Hadoop3.3.6(HDFS、YARN、MapReduce)完全分布式集群安装搭建
目录
- 一、节点部署角色目录
- 二、下载软件
- 三、基础设施
-
- 1、安装必要插件
- 2、设置IP及主机名
- 3、时间同步
- 4、jdk安装
- 5、ssh免密登录
- 四、Hadoop部署
-
- 1、目录及环境变量准备
- 2、安装
- 3、修改配置文件
- 4、分发文件
- 5、启动hadoop集群
- 6、集群部署验证
一、节点部署角色目录
| 节点 | ip | NN | SNN | DN | RM | NM | HS |
|---|---|---|---|---|---|---|---|
| node1 | 192.168.88.11 | √ | √ | ||||
| node2 | 192.168.88.12 | √ | √ | √ | √ | ||
| node3 | 192.168.88.13 | √ | √ | ||||
| node4 | 192.168.88.14 | √ | √ |
| HDFS | YARN | MapReduce |
|---|---|---|
| NameNode(NN) | ResourceManager(RM) | HistoryServer(HS) |
| SecondNameNode (SNN) | NodeManager(NM) | |
| DataNode (DN) |
二、下载软件
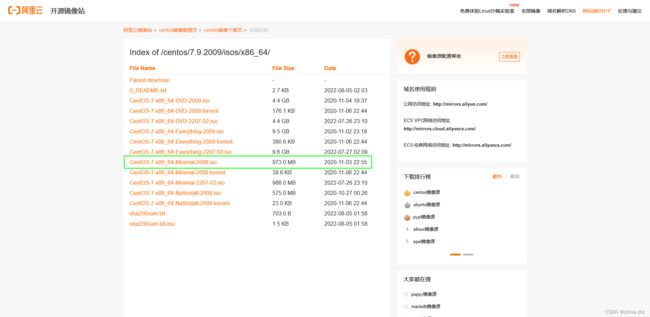
centos-7-minimal(阿里云源)
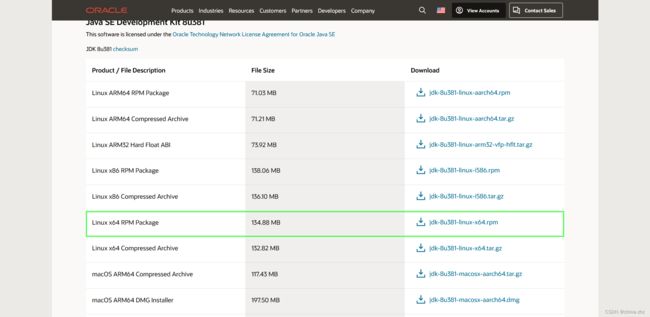
jdk8
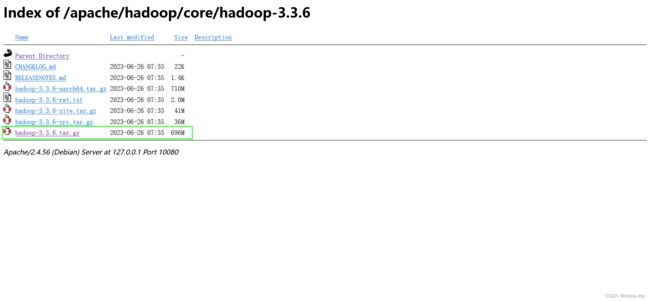
hadoop3.3.6(国内源)
三、基础设施
全部节点执行
1、安装必要插件
安装第三方epel源
yum install -y epel-release
yum install -y net-tools vim
2、设置IP及主机名
配置静态ip
vim /etc/sysconfig/network-scripts/ifcfg-ens33
修改为如下配置(node1主机配置其他主机类推)
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static #这里需要修改为静态
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=12c71633-86c5-4225-8089-f28f2a26e373
DEVICE=ens33
ONBOOT=yes #这里需要修改为yes
# 添加以下配置
IPADDR=192.168.88.11 #自行定义
NETMASK=255.255.255.0
GATEWAY=192.168.88.2 #自行定义
DNS1=223.5.5.5
DNS2=114.114.114.114
其中IPADDR和GATEWAY要修改为自己的网路配置参考:编辑->虚拟网络编辑器->NAT模式的网络->NAT设置 可以点击更改设置改成和我一致的
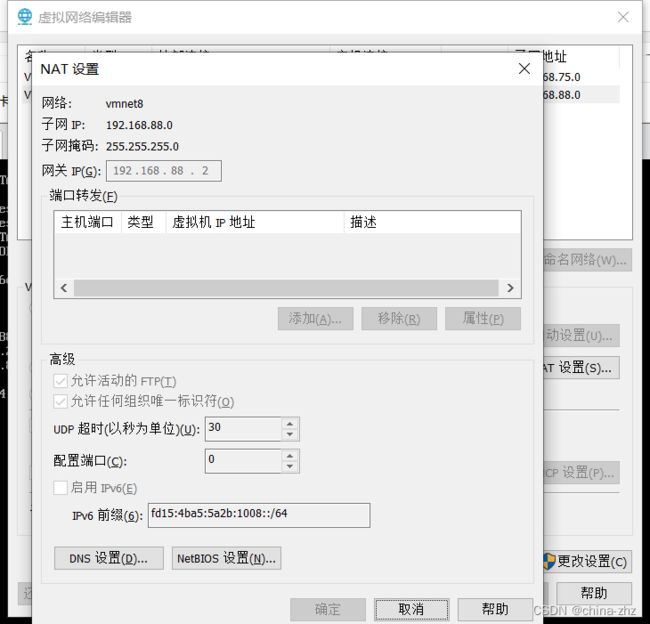
重启网络
systemctl restart network
设置主机名(node1主机执行其他主机类推)
hostnamectl --static set-hostname node1
设置hostname映射
vim /etc/hosts
添加如下映射
192.168.88.11 node1
192.168.88.12 node2
192.168.88.13 node3
192.168.88.14 node4
关闭防火墙
# 关闭防火墙
systemctl stop firewalld
# 禁止开机启动
systemctl disable firewalld
3、时间同步
centos7最小版镜像自带chrony
vim /etc/chrony.conf
修改为阿里和腾讯的ntp服务
server ntp1.aliyun.com iburst prefer
server time1.cloud.tencent.com iburst
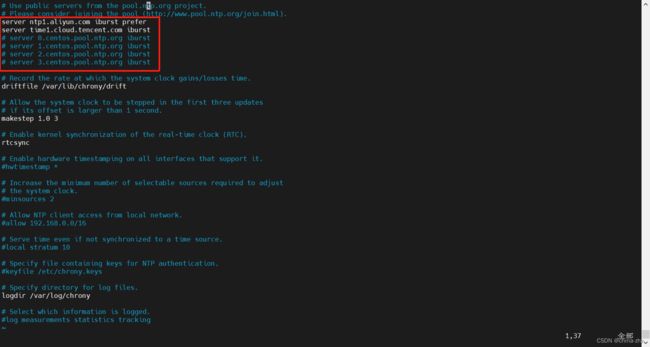
重启chronyd服务
systemctl restart chronyd
# 开机自启动
systemctl enable chronyd
查看状态如下即可
systemctl status chronyd

4、jdk安装
推荐使用rpm方式
上传下载的 jdk-8u381-linux-x64.rpm文件并执行以下命令(会安装在/usr/java目录下)
rpm -i jdk-8u381-linux-x64.rpm
执行完后配置环境变量
vim /etc/profile
在最下方添加
export JAVA_HOME=/usr/java/default
export PATH=$PATH:$JAVA_HOME/bin
重新加载配置
source /etc/profile
5、ssh免密登录
新增hadoop用户
useradd hadoop
passwd hadoop
切换到hadoop用户
su hadoop
先输入密码自己登录下自己生成.ssh目录
ssh localhost
生成秘钥
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
分发密钥(node1执行)
#后面是想要免密登录的节点主机名
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
ssh-copy-id node4
测试node1登录各个节点是否免密例如登录node2
ssh node2
四、Hadoop部署
1、目录及环境变量准备
所有节点执行(root)
新建bigdata目录
mkdir /opt/bigdata
给hadoop用户赋权
chown -R hadoop:hadoop /opt/bigdata
配置环境变量
vim /etc/profile
在最下方添加
export HADOOP_HOME=/opt/bigdata/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
重新加载配置
source /etc/profile
2、安装
node1节点执行(先在node1上安装和配置后面分发到各个节点)
切换到hadoop用户
su hadoop
上传hadoop压缩包并解压到/opt/bigdata目录
tar -zxvf hadoop-3.3.6.tar.gz -C /opt/bigdata
3、修改配置文件
node1节点执行
跳转到hadoop配置文件目录
cd /opt/bigdata/hadoop-3.3.6/etc/hadoop/
- hadoop-env.sh
第54行去掉注释并添加java_home路径
export JAVA_HOME=/usr/java/default
- core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://node1:8020value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/bigdata/hadoop-3.3.6/datavalue>
property>
<property>
<name>hadoop.http.staticuser.username>
<value>hadoopvalue>
property>
configuration>
- hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>node2:9868value>
property>
configuration>
- workers
DataNode节点主机名列表
node2
node3
node4
- mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>node2:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>node2:19888value>
property>
configuration>
- yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>node1value>
property>
<property>
<name>yarn.nodemanager.env-whitelistname>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOMEvalue>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log.server.urlname>
<value>http://node2:19888/jobhistory/logsvalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>
configuration>
4、分发文件
node1节点执行
把/opt/bigdata/的目录及文件分发到node2、3、4节点
scp -r /opt/bigdata/ node2:/opt/
scp -r /opt/bigdata/ node3:/opt/
scp -r /opt/bigdata/ node4:/opt/
5、启动hadoop集群
格式化NameNode
hdfs namenode -format

格式化NameNode会产生新的集群id,导致DataNode中记录的的集群id和刚生成的NameNode的集群id不 一致,DataNode找不到NameNode。所以,格式化NameNode时,一定要先删除每个节点的data目录和logs日志,然后再格式化NameNode,一般只在搭建初期执行这一次。
在node1执行
启动hadoop集群
# 启动集群
start-all.sh
# 停止集群
stop-all.sh
或者HDFS和YARN单独启动
# 启动
start-dfs.sh
start-yarn.sh
# 停止
stop-dfs.sh
stop-yarn.sh
 启动历史服务(node2节点)
启动历史服务(node2节点)
mapred --daemon start historyserver
6、集群部署验证
- 每个节点执行jps命令验证hdfs集群启动的角色是否正确
node1 NN、RM

node2 SNN、DN、NM、HS

node3 DN、NM

node4 DN、NM

- 访问NN的webUI地址 http://192.168.88.11:9870
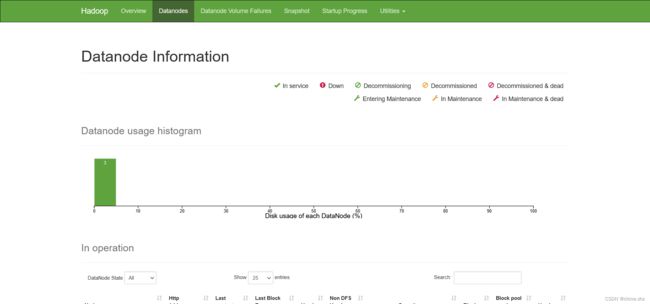
- 访问YARN的webUI 地址:http://192.168.88.11:8088
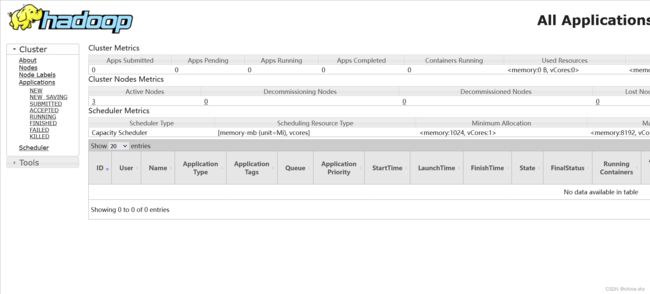
-
访问历史服务http://192.168.88.12:19888

-
测试HDFS上传文件
# 创建hadoop目录
hdfs dfs -mkdir /hadoop
# 上传文件到hadoop目录
hdfs dfs -put ~/hadoop-3.3.6.tar.gz /hadoop
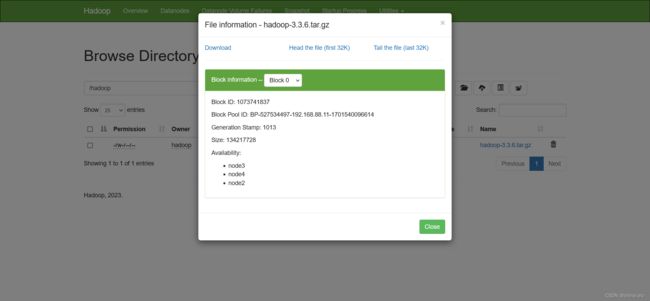
- 测试MR任务
自己编写一个word.txt文档上传到HDFS的/hadoop/input目录下
# 新建input目录
hdfs dfs -mkdir /hadoop/input
# 上传文件
hdfs dfs -put ~/word.txt /hadoop/input
使用Hadoop自带的脚本测试wordcount
hadoop jar /opt/bigdata/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /hadoop/input /hadoop/output
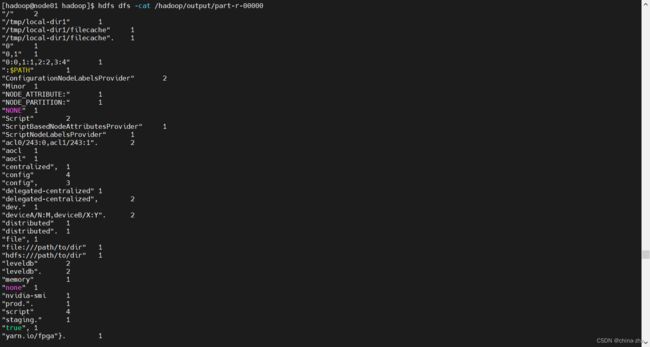
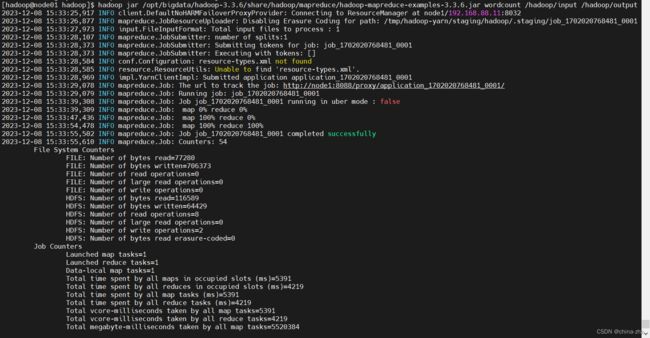 查看计算结果
查看计算结果
hdfs dfs -cat /hadoop/output/part-r-00000