【CV论文精读】Pedestrian Detection Based on YOLO Network Model 基于YOLO的行人检测
【CV论文精读】Pedestrian Detection Based on YOLO Network Model
0.论文摘要和作者信息
摘要——经过深度网络后,会有一些行人信息的丢失,会造成梯度的消失,造成行人检测不准确。本文改进了YOLO算法的网络结构,提出了一种新的网络结构YOLO-R。首先,在原有YOLO网络的基础上增加了三个直通层。直通层由路由层和重组层组成。其作用是将浅层行人特征连接到深层行人特征,并链接高分辨率和低分辨率行人特征。路线层的作用是将指定层的行人特征信息传递到当前层,然后使用重组层对特征图进行重组,使当前引入的路线层特征与下一层的特征图相匹配。该算法增加的三个直通层可以很好地将网络的浅行人细粒度特征传递到深层网络,使网络能够更好地学习浅行人特征信息。本文还将原YOLO算法中直通层连接的层数从第16层改为第12层,以增加网络提取浅行人特征信息的能力。改进在INRIA行人数据集上进行了测试。实验结果表明,该方法能有效提高行人的检测精度,同时降低误报率和漏检率,检测速度可达每秒25帧。
索引术语-YOLO网络模型;行人检测;直通层;路由层;重组层。
1.研究背景
行人检测是行人目标信息识别和行人行为分析的基础。行人检测也是后期识别和处理的基础。目前,最经典的行人检测方法是Dalal[1]等人提出的HOG+SVM行人检测,在MIT行人数据集上具有近乎完美的性能。Felzenszwalb等人提出了一种改进的DPM算法[2],DPM算法是一种基于组件的检测方法,对目标的变形具有很强的鲁棒性。多勒等提出了积分通道特征[3]和聚合通道特征[4]来整合梯度直方图、LUV和梯度幅度特征,以获得更好的行人特征性能。随着深度神经网络的发展,深度学习模型也广泛应用于行人检测。深度学习相对于传统的目标检测有很大的优势。传统的方法是人工提取特征,需要相关领域的专家通过多年的积累和经验进行人工设计和处理。深度学习的方法可以通过大量数据学习响应数据中的差异特征,更具代表性。深度学习模型模拟人脑的视觉感知系统。它直接从原始图像中提取特征,并通过这些特征逐层传递,获得图像的高维信息,在计算机视觉领域取得了巨大成功。欧阳[5]等人提出了一种基于分量的检测方法,对目标的变形具有鲁棒性。田[6]等人提出了利用深度学习结合部分模型进行ob用于解决行人检测中的遮挡问题。Anelia[7]等人提出了一种新的实时行人检测方法,利用深度神经网络的准确性和级联分类器的效率进行行人检测,实现高精度。目前优秀的目标检测模型有:R-CNN[8]、SPP-Net[9]、Fast-RCNN[10]、Faster-RCNN[11]、SSD[12]、YOLO[13]和ResNet[14]。
YOLO网络模型在目标的实时检测方面表现出色。因此,YOLO网络模型将用于行人检测,并将改进网络以提高其检测能力。本文的主要改进是在深度网络前面增加了3个直通层,将原有YOLO网络结构中的直通层连接数从第16层改为第12层,形成了新的YOLO-R网络模型。在本实验中,使用INRIA行人检测数据集进行测试。实验表明,改进算法提高了行人检测的准确率,同时降低了漏检率和误检率,检测速度达到25帧/秒。
2.行人检测程序
YOLO网络模型使用目标检测作为空间分离的目标框及其类别置信度的回归问题。单个神经网络可以从整个图像中直接预测目标框和类别的置信度。YOLO网络模型的行人检测过程如图1所示:

1)首先将图像划分为SxS网格。如果行人在网格中,网格负责检测行人。每个网格预测B个检测框和这些检测框的置信度,每个图片的检测帧数为SxSxB.
2)每个检测框有5个预测值(X,Y,W,H,Conf)。其中X,Y是预测框中心相对于单元边界的偏移量,W和H是预测框宽度与整个图像的比值,Conf表示检测框的置信度。3)每个网格预测行人的条件概率 P r ( c l a s s ∣ o b j e c t ) Pr(class|object) Pr(class∣object),前提是已知网格包含行人。4)在检测时,将条件概率乘以不同检测框置信度的预测值,以获得每个检测框行人类别的置信度得分。这些行人类型还包括行人出现在检测帧中的概率和检查box和行人之间的目标。置信度得分公式如(1)所示:

出现在网格中的行人, I O U P r e d T r u t h IOU_{Pred}^{Truth} IOUPredTruth表示预测框和地面真实框之间的区域重叠率。Pred表示预测框的面积,Truth表示地面真实框的面积。IOU越大,行人检测的准确率越高。每张图片通过网络的最终输出向量是 S x S x B x [ X , Y , W , H , C o n f , C o n f ( c l a s s ) ] SxSxBx[X,Y,W,H,Conf,Conf(class)] SxSxBx[X,Y,W,H,Conf,Conf(class)]。
3.网络结构
在本文中,YOLO v2[14]网络被用作原型。原YOLO v2网络增加了三个直通层,原YOLO v2算法中直通层中连接到路由层的层数从第16层提高到第12层。这构成了新的YOLO-R网络结构,使得改进后的网络能够进一步提高行人检测精度。结构图如表一所示。

在YOLO-R网络中,在第21层之前增加了一个直通层,它由路由层(第19层)和重组层(第20层)组成,将第11层的maxpooling浅层特征与第22层的深层特征相结合。在第25层之前增加了直通层,由路由层(第23层)和重组层(第24层)组成,将第11层的maxpooling浅层特征与第25层的深层特征相结合。在第30层之前增加了直通层,由路由层(第28层)和重组层(第29层)组成,将第11层的maxpooling浅层特征与第30层的深层特征相结合YOLO网络结构在路由层的第31层从原来的第16层到第12层,以便提取更多的浅层特征信息和深层信息n来做融合。
4.网络训练
基于开源神经网络框架Darknet[15]和YOLO-R网络结构作为模型,训练行人探测器。为了加快训练速度和防止过拟合,选择的脉冲常数为0.9,动量衰减系数为0.0005。学习率采用多步策略。为了减少训练时间,卷积网络用Darknet19[15]网络模型训练的网络参数初始化。
4.1 数据集
本文使用的数据集是INRIA数据集,它是最常用的静态行人检测数据集。它提供原始图片和相应的注释文件。训练集有614个阳性样本(包括2416个行人)。测试集有288个阳性样本(包括1126名行人)。图中人体大部分处于站立姿势,高度超过100像素,画面清晰度高。
5.实验结果与分析
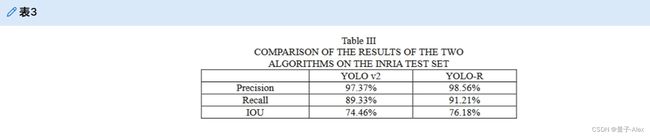
本文在INRIA数据集的测试集上对YOLO v2和YOLO-R网络模型进行了比较。实验结果如表三所示。从表三可以看出,YOLO-R网络模型在精确度、召回率和IOU方面都优于原YOLO v2网络模型。
公式(2)和(3)中的评价指数。

在公式(2)和(3)中,TP、FP和FN分别表示正确识别行人为行人的样本数、将非行人识别为行人的样本数和将行人识别为非行人的样本数。
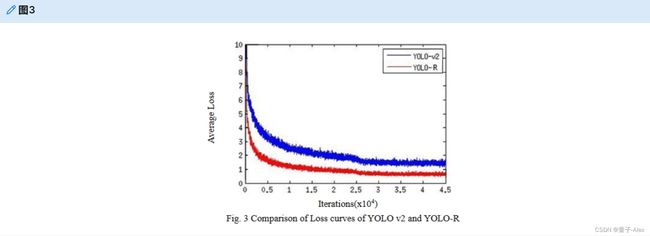
图3示出了训练过程中两种算法的损失曲线的比较。损失函数的公式如(4):
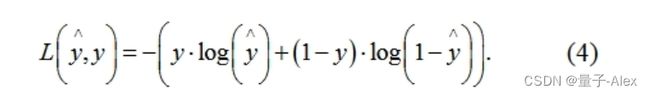
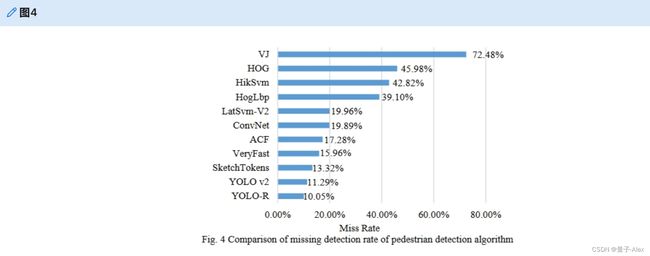
为了验证本文中用于行人检测的新型直通层的性能要求,选择LAMR[16](对数平均错失率)作为评价指标。LAMR反映了每幅图像的假阴性(FPPI)和漏失率之间的关系。FPPI越低,行人检测方法的性能越好。本文选择了INRIA数据集并对其进行了测试。当FPPI=0.1时,YOLO-R网络模型的漏失率比YOLO v2网络模型的11.29%低10.05%。为了进行比较,本文还与一些流行的行人检测算法进行了比较【17–20】。结果如图4所示。
6.总结
本文采用深度学习方法对YOLO v2的网络结构进行了改进,得到了YOLO-R网络模型。在行人检测中取得了良好的效果。本文在YOLO v2网络中增加了三个直通层来提取浅层行人特征,并将原算法从路线层提取的浅层特征从第16层改进到第12层,将浅层特征与深层特征相结合,提取更细粒度的特征。实验表明,该算法提高了行人检测的准确性。检测帧数可达25帧/s,基本满足实时性要求。未来,我们打算集成更多的行人背景特征,以提高行人检测的准确性。

图2部分图像的实验结果。(a)YOLO v2的结果,图片中有行人失踪现象。(b)YOLO-R的结果,在图片中检测到失踪行人。(c)YOLO v2的结果,图片中存在行人阻碍现象。(d)YOLO-R的结果,在图片中检测到受阻行人。(e)YOLO v2的结果,在图片中存在行人错误检测。(f)YOLO-R的结果,在图片中没有行人错误检测。