():清空当前map中的所有数据
- 元素查询的操作:
- Object get(Object key):获取指定key对应的value
- boolean containsKey(Object key):是否包含指定的key
- boolean containsValue(Object value):是否包含指定的value
- int size():返回map中key-value对的个数
- boolean isEmpty():判断当前map是否为空
- boolean equals(Object obj):判断当前map和参数对象obj是否相等
- 元视图操作的方法:
- Set keySet():返回所有key构成的Set集合
- Collection values():返回所有value构成的Collection集合
- Set entrySet():返回所有key-value对构成的Set集合
小结:
增:put(Object key,Object value); putAll(Map m)
删:Object remove(Object key)
改:put(Object key,Object value);putAll(Map m)
查:Object get(Object key)
长度:size()
遍历:遍历key集:Set keySet();遍历value集:Collection values();遍历entry集(类:Map.entry(entry有getkey和getvalue方法)):Set entrySet()
TreeMap的使用(类比TreeSet)
> 底层使用红黑树存储;
> 可以按照添加的key-value中的key元素的指定的属性的大小顺序进行遍历。
> 需要考虑使用①自然排序 ②定制排序。
> 要求:向TreeMap中添加的key必须是同一个类型的对象。
Hashtable与Properties的使用
Properties:是Hashtable的子类,其key和value都是String类型的,常用来处理属性文件。
Collections 是一个操作 Set、List 和 Map 等集合的工具类。
常用方法
排序操作:
- reverse(List):反转 List 中元素的顺序
- shuffle(List):对 List 集合元素进行随机排序
- sort(List):根据元素的自然顺序对指定 List 集合元素按升序排序
- sort(List,Comparator):根据指定的 Comparator 产生的顺序对 List 集合元素进行排序
- swap(List,int, int):将指定 list 集合中的 i 处元素和 j 处元素进行交换
查找
- Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素
- Object max(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最大元素
- Object min(Collection):根据元素的自然顺序,返回给定集合中的最小元素
- Object min(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最小元素
- int binarySearch(List list,T key)在List集合中查找某个元素的下标,但是List的元素必须是T或T的子类对象,而且必须是可比较大小的,即支持自然排序的。而且集合也事先必须是有序的,否则结果不确定。
- int binarySearch(List list,T key,Comparator c)在List集合中查找某个元素的下标,但是List的元素必须是T或T的子类对象,而且集合也事先必须是按照c比较器规则进行排序过的,否则结果不确定。
- int frequency(Collection c,Object o):返回指定集合中指定元素的出现次数
复制、替换
- void copy(List dest,List src):将src中的内容复制到dest中
使用要求dest的size大于src的size,否则会抛出异常,正确使用:
List dest = Arrays.asList(new Object[src.size()]);
Collections.copy(dest,src);
- boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换 List 对象的所有旧值
- 提供了多个unmodifiableXxx()方法,该方法返回指定 Xxx的不可修改的视图(只可读不可修改,用final修饰人可以增加修改)
添加
- boolean addAll(Collection c,T... elements)将所有指定元素添加到指定 collection 中。
同步
- Collections 类中提供了多个 synchronizedXxx() 方法,该方法可使将指定集合包装成线程同步的集合,从而可以解决多线程并发访问集合时的线程安全问题
区分Collection 和 Collections:
Collection:集合框架中的用于存储一个一个元素的接口,又分为List和Set等子接口。
Collections:用于操作集合框架的一个工具类。此时的集合框架包括:Set、List、Map