SQL拆分字段内容(含分隔符)
问题描述:
在做数据迁移的过程中,我们希望对表中的某个字段根据分隔符进行拆分,得到多条数据,原代码有点意思,因此记录一下。
我们假设某条数据如下:
| ID | STR |
|---|---|
| S1 | 公司名称不能小于四个字,行业类别不能为空,职务/岗位不能为空,公司电话不能小于8位且真是有效 |
针对这条数据,我们希望将其拆分成为四份或者五份,以便于后续的数据处理(这里是拆成四份,加上原来的那条数据一共是五条)。
希望得到的结果:
STEP1:
| ID | STR |
|---|---|
| S1 | 公司名称不能小于四个字,行业类别不能为空,职务/岗位不能为空,公司电话不能小于8位且真是有效 |
| S1 | 公司名称不能小于四个字,行业类别不能为空,职务/岗位不能为空,公司电话不能小于8位且真是有效 |
| S1 | 公司名称不能小于四个字,行业类别不能为空,职务/岗位不能为空,公司电话不能小于8位且真是有效 |
| S1 | 公司名称不能小于四个字,行业类别不能为空,职务/岗位不能为空,公司电话不能小于8位且真是有效 |
| S1 | 公司名称不能小于四个字,行业类别不能为空,职务/岗位不能为空,公司电话不能小于8位且真是有效 |
原作者最后希望得到如下的数据:
STEP2:
| ID | STR |
|---|---|
| S1 | 公司名称不能小于四个字, |
| S1 | 行业类别不能为空, |
| S1 | 职务/岗位不能为空, |
| S1 | 公司电话不能小于8位且真是有效 |
DB2原代码
针对STEP1:
原来的代码:
WITH N (STR,ORI,POS,ID) AS
(
(SELECT CONCAT(STR,','),
1,
POSSER(CONCAT(STR,','),','),
ID
FROM TABLE_NAME
WHERE ID = 'S1')
UNION ALL
SELECT
STR,
POS+1,
LOCATE(',',STR,POS+1),
STR
FROM N
WHERE LOCATE(',',STR,POS+1)+1>0)
SELECT * FROM N
结果如下:
| STR | ORI | POS | ID |
|---|---|---|---|
| 公司名称不能小于四个字,行业类别不能为空,职务/岗位不能为空,公司电话不能小于8位且真是有效 | 1 | 22 | S1 |
| 公司名称不能小于四个字,行业类别不能为空,职务/岗位不能为空,公司电话不能小于8位且真是有效 | 23 | 39 | S1 |
| 公司名称不能小于四个字,行业类别不能为空,职务/岗位不能为空,公司电话不能小于8位且真是有效 | 40 | 57 | S1 |
| 公司名称不能小于四个字,行业类别不能为空,职务/岗位不能为空,公司电话不能小于8位且真是有效 | 58 | 89 | S1 |
| 公司名称不能小于四个字,行业类别不能为空,职务/岗位不能为空,公司电话不能小于8位且真是有效 | 90 | 90 | S1 |
关于代码中涉及到的函数说明
CONCAT()
拼接函数
组合两部分形成一个字符串表达。
(看官方文档,只包括两个参数)
CONCAT官方说明

POSSER()
函数返回查找字符串在被查找字符串中第一次出现的位置。

POSSTR官方文档
官网示例:
Example: Select the RECEIVED column, the SUBJECT column, and the starting position of the string ‘GOOD BEER’ within the NOTE_TEXT column for all rows in the IN_TRAY table that contain that string.
结果返回RECEIVED列, SUBJECT列,以及字符串 ‘GOOD BEER’ 在 NOTE_TEXT列中第一次出现的位置。
SELECT RECEIVED, SUBJECT, POSSTR(NOTE_TEXT, 'GOOD BEER')
FROM IN_TRAY
WHERE POSSTR(NOTE_TEXT, 'GOOD BEER') <> 0;
LOCATE()

LOCATE()函数与POSSER()类似,参数数量不同
LOCATE()函数返回查找字符串在被查找字符串中第一次出现的位置,与POSSER()不同的是,它可以指定开始的位置以及编码计算的方式(CODEUNITS16, CODEUNITS32, or OCTETS)。
官方示例:
Locate the character ‘ß’ in the string ‘Jürgen lives on Hegelstraße’, and set the host variable LOCATION with the position, as measured in CODEUNITS32 units, within the string.
返回字符 'ß’在字符串’Jürgen lives on Hegelstraße’中的位置,从第一位之后开始计算
SET :LOCATION = LOCATE('ß','Jürgen lives on Hegelstraße',1,CODEUNITS32);
GBASE实现
上例改写
参考文章:
MySql字符串拆分实现split功能(字段分割转列、转行)
GBASE中 WITH AS 函数相较于DB2会有限制,因此不推荐使用(需要指定模式名称)
对于这个问题,我们要明确:
1、循环多少次
2、如何控制循环的次数
循环次数求取:
对于该字符串:
公司名称不能小于四个字,行业类别不能为空,职务/岗位不能为空,公司电话不能小于8位且真是有效
我们需要将其分为四段,每个逗号作为分隔
那么循环次数可以这样表示:
LENGTH(STR) - LENGTH(REPLACE(STR,',',''))
将逗号替换为空格,用含逗号的字符串的长度减去不含逗号的字符串长度,得到的就是逗号的数量,也就是循环的次数
对于如何控制循环,我们需要引入一个序列数,上述文章使用了MySQL中的系统表中的ID作为序列,我们可以新建一个表,存入这个自增序列作为辅助,因为希望在一个sql中完成这个操作,因此我这里使用row_number()over()函数自己创建一个序列
那么完整地代码如下所示:
SELECT H1.ID ,
SUBSTRING_INDEX(SUBSTRING_INDEX(H1.STR,',',SEQ),',',-1) AS STR
FROM TABLENAME
INNER JOIN (SELECT ROW_NUMBER()OVER(ORDER BY STR) AS SEQ ,T.*
FROM TABLENAME T
ORDER BY SQE) H2
ON H2.SEQ<= LENGTH(H1.STR) - LENGTH(REPLACE(H1.STR,',',''))
这里我们得到的是上述STEP2的结果:(而且没有冗余的字段)
| ID | STR |
|---|---|
| S1 | 公司名称不能小于四个字, |
| S1 | 行业类别不能为空, |
| S1 | 职务/岗位不能为空, |
| S1 | 公司电话不能小于8位且真是有效 |
另外一个例子
INSU表中存了保险代码以及付费期间两个字段,但是一个产品有多个付费期间,用符号’|'分隔,我们希望将付费期间字段拆开。
如表:
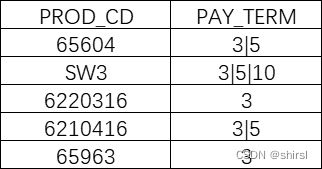
希望得到的结果:
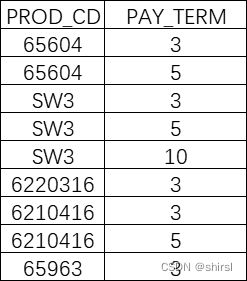
代码:
SELECT H1.PROD_CD,
SUBSTRING_INDEX(SUBSTRING_INDEX(H1.PAY_TERM,'|',ID),'|',-1)
FROM INSU
INNER JOIN
(SELECT ROW_NUMBER()OVER(ORDER BY PAYTERM) AS ID ,T.* FROM INSU T
ORDER BY ID ) H2
ON H1.ID <= LENGTH(H1.PAY_TERM) - LENGTH(REPLACE(H1.PAY_MENT,'|','')) +1
SUBSTRING_INDEX ()函数
SUBSTRING_INDEX function

以分隔符为界,将字符串划分为几个部分,然后返回前几个部分的字符串。
示例:
SUBSTRING_INDEX("www.ibm.com", ".", 2)
returns the leading characters www.ibm because count > 0.
返回值为:www.ibm
如果最后一个参数为负数的话:
示例:
SUBSTRING_INDEX("www.ibm.com", ".", -2)
返回值为:ibm.com (从后往前数)