Python实战:使用DrissionPage库爬取高考网大学信息
上一篇文章,我刚入门 DrissionPage 爬虫库,使用这个库爬取了拉钩网关于 Python 的职位信息。
今天再使用 DrissionPage 爬虫库练习一个案例,爬取高考网大学信息。
本次爬取到2885个大学信息,包含大学名称、所在省、市、大学标签信息。
截图如下:

一、页面分析
目标网页是https://www.gaokao.cn/school/search
获取学校名称、所在省市、学婊标签信息。

二、分析思路
使用 DrissionPage 库打开目标网页
使用元素定位方法,定位到包含学校信息的 div
在 div 内继续定位学校名称、所在省市、标签这个信息
将信息存储到列表
翻页,到下一页重复爬取信息
翻完所有页,使用 pandas 将存有所有信息的列表转为 datafram
使用 pandas 将 datafram 保存为 csv 文件或者 excel 文件,或者写入数据库
三、开始写代码
1、打开网页
from DrissionPage import ChromiumPage
page = ChromiumPage()
page.get('https://www.gaokao.cn/school/search')
2、定位信息
# 定位包含学校信息的div
divs = page.eles('tag:div@class=school-search_schoolItem__3q7R2')
# 提取学校信息
for div in divs:
# 提取学校名称
school = div.ele('.school-search_schoolName__1L7pc')
school_name = school.ele('tag:em')
# 提取学校城市
city = div.ele('.school-search_cityName__3LsWN')
if len(city.texts()) == 2:
city_level1 = city.texts()[0]
city_level2 = city.texts()[1]
elif len(city.texts()) == 1:
city_level1 = city.texts()[0]
city_level2 = ""
else:
city_level1 = ""
city_level2 = ""
# 提取学校标签
tags = div.ele('.school-search_tags__ZPsHs')
spans = tags.eles('tag:span')
spans_list = []
for span in spans:
spans_list.append(span.text)
3、存储信息
# contents列表用来存放所有爬取到的大学信息
contents = []
# 信息存到contents列表
contents.append([school_name.text, city_level1, city_level2, spans_list])
# print(school_name.text, city_level1, city_level2, spans_list)
4、翻页
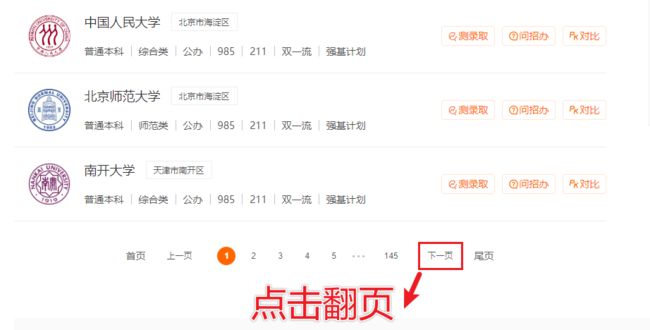
# 定位下一页,点击下一页
try:
next_page = page.ele('. ant-pagination-next')
next_page.click()
except:
pass
5、滑动页面到底部
# 页面滚动到底部,方便查看爬到第几页
time.sleep(2)
page.scroll.to_bottom()
6、反爬措施
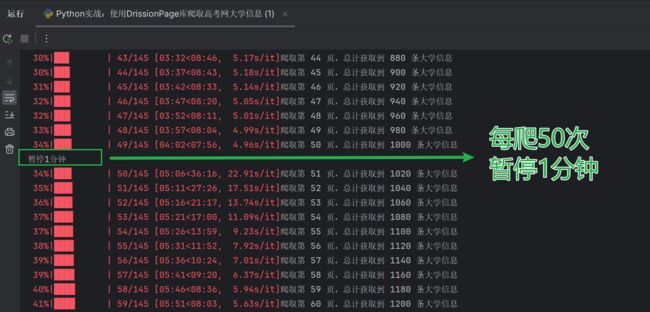
在编写爬虫代码时,要考虑反爬措施。不然就会遇到下面这种情况,服务器直接不给你返回数据了。

我设置的是每爬 1 次都暂停几秒,每爬 50 次暂停 1 分钟。
for i in tqdm(range(1, 146)):
# 每爬50页暂停1分钟
if i % 50 == 0:
get_info()
print("暂停1分钟")
time.sleep(60)
else:
get_info()
7、保存数据到csv文件
import pandas as pd
def save_to_csv(data):
# 保存到csv文件
name = ['school_name', 'city_level1', 'city_level2', 'tags']
df = pd.DataFrame(columns=name, data=data)
df.to_csv(f"高考网大学信息{len(data)}条.csv", index=False)
print("保存完成")
8、使用tqdm库显示进度
from tqdm import tqdm
for i in tqdm(range(1, 146)):
# 每爬50页暂停1分钟
if i % 50 == 0:
get_info()
print("暂停1分钟")
time.sleep(60)
else:
get_info()
四、完整代码
通过定义函数,优化代码,整合成一个完整的代码。完整代码如下:
from DrissionPage import ChromiumPage
import pandas as pd
from tqdm import tqdm
import time
def get_info():
global i
# 页面滚动到底部,方便查看爬到第几页
time.sleep(2)
page.scroll.to_bottom()
# 定位包含学校信息的div
divs = page.eles('tag:div@class=school-search_schoolItem__3q7R2')
# 提取学校信息
for div in divs:
# 提取学校名称
school = div.ele('.school-search_schoolName__1L7pc')
school_name = school.ele('tag:em')
# 提取学校城市
city = div.ele('.school-search_cityName__3LsWN')
if len(city.texts()) == 2:
city_level1 = city.texts()[0]
city_level2 = city.texts()[1]
elif len(city.texts()) == 1:
city_level1 = city.texts()[0]
city_level2 = ""
else:
city_level1 = ""
city_level2 = ""
# 提取学校标签
tags = div.ele('.school-search_tags__ZPsHs')
spans = tags.eles('tag:span')
spans_list = []
for span in spans:
spans_list.append(span.text)
# 信息存到contents列表
contents.append([school_name.text, city_level1, city_level2, spans_list])
# print(school_name.text, city.text, spans_list)
print("爬取第", i, "页,总计获取到", len(contents), "条大学信息")
time.sleep(2)
# 定位下一页,点击下一页
try:
next_page = page.ele('. ant-pagination-next')
next_page.click()
except:
pass
def craw():
global i
for i in tqdm(range(1, 146)):
# 每爬50页暂停1分钟
if i % 50 == 0:
get_info()
print("暂停1分钟")
time.sleep(60)
else:
get_info()
def save_to_csv(data):
# 保存到csv文件
name = ['school_name', 'city_level1', 'city_level2', 'tags']
df = pd.DataFrame(columns=name, data=data)
df.to_csv(f"高考网大学信息{len(data)}条.csv", index=False)
print("保存完成")
if __name__ == '__main__':
# contents列表用来存放所有爬取到的大学信息
contents = []
page = ChromiumPage()
page.get('https://www.gaokao.cn/school/search')
# 声明全局变量i
i = 0
craw()
save_to_csv(contents)
Pycharm 控制台输出如下:

五、数据分析
使用 excel 表自带的数据透视表功能,分析每个省的学校数量。

此外,标签字段含有的信息量也比较丰富,例如其中一个学校的标签是[‘普通本科’, ‘综合类’, ‘公办’, ‘985’, ‘211’, ‘双一流’, ‘强基计划’],也可以对标签字段进行数据分析。本文就不展开了。
六、总结
DrissionPage 库使用起来确实比 Selenium 库方便很多,再也回不去啦。哈哈哈。
本文首发在“程序员coding”公众号,欢迎关注与我一起交流学习。