【笔记】Python3|爬虫处理网页数据异步加载问题(结合Selenium完成)
文章目录
- 问题描述
- 1. 结合Selenium、Edge解析该网站搜索页面的数据
- 2. 结合lxml解析网页数据
- 3. 附加:不是异步加载的网页,结合requests直接请求数据
问题描述
一些网站会有很多的重定向,才能跳转到真实的资源页。然后爬虫就会报错:requests.exceptions.TooManyRedirects: Exceeded 30 redirects.
这种情况,可以直接关掉重定向,判断响应状态是301或302然后手动重定向。
参考:Python Requests:TooManyRedirects问题解决。
在手动重定向后,我又遇到了异步加载的问题。
爬取得到的页面只有“加载中”,没有实际内容。
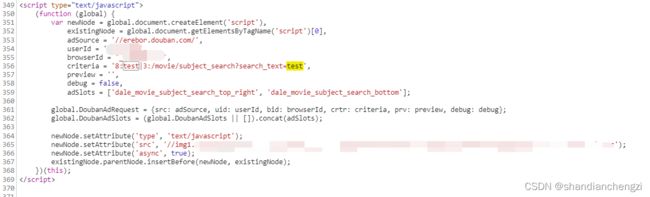
出问题的网页是:常用来爬虫的某网站。
爬取之后得到的就只有这个:

查看网页,可以看到数据是靠浏览器运行JS脚本异步加载的,这时候必须要浏览器渲染,网页的内容才会显示出来。
我查到两种解决方式,一是分析源码,然后想办法自己渲染一下;二是使用requests-html,它提供了render渲染、提供了html异步解析。
requests-html表面上看起来非常不戳啊,好像啥都有了,可是问题是它和requests是同一个作者,requests直到今天还在更新,而requests-html两年没更新了,怎么看都是个天坑吧?
那,要不结合浏览器,咱给它模拟渲染一个吧?
默默捡起了我好久没用的Selenium。
果然,兜兜转转,还是逃不过写模拟吗?
我的版本:
requests 2.27.1
selenium 4.2.0
Edge 102.0.1245.44
1. 结合Selenium、Edge解析该网站搜索页面的数据
如果你从前完全没使用过、没安装过Selenium,可以参考这篇博客《【记录】Python3|selenium4 极速上手入门(Windows)》快速安装Edge版本的webdriver,再继续看下文。
一个超简单的能正常运行的selenium程序如下:
from selenium import webdriver
from selenium.webdriver.edge.service import Service
import requests
from time import sleep
s = Service('./edgedriver_win64/msedgedriver.exe')
edge = webdriver.Edge(service=s)
edge.get("https://movie.douban.com/subject_search?search_text=花束般的恋爱")
# requests库,构造会话
session = requests.Session()
# 获取cookies
cookies = edge.get_cookies()
# 填充
for cookie in cookies:
session.cookies.set(cookie['name'], cookie['value'])
# 给网页留一点加载的时间,不然之后find不了元素
sleep(2)
detail = edge.find_elements(by='xpath', value="//div[@class='detail']")
for i in range(0, len(detail)):
title = detail[i].find_element(by='xpath', value="./div[@class='title']")
rating_nums = detail[i].find_elements(by='xpath', value="./div/span[@class='rating_nums']")
title_a = detail[i].find_element(by='xpath', value="./div[@class='title']/a").get_property('href')
if (len(rating_nums) == 0):
print(i, title.text, '暂无评分', title_a)
else:
print(i, title.text, rating_nums[0].text, title_a)
if (i >= 5): # 最多显示6个结果就行
break
我把常用的xpath相关的、selenium相关的都尽可能在上述代码中写到了。
这对于学习来说,应该是一个很好的例子。
比如get_property是获取元素的属性。
比如xpath中的“目录”层次,./div[@class='title'](其实和电脑的文件系统的目录结构是一样的,多看看就会发现这东西好简单的)。
比如find_elements和find_element的区别。
注意:当页面中没有
find_element能够找到的元素的时候,它就会直接抛出异常“invalid Locator”,而不是返回空。
所以不能确定到底有没有的时候只能用find_elements。
给大家表演一个实际效果~
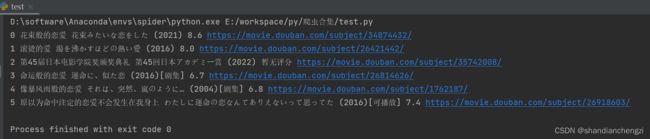
2. 结合lxml解析网页数据
selenium的xpath语法写得没有lxml的简洁,我之前一直用的是lxml解析网页。
selenium得到的网页→网页文本→用lxml做元素分析,(很容易);
网页文本→selenium的类,(很难);
所以我的建议是:干脆一直用lxml库做网页文本的解析,这样更通用些,而且代码量小很多很多。
给大伙看一下selenium和lxml的对比(上面是selenium,下面是lxml):
detail = edge.find_elements(by='xpath', value="//div[@class='detail']")
for i in range(0, len(detail)):
title = detail[i].find_element(by='xpath', value="./div[@class='title']")
rating_nums = detail[i].find_elements(by='xpath', value="./div/span[@class='rating_nums']")
title_a = detail[i].find_element(by='xpath', value="./div[@class='title']/a").get_property('href')
if (len(rating_nums) == 0):
print(i, title.text, '暂无评分', title_a)
else:
print(i, title.text, rating_nums[0].text, title_a)
if (i >= 5): # 最多显示6个结果就行
break
下面是lxml:
from lxml import etree
html=etree.HTML(edge.page_source) # 没错!只要加上一行!就可以丝滑地转换成lxml
detail = html.xpath("//div[@class='detail']")
for i in range(0, len(detail)):
title = detail[i].xpath("./div[@class='title']/a/text()")
rating_nums = detail[i].xpath("./div/span[@class='rating_nums']/text()")
title_a = detail[i].xpath("./div[@class='title']/a/@href")
if (len(rating_nums) == 0):
print(i, title[0], '暂无评分', title_a[0])
else:
print(i, title[0], rating_nums[0], title_a[0])
if (i >= 5): # 最多显示6个结果就行
break
运行结果和上面那个程序是一样的哈:
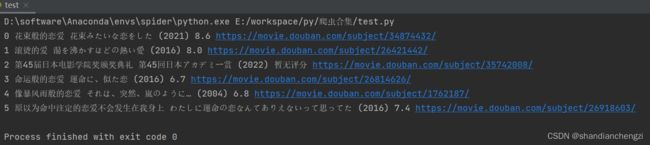
3. 附加:不是异步加载的网页,结合requests直接请求数据
上面那个程序是直接读selenium的网页内容,用的是find_elements之类的。而且每次读都要打开网页、等待加载,这其实挺繁琐的。
对于不是异步加载的网页,只要个url,就可以用requests来请求了。
请求方式有好几种:requests.get、requests.post、session.get等。
常用前两种,但是我后来发现session的bug少一点:网页反复重定向的时候,据说用session会话请求就不会丢失headers的内容。
session只是多一个步骤罢了。例如:
import requests
headers = {}
sessions = requests.session() # 就多这一个步骤
sessions.headers = headers
r = sessions.get(url, headers = headers)
我写了个比较通用的请求数据的函数,返回的是res和lxml解析的html,
有需要的话可以抱走:
from lxml import etree
def getData(url):
while (1):
res = session.get(url, headers=headers)
if (res.status_code == requests.codes.ok):
content = res.text
html = etree.HTML(content)
return res, html
elif (res.status_code == 302 or res.status_code == 301):
print(url + " --重定向到--> " + res.headers["Location"])
url = res.headers["Location"]
else:
print("出问题啦!", res.status_code)
cookieChange = int(input("是否更换Cookie(输入1或0):"))
if (cookieChange):
headers['Cookie'] = input("请输入Cookie:")
sleep(5)
本账号所有文章均为原创,欢迎转载,请注明文章出处:https://blog.csdn.net/qq_46106285/article/details/125416641。百度和各类采集站皆不可信,搜索请谨慎鉴别。技术类文章一般都有时效性,本人习惯不定期对自己的博文进行修正和更新,因此请访问出处以查看本文的最新版本。