python多任务【一】- 线程
- 多任务介绍
- python多任务【一】- 线程
- python多任务【二】- 线程:同步|互斥锁|死锁
- python多任务【三】- 进程
python的thread模块是比较底层的模块,python的threading模块是对thread做了一些包装的,可以更加方便的被使用
一、创建线程
1. 使用threading模块
单线程执行
# coding=utf-8
import time
def say_sorry():
print("嗨,你好!我能帮助你吗?")
time.sleep(1)
if __name__ == "__main__":
for i in range(5):
say_sorry()
运行结果:

多线程执行
# coding=utf-8
import threading
import time
def say_sorry():
print("嗨,你好!我能帮助你吗?")
time.sleep(1)
if __name__ == "__main__":
for i in range(5):
t = threading.Thread(target=say_sorry)
t.start() # 启动线程,即让线程开始执行运行结果:

说明
- 可以明显看出使用了多线程并发的操作,花费时间要短很多
- 创建好的线程,需要调用
start()方法来启动
2. 主线程会等待所有的子线程结束后才结束
# coding=utf-8
import threading
from time import sleep, ctime
def sing():
for i in range(3):
print("正在唱歌...%d" % i)
sleep(1)
def dance():
for i in range(3):
print("正在跳舞...%d" % i)
sleep(1)
if __name__ == '__main__':
print('---开始---:%s' % ctime())
t1 = threading.Thread(target=sing)
t2 = threading.Thread(target=dance)
t1.start()
t2.start()
sleep(5) # 屏蔽此行代码,试试看,程序是否会立马结束?
print('---结束---:%s' % ctime())

解释器会一直保持运行,直到所有的线程都终结为止。对于需要长时间运行的线程或者一直不断运行的后台任务,应该考虑将这些线程设置为 daemon(即,守护线程)。
t = Thread(target=countdown, args=(10,), daemon=True) # 或t.setDaemon(True)
t.start()
daemon线程是无法被连接的,但是当主线程完成后它会自动销毁掉。如果想要终止线程,这个线程必须要能够在某个指定的点上轮询退出状态。如果线程会执行阻塞性的操作比如 I/O,那么轮询线程的退出状态时如何实现同步将变得很棘手。对于该问题,需要小心地为线程加上超时循环。
由于全局解释锁(GIL) 的存在,python线程的执行模型被限制为任意时刻只允许在解释器中运行一个线程。基于这个原因,不应该使用python线程来处理IO密集型的任务,因为在这种任务中,我们希望在多个CPU 核心上实现并行处理。python 线程更适合于 I/O 处理以及阻塞操作的并发执行任务,如等待 I/O、等待从数据库中取出结果等。
3. 查看线程数量
# coding=utf-8
import threading
from time import sleep, ctime
def sing():
for i in range(3):
print("正在唱歌...%d" % i)
sleep(1)
def dance():
for i in range(3):
print("正在跳舞...%d" % i)
sleep(1)
if __name__ == '__main__':
print('---开始---:%s' % ctime())
t1 = threading.Thread(target=sing)
t2 = threading.Thread(target=dance)
t1.start()
t2.start()
while True:
length = len(threading.enumerate())
print('当前运行的线程数为:%d' % length)
if length <= 1:
break
sleep(0.5)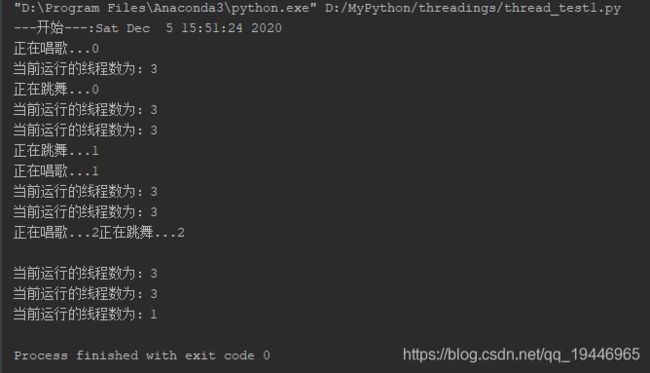
二、线程-注意点
1. 线程执行代码的封装
为了让每个线程的封装性更完美,所以使用threading模块时,往往会定义一个新的子类class,只要继承threading.Thread就可以了,然后重写run方法
示例如下:
# coding=utf-8
import threading
import time
class MyThread(threading.Thread):
def run(self):
for i in range(3):
time.sleep(1)
msg = "I'm " + self.name + '@' + str(i) # name属性中保存的是当前线程的名字
print(msg)
if __name__ == '__main__':
t = MyThread()
t.start()

说明:
- python的threading.Thread类有一个run方法,用于定义线程的功能函数,可以在自己的线程类中覆盖该方法。而创建自己的线程实例后,通过Thread类的start方法,可以启动该线程,交给python虚拟机进行调度,当该线程获得执行的机会时,就会调用run方法执行线程。
2. 线程的执行顺序
# coding=utf-8
import threading
import time
class MyThread(threading.Thread):
def run(self):
for i in range(3):
time.sleep(1)
msg = "I'm " + self.name + '@' + str(i)
print(msg)
def test():
for i in range(5):
t = MyThread()
t.start()
if __name__ == '__main__':
test()执行结果:(运行的结果可能不一样,但是大体是一致的)
I'm MyThread2@0
I'm MyThread1@0
I'm MyThread3@0
I'm MyThread0@0
I'm MyThread4@0
I'm MyThread1@1
I'm MyThread3@1
I'm MyThread2@1
I'm MyThread4@1
I'm MyThread0@1
I'm MyThread4@2
I'm MyThread2@2
I'm MyThread0@2
I'm MyThread3@2
I'm MyThread1@2
说明
从代码和执行结果我们可以看出,多线程程序的执行顺序是不确定的。当执行到sleep语句时,线程将被阻塞(Blocked),到sleep结束后,线程进入就绪(Runnable)状态,等待调度。而线程调度将自行选择一个线程执行。上面的代码中只能保证每个线程都运行完整个run函数,但是线程的启动顺序、run函数中每次循环的执行顺序都不能确定。
总结:
- 每个线程默认有一个名字,如果没有指定线程对象的name,但是python会自动为线程指定一个名字。
- 当线程的run()方法结束时该线程完成。
- 无法控制线程调度程序,但可以通过别的方式来影响线程调度的方式。
三、多线程-共享全局变量
from threading import Thread
import time
g_num = 100
def work1():
global g_num
for i in range(3):
g_num += 1
print("----in work1, g_num is %d---" % g_num)
def work2():
global g_num
print("----in work2, g_num is %d---" % g_num)
print("---线程创建之前 g_num is %d---" % g_num)
t1 = Thread(target=work1)
t1.start()
# 延时一会,保证t1线程中的事情做完
time.sleep(1)
t2 = Thread(target=work2)
t2.start()运行结果:
---线程创建之前g_num is 100---
----in work1, g_num is 103---
----in work2, g_num is 103---
1.列表当做实参传递到线程中
from threading import Thread
import time
def work1(nums):
nums.append(44)
print("----in work1---", nums)
def work2(nums):
# 延时一会,保证t1线程中的事情做完
time.sleep(1)
print("----in work2---", nums)
g_nums = [11, 22, 33]
t1 = Thread(target=work1, args=(g_nums,))
t1.start()
t2 = Thread(target=work2, args=(g_nums,))
t2.start()运行结果:
----in work1--- [11, 22, 33, 44]
----in work2--- [11, 22, 33, 44]
总结:
- 在一个进程内的所有线程共享全局变量,很方便在多个线程间共享数据
- 缺点就是,线程是对全局变量随意遂改可能造成多线程之间对全局变量的混乱(即线程非安全)
2.多线程开发可能遇到的问题
假设两个线程t1和t2都要对全局变量g_num(默认是0)进行加1运算,t1和t2都各对g_num加10次,g_num的最终的结果应该为20。
但是由于是多线程同时操作,有可能出现下面情况:
- 在g_num=0时,t1取得g_num=0。此时系统把t1调度为”sleeping”状态,把t2转换为”running”状态,t2也获得g_num=0
- 然后t2对得到的值进行加1并赋给g_num,使得g_num=1
- 然后系统又把t2调度为”sleeping”,把t1转为”running”。线程t1又把它之前得到的0加1后赋值给g_num。
- 这样导致虽然t1和t2都对g_num加1,但结果仍然是g_num=1
测试1
import threading
import time
g_num = 0
def work1(num):
global g_num
for i in range(num):
g_num += 1
print("----in work1, g_num is %d---" % g_num)
def work2(num):
global g_num
for i in range(num):
g_num += 1
print("----in work2, g_num is %d---" % g_num)
print("---线程创建之前g_num is %d---" % g_num)
t1 = threading.Thread(target=work1, args=(100,))
t1.start()
t2 = threading.Thread(target=work2, args=(100,))
t2.start()
while len(threading.enumerate()) != 1:
time.sleep(1)
print("2个线程对同一个全局变量操作之后的最终结果是:%s" % g_num)运行结果:
---线程创建之前g_num is 0---
----in work1, g_num is 100---
----in work2, g_num is 200---
2个线程对同一个全局变量操作之后的最终结果是:200
测试2
import threading
import time
g_num = 0
def work1(num):
global g_num
for i in range(num):
g_num += 1
print("----in work1, g_num is %d---" % g_num)
def work2(num):
global g_num
for i in range(num):
g_num += 1
print("----in work2, g_num is %d---" % g_num)
print("---线程创建之前g_num is %d---" % g_num)
t1 = threading.Thread(target=work1, args=(1000000,))
t1.start()
t2 = threading.Thread(target=work2, args=(1000000,))
t2.start()
while len(threading.enumerate()) != 1:
time.sleep(1)
print("2个线程对同一个全局变量操作之后的最终结果是:%s" % g_num)运行结果:
---线程创建之前g_num is 0---
----in work1, g_num is 1088005---
----in work2, g_num is 1286202---
2个线程对同一个全局变量操作之后的最终结果是:1286202
结论
- 如果多个线程同时对同一个全局变量操作,会出现资源竞争问题,从而数据结果会不正确
四、创建线程池
concurrent.features 库中包含一个 ThreadPoolExecutor 类可以用来实现创建线程池。如果想手动创建自己的线程池,使用Queue来实现通常是足够简单的。
import time
from concurrent.futures import ThreadPoolExecutor
def work(data):
print(f"work{data}: ", "do something!")
time.sleep(2)
if __name__ == '__main__':
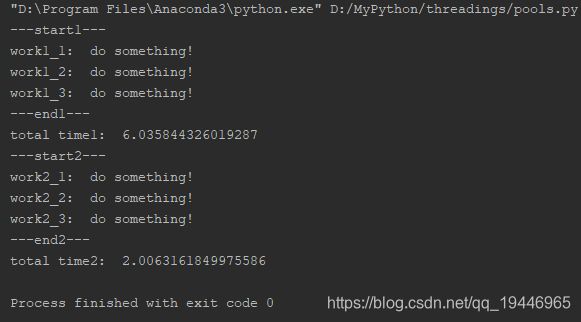
print("---start1---")
inputs = ["1_1", "1_2", "1_3"]
start1 = time.time()
for each in inputs:
work(each)
end1 = time.time()
print("---end1---")
print("total time1: ", end1 - start1)
print("---start2---")
inputs = ["2_1", "2_2", "2_3"]
start2 = time.time()
with ThreadPoolExecutor(10) as executor:
# for each in inputs:
# executor.map(work, each)
executor.map(work, inputs)
end2 = time.time()
print("---end2---")
print("total time2: ", end2 - start2)
结果:
map与submit的区别:
- map可以保证输出的顺序, submit输出的顺序是乱的
- 如果你要提交的任务的函数是一样的,就可以简化成map。但是假如提交的任务函数是不一样的,或者执行的过程之可能出现异常(使用map执行过程中发现问题会直接抛出错误)就要用到submit()
- submit和map的参数是不同的,submit每次都需要提交一个目标函数和对应的参数,map只需要提交一次目标函数,目标函数的参数放在一个迭代器(列表,字典)里就可以。
实现简单的额并行编程
ProcessPoolExecutor类,可以用来在单独的python解释器实例中执行计算密集型函数。例如
import gzip
import io
import glob
from concurrent import futures
def find_robots(filename):
'''
Find all of the hosts that access robots.txt in a single log file
'''
robots = set()
with gzip.open(filename) as f:
for line in io.TextIOWrapper(f,encoding='ascii'):
fields = line.split()
if fields[6] == '/robots.txt':
robots.add(fields[0])
return robots
def find_all_robots(logdir):
'''
Find all hosts across and entire sequence of files
'''
files = glob.glob(logdir+'/*.log.gz')
all_robots = set()
with futures.ProcessPoolExecutor() as pool:
for robots in pool.map(find_robots, files):
all_robots.update(robots)
return all_robots
if __name__ == '__main__':
robots = find_all_robots('logs')
for ipaddr in robots:
print(ipaddr)