MySQL 磁盘95%,删完数据磁盘炸了!聊聊清理数据遇到的问题
在降本增笑的大环境下,运维被砍,开发也要承担一部分 DBA 的任务。
例如,今天这个场景,某台 MySQL 5.7,磁盘 95%,继续解决。
开发想当然的做法是:删掉一些表的数据,肯定能降。
然而,未经指标调研和测试的情况下,大概率会让磁盘继续膨胀,数据没删完,库先炸了。
为什么删完数据磁盘没变化
这是 InnoDB 的 B+ 树,如果删除 R4,InnoDB 引擎只会把 R4 标为删除。如果之后要再插入一个 ID 在 300和 600 之间的记录时,新记录可能会复用这个位置。但磁盘文件不会缩小。
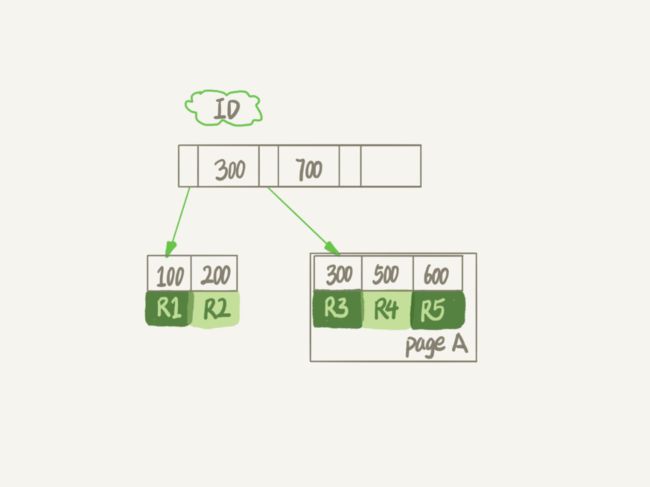
怎么看删完数据的表状态
观察 SHOW TABLE status 的输出。
SHOW TABLE STATUS LIKE 'xxx'\G
*************************** 1. row ***************************
Name: xxx
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 565023
Avg_row_length: 1037
Data_length: 585973760
Max_data_length: 0
Index_length: 158515200
Data_free: 6291456
...
当我们删除大批量数据时,Rows 行数会减少,Data Free (Bytes) 会相应升高。
如果 Data Free 已经在相当高的水平,不仅占空间,还会使得未索引字段查询扫描更多数据,进而查询变慢。
这时,可以考虑执行 OPTIMIZE TABLE 重建表或者 dump 数据到本地 reload 回 MySQL。
没删数据,为什么 Data Free 不等于 0
重建新表,插入大量新数据,你可能会发现,没删数据,怎么 Rows、Data_free 一起涨?
还是 InnoDB 的存储结构问题。
当数据页满了,再插入一条新的数据,引擎需再申请一个新页保存数据。页分裂完成后,原有的页末尾就留下了空洞。

同样地,数据的索引写入也会存在空洞。
不同类别的索引,空洞程度也不一样,自增主键 ID 索引和其他一些业务字段做索引,顺序写入的前者一般会更紧凑。
为什么 OPTIMIZE TABLE 能让磁盘炸了
前面提到 OPTIMIZE TABLE 可以实现重建表的操作,简化的流程是:
- 创建一个临时表
- 复制数据到临时表
- 交换新旧表,DROP 旧表

如果磁盘占用 95%,单表占用超过剩余比例,那么第二步可能就失败了。
再次强调,这里简化了新版本 OnlineDDL 做的锁退化(占耗时大头的复制数据阶段没有 DDL 锁了),但无论新旧版本,都需要扫描旧表,写入临时表,也就是说中间过程磁盘、IO 必然是上升的。
如果没有评估机器状态贸然执行,可能机器没救成,雪崩来得更快。
为什么用 INPLACE 磁盘还是炸了
因为 INPLACE 并不是字面意义上的原地替换
旧的 COPY 很好理解,就是中间建了一张同样数据的新表(为了维持一致,大表可能锁数小时以上)。
为了减少复制数据的锁表时间,才有了新的 OnlineDDL,也就是 INPLACE 算法。
原来的 COPY 是在 server 层创建了一个临时表,而新的是在 InnoDB 的引擎层创建临时文件,对于 server 层而言,看不到临时表,的确是 inplace。
从下方的图可以看到,MySQL 的 OnlineDDL 还多维护了一个 row log 来记录复制阶段的增删改,去掉了复制阶段的锁。
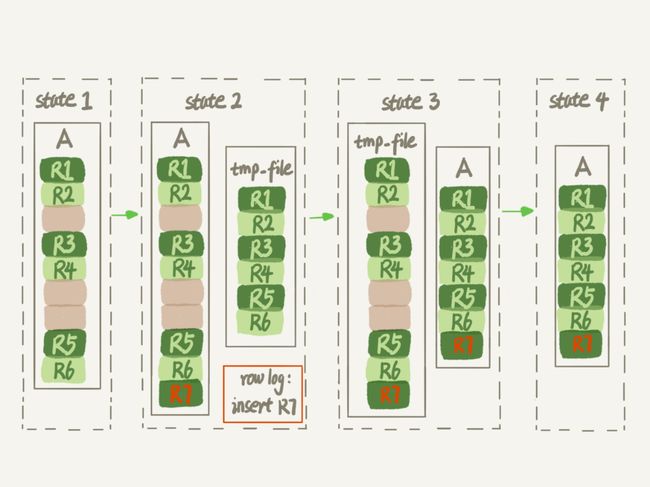
因此,OPTIMIZE TABLE 的 INPLACE 算法仅限于大幅降低锁的时间,减少一部分磁盘 IO,对于磁盘占用而言,两者的差异不大
还能怎么救磁盘满的库
有钞能力当然是扩容,没钱呢?
分析表的业务场景
- 中间表占用转移到本地。对于非面向客户的日志表,可以先 dump 本地,再 TRUNCATE 旧表,重新导入到新表,交换新旧表实现 OPTIMIZE TABLE。
- 舍弃旧数据。对于缓存性质或有明确过期时间的表,写入一部分近期数据到新表,交换新旧表,DROP 旧表。
如果你用的是分区表,旧数据刚好落在特定分区,那么直接 DROP PARTITION 是比 OPTIMIZE TABLE 更合适的操作。
删除不必要的索引
这个没有银弹,只能从查询日志统计
使用压缩的数据格式
创建表列格式为 ROW_FORMAT=COMPRESSED
降低日志占用
redo log 体积调整为适当的大小
除了归档数据外的其他方式,其他方式对于持续增长的表大小是无能为力的。
如果确定数据的生命周期在调整后不会增长到磁盘满,那么做上述改动可能值得,如果答案是否,用数据说服领导扩容吧!
总结
清理数据的思路是:
- 了解机器当前的资源状况。
执行OPTIMIZE TABLE需要二次评估磁盘空间,以及确定业务高低峰时期才可以执行 - 分析表业务场景,决定数据生命周期
- 平衡容灾要求,降低日志大小