C语言知识点
进程线程的区别
进程是系统进行资源分配和调度的一个独立单位。线程是进程的一个实体,是cpu调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。线程自己基本上不拥有系统资源,只拥有在运行中必不可少的资源(如程序计数器,寄存器和栈),可与同进程下的其他线程共享所有资源。
进程切换耗费资源较大,效率低。一个进程崩溃后不会影响其他进程。
一个线程可以创建和撤销另一个线程;同一个进程中的多个线程可以并发执行。
一个程序至少有一个进程。一个进程至少要有一个线程。
进程间通信方式有哪些
1 无名管道通信
无名管道( pipe ) :管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
2 高级管道通信
高级管道 (popen) : 将另一个程序当做一个新的进程在当前程序进程中启动,则它算是当前程序的子进程,这种方式我们成为高级管道方式。就是pipe fork execve的集合体。
3 命名(有名)管道通信
有名管道 (named pipe ,fifo) :有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。与管道不同,FIFO不是临时的对象,它们是文件系统中真正的实体,可以用mkfifo命令创建。FIFO是一种先进先出的队列.它类似于一个管道,只允许数据的单向流动.每个FIFO都有一个名字,允许你不相关的进程访问同一个FIFO,因此也成为命名管.
4 消息队列通信
消息队列( message queue ) : 消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
5 信号量通信
信号量( semophore ) : 信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
6 信号
信号 ( signal ) : 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
7 共享内存通信
共享内存( shared memory ) :共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。
8 套接字通信
套接字( socket ) : 套接口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同机器间的进程通信。
简述C函数:1)参数如何传递(__cdecl调用方式);2)返回值如何传递;3)调用后如何 返回到调用前的下一条指令执行。
__cdecl 是C Declaration的缩写(declaration,声明),表示C语言默认的函数调用方法:所有参数从右到左依次入栈,这些参数由调用者清除,称为手动清栈。被调用函数不会要求调用者传递多少参数,调用者传递过多或者过少的参数,甚至完全不同的参数都不会产生编译阶段的错误。
从《深入理解计算机系统》的压栈出栈和PC来讲。
简述处理器中断处理的过程(中断向量、中断保护现场、中断嵌套、中断返回等)。 请响关保识保服恢返
中断向量:中断服务程序的入口地址。
中断处理过程:
请求中断→响应中断→关闭中断→保留断点→中断源识别→保护现场→中断服务子程序→恢复现场→中断返回。
中断嵌套:当CPU正在处理优先级较低的一个中断,又来了优先级更高的一个中断请求,则CPU先停止低优先级的中断处理过程,去响应优先级更高的中断请求,在优先级更高的中断处理完成之后,再继续处理低优先级的中断,这种情况称为中断嵌套。
中断返回:在中断服务子程序的最后要安排一条中断返回指令IRET,执行该指令,系统自动将堆栈内保存的 IP/EIP和CS值弹出,从而恢复主程序断点处的地址值,同时还自动恢复标志寄存器FR或EFR的内容,使CPU转到被中断的程序中继续执行。
简述处理器在读内存的过程中,CPU核、cache、MMU如何协同工作?画出CPU核、 cache、MMU、内存之间的关系示意图加以说明(可以以你熟悉的处理器为例)。
这个看《深入理解计算机系统》虚拟内存那章。
请说明总线接口USRT、I2C、USB的异同点(串/并、速度、全/半双工、总线拓扑等)。
USRT:串,慢,全双工,txd,rxd,gnd,LSB first
I2C:串,100k,400k,3.4M,不能同时收发,sda,scl,gnd 可以挂有多个设备,只有主机能发时钟。MSB first
SPI:串,快,SPI同时收发;收发公用一个SCK信号。从机不能产生时钟信号,因此不能主动向主机发送数据。Sdi,sdo,sclk,cs。MSB first
USB:VCC,D+,D-,GND,2.0:480Mbps半双工,3.0:10Gbps全双工,USB3.0 标准针对此进行了改进,增加了5根信号线,分别是:SSTXP+,SSTXM-,GND,SSRXP+,SSRXM-,因此可以支持全双工。
列举你所知道的linux内核态和用户态之间的通信方式并给出你认为效率最高的方式, 说明理由。
内核态: CPU可以访问内存所有数据, 包括外围设备, 例如硬盘, 网卡. CPU也可以将自己从一个程序切换到另一个程序
用户态: 只能受限的访问内存, 且不允许访问外围设备. 占用CPU的能力被剥夺, CPU资源可以被其他程序获取
1)用户态切换到内核态的3种方式
a. 系统调用
这是用户态进程主动要求切换到内核态的一种方式,用户态进程通过系统调用申请使用操作系统提供的服务程序完成工作。而系统调用的机制,其核心还是使用了操作系统为用户特别开放的一个中断来实现,
b. 异常
当CPU在执行运行在用户态下的程序时,发生了某些事先不可知的异常,这时会触发由当前运行进程切换到处理此异常的内核相关的程序中,也就是转到了内核态,比如缺页异常。
c. 外围设备的中断
当外围设备完成用户请求的操作后,会向CPU发出相应的中断信号,这时CPU会暂停执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序,如果先前执行的指令是用户态下的程序,那么这个转换的过程自然也就发生了由用户态到内核态的切换。比如硬盘读写操作的完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等。
这3种方式是系统在运行时由用户态转到内核态的最主要方式,其中系统调用可以认为是用户进程主动发起的,异常和外围中断是被动的。
《深入理解计算机系统》异常:“中断,陷阱,故障,终止”
procfs 就是/proc文件夹
netlink 就是socket
syscall 就是系统调用
IOCTL ioctl机制,ioctl机制可以在驱动中扩展特定的ioctl消息,用于将一些状态从内核反应到用户态。
采用内存映射的方式,将内核地址映射到用户态。这种方式最直接,可以适用大量的数据传输机制。内存映射应该是最高效的。
获得ip的命令:ifconfig
获得路由的命令:route
系统运行情况:top
static全局变量
其中.text段保存进程所执行的程序二进制文件,.data段保存进程所有的已初始化的全局变量,.bss段保存进程未初始化的全局变量(其他段中还有很多乱七八糟的段,暂且不表)。在进程的整个生命周期中,.data段和.bss段内的数据时跟整个进程同生共死的,也就是在进程结束之后这些数据才会寿终就寝。
当一个进程的全局变量被声明为static之后,它的中文名叫静态全局变量。静态全局变量和其他的全局变量的存储地点并没有区别,都是在.data段(已初始化)或者.bss段(未初始化)内,但是它只在定义它的源文件内有效,其他源文件无法访问它。所以,普通全局变量穿上static外衣后,它就变成了新娘,已心有所属,只能被定义它的源文件(新郎)中的变量或函数访问。
static局部变量
普通的局部变量在栈空间上分配,这个局部变量所在的函数被多次调用时,每次调用这个局部变量在栈上的位置都不一定相同。局部变量也可以在堆上动态分配,但是记得使用完这个堆空间后要释放之。
static局部变量中文名叫静态局部变量。它与普通的局部变量比起来有如下几个区别:
1)位置:静态局部变量被编译器放在全局存储区.data(注意:不在.bss段内,原因见3)),所以它虽然是局部的,但是在程序的整个生命周期中存在。
2)访问权限:静态局部变量只能被其作用域内的变量或函数访问。也就是说虽然它会在程序的整个生命周期中存在,由于它是static的,它不能被其他的函数和源文件访问。
3)值:静态局部变量如果没有被用户初始化,则会被编译器自动赋值为0,以后每次调用静态局部变量的时候都用上次调用后的值。这个比较好理解,每次函数调用静态局部变量的时候都修改它然后离开,下次读的时候从全局存储区读出的静态局部变量就是上次修改后的值。
存储区
静态存储方式:是指在程序运行期间分配固定的存储空间的方式。
动态存储方式:是在程序运行期间根据需要进行动态的分配存储空间的方式。
用户存储空间可以分为三个部分:
1) 程序区;
2) 静态存储区;
3) 动态存储区;
全局变量全部存放在静态存储区,在程序开始执行时给全局变量分配存储区,程序行完毕就释放。在程序执行过程中它们占据固定的存储单元,而不动态地进行分配和释放;
动态存储区存放以下数据:
1) 函数形式参数;
2) 自动变量(未加static声明的局部变量);
3) 函数调用实的现场保护和返回地址;
对以上这些数据,在函数开始调用时分配动态存储空间,函数结束时释放这些空间。
大小端
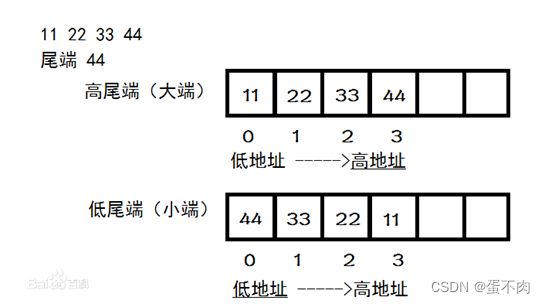
static union { char c[4]; unsigned long l; }endian_test = { { 'l', '?', '?', 'b' } };
#define ENDIANNESS ((char)endian_test.l)
上面这个估计是32位的可用
#include
int main()
{
short int x;
char x0,x1;
x=0x1122;
x0=((char *)&x)[0]; //低地址单元
x1=((char *)&x)[1]; //高地址单元
printf("x0=0x%x,x1=0x%x",x0,x1);// 若x0=0x11,则是大端; 若x0=0x22,则是小端......
return 0;
}
实时操作系统与分时操作系统
实时操作系统(Real Time Operating System)是指当外界事件或数据产生时,能够接受并以足够快的速度予以处理,其处理的结果又能在规定的时间之内来控制生产过程或对处理系统做出快速响应,调度一切可利用的资源完成实时任务,并控制所有实时任务协调一致运行的操作系统。
提供及时响应和高可靠性是其主要特点。
实时操作系统是保证在一定时间限制内完成特定功能的操作系统。实时操作系统有硬实时和软实时之分,硬实时要求在规定的时间内必须完成操作,这是在操作系统设计时保证的;软实时则只要按照任务的优先级,尽可能快地完成操作即可。我们通常使用的操作系统在经过一定改变之后就可以变成实时操作系统。
分时操作系统(Time-sharing Operating System):使一台计算机采用片轮转的方式同时为几个、几十个甚至几百个用户服务的一种操作系统。把计算机与许多终端用户连接起来,分时操作系统将系统处理机时间与内存空间按一定的时间间隔,轮流地切换给各终端用户的程序使用。由于时间间隔很短,每个用户的感觉就像他独占计算机一样。分时操作系统的特点是可有效增加资源的使用率。
分时操作系统的特点:
1. 多路性:即众多联机用户可以同时使用同一台计算机;
2. 独占性:各终端用户感觉到自己独占了计算机;
3. 交互性:用户与计算机之间可进行“会话”。
4. 及时性:用户的请求能在短时间内得到响应
1.指针函数
先看下面的函数声明,注意,此函数有返回值,返回值为int *,即返回值是指针类型的。
int *f(int a, int b);
2.函数指针
顾名思义,函数指针说的就是一个指针,但这个指针指向的函数,不是普通的基本数据类型或者类对象。
int (*f)(int a, int b); // 声明函数指针
位域
位域是指信息在存储时,并不需要占用一个完整的字节, 而只需占几个或一个二进制位。
struct bs
{int a:8;int b:2;int c:6;}data;
说明data为bs变量,共占2个字节。其中位域a占8位,位域b占2位,位域c占6位。
#pragma pack(n) 指定内存对齐,VC 8对齐 ,GCC 4 对齐
RT-Thread简介
RT-Thread是一款来自中国的开源嵌入式实时操作系统,由国内一些专业开发人员从2006年开始开发、维护,除了类似FreeRTOS和UCOS的实时操作系统内核外,也包括一系列应用组件和驱动框架,如TCP/IP协议栈,虚拟文件系统,POSIX接口,图形用户界面,FreeModbus主从协议栈,CAN框架,动态模块等,因为系统稳定,功能丰富的特性被广泛用于新能源,电网,风机等高可靠性行业和设备上,已经被验证是一款高可靠的实时操作系统。
RT-Thread实时操作系统遵循GPLv2+许可证,实时操作系统内核及所有开源组件可以免费在商业产品中使用,不需要公布应用源码,没有任何潜在商业风险。
堆和栈的区别
一、预备知识—程序的内存分配
一个由C/C++编译的程序占用的内存分为以下几个部分
1、栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
2、堆区(heap) — 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表,呵呵。
3、全局区(静态区)(static)—,全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另 一块区域。 - 程序结束后由系统释放。
4、文字常量区 —常量字符串就是放在这里的。 程序结束后由系统释放
5、程序代码区—存放函数体的二进制代码。
二、例子程序
//main.cpp
int a = 0; 全局初始化区
char *p1; 全局未初始化区
main()
{
int b; 栈
char s[] = "abc"; 栈
char *p2; 栈
char *p3 = "123456"; 123456/0在常量区,p3在栈上。
static int c =0; 全局(静态)初始化区
p1 = (char *)malloc(10);
p2 = (char *)malloc(20);
分配得来得10和20字节的区域就在堆区。
strcpy(p1, "123456"); 123456/0放在常量区,编译器可能会将它与p3所指向的"123456"
优化成一个地方。
}
二、堆和栈的理论知识
2.1申请方式
stack:
由系统自动分配。 例如,声明在函数中一个局部变量 int b; 系统自动在栈中为b开辟空间
heap:
需要程序员自己申请,并指明大小,在c中malloc函数
如p1 = (char *)malloc(10);
在C++中用new运算符
如p2 = new char[10];
但是注意p1、p2本身是在栈中的。
2.2 申请后系统的响应
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
堆:首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内存空间中的 首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。 另外,由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
2.3申请大小的限制
栈:在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意 思是栈顶的地址和栈的最大容量是系统预先规定好的,在WINDOWS下,栈的大小是2M(也有 的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
2.4申请效率的比较:
栈由系统自动分配,速度较快。但程序员是无法控制的。
堆是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便.
另外,在WINDOWS下,最好的方式是用VirtualAlloc分配内存,他不是在堆,也不是在栈是直接在进程的地址空间中保留一块内存,虽然用起来最不方便。但是速度快,也最灵活。
2.5堆和栈中的存储内容
栈:在函数调用时,第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数,在大多数的C编译器中,参数是由右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容由程序员安排。
2.6存取效率的比较
char s1[] = "aaaaaaaaaaaaaaa";
char *s2 = "bbbbbbbbbbbbbbbbb";
aaaaaaaaaaa是在运行时刻赋值的;
而bbbbbbbbbbb是在编译时就确定的;
但是,在以后的存取中,在栈上的数组比指针所指向的字符串(例如堆)快。
一个进程一个堆?
至少一个用户栈一个内核栈。
静态存储方式:是指在程序运行期间分配固定的存储空间的方式。
动态存储方式:是在程序运行期间根据需要进行动态的分配存储空间的方式。
动态链接库和静态链接库
静态连接库就是把(lib)文件中用到的函数代码直接链接进目标程序,程序运行的时候不再需要其它的库文件;动态链接就是把调用的函数所在文件模块(DLL)和调用函数在文件中的位置等信息链接进目标程序,程序运行的时候再从DLL中寻找相应函数代码,因此需要相应DLL文件的支持。
静态链接库与动态链接库都是共享代码的方式,如果采用静态链接库,则无论你愿不愿意,lib 中的指令都全部被直接包含在最终生成的 EXE 文件中了。但是若使用 DLL,该 DLL 不必被包含在最终 EXE 文件中,EXE 文件执行时可以“动态”地引用和卸载这个与 EXE 独立的 DLL 文件。静态链接库和动态链接库的另外一个区别在于静态链接库中不能再包含其他的动态链接库或者静态库,而在动态链接库中还可以再包含其他的动态或静态链接库。
Linux的话就是.lib和.so,链接那一章讲的了。
压缩打包:tar -zcvf /tmp/zhu.gz.tar /etc
解压到指定目录:tar -zxvf zhu.gz.tar -C /home/share/zhu/
死锁的必要条件,怎么处理死锁。
什么是死锁及死锁的必要条件和解决方法【转】-CSDN博客
产生死锁的原因主要是:
(1) 因为系统资源不足。
(2) 进程运行推进的顺序不合适。
(3) 资源分配不当等。
如果系统资源充足,进程的资源请求都能够得到满足,死锁出现的可能性就很低,否则
就会因争夺有限的资源而陷入死锁。其次,进程运行推进顺序与速度不同,也可能产生死锁。
产生死锁的四个必要条件:
(1) 互斥条件:一个资源每次只能被一个进程使用。
(2) 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
(3) 不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
(4) 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
这四个条件是死锁的必要条件,只要系统发生死锁,这些条件必然成立,而只要上述条件之
一不满足,就不会发生死锁。
死锁的解除与预防:
理解了死锁的原因,尤其是产生死锁的四个必要条件,就可以最大可能地避免、预防和
解除死锁。所以,在系统设计、进程调度等方面注意如何不让这四个必要条件成立,如何确
定资源的合理分配算法,避免进程永久占据系统资源。此外,也要防止进程在处于等待状态
的情况下占用资源。因此,对资源的分配要给予合理的规划。
内存管理方式:段存储,页存储,段页存储。
页存储:见《深入理解计算机系统P543页》
虚拟地址:虚拟页号(VPN)+虚拟页偏移量(VPO);
页表:有效位+物理页号或磁盘地址
地址翻译过程是:
首先根据虚拟地址的虚拟页号到页表中找对应页表项(PTE);
如果有效位为1,代表命中,那么得到PTE中的物理页号,根据虚拟地址中的VPO和物理页号来构造出物理地址即可;
如果有效位为0,代表未命中,那么触发缺页故障,调用缺页异常处理程序,选择一个牺牲页,将这个页面拷贝回去,然后对应虚拟页到物理页中,更新页表PTE。
段存储:
按逻辑划分成段。比如Main函数段,
进程的几种状态。
为了对进程从产生到消亡的整个过程进行跟踪和描述,就需要定义各种进程的各种状态并制定相应的状态转换策略,以此来控制进程的运行。
不同的操作系统对进程的状态解释不同,但是最基本的状态都是一样的。包括一下三种:
运行态:进程占用CPU,并在CPU上运行;
就绪态:进程已经具备运行条件,但是CPU还没有分配过来;
阻塞态:进程因等待某件事发生而暂时不能运行;
进程在一生中,都处于上述3中状态之一。
下面是3种状态转换图
当然理论上上述三种状态之间转换分为六种情况;
运行---》就绪:这是有调度引起的,主要是进程占用CPU的时间过长
就绪---》运行:运行的进程的时间片用完,调度就转到就绪队列中选择合适的进程分配CPU
运行---》阻塞:发生了I/O请求或等待某件事的发生
阻塞---》就绪:进程所等待的事件发生,就进入就绪队列
以上4种情况可以相互正常转换,不是还有两种情况吗?
阻塞--》运行:即使给阻塞进程分配CPU,也无法执行,操作系统載进行调度时不会載阻塞队列进行挑选,其调度的选择对象为就绪队列:
就绪--》阻塞:因为就绪态根本就没有执行,何来进入阻塞态?

Gcc 常用参数整理:
gcc -E hello.c -o hello.i //预处理
gcc -S hello.i -o hello.s //编译,将高级语言转化为汇编语言
gcc -c hello.s -o hello.o //汇编,将汇编语言转化为机器语言
gcc hello.o -o a.out //链接
-g 产生调试符号表。gdb使用,此时不能加O2优化。
struct的用法
struct stuff{
char job[20];
int age;
float height;
};
//直接带变量名Huqinwei
struct stuff{
char job[20];
int age;
float height;
}Huqinwei;
struct stuff{
char job[20];
int age;
float height;
};
struct stuff Huqinwei;
struct{
char job[20];
int age;
float height;
}Huqinwei;
struct stuff Huqinwei = {"manager",30,185};
struct stuff faker = Huqinwei;
//或 struct stuff faker2;
// faker2 = faker;
RW/ZI段
一个ARM程序包含3部分:RO,RW和ZI
RO是程序中的指令和常量
RW是程序中的已初始化变量
ZI是程序中的未初始化的变量
由以上3点说明可以理解为:
RO就是readonly,
RW就是read/write,
ZI就是zero
指针数组和数组指针
这两个名字不同当然所代表的意思也就不同。我刚开始看到这就吓到了,主要是中文太博大精深了,整这样的简称太专业了,把人都绕晕了。从英文解释或中文全称看就比较容易理解。
指针数组:array of pointers,即用于存储指针的数组,也就是数组元素都是指针
数组指针:a pointer to an array,即指向数组的指针
还要注意的是他们用法的区别,下面举例说明。
int* a[4] 指针数组
表示:数组a中的元素都为int型指针
元素表示:*a[i] *(a[i])是一样的,因为[]优先级高于*
int (*a)[4] 数组指针
表示:指向数组a的指针
元素表示:(*a)[i]
注意:在实际应用中,对于指针数组,我们经常这样使用:
| 1 2 |
typedef int* pInt; pInt a[4]; |
这跟上面指针数组定义所表达的意思是一样的,只不过采取了类型变换。
代码演示如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
#include using namespace std; int main() { int c[4]={1,2,3,4}; int *a[4]; //指针数组 int (*b)[4]; //数组指针 b=&c; //将数组c中元素赋给数组a for(int i=0;i<4;i++) { a[i]=&c[i]; } //输出看下结果 cout<<*a[1]< cout<<(*b)[2]< return 0; } |
注意:定义了数组指针,该指针指向这个数组的首地址,必须给指针指定一个地址,容易犯的错得就是,不给b地址,直接用(*b)[i]=c[i]给数组b中元素赋值,这时数组指针不知道指向哪里,调试时可能没错,但运行时肯定出现问题,使用指针时要注意这个问题。但为什么a就不用给他地址呢,a的元素是指针,实际上for循环内已经给数组a中元素指定地址了。但若在for循环内写*a[i]=c[i],这同样会出问题。总之一句话,定义了指针一定要知道指针指向哪里,不然要悲剧。
类似的还有指针函数和函数指针,遇到了再说吧。
数组指针(也称行指针)
定义 int (*p)[n];
()优先级高,首先说明p是一个指针,指向一个整型的一维数组,这个一维数组的长度是n,也可以说是p的步长。也就是说执行p+1时,p要跨过n个整型数据的长度。
如要将二维数组赋给一指针,应这样赋值:
int a[3][4];
int (*p)[4]; //该语句是定义一个数组指针,指向含4个元素的一维数组。
p=a; //将该二维数组的首地址赋给p,也就是a[0]或&a[0][0]
p++; //该语句执行过后,也就是p=p+1;p跨过行a[0][]指向了行a[1][]
所以数组指针也称指向一维数组的指针,亦称行指针。
指针数组
定义 int *p[n];
[]优先级高,先与p结合成为一个数组,再由int*说明这是一个整型指针数组,它有n个指针类型的数组元素。这里执行p+1时,则p指向下一个数组元素,这样赋值是错误的:p=a;因为p是个不可知的表示,只存在p[0]、p[1]、p[2]...p[n-1],而且它们分别是指针变量可以用来存放变量地址。但可以这样 *p=a; 这里*p表示指针数组第一个元素的值,a的首地址的值。
如要将二维数组赋给一指针数组:
int *p[3];
int a[3][4];
p++; //该语句表示p数组指向下一个数组元素。注:此数组每一个元素都是一个指针
for(i=0;i<3;i++)
p[i]=a[i]
这里int *p[3] 表示一个一维数组内存放着三个指针变量,分别是p[0]、p[1]、p[2]
所以要分别赋值。
这样两者的区别就豁然开朗了,数组指针只是一个指针变量,似乎是C语言里专门用来指向二维数组的,它占有内存中一个指针的存储空间。指针数组是多个指针变量,以数组形式存在内存当中,占有多个指针的存储空间。
还需要说明的一点就是,同时用来指向二维数组时,其引用和用数组名引用都是一样的。
比如要表示数组中i行j列一个元素:
*(p[i]+j)、*(*(p+i)+j)、(*(p+i))[j]、p[i][j]
优先级:()>[]>*
1.指针函数
先看下面的函数声明,注意,此函数有返回值,返回值为int *,即返回值是指针类型的。
[cpp] view plain copy
- int *f(int a, int b);
上面的函数声明又可以写成如下形式:
int* f(int a, int b);
让指针标志 * 与int紧贴在一起,而与函数名f间隔开,这样看起来就明了些了,f是函数名,返回值类型是一个int类型的指针。
2.函数指针
顾名思义,函数指针说的就是一个指针,但这个指针指向的函数,不是普通的基本数据类型或者类对象。
函数指针的定义如下:
[cpp] view plain copy
- int (*f)(int a, int b); // 声明函数指针
通过与1中指针函数的定义对比可以看到,函数指针与指针函数的最大区别是函数指针的函数名是一个指针,即函数名前面有一个指针类型的标志型号“*”。
当然,函数指针的返回值也可以是指针。
上面的函数指针定义为一个指向一个返回值为整型,有两个参数并且两个参数的类型都是整型的函数。
具体代码:
- int max(int a, int b) {
- return a > b ? a : b;
- }
- int min(int a, int b) {
- return a < b ? a : b;
- }
- int (*f)(int, int); // 声明函数指针,指向返回值类型为int,有两个参数类型都是int的函数
- int _tmain(int argc, _TCHAR* argv[])
- {
- f = max; // 函数指针f指向求最大值的函数max
- int c = (*f)(1, 2);
- f = min; // 函数指针f指向求最小值的函数min
- c = (*f)(1, 2);
- return 0;
- }
Memcpy错误
1. 失败情况:copy的区域重叠。
例如如下例子
memcpy(a, b, 10);
如果指针b在a之前且距离小于10,则实际copy结果没有达到预计目标,
这个和memcpy的实现有关。这种情况需要使用memmove。
2. 异常情况
当copy越界时,可能会出现程序异常。
如果是在栈上,那可能更麻烦,因为它出现异常的位置往往不是真的有问题的位置。
memcpy进行内存拷贝时有可能发生内存读写错误,比如length大于要拷贝的空间或大于目的空间,可能发生:
int *p = new[10];
memcpy(dst, p, 20);//20超过10了,由于p是堆内分配的,所以超过的部分不属于进程空间,发生内存读写错误。
而int p[10];memcpy(dst, p, 20);不发生错误,因为定义的变量在栈里,p超过10位仍属于进程空间。
交叉编译
Gcc升级之后需要把目标文件(.o)和库重新编译。
本地编译
本地编译可以理解为,在当前编译平台下,编译出来的程序只能放到当前平台下运行。平时我们常见的软件开发,都是属于本地编译:
比如,我们在 x86 平台上,编写程序并编译成可执行程序。这种方式下,我们使用 x86 平台上的工具,开发针对 x86 平台本身的可执行程序,这个编译过程称为本地编译。
交叉编译
交叉编译可以理解为,在当前编译平台下,编译出来的程序能运行在体系结构不同的另一种目标平台上,但是编译平台本身却不能运行该程序:
比如,我们在 x86 平台上,编写程序并编译成能运行在 ARM 平台的程序,编译得到的程序在 x86 平台上是不能运行的,必须放到 ARM 平台上才能运行。
排序算法
冒泡:O(n2)
void bubble_sort(int a[], int n)
{
int i, j, temp;
for (j = 0; j < n - 1; j++)
for (i = 0; i < n - 1 - j; i++)
{
if(a[i] > a[i + 1])
{
temp = a[i];
a[i] = a[i + 1];
a[i + 1] = temp;
}
}
}
快速排序:O(n*log2n)
void quick_sort(int s[], int l, int r)
{
if (l < r)
{
//Swap(s[l], s[(l + r) / 2]); //将中间的这个数和第一个数交换 参见注1
int i = l, j = r, x = s[l];
while (i < j)
{
while(i < j && s[j] >= x) // 从右向左找第一个小于x的数
j--;
if(i < j)
s[i++] = s[j];
while(i < j && s[i] < x) // 从左向右找第一个大于等于x的数
i++;
if(i < j)
s[j--] = s[i];
}
s[i] = x;
quick_sort(s, l, i - 1); // 递归调用
quick_sort(s, i + 1, r);
}
}
通信链路,并行优化
链路图:

除了CRC,信道交织,加扰;CRC校验,解信道交织,解扰只能两并行,其他都可以至少26并行。我们做了一个两发两收的PUSCH(物理上行共享信道)的C语言实现,两发两收就包括了两个codebook,对应两个天线。每个codebook数据长度75376比特,分为13个码块,一共26个码块,可以做26并行。
编程用到了预线程化技术,
| 信道带宽 |
20MHz |
| 循环前缀类型 |
常规CP |
| 有效子载波数 |
1200 |
| 发送数据长度 |
2x75376比特 |
| 信道编码 |
1/3Turbo编码 |
| 收发天线数 |
2x2 |
| 信道类型 |
高斯信道 |
RTT相关知识

RTT移植
启动代码:一般来说,在移植过程中需要用确认几个异常入口以及变量是否正确:
1. 栈尺寸
如果中断服务例程使用的栈尺寸需要不高,可以使用默认值。Stack_Size EQU 0x00000200
2. PenSV异常
PendSV_Handler在context_rvds.S中实现,完成上下文切换。
3. HardFault_Handler异常
HardFault异常直接保留代码也没关系,只是当系统出现了fault异常时,并不容易
看到。为完善代码起见,在context_rvds.S中有相关Fault信息输出代码,入口名称为Hard-
Fault_Handler异常。
4. 时钟中断
OS时钟在Cortex-M3中使用了统一的中断方式:SysTick_Handler。需要在bsp的drivers
的board.c中调用rt_tick_increase();
栈初始化代码:
栈的初始化代码用于创建线程或初始化线程,“手工”的构造一份线程运行栈,相当于
在线程栈上保留了一份线程从初始位置运行的上下文信息。在Cortex-M3体系结构中,当系
统进入异常时,CPU Core会自动进行R0 – R3以及R12、psr、pc、lr等压栈,所以手工构造
这个初始化栈时,也相应的把这些寄存器初始值放置到正确的位置。
上下文切换代码:
代码清单libcpu\arm\cortex-m3\context_rvds.S: 在RT-Thread中,中断锁是完全由芯片移植来实现的,参见线程间同步与通信章节。以下是Cortex-M3上的开关中断实现,它是使用CPSID指令来实现的。
当要进行切换时(假设从Thread from 切换到Thread to),通过rt_hw_context_switch()
函数触发一个PenSV异常。异常产生时,Cortex M3会把PSR,PC,LR,R0 – R3,R12自动
压入当前线程的栈中,然后切换到PenSV异常处理。到PenSV异常后,Cortex M3工作模式(从Thread模式)切换到Handler模式,由函数rt_hw_pend_sv进行处理。rt_hw_pend_sv函
数会载入切换出线程(Thread from)和切换到线程(Thread to)的栈指针,如果切换出线
程的栈指针是0那么表示这是系统启动时的第一次线程上下文切换,不需要对切换出线程做
压栈动作。如果切换出线程栈指针非零,则把剩余未压栈的R4 – R11寄存器依次压栈;然
后从切换到线程栈中恢复R4 – R11寄存器。当从PendSV异常返回时,PSR,PC,LR,R0 –
R3,R12等寄存器由Cortex M3自动恢复。