【编程二三事】SQL是如何执行的?
前言
Mysql是我们日常接触最多的一个开发组件了。但是,一个SQL是如何从我们的应用程序里传递到数据库里去的呢?数据库又是如何解析并处理这些SQL语句的呢?别急,让我给你一一道来。
整体架构
开门见山,我这里先绘制出Mysql数据库整个流程的一个架构图。

从图中不难看出,Mysql的架构主要划分为三层:客户端、Server层和存储引擎层。
客户端层:顾名思义,是调用Mysql数据库进行存储的各类程序,以Java开发为例子,最常见的就是SpringBoot框架体系的tomcat容器。这一层主要负责将客户端的请求数据传输到Mysql中。
Server层:在获取到了客户所需要查询的语句后,Mysql就能直接查询了吗?当然不是,众所周知,绝大多数的开发者在查询,更新的时候,基本都不会考虑怎么查询才是最快、最节省空间的。那么在系统上,mysql自然要对这些查询做优化,而这就是Server层的作用。对接收到的语句进行二次调整、改善。
存储引擎层:在对输入语句优化完成之后,mysql就可以进入到执行的操作中了。当然,需要执行也不是这么简单的。以我们常用的Innodb引擎为例子,需要综合考虑性能、健全性、回滚数据恢复等等情况,因此也衍生出了三个比较常见的Log数据对象。
在简单的介绍了三个层级的划分以后,让我们逐一来看看,各个分层都有些什么特殊的实现吧。
客户端层
数据库连接池
对于客户端层来说,最主要的功能便是保持和外部业务系统的连接稳定。为了保持稳定性,那么在选择连接的时候就需要考虑TCP/IP的协议类型。但是我们都知道,建立一次这样的连接是十分耗费时间的。而且通常情况下,咱们的数据库面对的都是成千上万的并发网络请求。如果频繁的把资源耗费在建立连接上,那么资源的有效利用率就会很低。

解决的方案也很简单,我将几个连接作为常用连接保存起来,等到外部调用的时候我就直接取这些连接不就行了吗?于是,数据库连接池应运而生。
连接池会将一定数量的连接线程维护起来,不做销毁的处理,等第二次请求数据来的时候直接使用,从而减少了线程创建销毁的成本。另一方面,如果线程数不足了,那么此时也会及时停下连接,从某种程度上也是做了一次限流处理,避免过多的并发压力把数据库打挂掉。
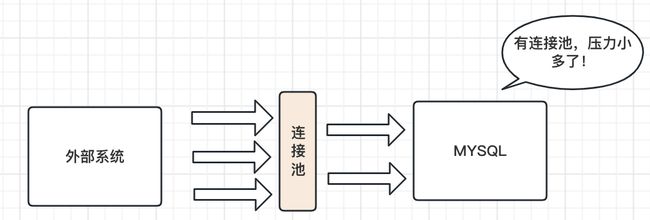
由此从另一个方面分析,数据库的连接数是固定的,也就导致如果前面一个连接不释放,后续的请求是没法处理的。为此,我们在编写SQL的时候也需要十分的注意慢SQL的情况,避免因为慢SQL拖垮了整个数据库的性能。
查询缓存
除了通过连接池管理线程减少创建/销毁连接的成本以外,mysql还维护了一个查询缓存。其思路其实跟我们采用redis等实现的分布式缓存类似。都是企图通过将热点数据缓存下来,从而减少后续的数据搜索、查询的逻辑。
但是其缺陷也很明显,就是在每一次写入的时候都会将这部分缓存清空(避免查询到脏数据),由此导致这部分的缓存逻辑命中率其实并不高,且还需要频繁的刷新,带来的成本其实更大,因此在8.0版本以后的mysql中,这个设计就被废除掉了。
Server层
在获取到用户的连接,并收到SQL语句后,Mysql还需要将其解析为机器能够读懂的操作。为此首先需要对这些SQL语句进行解析。 而这就是查询解析器需要执行的逻辑。
解析器
查询解析器会将用户传入的SQL语句进行预处理和解析,并生成相关的语法树。
select * from user where userId = 1234;
比如上述的语句,mysql就会自动识别select、from、where等关键词。同时,如果用户填写的数据有误,那么此时解析器也会提示用户进行修正:
ERROR: You have an error in your SQL syntax.
优化器
在解析器解析完成语句以后,还需要对用户的代码进行相关的优化处理。例如调整用户的SQL语句使其走索引等处理。这里我简单举一个实际例子:
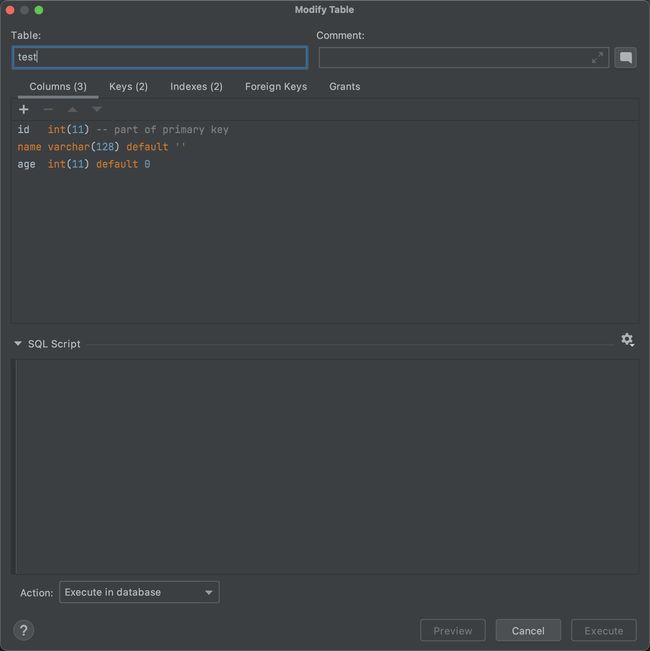
简单建立了一个表,同时设置索引为(name,age)。随后咱们分析如下语句:
explain select *
from test
where age = '' and name = '';
由于咱们设置的索引为(name,age),按照最左匹配的原则来说,这条语句理应是没法走索引的。但是实际咱们验证下来就会发现,其实这个查询还是走了索引的。

而这其中就是优化器的作用,他会将我们的SQL语句按照能够执行索引的方向查询处理。从而尽可能的提升每次查询的效率。
执行器
执行器这里的逻辑就相对比较少了,主要是调用选择的执行引擎将数据执行完成后返回。常见的执行引擎有MyISAM和Innodb,后文的内容主要以最常使用的Innodb进行展开。
存储引擎层
缓冲池 (Buffer Pool)
在Server层处理完用户输入的SQL语句后,就轮到了实际存储引擎去搜索数据的过程。但我们知道,数据库的数据都是存储在磁盘中的。而一次磁盘IO所需要耗费的时间是十分多的,那么有没有什么办法可以减少这样的开销呢?
其实思路上是跟我们上述提到的数据库连接、查询缓存也类似,在存储引擎层,会有一个名为Buffer Pool多的结构,其中存储着被查询到的热点数据。通过这样的缓存存储,将热点的数据查询从磁盘IO转变成了内存读写,那么这样的操作速度就能够以几何倍数加快。
当然,查询的逻辑也随之转变成了如下图所示:
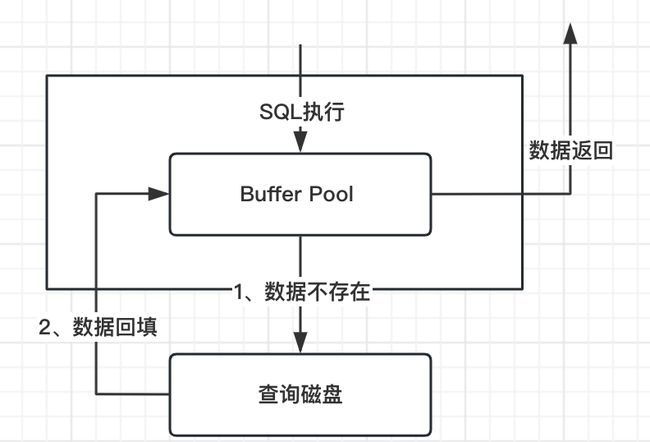
进来的SQL会优先查询是否在Buffer Pool中存在,如果存在,那么直接处理,否则就进行IO读写,同时将读写完的街过会写到BufferPool里面。
undo Log
再获取到数据以后,一部分SQL还可能需要对数据进行修改的操作。那么这个时候就不得不考虑一个问题了,如果数据更新失败/更新错了,同事务内的数据怎么恢复呢?
谈到这个,你就不得不了解一下UndoLog了。
UndoLog,顾名思义,就是未执行前的日志。在每次要对数据更新的时候,Mysql都会将数据的原始模样保存到UndoLog里面,如此一来,如果当前的数据更新失败了,需要进行回滚了,那么此时mysql就只需要按照UndoLog的记录进行回退。
因此,咱们SQL修改的逻辑就变成了下面这样:
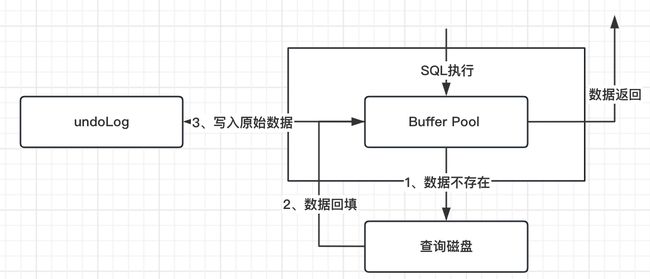
redo Log
在记录下原始数据后,语句当然就要对BufferPool中的数据进行修改了。但是需要注意的点就是,BufferPool是存储在内存中的数据。如果一旦断电,那么此时就会导致内存中的数据全部丢失。你的修改也就功亏一篑了。
为此,InnoDB特地在写入磁盘之前,会记录一下要执行的语句是哪些,并存放到一个名为redoLog的日志中,从而避免因为宕机、断电等原因造成的数据丢失。
由此一来,我们的整个的SQL执行流程就变成了如下所示:

这里有小伙伴可能就要问了,“为什么不直接写数据库呀?这多了一次写redoLog的成本,不是更麻烦了吗?”。说实话,我一开始也没搞明白,但是翻阅了一些资料后我大概了解到,虽然写数据库磁盘和写redoLog都是磁盘IO的持久化操作,但是两者记录的数据内容是不一样的。
redoLog可能只需要记录每次执行的SQL是什么,数量少且都是顺序写入。但是写入数据的操作,都是随机读盘,且都是按照一个磁盘页去做刷入处理的,速度自然会更慢一些。
从这个角度也不难看到,Mysql为了保证系统的稳定性,也是下足了功夫。而且为了进一步增加写入redoLog的效率,mysql还设计了一个redo Log Buffer,用于缓存待写入的数据。等到某个时刻,将数据统一刷入到磁盘中,从而节省写入的次数,减少磁盘IO的次数。
bin Log
上述介绍的redoLog是Innodb引擎级别的日志。对于Mysql本身来说,他也有记录整个操作流程的诉求。比如常见的分布式集群下,从节点需要拷贝主节点的数据,就需要这样类似的操作记录。(参考文章:从一个主从延迟问题,学习Mysql主从复制原理)
于是,Mysql本身也设计了一个记录操作语句的日志,这个日志就是BinLog。
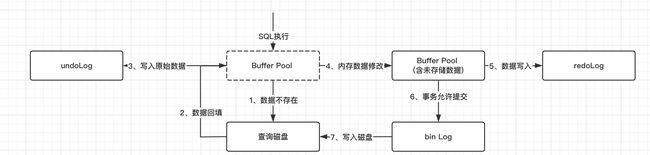
那么可能有人会想问了,binLog和redoLog的差别是什么呢?总结了一下,主要有以下几点:
- redoLog记录所有的数据变动,而binLog只记录事务提交时候的数据变动。
- 日志格式不同,redoLog主要记录数据的变化,即:xx表xx数据发生了xx变化;而binLog则更倾向于记录,采用xx语句更新xx数据库。
- 用途不一样,binLog是用于主从复制、人工恢复数据等使用的。而redoLog则是引擎内部使用的,是用于出现故障时恢复数据使用的。
总结
那么最后回顾总结下来,执行一句SQL语句大致要经过如下的步骤:
第一层需经过客户层,建立客户端与Mysql数据库之间的连接。其中,Mysql会通过连接池、数据缓存等方式,减少连接的耗时、查询的耗时。
第二层会经过服务层,该层主要针对用户输入的语句信息进行翻译、解析、校验等逻辑。依次对应于解析器、优化器、执行器
第三层则会经过存储引擎层,该层主要针对解析完成的SQL语句做处理执行。会在执行前记录下数据原始状态(undoLog)、变更中的每个过程态(redoLog)、以及数据最后的保存态(binLog)。
更多精彩内容,欢迎关注wx公众号【笑傲菌】~
参考文献
字节三面:详解一条 SQL 的执行过程
第三篇:SQL是如何执行的?
一条sql语句究竟是如何执行的