Python算法概述(2)
四、查找与哈希算法
哈希法则是通过数学函数来获取对应的存放地址的,可以快速地找到所需要的数据。
4.1 常见地查找算法的介绍
4.1.1 顺序查找
- 按顺序进行查找,遍历所有元素。
- 优点是不需要做任何处理
- 缺点是查找速度慢
- 时间复杂度为:O(n)
4.1.2 二分查找
- 又称折半查找
- 将从小到大排列好的元素分成两半,将中间值跟要查找的数字进行比较,若要查找的数字小于中间值,则在中间值的左边继续查找,反之在中间值的右边查找。常用递归函数进行查找,直到查找完成为止。
- 时间复杂度为:O(logn)
4.1.3 插值查找
插值查找(Interpolation Search)又叫插补查找法,是二分查找的改进版。它是按照位置的分布,利用公式预测数据所在的位置,再以二分法的方式逐渐逼近。公式为:
Mid= low + ((key - data[low]) /(data[high] - data[low])) * (high - low)
其中key是要查找的键,data[high],data[low]是剩余查找的最大值和最小值,假设数据项数为n,其插值查找的步骤如下:
① 将记录从小到大的顺序给予1、2、3…n编号
② 令low=1,high=n
③ 当low < high时,重复执行④和⑤步骤
④ Mid= low + ((key - data[low]) /(data[high] - data[low])) * (high - low)
⑤ 若key < keyMid且high != Mid-1,则令high=Mid-1
⑥ 若key = keyMid表示成功查找到键值的位置
⑦ 若key > keyMid且low != Mid +1,则令low=Mid+1
4.2 常见的哈希法简介
哈希法是使用哈希函数来计算一个键值所对应的地址,进而建立哈希表格,然后依靠哈希函数来查找到各个键值存放在表格中的地址,查找速度与数据多少无关,在没有碰撞和溢出的情况下,一次读取即可完成。哈希还具有保密性高的特点,因为不事先知道哈希函数就无法查找到数据,信息技术上有许多哈希法的应用,特别在数据压缩和加解密方面。
选择哈希函数时,不宜过于复杂,设计原则上至少符合计算机速度快和碰撞频率尽量低的两个特点。
常见的哈希算法有除留余数法、取平方法、折叠法及数字分析法。
4.2.1 除留余数法
最简单的哈希函数是将数据除以某一个常数之后,取余数来当索引。
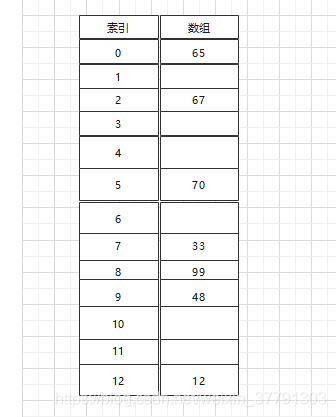
例如,在一个13个位置的数组中,只使用7个地址,值分别是12、65、70、99、33、67、48。我们可以把数组内的值除以13,并以其余数来当作数组的下标(作为索引),以下表示:
H(key) = key mod B
4.2.2 平方取中法
取平方法和除留取余法相当类似,就是先计算数据的平方,之后再取中间的某段数字作为索引。
下例中,用平方取中法,并将数据存放在100个地址空间中,操作步骤如下:
① 将12、65、70、99、33、67、51平方如下:
144、4225、4900、9801、1089、4489、2601
② 再取百位和十位数作为键值,分别为:
14、22、90、80、08、48、60
7个数字存在100个地址空间的索引键值如下:
F(14)=12
F(22)=65
F(90)=70
F(80)=99
F(8)=33
F(48)=67
F(60)=51
若实际空间介于09(10个空间),但取百分数和十位数的值介于099(共一百个空间),则必须将平方取中法第一次所求得的键值再压缩1/10才可以将100个可能产生的值对应到10个空间,即将每一个键值除以10取整(下面采用DIV运算符作为取整数的除法),可以得到下列对应关系:

4.2.3 折叠法
折叠法是将数据转成一串数字后,先将这串数字拆分成几个部分,再把他们加起来就得到这个键值的Bucket Address(桶地址)。
例如有一个数字,转换成数字后为:2365479125443
若以每4个数字为一个部分,则可拆分为2365、4791、2544、3。
将这4组数字加起来之后即为索引值:
移动折叠法:
2365
4691
2544
+ 3
————————
9073 ——>bucket address(桶地址)
哈希法的设计原则之一就是降低碰撞,如果希望降低碰撞的机会,就可将上述每一部分的奇数或偶数反转,再相加来取得其bucket address,这种改进式的做法称为“边界折叠法(folding at the boundaries)”
(1)情况一:将偶数反转
2365 (奇数,不转)
4691 (奇数,不转)
4452 (偶数,反转)
+ 3 奇数,不转)
————————
11611 —> bucket address(桶地址)
(1)情况二:将奇数反转
2365 (奇数,反转)
4691 (奇数,反转)
2544 (偶数,不转)
+ 3 (奇数,反转)
————————
10153 —> bucket address(桶地址)
4.2.4 数字分析法
数字分析法适用于数据不会更改,且为数字类型的静态表。在决定哈希函数时先逐一检查数据的相对位置和分布情况,将重复性高的部分删除。
4.3 碰撞与溢出问题的处理
在哈希法中,当标识符要放在某个桶(Bucket,哈希表中存储数据的位置)时,若桶已经满了,就会发生溢出(Overflow);另一方面哈希的理想情况是所有数据经过哈希函数运算后都得到不同的值,但现实情况是即使所有关键字段的值都不相同,还是可能得到相同的地址,于是就发生了碰撞(Collision)问题。因此,碰撞发生后处理溢出的问题就显得相当重要。常见的算法有以下几种:
4.3.1 线性探测法
线性探测是当发生碰撞的情况时,若该索引对应的存储位置已有数据,则以线性的方法往后寻找空的存储位置,一旦找到位置就把数据放进去。线性探测法通常把哈希的位置视为环形结构,如此一来若后面的位置已被填满而前面还有位置时,可以将数据存放在前面。
4.3.2 平方探测法
平方探测法中,当溢出发生时,下一次查找的地址是(f(x)+i^2)mod B 与 f(f(x)-i^2) mod B,即让数据值加或减i的平方,例如数据值key,哈希函数f:
第一次查找: f(key)
第二次查找:f((key)+1^2)%B
第三次查找:f((key)-1^2)%B
第四次查找:f((key)+2^2)%B
第五次查找:f((key)-2^2)%B
......
......
......
第n次查找:(f(key)+((B-1)/2)^2)%B,其中,B必须为4j+3型的质数,且1<=i<=(B-1)/2
4.3.3 再哈希法
再哈希就是一开始就先设置一系列的哈希函数,如果使用第一种哈希函数出现溢出时就改用第二种,如果第二种也出现溢出则改用第三种,一直到没有发生溢出为止。
例如,h1为key%11,h2为keykey,h3为keykey%11,h4…。接着请使用再哈希处理下列数据碰撞的问题:
681,467,633,511,100,164,472,438,445,366,118:
其中哈希函数为(此处的 m=13)
F1=h(key)=key MOD m
F2=h(key)=(key+2) MOD m
F3=h(key)=(key+4) MOD m
说明如下:
(1) 使用第一种哈希函数h(key)=key MOD 13,所得的哈希地址如下:
618 -> 5
467 -> 12
633 -> 9
511 -> 4
100 -> 9
164 -> 8
472 -> 4
438 -> 9
445 -> 3
366 -> 2
118 -> 1
(2) 其中100,472,438都发生碰撞,再使用第二种哈希函数h(value+2)=(value+2) MOD 13,进行数据的地址安排:
100 ->h(100+2)=102 mod 13 =11
472 ->h(472+2)=474 mod 13=6
438 ->h(438+2)=440 mod 13=11
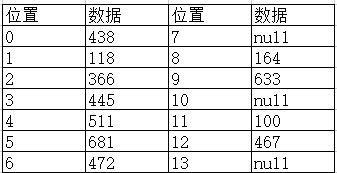
(3) 438仍发生碰撞问题,故接着使用第三种哈希函数h(value+4)=(438+4) MOD 13,重新进行438地址的安排:
438 ->h(438+4)=442 mod 13=11
经过三次再哈希后,数据的地址安排如下:
五、数组与链表算法
1、静态数据结构(stattic data struct)
数组类型是典型的静态数据结构,它使用连续分配的内存空间,来存储有序表中的数据。静态数据结构是在编译时就给相关额变量分配好的内存空间,由于建立静态数据结构的初期必须事先声明最大可能要占用的固定内存空间,因此容易造成内存浪费。
例如,数据类型就是一种典型的静态数据结构。优点是设计时相当简单,而且读取与修改表中任意一个元素的时间是固定的。缺点是删除或加入数据时,需要移动大量的数据。
2、动态数据结构(dynamic data struct)
动态数据结构又称为“链表”,它使用不连续的内存空间存储具有线性表特性的数据。优点是数据的插入或删除都相当方便,不需移动大量的数据。内存分配是在程序执行时才进行的,所以不需事先声明,这能充分节省内存。优点是在设计数据结构时较麻烦,查找数据时需要按顺序查找,不像数组那样可随机读取。
5.1矩阵
数学角度看,对于m × n矩阵(matrix)的形式,可用计算机中A(m,n)的二位数组来描述。
大部分矩阵的运算和应用都可以使用计算机中的二维数组解决。
朋友们可以去温习下线性代数
5.1.1 矩阵相加算法
5.1.2 矩阵相乘算法
5.1.3 转置矩阵
5.2 建立单向链表
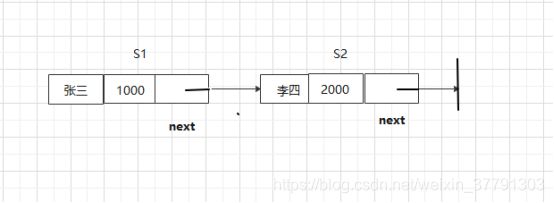
若以动态分配产生链表节点的节点,可先定义一个类,接着在该类中定义一个指针字段,作用是指向下一个链表节点,该类中至少要有一个数据字段。
例如,声明一个公司员工成绩链表节点的结构声明,包含姓名(name),工资(salary)两个数据字段与一个指针字段(next)。
可以声明如下:
class employee:
def __init__(self):
self.name=''
self.salary=0
self.next=None
完成声明后,可动态建立链表中的每个节点。假设现要新增一个节点至链表的末尾,且ptr指向链表的每一个节点,在程序上必须设计4个步骤:
①动态分配内存空间给新节点使用;
②将原链表尾部的指针(next)指向新元素所在的内存为止;
③将ptr指针指向新节点的内存位置,表示这是新的链表尾部;
④由于新节点当前为链表的最后一个元素,因此将它的指针(next)指向none。
5.2.1单向链表的连接功能
对于两个或两个以上的链表的连接(concatention,也称级联),实现方法是将一个链表的尾部连接另外一个链表的头部,以此类推,多个链表也是这样操作,直到连接完为止。
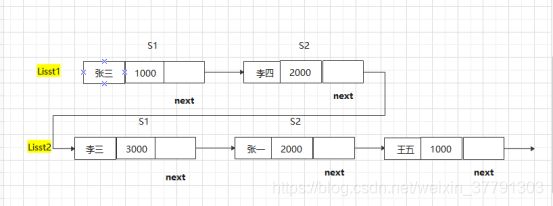
5.2.2单向链表的节点删除
链表可比作是火车,删除链表中的节点,就像解除火车的其中一个车厢。
其实,编程的很多思想和原理都可在生活中找到参照东西。
删除链表节点的位置主要有以下三种情况:
(1)删除链表的第一个节点(即是删除头节点)
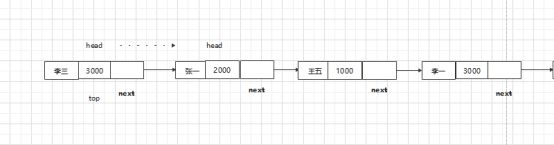
算法:
top=head
Head=head.next
(2)删除中间的节点

算法:
Y=ptr.next
ptr.next=Y.next
(3)删除链表的最后一个节点(链表尾部)
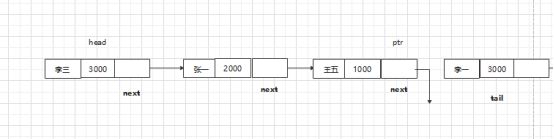
算法:
ptr.next=tail
Ptr.next=None
有兴趣的朋友自己去丰富一下
5.2.3单向链表的反转
六、堆栈与队列算法
堆栈在python中有两种:数组结构和链表结构
6.1用数组实现堆栈
以数组结构实现堆栈的好处是设计的算法相当简单,但如果堆栈本身的大小是变动的,而数组大小只能事先规划和声明好,那么数组规划太大会浪费空间,规划太小了则不够用。
6.2用链表实现堆栈
用链表来实现堆栈的优点是随时可以动态改变链表长度,能有效利用内存资源,不过缺点是设计的算法较为复杂。
6.3 汉诺塔问题的求解算法
法国数学家Lucas在1883年介绍了一个十分经典的汉诺塔(Tower of Hanoi)智力游戏,就是使用递归法与堆栈概念来解决问题的典型范例。
以下内容,有兴趣的朋友自己去丰富一下