MySQL探险-6、调优
文章目录
- 一、性能分析:
-
- MySQL Query Optimizer
- MySQL 常见瓶颈
- MySQL 常见性能分析手段
-
- 性能瓶颈定位
- Explain(执行计划)
-
- 使用方法:
- 慢查询日志
-
- 查看开启状态
- 开启慢查询日志
- 分析工具
- 实际使用情况
- Show Profile 分析查询
- 二、性能优化:
-
- 索引优化
-
- 一般性建议
- 查询优化
-
- 尽量使用 select 具体字段而非 select *
- 合理使用 LIMIT 1
- 尽量避免在 where 子句中使用 or 来连接条件
- 尽量避免在索引列上使用 MySQL 的内置函数
- 尽量避免在 where 子句中对字段进行表达式操作
- 尽量避免隐式类型转换
- INNER JOIN、LEFT JOIN、RIGHT JOIN,优先使用 INNER JOIN(如果是 LEFT JOIN,左边表结果尽量小)
- 永远小标驱动大表(小的数据集驱动大的数据集)
- 参数是子查询时,可以使用 EXISTS 代替 IN
- 减少中间表
-
- 灵活使用 HAVING 子句
- 多个 IN 的汇总
- 分解关联查询
- 优化 LIMIT 分页
-
- 方法一:先查询出主键 id 值
- 方法二:建立复合索引
- 方法三:关延迟联
- ORDER BY 关键字优化
- GROUP BY 关键字优化
- 无需排序时避免排序
-
- 使用集合运算符的 ALL 可选项
- 使用 EXISTS 代表 DISTINCT
- 能写在 WHERE 子句里的条件不要写在 HAVING 子句里
- 使用 SQL 提示(慎用)
-
- USE INDEX
- IGNORE INDEX
- FORCE INDEX
- 数据类型优化
-
- 尽可能使用 varchar/nvarchar 代替 char/nchar
- 总结
- 三、总结:
一、性能分析:
MySQL Query Optimizer
MySQL 中有专门负责优化 SELECT 语句的优化器模块,主要功能为:通过计算分析系统中收集到的统计信息,为客户端请求的 Query 提供它认为最优的执行计划(不一定是最优的,这部分最耗费时间)。
当客户端向 MySQL 请求一条 Query 语句,命令解析器模块完成请求分类,区别出是 SELECT 并转发给 MySQL Query Optimizer 时,MySQL Query Optimizer 首先会对整条 Query 进行优化,处理掉一些常量表达式的预算,直接换算成常量值。并对 Query 中的查询条件进行简化和转换,如去掉一些无用或显而易见的条件、结构调整等。然后分析 Query 中的 Hint 信息(如果有),看显示 Hint 信息是否可以完全确定该 Query 的执行计划。如果没有 Hint 或 Hint 信息还不足以完全确定执行计划,则会读取所涉及对象的统计信息,根据 Query 进行写相应的计算分析,然后再得出最后的执行计划。
整体流程可以参考之前的MySQL探险-3、查询
MySQL 常见瓶颈
●CPU:CPU 饱和一般发生在数据装入内存或从磁盘上读取数据的时候。
●I/O:磁盘 I/O 瓶颈发生在装入数据远大于内存容量的时候。
●服务器硬件的性能瓶颈:可以通过 top、free、iostat 和 vmstat 来查看系统的性能状态。
MySQL 常见性能分析手段
在优化 MySQL 时,通常需要对数据库及查询语句进行分析。常见的分析手段有慢查询日志、EXPLAIN 分析查询、profiling 分析以及 show 命令查询系统状态及系统变量,通过定位分析性能的瓶颈,才能更好的优化数据库系统的性能。
性能瓶颈定位
可以通过 show 命令查看 MySQL 状态及变量,找到系统的瓶颈:
Mysql> show status ——显示状态信息(扩展show status like ‘XXX’)
Mysql> show variables ——显示系统变量(扩展show variables like ‘XXX’)
Mysql> show innodb status ——显示InnoDB存储引擎的状态
Mysql> show processlist ——查看当前SQL执行,包括执行状态、是否锁表等
Shell> mysqladmin variables -u username -p password——显示系统变量
Shell> mysqladmin extended-status -u username -p password——显示状态信息
Explain(执行计划)
使用 Explain 关键字可以模拟优化器执行 SQL 查询语句,从而知道 MySQL 是如何处理该 SQL 语句的。常用于分析查询语句或是表结构的性能瓶颈。
使用方法:
执行 Explain + SQL 语句即可,得到如下结果:
![]()
●id(select 查询的序列号。包含一组数字,表示查询中执行 select 子句或操作表的顺序)
id 相同,执行顺序从上往下。
id 全不同,如果是子查询,id 的序号会递增,id 值越大优先级越高,越先被执行。
id 部分相同,执行顺序是先按照数字大的先执行,然后数字相同的按照从上往下的顺序执行。
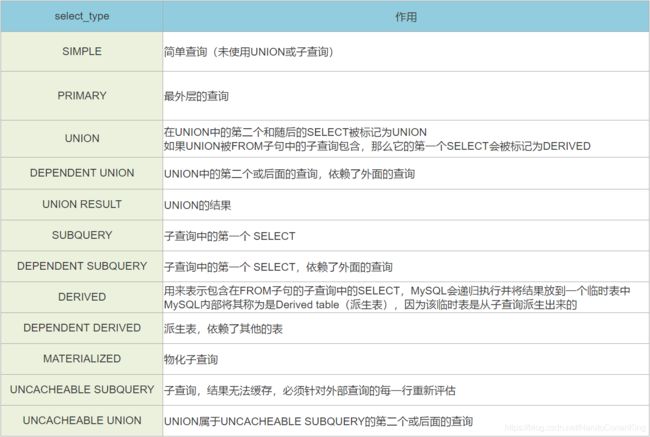
●select_type(查询类型。用于区别普通查询、联合查询、子查询等复杂查询)
●table(显示这一行的数据来源于哪张表)
●partitions(显示这一行的数据来源于哪个分区。对于未分区的表,返回 null)
●type(显示查询使用了那种类型)
从最好到最差依次排列为:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL,一般来说,应当保证查询至少达到 range 级别,最好到达 ref。

●possible_keys(显示可能应用在这张表中的索引,一个或多个,查询涉及到的字段若存在索引,则该索引将被列出,但不一定被查询实际使用)
●key(实际使用的索引)
如果为 NULL,则没有使用索引。
查询中若使用了覆盖索引,则该索引和查询的 select 字段重叠,仅出现在 key 列表中。
●key_len(索引中使用的字节数)
可通过该列计算查询中使用的索引的长度。在不损失精确性的情况下,长度越短越好。
key_len 显示的值为索引字段的最大可能长度,并非实际使用长度,即 key_len 是根据表定义计算而得,不是通过表内检索出的。
●ref(显示索引的哪一列被使用了,如果可能的话,是一个常数)
●rows(根据表统计信息及索引选用情况,大致估算找到所需的记录所需要读取的行数)
●filtered(表示符合查询条件的数据百分比)
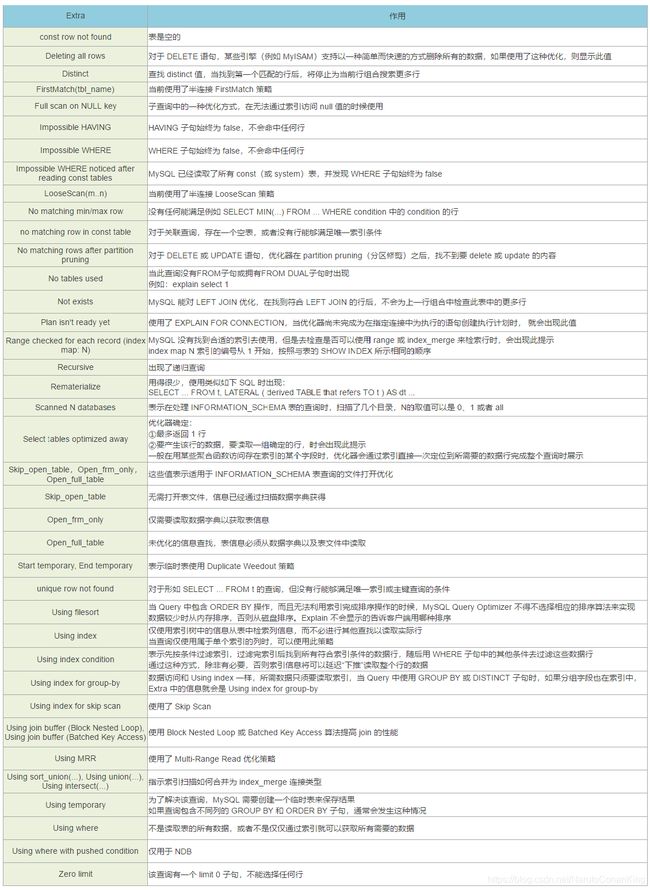
●Extra(包含不适合在其他列中显示但十分重要的额外信息)
慢查询日志
MySQL 的慢查询日志是 MySQL 提供的一种日志记录,它用来记录在 MySQL 中响应时间超过阈值的语句,具体指运行时间超过 long_query_time 值的 SQL,会被记录到慢查询日志中。
●long_query_time 的默认值为 10,意思是运行 10 秒以上的语句。
●默认情况下,MySQL 数据库没有开启慢查询日志,需要手动设置参数开启。
查看开启状态
SHOW VARIABLES LIKE '%slow_query_log%'
开启慢查询日志
●临时配置:
mysql> set global slow_query_log='ON';
mysql> set global slow_query_log_file='/var/lib/mysql/hostname-slow.log';
mysql> set global long_query_time=2;
也可以 set 文件位置,系统会默认给一个缺省文件 host_name-slow.log。
使用 set 操作开启慢查询日志只对当前数据库生效,如果 MySQL 重启则会失效。
●永久配置:
修改配置文件 my.cnf 或 my.ini,在 [mysqld] 一行下面加入两个配置参数:
[mysqld]
slow_query_log = ON
slow_query_log_file = /var/lib/mysql/hostname-slow.log
long_query_time = 3
注意:log-slow-queries 参数为慢查询日志存放的位置,一般这个目录要有 MySQL 的运行帐号的可写权限,一般都将这个目录设置为 MySQL 的数据存放目录。long_query_time=2 表示查询超过两秒才记录。在 my.cnf 或者 my.ini 中添加 log-queries-not-using-indexes 参数,表示记录下没有使用索引的查询。这里可以用 select sleep(4)(模拟慢查询)验证是否成功开启。
分析工具
在生产环境中,如果手工分析日志,查找、分析 SQL,还是比较费劲的,所以MySQL 提供了日志分析工具 mysqldumpslow。
可以通过 mysqldumpslow --help 查看操作帮助信息:
●查询返回记录集最多的 10 个 SQL:
mysqldumpslow -s r -t 10 /var/lib/mysql/hostname-slow.log
●查询访问次数最多的 10 个 SQL:
mysqldumpslow -s c -t 10 /var/lib/mysql/hostname-slow.log
●查询按照时间排序的前 10 条里面含有左连接的查询语句:
mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/hostname-slow.log
●也可以和管道配合使用:
mysqldumpslow -s r -t 10 /var/lib/mysql/hostname-slow.log | more
●也可使用 pt-query-digest 分析 RDS MySQL 慢查询日志。
实际使用情况
如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会或多或少带来一定的性能影响。慢查询日志支持将日志记录写入文件,也支持将日志记录写入数据库表。
Show Profile 分析查询
通过慢日志查询可以知道哪些 SQL 语句执行效率低下;通过 explain 可以得知 SQL 语句的具体执行情况,索引使用等。还可以结合 Show Profile 命令查看执行状态。
Show Profile 是 MySQL 提供可以用来分析当前会话中语句执行的资源消耗情况。可以用于 SQL 的调优的测量。默认情况下,参数处于关闭状态,并保存最近 15 次的运行结果。
使用步骤:
●看当前的 MySQL 版本是否支持:
SHOW VARIABLES LIKE 'profiling';
●开启功能。(默认是关闭,使用前需要开启)
SET profiling = 1;
●运行 SQL。
●查看结果。
分析步骤:
●执行 show profiles; 得到三列数据:Query_ID、Duration、Query。
●执行 converting HEAP to MyISAM,查询结果太大,内存不够用了往磁盘上搬了。
●执行 create tmp table,创建临时表。
●执行 Copying to tmp table on disk,把内存临时表复制到磁盘。
●执行 locked。
●执行 show profile cpu,block io for query id(前面的问题 SQL 数字号码)
二、性能优化:
索引优化
●最好做全值匹配。
●最佳左前缀法则,比如建立了一个联合索引 (a,b,c),那么其实可利用的索引就有 (a), (a,b), (a,b,c)。
●不在索引列上做任何操作(计算、函数、自动或者手动的类型转换),否则会导致索引失效而转向全表扫描。
●存储引擎不能使用索引中范围条件右边的列。
●尽量使用覆盖索引(只访问索引的查询),减少查询次数。
●is null、is not null 无法使用索引。
●LIKE “xxxx%” 是可以用到索引的,LIKE “%xxxx” 则不行(LIKE “%xxx%” 同理)。LIKE 以通配符开头(’%abc…’)索引失效会变成全表扫描的操作。
●字符串不加单引号索引失效。
●少用 or,用它来连接时会导致索引失效。
●<、<=、=、>、>=、BETWEEN、IN 可用到索引;<>、not in、!= 则不行,会导致全表扫描。
●索引不适合建在有大量重复数据的字段上。
●索引不宜太多,一般 5 个以内。若索引太多需要考虑一些索引是否有存在的必要、是否可以优化为联合索引等。
一般性建议
●对于单键索引,尽量选择针对当前 Query 过滤性更好的索引。
●在选择组合索引的时候,当前 Query 中过滤性最好的字段在索引字段顺序中的位置越靠前越好。
●在选择组合索引的时候,尽量选择可以能够包含当前 Query 中的 where 语句中更多字段的索引。
●尽可能通过分析统计信息和调整 Query 的写法来达到选择合适索引的目的。
●少用 Hint 强制索引。
查询优化
尽量使用 select 具体字段而非 select *
只取需要的字段可以节省资源、减少网络开销。
可能需要的查询可以走覆盖索引,如果查询全部数据就会造成回表查询。
合理使用 LIMIT 1
●查询最大/最小的记录。
●查询满足某条件的记录是否存在。
以上场景中使用 limit 1,可以在找到了对应的一条记录后,不再继续向下扫描,效率将会大大提高。
尽量避免在 where 子句中使用 or 来连接条件
使用 or 可能会使索引失效,从而全表扫描。
假设有如下查询:
SELECT * FROM employ WHERE employ_name = '保国' OR age = 18;
可优化如下:
-- 分别查询
SELECT * FROM employ WHERE employ_name = '保国';
SELECT * FROM employ WHERE age = 18;
-- 使用 union all
SELECT * FROM employ WHERE employ_name = '保国'
UNION ALL
SELECT * FROM employ WHERE age = 18;
尽量避免在索引列上使用 MySQL 的内置函数
索引列上使用 MySQL 的内置函数会导致索引失效。
假设有如下查询:(查询最近七天内登陆过的用户,假设 loginTime 加了索引)
SELECT userId, loginTime FROM loginuser WHERE Date_ADD ( loginTime, INTERVAL 7 DAY ) >= now ( );
可优化如下:
SELECT userId, loginTime FROM loginuser WHERE loginTime >= Date_ADD ( NOW ( ), INTERVAL - 7 DAY );
尽量避免在 where 子句中对字段进行表达式操作
对字段进行表达式操作会导致索引失效。
假设有如下查询:
SELECT * FROM employ WHERE age - 1 = 10;
可优化如下:
SELECT * FROM employ WHERE age = 11;
尽量避免隐式类型转换
一些情况下 MySQL 会做隐式的类型转换,导致索引失效。
假设有如下查询:(employ_name 为字符串属性)
SELECT * FROM employ WHERE employ_name = 12;
可优化如下:
SELECT * FROM employ WHERE employ_name = '12';
INNER JOIN、LEFT JOIN、RIGHT JOIN,优先使用 INNER JOIN(如果是 LEFT JOIN,左边表结果尽量小)
INNER JOIN 是内连接,在两张表进行连接查询时,只保留两张表中完全匹配的结果集。
LEFT JOIN 在两张表进行连接查询时,会返回左表所有的行,即使在右表中没有匹配的记录。
RIGHT JOIN 在两张表进行连接查询时,会返回右表所有的行,即使在左表中没有匹配的记录。
永远小标驱动大表(小的数据集驱动大的数据集)
假设有 A 表与 B 表,ID 字段有索引。
当 A 表的数据集小于 B 表的数据集时,用 exists优于用 in。
select * from A where exists (select 1 from B where B.id = A.id)
# 等价于
select * from A
select * from B where B.id = A.id
当 B 表的数据集小于 A 表的数据集时,用 in 优于 exists。
select * from A where id in (select id from B)
# 等价于
select id from B
select * from A where A.id = B.id
参数是子查询时,可以使用 EXISTS 代替 IN
如果 IN 的参数是 (1, 2, 3) 这样的值列表时,没啥问题,但如果参数是子查询时,就需要注意了。
如下查询用 IN 和 EXISTS 返回的结果是一样的,但是用 EXISTS 会更快:
-- 慢
SELECT * FROM Table_A WHERE id IN (SELECT id FROM Table_B);
-- 快
SELECT * FROM Table_A A WHERE EXISTS
(SELECT * FROM Table_B B WHERE A.id = B.id);
这里为什么使用 EXISTS 运行更快呢?
●如果连接列 id 上建立了索引,那么查询 Table_B 时不用查实际的表,只需查索引就可以了。
●如果使用 EXISTS,那么只要查到一行数据满足条件就会终止查询,不用像使用 IN 时一样扫描全表。在这一点上 NOT EXISTS 也一样。
如果 IN 后面如果跟着的是子查询,由于 SQL 会先执行 IN 后面的子查询,会将子查询的结果保存在一张临时的工作表里(内联视图),然后扫描整个视图。显然扫描整个视图这个工作很多时候是非常耗时的,而用 EXISTS 不会生成临时表。
当然了,如果 IN 的参数是子查询时,也可以用关联查询来优化:
-- 使用关联查询代替 IN
SELECT * FROM Table_A A INNER JOIN Table_B B ON A.id = B.id;
减少中间表
在 SQL 中,子查询的结果会产生一张新表,不过如果不加限制大量使用中间表的话,会带来两个问题:一是展示数据需要消耗内存资源,二是原始表中的索引不容易用到。所以尽量减少中间表也可以提升性能。
灵活使用 HAVING 子句
比如有如下查询:
SELECT * FROM (SELECT pay_time, MAX( sale_amount ) AS maxAmount FROM orders GROUP BY pay_time) TMP WHERE maxAmount >= 10;
这样的写法能达到目的,但会生成 TMP 这张临时表。其实也可以优化为下面这样:
SELECT pay_time, MAX( sale_amount ) FROM orders GROUP BY pay_time HAVING MAX( sale_amount ) >= 10;
HAVING 子句和聚合操作是同时执行的,所以比起生成中间表后再执行 HAVING 子句,效率会更高,代码也更简洁。
多个 IN 的汇总
比如有如下查询:
SELECT id, a, b FROM A WHERE a IN (SELECT a FROM B WHERE A.id = B.id)
AND b IN (SELECT b FROM B WHERE A.id = B.id);
这里用到了两个子查询,也就产生了两个中间表。其实也可以优化为下面这样:
SELECT * FROM A WHERE id || a || b IN (SELECT id || a || b FROM B);
这样子查询不用考虑关联性,没有中间表产生,而且只执行一次即可。
分解关联查询
将一个大的查询分解为多个小查询是很有必要的。
很多高性能的应用都会对关联查询进行分解,就是可以对每一个表进行一次单表查询,然后将查询结果在应用程序中进行关联,很多场景下这样会更高效。
优化 LIMIT 分页
在系统中需要分页的操作通常会使用 LIMIT 加上偏移量的方法实现,同时加上合适的 ORDER BY 子句。如果有对应的索引,通常效率会不错,否则 MySQL 需要做大量的文件排序操作。
一个非常令人头疼问题就是当偏移量非常大的时候,例如可能是 limit 10000,20 这样的查询,这是 MySQL 需要查询 10020 条然后只返回最后 20 条,前面的 10000 条记录都将被舍弃,这样的代价很高。
优化此类查询的一个最简单的方法是尽可能的使用索引覆盖扫描,而不是查询所有的列,然后根据需要做一次关联操作再返回所需的列。对于偏移量很大的时候这样做的效率会得到很大提升。
假设有查询语句:
SELECT * FROM activity ORDER BY title LIMIT 90000, 10;
该语句存在的最大问题在于 limit M,N 中偏移量 M 太大(暂不考虑筛选字段上要不要添加索引的影响),导致每次查询都要先从整个表中找到满足条件的前 M 条记录,之后舍弃这 M 条记录并从第 M+1 条记录开始再依次找到 N 条满足条件的记录。如果表非常大,且筛选字段没有合适的索引,且 M 特别大,那么这样做的代价是非常高的。
如果下一次的查询能从前一次查询结束后标记的位置开始查找,找到满足条件的 100 条记录,并记下下一次查询应该开始的位置,以便于下一次查询能直接从该位置开始,这样就不必每次查询都先从整个表中先找到满足条件的前 M 条记录,舍弃,在从 M+1 开始再找到 100 条满足条件的记录了。
方法一:先查询出主键 id 值
可以先查询出第 90000 条数据对应的主键 id 的值,然后直接通过该 id 的值查询该 id 后面的若干数据。SQL 如下:
SELECT * FROM activity WHERE id >= ( SELECT id FROM activity ORDER BY title LIMIT 90000, 1 ) LIMIT 10;
方法二:建立复合索引
SELECT * FROM activity WHERE activity_id = 100 ORDER BY create_time DESC LIMIT 0, 10;
对于如上 SQL 语句,可以建立 activity_id 和 create_time 的复合索引,从而提升效率。
方法三:关延迟联
如果这个表非常大,那么类似查询可以改写成如下的方式:
SELECT * FROM activity INNER JOIN ( SELECT id form FROM activity ORDER BY title LIMIT 90000, 10 ) AS a USING ( id );
这里的“关延迟联”将大大提升查询的效率,它让 MySQL 扫描尽可能少的页面,获取需要的记录后再根据关联列回原表查询需要的所有列。这个技术也可以用在优化关联查询中的 limit。
ORDER BY 关键字优化
MySQL 支持两种方式的排序,FileSort 和 Index,Index 效率高,它指 MySQL 扫描索引本身完成排序,FileSort 效率较低。
因此 ORDER BY 子句,尽量使用 Index 方式排序,避免使用 FileSort 方式排序。
ORDER BY 满足两种情况,会使用 Index 方式排序:
●ORDER BY 语句使用索引最左前列。
●使用 where 子句与 ORDER BY 子句条件列组合满足索引最左前列。
尽可能在索引列上完成排序操作,遵照索引建的最佳最前缀。
如果不在索引列上,filesort 有两种算法,MySQL 就要启动双路排序和单路排序。
●双路排序:MySQL 4.1之前是使用双路排序,字面意思就是两次扫描磁盘,最终得到数据。
●单路排序:从磁盘读取查询需要的所有列,按照 ORDER BY 列在 buffer 对它们进行排序,然后扫描排序后的列表进行输出,效率高于双路排序。
优化策略:
●增大 sort_buffer_size 参数的设置。
●增大 max_lencth_for_sort_data 参数的设置。
注意:如果存在如下情况,可能导致索引失效:
●ORDER BY 中混合 ASC 和 DESC。
●WHERE 后的字段与 ORDER BY 后的字段不同。
GROUP BY 关键字优化
GROUP BY 实质是先排序后进行分组,遵照索引建的最佳左前缀。
当无法使用索引列时,增大 max_length_for_sort_data 参数的设置、增大 sort_buffer_size 参数的设置。
where 高于 having,能写在 where 限定的条件就不要去 having 限定了。
在默认情况下,MySQL 中的 GROUP BY 语句会对其后出现的字段进行默认排序。当我们对查询到的结果无需排序时,可以使用 ORDER BY NULL 禁止排序达到优化目的。
无需排序时避免排序
SQL 是声明式语言,即对用户来说,只关心它能做什么,不用关心它怎么做。这样可能会产生潜在的性能问题:排序。会产生排序的代表性运算如下:
●GROUP BY 子句
●ORDER BY 子句
●聚合函数(SUM、COUNT、AVG、MAX、MIN)
●DISTINCT
●集合运算符(UNION、INTERSECT、EXCEPT)
●窗口函数(RANK、ROW_NUMBER 等)
如果在内存中排序还好,但如果内存不够导致需要在硬盘上排序上的话,性能就会急剧下降。所以需要减少不必要的排序。
使用集合运算符的 ALL 可选项
SQL 中有 UNION、INTERSECT、EXCEPT 三个集合运算符,默认情况下,这些运算符会为了避免重复数据而进行排序。
以 UNION 为例,如果检索结果中不会有重复的记录,推荐使用 UNION ALL 替换 UNION。
假设有如下查询:
SELECT * FROM employ WHERE userid = 1;
UNION
SELECT * FROM employ WHERE age = 10;
可优化如下:
SELECT * FROM employ WHERE userid = 1;
UNION ALL
SELECT * FROM employ WHERE age = 10;
因为如果使用 UNION,不管检索结果有没有重复,都会尝试进行合并,然后在输出最终结果前进行排序。如果已知检索结果没有重复记录,使用 UNION ALL 代替 UNION 可以提高效率。
使用 EXISTS 代表 DISTINCT
为了排除重复数据, DISTINCT 也会对结果进行排序,如果需要对两张表的连接结果进行去重,可以考虑用 EXISTS 代替 DISTINCT,这样可以避免排序。
比如有如下 DISTINCT 语句:
SELECT DISTINCT A.item_no FROM Table_A A INNER JOIN Table_B B ON A.item_no = B.item_no;
可以使用 EXISTS 优化为:
SELECT item_no FROM Table_A A WHERE EXISTS
(SELECT * FROM Table_B B WHERE A.item_no = B.item_no);
既用到了索引,又避免了排序对性能的损耗。
能写在 WHERE 子句里的条件不要写在 HAVING 子句里
直接看一个订单表的例子:
-- 聚合后使用 HAVING 子句过滤
SELECT pay_time, SUM( sale_amount ) FROM orders GROUP BY pay_time HAVING pay_time > '2020-10-01';
-- 聚合前使用 WHERE 子句过滤
SELECT pay_time, SUM( sale_amount ) FROM orders WHERE pay_time = '2020-10-01' GROUP BY pay_time;
使用下面的语句效率更高,原因主要有两点:
●使用 GROUP BY 子句进行聚合时会进行排序,如果事先通过 WHERE 子句能筛选出一部分行,能减轻排序的负担。
●在 WHERE 子句中可以使用索引,而 HAVING 子句是针对聚合后生成的中间视图进行筛选的,但很多时候聚合后生成的视图并没有保留原表的索引结构。
使用 SQL 提示(慎用)
SQL 提示(SQL HINT)是优化数据库的一个重要手段,就是往 SQL 语句中加入一些人为的提示来达到优化目的。
USE INDEX
使用 USE INDEX 是希望 MySQL 去参考索引列表,就可以让 MySQL 不需要考虑其他可用索引,其实也就是 possible_keys 属性下参考的索引值。
IGNORE INDEX
与 USE INDEX 相反,从 possible_keys 中减去不需要的索引,但是实际环境中很少使用。
FORCE INDEX
强制 MySQL 使用指定索引。(执行效率可能不是最高)
数据类型优化
MySQL 支持的数据类型非常多,选择正确的数据类型对于获取高性能至关重要。不管存储哪种类型的数据,遵循一些简单的原则都有助于做出更好的选择:
●更小的通常更好:一般情况下,应该尽量使用可以正确存储数据的最小数据类型。
●简单就好:简单的数据类型通常需要更少的 CPU 周期。例如,整数比字符操作代价更低,因为字符集和校对规则(排序规则)使字符比较比整型比较复杂。
●尽量避免 NULL:通常情况下最好指定列为 NOT NULL。(索引相关)
尽可能使用 varchar/nvarchar 代替 char/nchar
●变长字段存储空间小,可以节省存储空间。
●对于查询来说,在一个相对较小的字段内搜索,效率更高。
总结
●通常来说把可为 NULL 的列改为 NOT NULL 不会对性能提升有多少帮助,只是如果计划在列上创建索引,就应该将该列设置为 NOT NULL。
●对整数类型指定宽度,比如 INT(11),没有任何用。INT 使用 32 位(4 个字节)存储空间,那么它的表示范围已经确定,所以 INT(1) 和 INT(20) 对于存储和计算是相同的。
●UNSIGNED 表示不允许负值,大致可以使正数的上限提高一倍。比如 TINYINT 存储范围是 -128 ~ 127,而 UNSIGNED TINYINT 存储的范围却是 0 ~ 255。
●通常来讲,没有太大的必要使用 DECIMAL 数据类型。即使是在需要存储财务数据时,仍然可以使用 BIGINT。比如需要精确到万分之一,那么可以将数据乘以一百万然后使用 BIGINT 存储。这样可以避免浮点数计算不准确和 DECIMAL 精确计算代价高的问题。
●TIMESTAMP 使用 4 个字节存储空间,DATETIME 使用 8 个字节存储空间。因而,TIMESTAMP 只能表示1970 - 2038年,比 DATETIME 表示的范围小得多,而且 TIMESTAMP 的值因时区不同而不同。
●大多数情况下没有使用枚举类型的必要,其中一个缺点是枚举的字符串列表是固定的,添加和删除字符串(枚举选项)必须使用 ALTER TABLE(如果只是在列表末尾追加元素,不需要重建表)。
●schema 的列不要太多。原因是存储引擎的 API 工作时需要在服务器层和存储引擎层之间通过行缓冲格式拷贝数据,然后在服务器层将缓冲内容解码成各个列,这个转换过程的代价是非常高的。如果列太多而实际使用的列又很少的话,有可能会导致 CPU 占用过高。
●大表 ALTER TABLE 非常耗时,MySQL 执行大部分修改表结果操作的方法是用新的结构创建一个张空表,从旧表中查出所有的数据插入新表,然后再删除旧表。尤其当内存不足而表又很大,而且还有很大索引的情况下,耗时更久。(此处可以有一些其他方法优化解决)
三、总结:
上面主要介绍了一些性能分析的手段和一些优化建议,实际应用中,还是应该以分析为主,不可生搬硬套优化建议,需要根据不同情况具体分析。在大数据量、特殊数据类型等场景下,可能会发现与建议不同的优化方向。其中,锁等待的影响在MySQL探险-4、事务及锁机制中介绍过,因此这里不再说明。
生产过程中可能还有很多 CASE 导致了慢查询,追根溯源,会发现这些都和 MySQL 索引的底层数据 B+ 树有很大的关系,强烈建议仔细研究下 B+ 树这类的底层结构,这样才能理解到问题的根本。在前面的MySQL探险-2、索引部分做过一些简单介绍,希望可以引起大家深入研究的兴趣。