【机器学习】【贝叶斯算法】Python实战演练贝叶斯算法中的关联规则
关联规则概念
-
一个样本称为一个事务
-
每个事务由多个属性来确定,这里的属性称为“项”
-
多个项组成的集合为“项集”
X==>Y:X和Y是项集;X称为规则前项;Y称为规则后项
支持度
支持度(support):一个项集或者规则在所有事务中出现的频率,σ(X):表示项集X的支持度计数
·项集X的支持度:s(X)=σ(X)N
·规侧X==>Y表示物品集X对物品集Y的支持度,也就是物品集X和物品集Y同时出现的概率
·某天共有100个顾客到商场购买物品,其中有30个顾客同时购买了啤酒和尿布,那么上述的关联规则的支持度就是30%
置信度
置信度(confidence):确定Y在包含X的事务中出现的频繁程度。c(X→Y)=σ(XUY)/σ(X)
·p(YX)=p(XY)/p(X).
·置信度反应了关联规则的可信度一购买了项目集X中的商品的顾客同时也购买了Y中商品的可能性有多大
·购买薯片的顾客中有50%的人购买了可乐,则置信度为50%
前项与后项不同则得到的结果也将可能发生变化
强关联规则:当关联规则X->Y的支持度与置信度分别大于或等于用户指定的最小支持度和最小置信度的规则X->Y 否则为弱关联规则
提升度
物品集A的出现对物品集B的出现概率发生了多大的变化
lift(A==>B)=confidence(A==>B)/support(A==>B)=P(B|A)/P(B)
如果提升度为1则X与Y独立,X对Y出现的可能性没有提升作用,其值越大则表明X对Y的提升程度越大,也表明关联性越强。
Python实战演练
通过不同的关联规则可以挖掘项集之间的联系
使用mlxtend工具包得出频繁项集与规则
-
若电脑中有多个Python版本则进入对应版本Python的Scripts文件夹中调用pip install mlxtend来安装工具包
import pandas as pd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules自定义一份数据集
data = {'ID': [1, 2, 3, 4, 5, 6],
'0nion': [1, 0, 0, 1, 1, 1],
'Potato': [1, 1, 0, 1, 1, 1],
'Burger': [1, 1, 0, 0, 1, 1],
'Milk': [0, 1, 1, 1, 0, 1],
'Beer': [0, 0, 1, 0, 1, 0]}
df=pd.DataFrame(data)
df=df[['ID','0nion','Potato','Burger','Milk','Beer']]
df 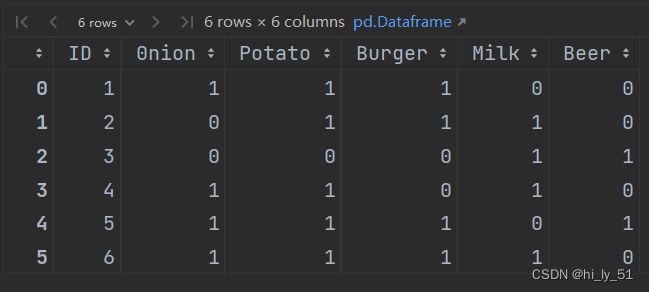
设置支持度来选择频繁项集
frequent_itemsets=apriori(df[['0nion','Potato','Burger','Milk','Beer']],min_support=0.50,use_colnames=True)
####设置最小支持度为50%,将支持度较小的结果过滤掉 并不使用ID列,ID列是自己观察使用的 一般情况下都使用列名
frequent_itemsets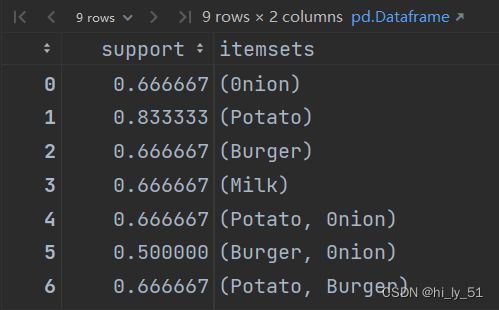
对于分析得到的频繁项集后续可以计算规则
rules=association_rules(frequent_itemsets,metric='lift',min_threshold=1)
##传入频繁项集,指定评估模块进行过滤(lift值最小为1)
rules
支持度与置信度表达在不同层面上的关联,需要具体情况具体分析,需要根据业务来选择
rules[(rules['lift']>1.125)&(rules['confidence']>0.8)]