数据库系统知识点总结与英文课件翻译
数据库系统
lec1 数据库系统概述
1、什么是数据库
P3
- Data 数据:
- facts and statistics collected together for reference or analysis.收集事实和统计数据以供参考或分析。
- Database 数据库:Data + Base
- A very large, structured collection of data.一个非常大的、结构化的数据集合。
- Models some real-world “enterprise”, such as a university。模拟一些真实世界的“规划”,如大学
- Entities 实体:例如学生、课程
- Relationships 联系:例如张三正在上数据库系统课程。
2、什么是数据库管理系统
P3
- Database Management System (DBMS) 数据库管理系统是:
- A software system designed to store, manage, and facilitate query to databases.一种用于存储、管理和方便查询数据库的软件系统。
- Popular DBMS:Oracle、IBM DB2、Microsoft SQL Server
- Database System = Databases + DBMS 数据库系统 = 数据库 + 数据库管理系统
3、Typical Applications Supported by Database Systems 数据库系统支持的典型应用程序
-
Online Transaction Processing (OLTP) 联机事务处理
- Recording sales data in supermarkets
- Booking flight tickets
- Electronic banking
-
Online analytical processing (OLAP) and Data Warehousing 在线分析处理和数据仓库
- Business reporting for sales data
- Customer Relationship Management (CRM)
-
Is the WWW a DBMS?
- The Web = Surface Web + Deep Web
- Surface Web: simply the HTML pages
- Accessed by “search”:
- Pose keywords in search box.
- Accessed by “search”:
- Deep Web: content hidden behind HTML forms
- Accessed by “query”
- Fill in query forms.
4、搜索和查询的区别
Search is structure-free.Query is structure-aware.搜索是无结构的。查询是结构感知的。
- Search is structure-free.
- The keywords “database systems” can appear in anyplace in a HTML pages
- Query is structure-aware.
- Say, we restruct that the keywords “database systems” can only appear in the “TITLE” field.
- i.e., we assume there is an underlying STRUCTURE (of a book).
5、文件和DBMS的区别
- We can store data in OS files.
- E.g., Google has its own distributed file system called Google File System (GFS).
- What are the advantages of DBMS?
- Good data modeling 好的数据建模
- Data Independence 数据独立性
- Data Integrity and Security 数据完整性和安全性
- Simple and efficient ad-hoc queries 简单高效的即时查询
- Reduced application development time 缩短应用程序开发时间
- Concurrency control 并发控制
- Crash recovery 事故恢复
- Good data modeling 好的数据建模
6、历史视角
P5
- Integrated Data Store (IDS)集成数据存储, by Charles Bachman, early 1960s.网络数据模型,1973年图灵奖获得者。
- Information Management System (IMS)信息管理系统, by IBM, late 1960s.Hierarchical data model.分层数据模型
- Relational Data Model关系数据模型, by Edgar Codd, 1970.1981年图灵奖获得者
- System R R系统,关系型数据库系统, by IBM, started in 1974.Structured Query Language (SQL) 结构化查询语言
- INGRES 数据库, by Berkeley, started in 1974.“Interactive Graphic and Retrieval System”交互式图形检索系统。
- Database Transaction Processing数据库事务处理, mainly by Jim Gray.1993年图灵奖获得者
- Object-Relational DBMS对象关系数据库管理系统, 1990s.
- Stonebraker, Michael with Moore, Dorothy. Object-Relational DBMSs: The Next Great Wave. 1996.
- Postgres (UC Berkeley), PostgreSQL.
- IBM’s DB2, Oracle database, and Microsoft SQL Server
- Turing Award, 2014.
- Column store列存储, memory database内存数据库, big data大数据, 2010s.
- C-store, H-Store, SciDB , …
7、从OLTP到OLAP和数据仓库
- OLAP (On-Line Analytical Processing, Codd, 1993)联机分析处理
- Flexible Reporting for Business Intelligence灵活的商业智能报告
- Characteristics of OLAP applications :
- Transactions that involve large numbers of records 涉及大量记录的事务
- Frequent Ad-hoc queries and Infrequent updates 频繁的特定查询和不频繁的更新
- A few decision making users 少数决策用户
- Fast response times 快速响应时间
- Data warehouses are designed to facilitate reporting and analysis. 促进报告和分析
- Read-Mostly DBMS: C-Store, MonetDB
- Data Warehousing 数据仓库
- Integrated data spanning long time periods, often augmented with summary information. 跨长时间段的集成数据,通常附有摘要信息。
- Several gigabytes to terabytes common. 几GB到TB是常见的。
- Interactive response times expected for complex queries: ad-hoc updates uncommon 复杂查询有预期的交互式响应时间:特别更新不常见
8、Data Mining (DM)数据挖掘
- DM是对大量数据的探索和分析,以发现数据中有效、新颖、潜在有用且最终可理解的模式。
- Association Rules关联规则
- 60%购买尿布的顾客也会购买啤酒。
- 分类:垃圾邮件
- 聚类:按相似兴趣对新浪微博用户进行聚类
- 网页排名:谷歌的PageRank
9、Big Data 大数据
- 牛津字典:太大、太复杂,无法使用标准方法或工具进行操作或查询的数据集。
- 数据来自各个地方
- Big data spans four dimensions: 大数据包括四个维度
- Volume, terabytes (TB), even petabytes of information 容量,TB,甚至PB的信息
- Velocity, Sometimes 2 minutes is too late 速度
- Variety, Big data is any type of data - structured and unstructured data 多样性,大数据是任意类型的数据——结构化和非结构化数据
- Veracity 真实性
10、Describing Data: Data Models 描述数据:数据模型
P8
- A data model is a collection of concepts for describing data. 数据模型是用于描述数据的概念集合。
- A schema is a description of a particular collection of data, using a given data model. 模式是使用给定数据模型对特定数据集合的描述。
- The relational data model is the most widely used model today. 关系数据模型是当今应用最广泛的模型。
- Main concept: relation, basically a table with rows and columns. 关系,基本上是一个包含行和列的表。
- Every relation has a schema, which describes the columns, or fields (their names, types, constraints, etc.). 每个关系都有一个模式,它描述列或字段(它们的名称、类型、约束等)。
11、Schema in Relation Data Model 关系数据模型中的模式
P8
A relation schema is a TEMPLATE of the corresponding relation. 关系模式是对应关系的模板。
12、Levels of Abstraction in a DBMS 数据库管理系统中的抽象层次
P9
- Many views describe how users see the data. 许多场景描述用户如何查看数据。
- Personalized access of data. 个性化数据访问。
- Conceptual schema defines logical structure 概念模式定义了逻辑结构
- i.e., what relations to store. 例如,存储什么关系。
- Physical schema specifies physical structure. 物理模式指定物理结构。
- How the “logical” relations are physically stored on external storage such as disk. 如何将“逻辑”关系物理存储在外部存储器(如磁盘)上。
View外模式->Conceptual schema概念模式->Physical schema物理模式->DB磁盘
Example: University Database
- Conceptual schema:
- Students(sid: string, name: string, login: string, age: integer, gpa: real)
- Courses(cid: string, cname: string, credits: integer)
- Enrolled(sid: string, cid: string, grade: string)
- Physical schema:
- Relations stored as unordered files.
- Index on first column of Students.
- External Schema (View):
- Course_info(cid: string, enrollment: integer)
13、Data Independence 数据独立性
P11
- Applications insulated from how data is structured and stored. 应用程序与数据的结构和存储方式无关。
- Logical data independence: Protection from changes in logical structure of data. 逻辑数据独立性:防止数据的逻辑结构发生变化。
- Physical data independence: Protection from changes in physicalstructure of data. 物理数据独立性:防止数据的物理结构发生变化。
- One of the most important benefits of using a DBMS!
14、Queries in a Relational DBMS 关系数据库管理系统中的查询
P11
- Specified in a Non-Procedural way 以非程序方式指定
- Users only specify what data they need; 用户只指定他们需要什么数据;
- A DBMS takes care to evaluate queries as efficiently as possible. DBMS会尽可能高效地评估查询。
- a Non-Procedural Query Language: 非过程查询语言:
- SQL: Structured Query Language 结构化查询语言
15、Concurrent execution of user programs 用户程序的并发执行
P13
Why?
- Utilize CPU while waiting for disk I/O 在等待磁盘I/O时利用CPU
- (database programs make heavy use of disk)
- Avoid short programs waiting behind long ones 避免短程序在等待长程序执行完之后再执行
- e.g. ATM withdrawal while bank manager sums balance across all accounts
Concurrent execution 并行执行
- Interleaving actions of different user programs can lead to inconsistency: 不同用户程序的交叉操作可能导致不一致
Concurrency Control 并发控制
- DBMS ensures such problems don’t arise.
- Users can pretend they are using a single-user system. 用户可以当作使用单用户系统。
16、Key concept: Transaction 关键概念:事务
P12
- An Transaction is an atomic sequence of database actions (reads / writes) 事务是数据库操作(读/写)的原子序列
- Each transaction, executed completely, must leave the DB in a consistent state if DB is consistent when the transaction begins. 如果事务开始时DB是一致的,则完全执行的每个事务都必须使DB保持一致状态。
17、Incomplete Transaction and System Crashes 未完成的事务和系统崩溃
P13
- Incomplete transaction 未完成的事务
- Canceled by the transaction or DBMS 被事务或DBMS取消
- Aborted unexpectedly by system crash 由于系统崩溃而意外中止
- Idea: Keep a log (history) of all actions carried out by the DBMS while executing a set of transactions: 在执行一组事务时,保留DBMS执行的所有操作的日志(历史记录)
- Before a change is made to the database, the corresponding log entry is forced to a safe location. (WAL protocol; OS support for this is often inadequate.) 在对数据库进行更改之前,会将相应的日志条目强制放到安全位置(预写式协议;操作系统对此的支持通常是不够的)
- After a crash, the effects of partially executed transactions are undone using the log. 崩溃后,部分执行的事务的效果将使用日志撤消。
18、数据库管理系统的结构
P14

Databases make these folks happy 数据库让这些人很开心
P15
- End users and DBMS vendors 终端用户和DBMS供应商
- DB application programmers 数据库应用程序程序员
- E.g., smart webmasters 网站管理员
- Database administrator (DBA) 数据库管理员
- Designs logical /physical schemas 设计逻辑/物理模式
- Handles security and authorization 处理安全和授权
- Data availability, crash recovery 数据可用性、崩溃恢复
- Database tuning as needs evolve 根据需要调整数据库
- Must understand how a DBMS works! 必须了解DBMS是如何工作的!
19、Summary 总结
- DBMS used to maintain, query large datasets. DBMS用于维护、查询大型数据集
- Benefits include recovery from system crashes, concurrent access, quick application development, data integrity and security. 好处包括从系统崩溃中恢复、并发访问、快速应用程序开发、数据完整性和安全性。
- Levels of abstraction give data independence. 抽象级别提供了数据独立性。
- A DBMS typically has a layered architecture. DBMS通常具有分层体系结构。
- DBAs hold responsible jobs and are well-paid! DBA拥有负责任的工作,而且薪水很高!
- DBMS R&D is one of the broadest, most exciting areas in CS. DBMS研发是CS中最广泛、最令人兴奋的领域之一。
- We focus on Relational DBMS: 我们主要关注关系型DBMS:
- maintain/query structured data 维护/查询结构化数据
lec2 关系模型 The Relational Model
1、关系模型定义
P43-45
- Relational database: 关系数据库
- a set of relations. 一组关系
- Relation: made up of 2 parts:
- Schema模式: specifies name of relation, plus name and type of each column. 指定关系的名称,加上每个列的名称和类型。
- Instance实例: a table, with rows and columns. 具有行和列的表。
- #rows = cardinality行=基
- #fields = arity (or degree)字段=参数数量(或度)
- Can think of a relation as a set of rows or tuples. 可以将关系视为一组行或元组。
- i.e., all rows are distinct 例如,所有行都是不同的
2、SQL - A language for Relational DBs
P45
- SQL (a.k.a. “Sequel”), standard language 标准语言
- Data Definition Language (DDL) 数据定义语言
- create, modify, delete relations 创建、修改、删除关系
- specify constraints 指定约束条件
- administer users, security, etc. 管理用户、安全等。
- Data Manipulation Language (DML) 数据操作语言
- Specify queries to find tuples that satisfy criteria 指定查询以查找满足条件的元组
- add, modify, remove tuples 添加、修改、删除元组
CREATE TABLE ( , … )
INSERT INTO ()
VALUES ()
DELETE FROM
WHERE
UPDATE
SET =
WHERE
SELECT
FROM
WHERE
3、Creating Relations in SQL 创建关系
P45
CREATE TABLE Students
(sid CHAR(20),
name CHAR(20),
login CHAR(10),
age INTEGER,
gpa FLOAT)
创建表格
CREATE TABLE Enrolled
(sid CHAR(20),
cid CHAR(20),
grade CHAR(2))
添加和删除元组
INSERT INTO Students (sid, name, login, age, gpa)
VALUES ('53688', 'Smith', 'smith@ee', 18, 3.2)
DELETE
FROM Students S
WHERE S.name = 'Smith'
4、Keys 键
P47
- Keys are a way to associate tuples in different relations. 键是在不同关系中关联元组的一种方法。
- Keys are one form of integrity constraint (IC) 键是完整性约束(IC)的一种形式
5、Primary Keys 主键
- A set of fields is a superkey if 一组字段是超键:
- No two distinct tuples can have same values in all key fields 没有两个不同的元组可以在所有键字段中具有相同的值
- A set of fields is a key for a relation if 一组字段是关系的键:
- It is a superkey
- No subset of the fields is a superkey. (i.e., minimal). 字段的任何子集都不是超级键
- what if more than one keys for a relation?
- One of the keys is chosen (by DBA) to be the primary key. DBA选择其中一个键作为主键。
- Other keys are called candidate keys. 其他键称为候选键
- E.g.
- sid is a key for Students.
- What about name?
- The set {sid, gpa} is a superkey.
6、Primary and Candidate Keys in SQL SQL中的主键和候选键
P47
- Possibly many candidate keys (specified using UNIQUE), one of which is chosen as the primary key. 可能有许多候选键(使用UNIQUE指定),其中一个被选为主键。
- Keys must be used carefully!
- “For a given student and course, there is a single grade.”
CREATE TABLE Enrolled
(sid CHAR(20)
cid CHAR(20),
grade CHAR(2),
PRIMARY KEY (sid,cid))
VS.
CREATE TABLE Enrolled
(sid CHAR(20),
cid CHAR(20),
grade CHAR(2),
PRIMARY KEY (sid),
UNIQUE (cid, grade))
- “Students can take only one course, and no two students in a course receive the same grade.”
7、Foreign Keys 外键 vs. Referential Integrity 参照完整性
P48
-
Foreign key: Set of fields in one relation that is used to `refer’ to a tuple in another relation. 一个关系中的一组字段,用于“引用”另一个关系中的元组。
- Must correspond to the primary key of the other relation. 必须对应于其他关系的主键。
- Like a `logical pointer’.
-
If all foreign key constraints are enforced, referential integrity is achieved (i.e., no dangling references.) 如果强制执行所有外键约束,则实现参照完整性(即,没有悬空引用)
-
E.g. Only students listed in the Students relation should be allowed to enroll for courses. 只有学生关系中列出的学生才允许注册课程。
- sid is a foreign key referring to Students: sid是指向学生关系的外键
CREATE TABLE Enrolled
(sid CHAR(20),cid CHAR(20),grade CHAR(2),
PRIMARY KEY (sid,cid),
FOREIGN KEY (sid) REFERENCES Students )
8、Enforcing Referential Integrity 强制引用完整性
P51
- sid in Enrolled: foreign key referencing Students. sid是指向学生关系的外键
- Scenarios:
- Insert Enrolled tuple with non-existent student id? 向Enrolled中插入不存在的学生学号的元组
- Delete a Students tuple? 删除一个学生元组
- Also delete Enrolled tuples that refer to it? (Cascade) 级联
- Disallow if referred to? (No Action) 不采取行动
- Set sid in referring Enrolled tuples to a default value? (Set Default) 设置默认值
- Set sid in referring Enrolled tuples to null, denoting
unknown’ orinapplicable’. (Set NULL) 设置为空
- Similar issues arise if primary key of Students tuple is updated. 如果更新Students元组的主键,也会出现类似的问题
9、Integrity Constraints (ICs) 完整性约束
P46
- IC: condition that must be true for any instance of the database 对于数据库的任何实例都必须为真的条件
- e.g., domain constraints. 域约束。
- ICs are specified when schema is defined. 在定义模式时指定ICs
- ICs are checked when relations are modified. 修改关系时会检查ICs
- A legal instance of a relation is one that satisfies all specified ICs. 一个关系的合法实例是满足所有指定ICs的实例
- DBMS should not allow illegal instances. DBMS不应该允许非法实例
- If the DBMS checks ICs, stored data is more faithful to real-world meaning. 如果DBMS检查ICs,则存储的数据更符合真实世界的含义
- Avoids data entry errors, too! 避免数据也输入错误
10、Where do ICs Come From?
- Semantics 语义学 of the real world!
- Key and foreign key ICs are the most common 键和外键ICs是最常见的
- More general ICs supported too. 也支持更通用的ICs
11、Relational Query Languages 关系查询语言
- Feature: Simple, powerful ad hoc querying 简单、功能强大的即时查询
- Declarative languages 说明性语言
- Queries precisely specify what to return 查询精确地指定要返回的内容
- DBMS is responsible for efficient evaluation (how). DBMS负责有效的评估
- Allows the optimizer to extensively re-order operations, and still ensure that the answer does not change. 允许优化器广泛地重新排序操作,并且仍然确保答案不变。
- Key to data independence! 数据独立性关键
The SQL Query Language SQL查询语言
- The most widely used relational query language.
- Current std is SQL:2008; SQL92 is a basic subset
- To find all 18 year old students, we can write:
SELECT *
FROM Students S
WHERE S.age=18
- To find just names and logins, replace the first line:
SELECT S.name, S.login
Querying Multiple Relations 查询多个关系
- What does the following query compute
SELECT S.name, E.cid
FROM Students S, Enrolled E
WHERE S.sid=E.sid AND E.grade='A'
12、Semantics of a Query 查询的语义
- A conceptual evaluation method for the previous query: 之前的查询的概念评估方法:
- do FROM clause: compute cross-product of Students and Enrolled 计算学生和注册课程的叉积
- do WHERE clause: Check conditions, discard tuples that fail 检查条件,丢弃不要的元组
- do SELECT clause: Delete unwanted fields 删除不需要的字段
- Remember, this is conceptual. Actual evaluation will be much more efficient, but must produce the same answers. 记住,这是概念性的。实际评估将更加有效,但必须得出相同的答案。
13、Summary 总结
- A tabular representation of data, simple and intuitive, currently the most widely used 数据的表格表示,简单直观,目前使用最广泛
- Object-relational features in most products 大多数产品中的对象关系特性
- Integrity constraints can be specified by the DBA, based on application semantics. DBMS checks for violations. 完整性约束可以由DBA根据应用程序语义指定。DBMS检查违规行为。
- Two important ICs: primary and foreign keys 主键和外键
- In addition, we always have domain constraints. 域约束
- Powerful query languages exist.
- SQL is the standard commercial one SQL是一种标准商用语言
- DDL - Data Definition Language 数据定义语言
- DML - Data Manipulation Language 数据操作语言
- SQL is the standard commercial one SQL是一种标准商用语言
lec3 关系代数 Relational Algebra
1、Formal Relational Query Languages 形式关系查询语言
P74
- Relational Algebra: More operational, very useful for representing execution plans. 关系代数:更具操作性,对于表示执行计划非常有用。
- Relational Calculus: Describe what you want, rather than how to compute it. (Non-procedural, declarative.) 关系演算:描述你想要什么,而不是如何计算它。(非程序性、说明性。)
Preliminaries
- A query is applied to relation instances 查询应用于关系实例
- The result of a query is also a relation instance. 查询的结果也是一个关系实例。
- Schemas of input relations for a query are fixed 查询的输入关系模式是固定的
- Schema for the result of a query is also fixed. 查询结果的模式也是固定的。
- determined by the query language constructs 由查询语言构造确定
- Positional vs. named-field notation 位置与命名字段表示法:
- Positional notation easier for formal definitions 位置表示法便于形式化定义
- Named-field notation more readable. 命名字段表示法更具可读性。
- Both used in SQL 两者都用于SQL
- Though positional notation is discouraged 虽然不鼓励使用位置表示法
2、Relational Algebra: 5 Basic Operations 关系代数:5种基本运算
- Selection ( σ ) 选择(选行)
- Selects a subset of rows (horizontal) 选择行的子集(水平)
- Projection ( π ) 投影(选列)
- Retains only desired columns (vertical) 仅保留所需的列(垂直)
- Cross-product ( × ) 叉乘/拼表
- Allows us to combine two relations.
- Set-difference ( — ) 差/减表
- Tuples in r1, but not in r2.
- Union ( ∪ ) 并表
- Tuples in r1 or in r2.
- Since each operation returns a relation, operations can be composed! (Algebra is “closed”.)
Projection ( π ) 投影
P76
- Example:
- Retains only attributes that are in the “projection list”. 仅保留“投影列表”中的属性。
- Schema of result: 结果模式
- the fields in the projection list 投影列表中的字段
- with the same names that they had in the input relation. 与输入关系中的名称相同
- Projection operator has to eliminate duplicates 必须消除重复项
- Note: real systems typically don’t do duplicate elimination 实际系统通常不进行重复消除
- Unless the user explicitly asks for it. 除非用户明确要求
- (Why not?)
Selection ( σ ) 选择
P76
- Selects rows that satisfy selection condition. 选择满足选择条件的行
- Result is a relation. 结果是一种关系
- Schema of result is same as that of the input relation. 结果的模式与输入关系的模式相同
- Do we need to do duplicate elimination?
Union and Set-Difference 并差
P77
- Both of these operations take two input relations, which must be union-compatible: 这两种操作都采用两种输入关系,它们必须是并集兼容的
- Same number of fields. 相同数量的字段
- ‘Corresponding’ fields have the same type. “对应”字段具有相同的类型
- For which, if any, is duplicate elimination required?
Cross-Product 叉积
P78
- S1 × R1:
- Each row of S1 paired with each row of R1. S1的每一行与R1的每一行配对
- Q: How many rows in the result?
- Result schema has one field per field of S1 and R1, 结果牧师在S1和R1的每个字段中有一个字段
- Field names `inherited’ if possible. 如果可能,字段名“继承”
- Naming conflict: S1 and R1 have a field with the same name. 命名冲突:S1和R1有一个同名字段
- Can use the renaming operator: 可以使用重命名运算符
重命名 ρ
P78
Compound Operator: Intersection 交
P77
- On top of 5 basic operators, several additional “Compound Operators” 除5个基本运算符外,还有几个“复合运算符”
- These add no computational power to the language 这些不增加语言的计算能力 有用的速记
- Useful shorthand 可以用基本运算符单独表示
- Can be expressed solely with the basic operators. 交集采用两个输入关系,它们必须是并集兼容的
- Intersection takes two input relations, which must be union-compatible.
- Q: How to express it using basic operators? 问:如何使用基本运算符表示它?
- R ∩ S = R - (R - S)
Compound Operator: Join 连接
P78
- Involve cross product, selection, and (sometimes) projection. 涉及叉积、选择和(有时)投影。
- Most common type of join: “natural join” 最常见的连接类型:“自然连接”
- R |X| S conceptually is:
- Compute R × S 计算R×S
- Select rows where attributes appearing in both relations have equal values 选择两个关系中出现的属性值相等的行
- Project all unique attributes and one copy of each of the common ones. 投影所有唯一属性和每个公共属性的一个副本
- R |X| S conceptually is:
- Note: Usually done much more efficiently than this. 注意:通常完成比这更高效
Other Types of Joins
- Condition Join (or “theta-join”) 条件连接 :
P79
Result schema same as that of cross-product. 结果模式与叉积的结果模式相同。
May have fewer tuples than cross-product. 可能具有比叉积更少的元组。
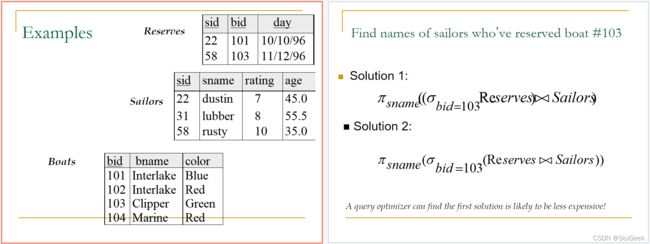
Equi-Join 等值连接 : Special case: condition c contains only conjunction of equalities. 特例:条件c只包含等式的连接。
例子
P81


Summary 总结
- Relational Algebra: a small set of operators mapping relations to relations 关系代数:将关系映射到关系的一小组运算符
- Operational, in the sense that you specify the explicit order of operations 可操作性,即指定操作的显式顺序
- A closed set of operators! Can mix and match. 一组闭合的运算符!可以混搭。
- Basic ops include: σ, π, x, ∪, -,|X|
- Important compound ops: ∩,
lec3 Storing Data: Disks and Files 存储数据:磁盘和文件
Block diagram of a DBMS 数据库管理系统的框图
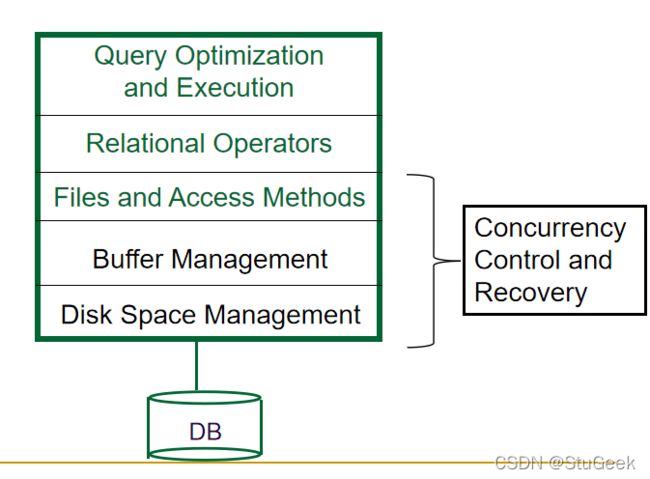
Disks, Memory, and Files 磁盘、内存和文件

Disks and Files 磁盘和文件
- DBMS stores information on disks. DBMS将信息存储在磁盘上。
- Tapes are also used. 还使用磁带。
- Major implications for DBMS design! DBMS设计的主要含义!
- READ: transfer data from disk to main memory (RAM). 读取:将数据从磁盘传输到主存储器(RAM)。
- WRITE: transfer data from RAM to disk. 写入:将数据从RAM传输到磁盘。
- Both high-cost relative to memory references 两者都比内存引用成本高
- Can/should plan carefully! 可以/应该仔细计划!
Why Not Store Everything in Main Memory? 为什么不把所有东西都存储在主内存中呢?
- Costs too much. For ~$1000, PCConnection will sell you either 费用太高了。只需约1000美元,PCConnection即可向您出售
- ~80GB of RAM (unrealistic) ~80GB内存(不切实际)
- ~400GB of Flash USB keys (unrealistic) 约400GB闪存USB密钥(不现实)
- ~180GB of Flash solid-state disk (serious) ~180GB闪存固态磁盘(严重)
- ~7.7TB of disk (serious) 约7.7TB磁盘(严重)
- Main memory is volatile. 主存储器是易失性的。
- Want data to persist between runs. (Obviously!) 希望数据在两次运行之间保持不变。(显然!)
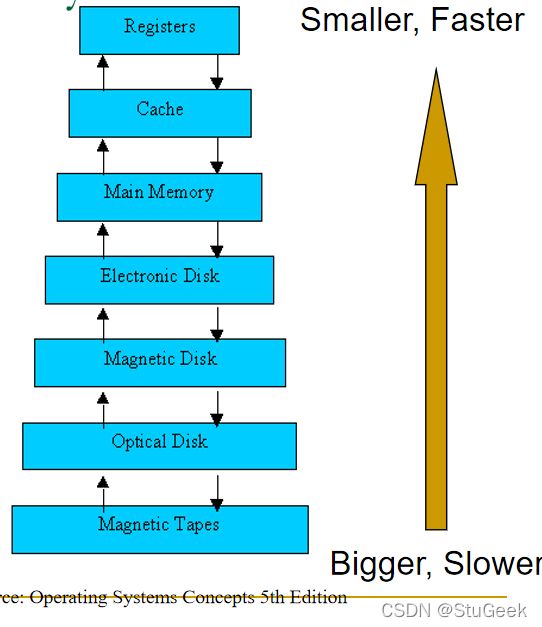
The Storage Hierarchy 存储层次结构
P231
- Main memory (RAM) for currently used data. 用于当前使用数据的主存储器(RAM)。
- Disk for main database (secondary storage). 主数据库磁盘(辅助存储)
- Tapes for archive (tertiary storage). 用于存档的磁带(第三级存储)
- The role of Flash (SSD) still unclear 闪存(SSD)的作用仍不清楚
Disks 磁盘
P231
- Still the secondary storage device of choice. 仍然是首选的辅助存储设备。
- Main advantage over tape: 与磁带相比的主要优势:
- random access vs. sequential. 随机存取与顺序存取。
- Fixed unit of transfer 固定转移单位
- Read/write disk blocks or pages (8K) 读/写磁盘块或页(8K)
- Not “random access” (vs. RAM) 非“随机存取”(与RAM相比)
- Time to retrieve a block depends on location 检索块的时间取决于位置
- Relative placement of blocks on disk has major impact on DBMS performance! 块在磁盘上的相对位置对DBMS性能有重大影响!
Components of a Disk 磁盘组件
- The platters spin (say, 120 rps). 盘片旋转(比如120转)。
- The arm assembly is moved in or out to position a head on a desired track. Tracks under heads make a cylinder (imaginary!). 将臂组件移入或移出,以将头部定位在所需轨道上。头部下方的轨道构成一个圆柱体(想象中的!)。
- Only one head reads/writes at any one time. 一次只能读取/写入一个磁头。
- Block size is a multiple of sector size (which is fixed). 块大小是扇区大小(固定)的倍数。
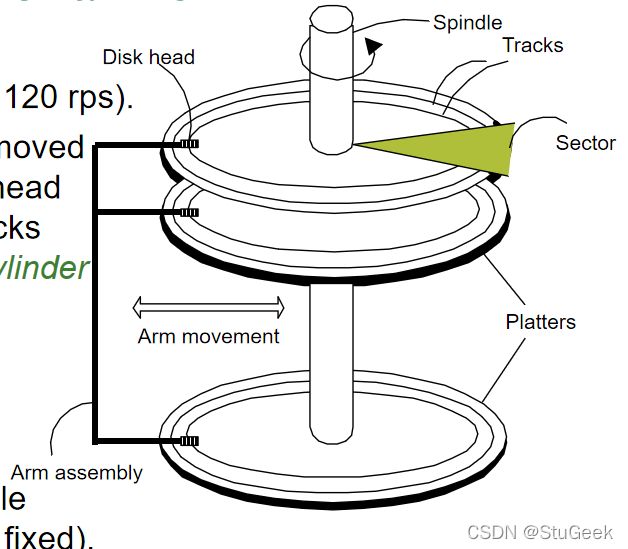
Accessing a Disk Page 访问磁盘页
- Time to access (read/write) a disk block: 访问(读/写)磁盘块的时间
- seek time (moving arms to position disk head on track) 寻道时间(移动臂将磁头定位在磁道上)
- rotational delay (waiting for block to rotate under head) 旋转延迟(等待块在头部下方旋转)
- transfer time (actually moving data to/from disk surface) 传输时间(实际将数据移动到磁盘表面或从磁盘表面移动数据)
- Seek time and rotational delay dominate. 寻道时间和旋转延迟占主导地位。
- Seek time varies from 0 to 10msec 寻道时间从0到10毫秒不等
- Rotational delay varies from 0 to 3msec 旋转延迟从0到3毫秒不等
- Transfer rate around .02msec per 8K block 传输速率约为每8K块0.02毫秒
- Key to lower I/O cost: reduce seek/rotation delays! Hardware vs. software solutions? 降低I/O成本的关键:减少寻道/旋转延迟!硬件与软件解决方案?
Arranging Pages on Disk 在磁盘上排列页面
Next’ block concept:下一个“块”概念:- blocks on same track, followed by 同一磁道上的块,然后是
- blocks on same cylinder, followed by 位于同一柱面上的块,然后是
- blocks on adjacent cylinder 相邻柱面上的块
- Blocks in a file should be arranged sequentially on disk (by `next’), to minimize seek and rotational delay. 文件中的块应在磁盘上按顺序排列(按“下一步”),以最小化寻道和旋转延迟。
- For a sequential scan, pre-fetching several pages at a time is a big win! 对于顺序扫描,一次预取几个页面是一个巨大的胜利!
Disk Space Management 磁盘空间管理
- Lowest layer of DBMS, manages space on disk 数据库管理系统的最底层,管理磁盘上的空间
- Higher levels call upon this layer to: 更高级别要求该层
- allocate/de-allocate a page 分配/取消分配页面
- read/write a page 读/写一页
- Request for a sequence of pages best satisfied by pages stored + sequentially on disk! 请求按顺序存储在磁盘上的页面最好满足页面序列!
- Responsibility of disk space manager. 磁盘空间管理器的职责
- Higher levels don’t know how this is done, or how free space is managed. 更高的级别不知道如何做到这一点,也不知道如何管理可用空间
- Though they may make performance assumptions! 尽管他们可能会做出性能假设
- Hence disk space manager should do a decent job. 因此,磁盘空间管理器应该做得很好
Context 环境
Files of Records 文件记录
- Blocks are the interface for I/O, but… 块是I/O的接口,但是…
- Higher levels of DBMS operate on records, and files of records. 更高级别的DBMS对记录和记录文件进行操作。
- FILE: A collection of pages, each containing a collection of records. Must support: 文件:页面的集合,每个页面包含一组记录。必须支持:
- insert/delete/modify record 插入/删除/修改记录
- fetch a particular record (specified using record id) 获取特定记录(使用记录id指定)
- scan all records (possibly with some conditions on the records to be retrieved) 扫描所有记录(可能对要检索的记录具有某些条件)
- Typically implemented as multiple OS “files” 通常实现为多个操作系统“文件”
- Or “raw” disk space 或“原始”磁盘空间
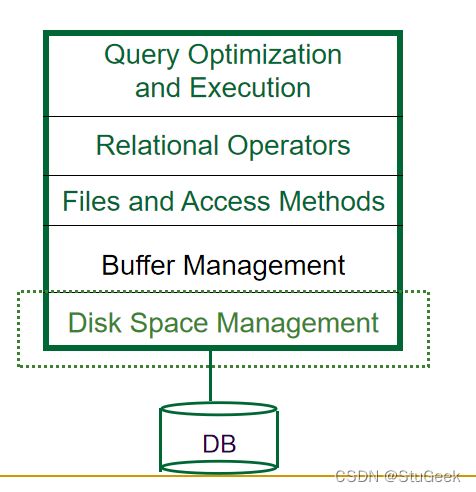
Unordered (Heap) Files 无序(堆)文件
- Collection of records in no particular order. 不按特定顺序收集记录。
- As file shrinks/grows, disk pages (de)allocated 随着文件的缩小/增长,磁盘页(不)被分配
- To support record level operations, we must: 为了支持记录级操作,我们必须:
- keep track of the pages in a file 跟踪文件中的页面
- keep track of free space on pages 跟踪页面上的可用空间
- keep track of the records on a page 跟踪页面上的记录
- There are many alternatives for keeping track of this. 有很多方法可以跟踪这一点。
- We’ll consider two. 我们考虑两个。
Heap File Implemented as a List 作为链表实现的堆文件
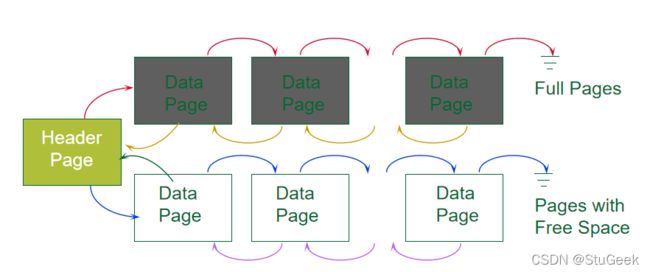
- The header page id and Heap file name must be stored someplace. 头页id和堆文件名必须存储在某个位置。
- Database “catalog” 数据库“目录”
- Each page contains 2 `pointers’ plus data. 每页包含2个“指针”和数据。
- One disadvantage 一个缺点
- Virtually all pages will be on the free list if records are of variable length, i.e., every page may have some free bytes if we like to keep each record in a single page. 如果记录长度可变,则几乎所有页面都将位于空闲列表中,即,如果我们希望将每个记录保留在单个页面中,则每个页面可能都有一些空闲字节。
Heap File Using a Page Directory 使用页面目录堆文件

- The directory is itself a collection of pages; each page can hold several entries. 目录本身就是一个页面集合;每页可以容纳多个条目。
- The entry for a page can include the number of free bytes on the page. 页面的条目可以包括页面上的可用字节数。
- To insert a record, we can search the directory to determine which page has enough space to hold the record. 要插入记录,我们可以搜索目录以确定哪个页面有足够的空间来保存记录。
Indexes (a sneak preview) 索引(预览)
- A Heap file allows us to retrieve records: 堆文件允许我们检索记录
- by specifying the rid (record id), or 通过指定rid(记录id),或
- by scanning all records sequentially 按顺序扫描所有记录
- Sometimes, we want to retrieve records by specifying the values in one or more fields, e.g., 有时,我们希望通过在一个或多个字段中指定值来检索记录,例如
- Find all students in the “CS” department 查找“CS”系的所有学生
- Find all students with a gpa > 3 查找gpa>3的所有学生
- Indexes are file structures that enable us to answer such value-based queries efficiently. 索引是一种文件结构,使我们能够高效地回答此类基于值的查询。
Record Formats: Fixed Length 记录格式:固定长度
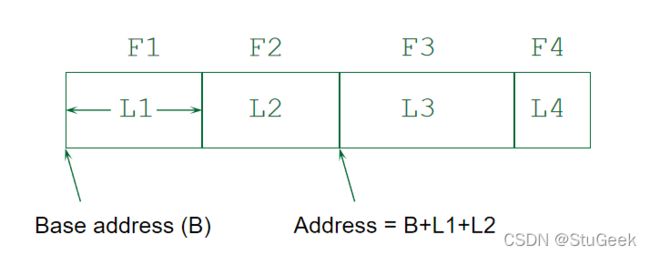
- Information about field types same for all records in a file; stored in system catalogs. 关于文件中所有记录的相同字段类型的信息;存储在系统目录中。
- Finding i’th field done via arithmetic. 通过运算找到第i个字段
Record Formats: Variable Length 记录格式:可变长度

- Two alternative formats (# fields is fixed): 两种可选格式(#字段是固定的)
- Fields Delimited by Special Symbols 由特殊符号分隔的字段
- Array of Field Offsets 字段偏移数组
- Second offers direct access to i’th field, efficient storage of nulls (special don’t know value); small directory overhead. 第二个提供了对第i个字段的直接访问,有效地存储空值(特殊的未知值);目录开销小。







Summary 总结
- Disks provide cheap, non-volatile storage. 磁盘提供廉价的非易失性存储
- Better random access than tape, worse than RAM 随机存取比磁带好,比RAM差
- Arrange data to minimize seek and rotation delays. 安排数据以最小化寻道和旋转延迟
- Depends on workload! 取决于工作量
- Buffer manager brings pages into RAM. 缓冲区管理器将页面带入RAM
- Page pinned in RAM until released by requestor. 页面固定在RAM中,直到请求者释放
- Dirty pages written to disk when frame replaced (sometime after requestor unpins the page). 当帧被替换时(请求者解除页面锁定后的某个时间),脏页被写入磁盘
- Choice of frame to replace based on replacement policy. 根据更换策略选择要更换的帧
- Tries to pre-fetch several pages at a time. 尝试一次预取几页
- DBMS vs. OS File Support DBMS与OS文件支持
- DBMS needs non-default features DBMS需要非默认特性
- Careful timing of writes, control over prefetch 仔细安排写入时间,控制预取
- Variable length record format 可变长度记录格式
- Direct access to i’th field and null values. 直接访问第i个字段和空值
- Slotted page format 分槽页格式
- Variable length records and intra-page reorg 可变长度记录和页面内重新排序
- DBMS “File” tracks collection of pages, records within each. DBMS“文件”跟踪每个文件中的页面和记录的集合
- Pages with free space identified using linked list or directory structure 使用链表或目录结构标识具有可用空间的页面
- Indexes support efficient retrieval of records based on the values in some fields. 索引支持根据某些字段中的值高效检索记录
- Catalog relations store information about relations, indexes and views. 目录关系存储有关关系、索引和视图的信息
lec4 查询语言 SQL: The Query Language
回顾
- Relational Algebra (Operational Semantics) 关系代数(操作语义)
- Given a query, how to mix and match the relational algebra operators to answer it 给定一个查询,如何混合和匹配关系代数运算符来解答它
- Used for query optimization 用于查询优化
- Relational Calculus (Declarative Semantics) 关系演算(说明语义)
- Given a query, what do I want my answer set to include? 给定一个查询,我希望我的答案集包括什么?
- Algebra and safe calculus are simple and powerful models for query languages for relational model 代数和安全演算是关系模式查询语言的简单而强大的模型
- Have same expressive power 有同样的表现力
- SQL can express every query that is expressible in relational algebra/calculus. (and more) SQL可以表达每一个可以用关系代数/演算表达的查询。(及更多)
Relational Query Languages 关系查询语言
- Two sublanguages: 两个子语言:
- DDL – Data Definition Language 数据定义语言
- Define and modify schema (at all 3 levels) 定义和修改架构(在所有3个级别)
- DML – Data Manipulation Language 数据操作语言
- Queries can be written intuitively. 可以直观地编写查询。
- DDL – Data Definition Language 数据定义语言
- DBMS is responsible for efficient evaluation. DBMS负责有效的评估。
- The key: precise semantics for relational queries. 关键:关系查询的精确语义。
- Optimizer can re-order operations 优化器可以重新排序操作
- Won’t affect query answer. 不会影响查询答案。
- Choices driven by “cost model” 由“成本模型”驱动的选择
The SQL Query Language SQL查询语言
P97
- The most widely used relational query language. 最广泛使用的关系查询语言
- Standardized 标准化
- (although most systems add their own “special sauce” – including PostgreSQL) 尽管大多数系统都添加了自己的“特殊角色”——包括PostgreSQL
- We will study SQL92 – a basic subset 我们将研究SQL92——一个基本子集
数据库例子
P98
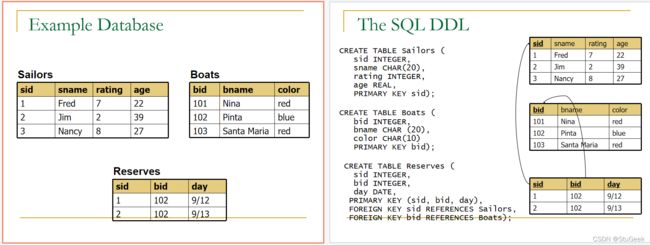











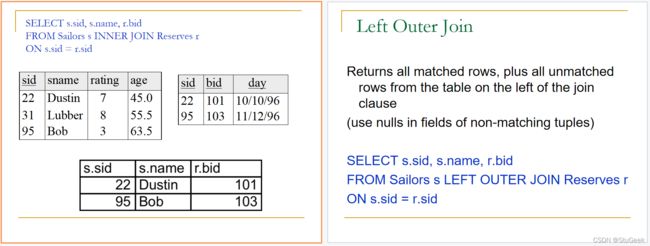





Conceptual Evaluation 概念评估
- The cross-product of relation-list is computed, tuples that fail qualification are discarded, `unnecessary’ fields are deleted, and the remaining tuples are partitioned into groups by the value of attributes in grouping-list. 计算关系列表的叉积,丢弃不符合要求的元组,删除“不必要”字段,并根据分组列表中的属性值将剩余元组划分为组。
- One answer tuple is generated per qualifying group. 每个符合条件的组生成一个答案元组。

Conceptual Evaluation 概念评估
- Form groups as before. 像以前一样分组。
- The group-qualification is then applied to eliminate some groups. 然后应用组限定来消除某些组。
- Expressions in group-qualification must have a single value per group! 组限定中的表达式每个组必须有一个值!
- That is, attributes in group-qualification must be arguments of an aggregate op or must also appear in the grouping-list. (SQL does not exploit primary key semantics here!) 也就是说,组限定中的属性必须是聚合op的参数,或者也必须出现在分组列表中。(SQL在此不利用主键语义!)
- One answer tuple is generated per qualifying group. 每个符合条件的组生成一个答案元组。



Two more important topics 还有两个重要的话题
- Constraints 约束条件
- SQL embedded in other languages 嵌入其他语言的SQL
Integrity Constraints (Review) 完整性约束(回顾)
- An IC describes conditions that every legal instance of a relation must satisfy. IC描述了关系的每个合法实例必须满足的条件。
- Inserts/deletes/updates that violate IC’s are disallowed. 不允许违反IC的插入/删除/更新。
- Can ensure application semantics (e.g., sid is a key), or prevent inconsistencies (e.g., sname has to be a string, age must be < 200) 可以确保应用程序语义(例如,sid是一个键),或防止不一致(例如,sname必须是一个字符串,年龄必须小于200)
- Types of IC’s: Domain constraints, primary key constraints, foreign key constraints, general constraints. IC的类型:域约束、主键约束、外键约束、一般约束。
General Constraints 一般约束
P50
- Useful when more general ICs than keys are involved. 当涉及比键更通用的IC时非常有用。
- Can use queries to express constraint. 可以使用查询来表示约束。
- Checked on insert or update. 在插入或更新时选中。
- Constraints can be named. 可以命名约束。
Summary 总结
- Relational model has well-defined query semantics 关系模型具有定义良好的查询语义
- SQL provides functionality close to basic relational model SQL提供了接近基本关系模型的功能
(some differences in duplicate handling, null values, set operators, …) (在重复处理、空值、集合运算符等方面存在一些差异) - Typically, many ways to write a query 通常,有许多方法可以编写查询
- DBMS figures out a fast way to execute a query, regardless of how it is written. DBMS找到了一种执行查询的快速方法,而不管它是如何编写的。
lec5 Tree-Structured Indexes 树结构索引
Review: Files, Pages, Records 回顾:文件、页面、记录
- Abstraction of stored data is “files” with “pages” of “records”. 存储数据的抽象是“文件”和“记录”的“页面”。
- Records live on pages 记录在页面上
- Physical Record ID (RID) =
- Records can have fixed length or variable length. 记录可以具有固定长度或可变长度。
- Files can be unordered (heap), sorted, or kind of sorted (i.e., “clustered”) on a search key. 在搜索键上,文件可以是无序(堆)、排序或某种排序(即“聚簇”)。
- Indexes can be used to speed up many kinds of accesses. (i.e., “access paths”) 索引可用于加速多种访问。(即“访问路径”)
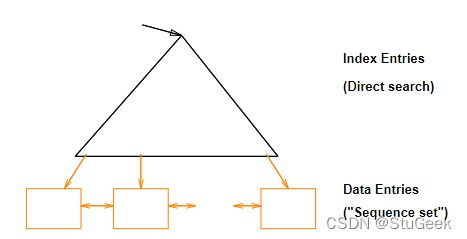
Tree-Structured Indexes: Introduction 树索引介绍
- Selections of form: field constant 选择形式
- Equality selections (op is =) 相等选择
- Either “tree” or “hash” indexes help here. “树”或“散列”索引在这里都有帮助
- Range selections (op is one of <, >, <=, >=, BETWEEN) 范围选择
- “Hash” indexes don’t work for these. “散列”索引对这些不起作用
- More complex selections (e.g. spatial containment) 更复杂的选择(如空间包容)
- There are fancier trees that can do this… 有更奇特的树可以做到这一点
- Tree-structured indexing techniques support both range selections and equality selections. 树结构索引技术支持范围选择和相等选择
- ISAM: static structure; early index technology. 静态结构;早期索引技术
- B+ tree: dynamic, adjusts gracefully under inserts and deletes. 动态,在插入和删除发生时优雅地调整
Range Searches 范围搜索
P254
- ``Find all students with gpa > 3.0’’
- If data is in sorted file, do binary search to find first such student, then scan to find others. 若数据在已排序的文件中,则进行二分搜索以查找第一个此类学生,然后进行扫描以查找其他这种学生
- Cost of binary search in a database can be quite high. 在数据库中进行二分搜索的成本可能相当高
- Why???
- Simple idea: Create an `index’ file, and then do binary search on (smaller) index file. 简单的想法:创建一个“索引”文件,然后对(较小的)索引文件进行二分搜索

ISAM (Indexed Sequential Access Method) 索引顺序存储方法
P255
- 索引项:
,它们直接搜索叶子中的数据项。 - 每个节点可以容纳2个条目的示例;

ISAM is a STATIC Structure ISAM是一种静态结构
P256
- File creation: 文件创建
- Leaf (data) pages allocated sequentially, sorted by search key 按顺序分配的叶子(数据)页,按搜索键排序
- then index pages 然后索引页面
- then overflow pages. 然后溢出页
- Search: Start at root; use key comparisons to go to leaf. 搜索:从根开始;使用键比较转到叶
- Cost = log F N
- F = # entries/page (i.e., fanout) F=#条目/页面(即扇出)(在一个节点中指向子节点的指针数量)
- N = # leaf pages N=#叶子页数
- no need for `next-leaf-page’ pointers. (Why?) 不需要“下一页”指针
- Insert: Find leaf that data entry belongs to, and put it there. Overflow page if necessary. 插入:找到数据项所属的叶,并将其放在那个里面。如有必要,增加溢出页。
- Delete: Seek and destroy! If deleting a tuple empties an overflow page, de-allocate it and remove from linked-list. 删除:寻找并销毁!若删除元组会清空溢出页面,则取消分配该页面并将其从链表中删除。
例子:插入23*,48*,41*,42*,然后删除42*,51*,97*
P256

B+ Tree Structure (1) B+树结构
P257
- The ROOT node contains between 1 and 2d index entries. 根节点包含1到2d个索引项。
- The parameter d is called the order of the tree. 参数d称为树的阶(秩)。
- An index entry is a pair of
- the ROOT is a leaf or has at least two children. 根是一片叶子或至少有两个孩子。
- Each internal node contains m (d ≤ m ≤ 2d) index entries. 每个内部节点包含m个(d≤ M≤ 2d)索引项。
- Each internal node has m +1 children. 每个内部节点都有m+1个子节点。
- Each leaf node contains m (d ≤ m ≤ 2d) data entries 每个叶节点包含m(d≤ M≤ 2d)数据项
- A data entry is one of
或 或
- A data entry is one of
- Each path from the ROOT to any leaf has the same length. 从根到任何叶子的每条路径都具有相同的长度。
- Length is the number of nodes in a path. Length是路径中的节点数。
- Supports equality and range-searches efficiently. 有效地支持相等和范围搜索。
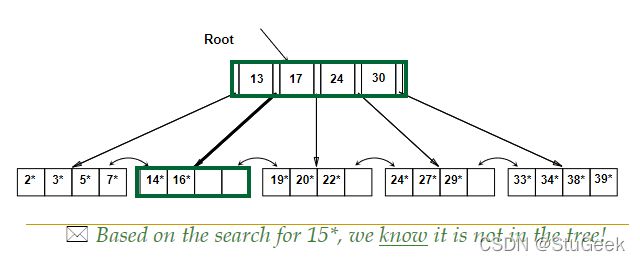
B+ Tree Equality Search B+数相等搜索
- Search begins at root, and key comparisons direct it to a leaf. 搜索从根开始,键比较将其指向叶。
- Search for 15*…
B+ Tree Range Search B+树范围搜索
- Search all records whose ages are in [15,28]. 搜索在[15,28]的所有记录
- Equality search 15*. 和搜索15一样
- Follow sibling pointers. 沿着兄弟指针

B+ Trees in Practice 实践中的B+树
- Typical order: 100. Typical fill-factor: 67%. 典型阶数:100 典型填充系数:67%
- average fanout = 133 平均扇出:133
- Can often hold top levels in buffer pool:
- Level 1 = 1 page = 8 KB
- Level 2 = 133 pages = 1 MB
- Level 3 = 17,689 pages = 145 MB
- Level 4 = 2,352,637 pages = 19 GB
- With 1 MB buffer, can locate one record in 19 GB (or 0.3 billion records) in two I/Os! 使用1 MB缓冲区,可以在两个I/O中定位19 GB(或3亿条记录)中的一条记录!
Inserting a Data Entry into a B+ Tree 向B+树中插入一个数据项
P261
- Find correct leaf L. 找到正确的叶L
- Put data entry onto L. 把数据放进到L
- If L has enough space, done! 如果L有足够的空间,完成
- Else, must split L (into L and a new node L2) 否则,必须拆分L(分为L和新节点L2)
- Redistribute entries evenly, copy up middle key. 均匀地重新分配条目,向上复制中间键
- Insert index entry pointing to L2 into parent of L. 将指向L2的索引项插入L的父项
- This can happen recursively 这可能会递归发生
- To split index node, redistribute entries evenly, but push up middle key. (Contrast with leaf splits.) 要分割索引节点,请均匀地重新分配条目,但向上推中间键。(与叶裂开形成对比。)
- Splits “grow” tree; root split increases height. 分裂“生长”树;根分裂增加高度。
- Tree growth: gets wider or one level taller at top. 树生长:顶部变宽或高一级。
Example B+ Tree – Inserting 8*
P261
可以使用重分布避免分裂,但在实践中通常不会使用。
Data vs. Index Page Split (from previous example of inserting “8*”) 数据页和索引页分裂对比
- Observe how minimum occupancy is guaranteed in both leaf and index pg splits. 观察如何在叶子页和索引页拆分中保证最低占用率。
- Note difference between copy-up and push-up; be sure you understand the reasons for this. 注意复制上去和弹上去之间的区别
Deleting a Data Entry from a B+ Tree 从B+树中删除一个数据项
P263
- Start at root, find leaf L where entry belongs. 从根开始,找到条目所属的叶L。
- Remove the entry. 删除条目
- If L is at least half-full, done! 如果L至少有半满,完成。
- If L has only d-1 entries, 如果L只有d-1个条目
- Try to re-distribute, borrowing from sibling (adjacent node with same parent as L). 尝试重分布,从兄弟节点(与L具有相同父节点的相邻节点)借用
- If re-distribution fails, merge L and sibling. 如果重分布失败,则合并L和兄弟结点
- If merge occurred, must delete entry (pointing to L or sibling) from parent of L. 如果发生合并,则必须从L的父项中删除条目(指向L或兄弟结点)
- Merge could propagate to root, decreasing height. 合并可能会传播到根,从而降低高度
Example Tree (including 8*) Delete 19* and 20* …
P264
重分布
P265

Bulk Loading of a B+ Tree B+树的块加载
P268
- Given: large collection of records 给定:大量的记录集合
- Desire: B+ tree on some field 希望:某个领域的B+树
- Bad idea: repeatedly insert records 坏主意:重复插入记录
- Slow, and poor leaf space utilization . Why? 速度慢,叶空间利用率低。
- Bulk Loading can be done much more efficiently. 块加载可以更有效地完成
- Initialization: Sort all data entries, insert pointer to first (leaf) page in a new (root) page. 初始化:对所有数据项进行排序,在新(根)页中插入指向第一(叶)页的指针。
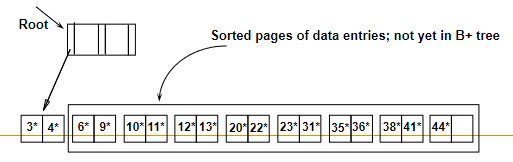
- Index entries for leaf pages always entered into right-most index page just above leaf level. When this fills up, it splits. (Split may go up right-most path to the root.) 叶子页的索引项总是插入到叶子层级上方最右边的索引页中。当这个填满时,它就会分裂。(拆分可能会沿最右边的路径到达根。)
- Much faster than repeated inserts. 比重复插入快得多。
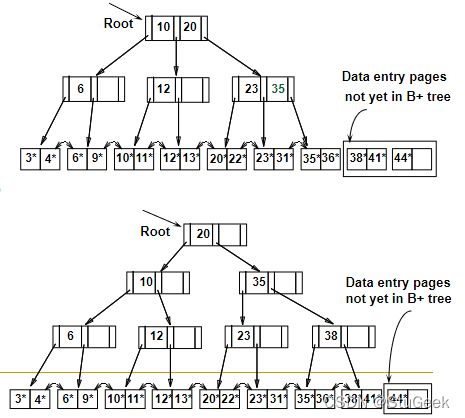
Summary of Bulk Loading 块加载总结
- Option 1: multiple inserts. 多个插入
- Slow. 缓慢的
- Does not give sequential storage of leaves. 不提供叶子的顺序存储
- Option 2: Bulk Loading 块加载
- Fewer I/Os during build. 在构建过程中更少的I/O次
- Leaves will be stored sequentially (and linked, of course). 叶子将按顺序存储(当然还有链接)
- Can control “fill factor” on pages. 可以控制页面上的“填充因子”
A Note on `Order’
- Order (d) makes little sense with variable-length entries 对于可变长度的条目,阶数(d)没有什么意义
- Use a physical criterion in practice (`at least half-full’). 在实践中使用物理标准(“至少半满”)。
- Index pages often hold many more entries than leaf pages. 索引页通常比叶子页包含更多的条目。
- Variable sized records and search keys: 可变大小的记录和搜索键
- different nodes have different numbers of entries. 不同的节点具有不同的条目数
- Even with fixed length fields, Alternative (3) gives variable length 即使使用固定长度字段,备选方案也会给出可变长度
- Many real systems are even sloppier than this — only reclaim space when a page is completely empty. 许多真正的系统甚至比这更草率 — 只在页面完全为空时回收空间
Summary 总结
- Tree-structured indexes are ideal for range-searches, also good for equality searches. 树结构索引非常适合范围搜索,也适用于相等搜索。
- ISAM is a static structure. ISAM是一种静态结构。
- Only leaf pages modified; overflow pages needed. 只修改叶子页;需要溢出页面
- Overflow chains can degrade performance unless size of data set and data distribution stay constant. 溢出链会降低性能,除非数据集和数据分布的大小保持不变
- B+ tree is a dynamic structure. B+树是一种动态结构
- Inserts/deletes leave tree height-balanced; log F N cost. 插入/删除保持树高平衡;logF N成本
- High fanout (F) means depth rarely more than 3 or 4. 高扇出(F)表明深度很少超过3或4
- Typically, 67% occupancy on average. 通常,平均填充系数为67%
- Usually preferable to ISAM; adjusts to growth gracefully. 通常优于ISAM;优雅地适应成长
- If data entries are data records, splits can change rids! 如果数据项是数据记录,拆分可以更改去除
- Key compression increases fanout, reduces height. 按键压缩增加扇出,降低高度
- Bulk loading can be much faster than repeated inserts for creating a B+ tree on a large data set. 对于在大型数据集上创建B+树,块加载比重复插入快得多
- B+ tree widely used because of its versatility. B+树因其多功能性而被广泛使用
- One of the most optimized components of a DBMS. 数据库管理系统中最优化的组件之一
lec6 External Sorting 外部排序
Why Sort?
P315
- A classic problem in computer science!
- Data requested in sorted order 按排序顺序请求的数据
- e.g., find students in increasing gpa order
- First step in bulk loading B+ tree index. 块加载B+树索引的第一步
- Useful for eliminating duplicates (Why?) 用于消除重复项
- Useful for summarizing groups of tuples 于汇总元组的组
- Sort-merge join algorithm involves sorting. 排序合并连接算法涉及排序
- Problem: sort 100Gb of data with 1Gb of RAM. 问题:使用1Gb内存对100Gb数据进行排序
- why not virtual memory? 为什么不是虚拟内存
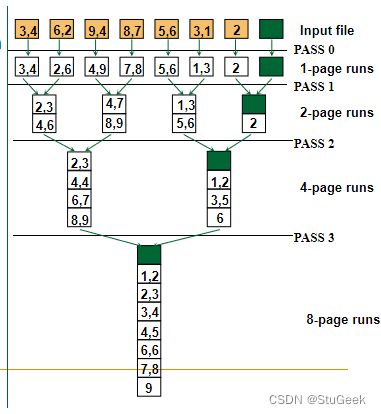
2-Way Sort: Requires 3 Buffers 2路排序:需要3个缓冲区
P317
- Pass 0: Read a page, sort it, write it. 第0趟:每次从文件中读取一个数据页,读入数据后,对其中的数据进行排序,写回磁盘
- only one buffer page is used.
- each sorted page (or subfiles) is called a run.
- Pass 1, 2, 3, …, etc.: 从之前处理的输出中读入一对有序段并进行归并,生成两倍长的段
- requires 3 buffer pages
- merge pairs of runs into runs twice as long
- three buffer pages used.

- Each pass we read + write each page in file. 每一趟读入一个数据页,进行处理然后写回磁盘,对每个数据页读写磁盘两次
- N pages in the file => the number of passes N个页面处理趟数为 向上取整[log2N] + 1
- So total cost is: 2N(向上取整[log2N] + 1)
- Idea: Divide and conquer: sort subfiles and merge 分治法:对子文件排序然后合并。
General External Merge Sort 常用外部合并排序
P318
- To sort a file with N pages using B buffer pages: 使用B个可用主存页排序有N个数据页的文件
- Pass 0: use B buffer pages. Produce 向上取整[N / B] sorted runs of B pages each. 第0趟:每次读入B个数据页,在主存内排序后生成向上取整[N / B]个长为B个数据页的段
- Pass 1, 2, …, etc.: merge B-1 runs. 用B-1个缓存作输入,剩余的一个缓存作输出,同时归并B-1个有序段
Cost of External Merge Sort 外部排序花费
P319
- Number of passes: 趟数为 1+向上取整[log(B-1)向上取整[N / B]]
- Cost = 2N * (# of passes) 2N *趟数
- E.g., with 5 buffer pages, to sort 108 page file: 用5个缓冲区排序包含108个数据页的文件
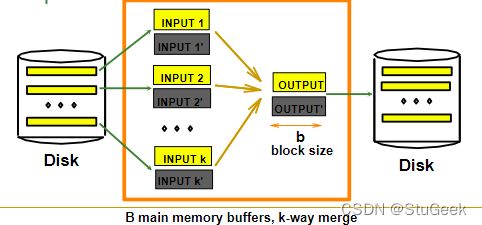
Blocked I/O for External Merge Sort
- Do I/O a page at a time 一次I/O一页
- Not one I/O per record 不是每个记录一个I/O
- In fact, read a block (chunk) of pages sequentially! 事实上,按顺序读取一块页面!
- Suggests we should make each buffer (input/output) be a block of pages. 建议将每个缓冲区(输入/输出)设为一个页面块。
- But this will reduce fan-in during merge passes! 但这将减少合并过程中的扇入!
- In practice, most files still sorted in 2-3 passes. 实际上,大多数文件仍按2-3遍排序。
- Theme: Amortize a random I/O across more data read. 主题:将随机I/O分摊到更多读取的数据中。
- But pay for it in memory footprint 但要在内存占用中付出消耗
Double Buffering 双缓冲
P323
- Goal: reduce wait time for I/O requests during merge 目标:减少合并期间I/O请求的等待时间
- Idea: 2 blocks RAM per run, disk reader fills one while sort merges the other 想法:每次运行2块RAM,磁盘读取器填充一个,而排序合并另一个
- Potentially, more passes; in practice, most files still sorted in 2-3 passes. 潜在的,更多的趟;实际上,大多数文件仍按2-3遍排序。
- Theme: overlap I/O and CPU activity via read-ahead (prefetching) 主题:通过预读(预取)重叠I/O和CPU活动
Using B+ Trees for Sorting 使用B+树来排序
- Scenario: Table to be sorted has B+ tree index on sorting column(s). 场景:要排序的表在排序列上有B+树索引。
- Idea: Can retrieve records in order by traversing leaf pages. 想法:可以通过遍历叶子页按顺序检索记录。
- Is this a good idea? 这是个好主意吗?
- Cases to consider:
- B+ tree is clustered B+树是聚簇的
- B+ tree is not clustered B+树不是聚簇的
Clustered B+ Tree Used for Sorting 使用聚簇索引的B+树来排序
P324
- Cost: root to the left-most leaf, then retrieve all leaf pages (Alternative 1) 成本:从根开始到最左边的叶子,然后检索所有叶子页(备选方案1)
- If Alternative 2 is used? Additional cost of retrieving data records: each page fetched just once. 如果使用备选方案2?检索数据记录的额外成本:每个页面只提取一次。
- Always better than external sorting! 永远比外排序好

Unclustered B+ Tree Used for Sorting 使用非聚簇索引的B+树来排序
P324
- Alternative (2) for data entries; each data entry contains rid of a data record. In general, one I/O per data record! 数据输入的备选方案(2);每个数据项都包含一条数据记录。通常,每个数据记录一个I/O!

Summary 总结
- External sorting is important 外排序很重要
- External merge sort minimizes disk I/O cost: 外部合并排序将磁盘I/O成本降至最低
- Pass 0: Produces sorted runs of size B (# buffer pages). Later passes: merge runs. 第0趟:生成大小为B(#缓冲页)的排序运行。以后的过程:合并运行。
-
of runs merged at a time depends on B, and block size. #一次合并的运行次数取决于B和块大小。
- Larger block size means less I/O cost per page. 较大的块大小意味着每页的I/O成本较低。
- Larger block size means smaller # runs merged. 较大的块大小意味着较小的#运行合并。
- In practice, # of runs rarely more than 2 or 3. 在实践中#的运行次数很少超过2或3次。
- Choice of internal sort algorithm may matter: 选择内部排序算法可能很重要:
- Quicksort: Quick! 快速排序:快!
- Heap/tournament sort 堆/锦标赛排序
- The best sorts are wildly fast: 最好的排序非常快:
- Despite 40+ years of research, still improving!
- Clustered B+ tree is good for sorting; unclustered tree is usually very bad. 聚簇B+树有利于排序;非聚簇的树通常很糟糕。
lec7 Hash-Based Indexes
Introduction 介绍
- As for any index, 3 alternatives for data entries k*: 对于任何索引,数据项k*有3个备选方案
- Data record with key value k 具有键值k的数据记录
- Choice orthogonal to the indexing technique 与索引技术正交的选择
- Hash-based indexes are best for equality selections. Cannot support range searches. 基于哈希的索引最适合于相等选择。无法支持范围搜索。
- Static and dynamic hashing techniques exist; trade-offs similar to ISAM vs. B+ trees. 存在静态和动态哈希技术;类似于ISAM与B+树的权衡。
Static Hashing 静态哈希
P278
- The number of primary pages is fixed. 主页面的数量是固定的。
- Primary pages are allocated sequentially, never de-allocated; 主页面按顺序分配,从不取消分配;
- overflow pages if needed. 如果需要,创建溢出页面。
- h(k) mod N = bucket to which data entry with key k belongs. (N = number of buckets) h(k)mod N=带有k键的数据输入所属的存储桶。(N=桶的数量)

- Buckets contain data entries. 桶包含数据条目。
- Hash function works on search key field of record r. Must distribute values over range 0 … N-1. 哈希函数作用于记录r的搜索键字段。必须将值分布在范围0 … N-1上。
- h(key) = (a * key+ b) usually works well. h(key) = (a * key+ b)通常工作正常。
- a and b are constants; lots known about how to tune h. a和b是常数;很多知道如何调整h。
- Long overflow chains can develop and degrade performance. 长溢出链可能会伸长并降低性能。
- Extendible and Linear Hashing: Dynamic techniques to fix this problem. 可扩展和线性哈希:解决此问题的动态技术。
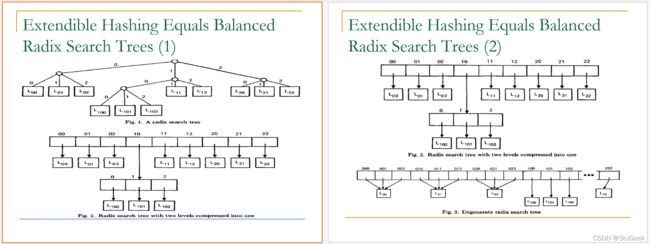
Extendible Hashing 可扩展哈希
P279
- Situation: Bucket (primary page) becomes full. Why not re-organize file by doubling the number of buckets? 情况:存储桶(主页)已满。为什么不通过加倍存储桶的数量来重新组织文件?
- Reading and writing all pages is expensive! 读和写所有页面都很昂贵!
- Idea of Extendible Hashing: 可扩展哈希的概念:
- Use directory of pointers to buckets, double the number of buckets by doubling the directory, 使用指向存储桶的指针目录,通过加倍目录将存储桶的数量加倍,
- splitting just the bucket that overflowed! 将满溢的桶分开!
- Directory is much smaller than file, so doubling it is much cheaper. 目录比文件小得多,所以翻倍要便宜得多。
- Only one page of data entries is split. No overflow page! 只拆分一页数据条目。没有溢出页面!
- Trick lies in how hash function is adjusted! 诀窍在于如何调整哈希函数!
例子
P279

Points to Note
- 20 = binary 10100. Last 2 bits (00) tell us r belongs in A or A2. Last 3 bits needed to tell which. 最后2位(00)告诉我们r属于A或A2。最后3位告诉属于哪个
- Global depth of directory: Max number of bits needed to tell which bucket an entry belongs to. 全局目录深度:告诉条目属于哪个bucket所需的最大位数。
- Local depth of a bucket: number of bits used to determine if an entry belongs to this bucket. 桶的局部深度:用于确定条目是否属于该桶的位数。
- When does bucket split cause directory doubling? 什么时候桶分裂会导致目录加倍
- Before insert, local depth of bucket = global depth. Insert causes local depth to become > global depth. 插入前,桶的局部深度=全局深度。插入使桶的局部深度大于全局深度。
目录翻倍

Equality Search in Extendible Hashing 可扩展哈希中的相等搜索
P283
- If directory fits in memory, equality search answered with one disk access; else two. 若目录在内存中,等值选择能在一次磁盘访问中完成;另外两点
- 100MB file, 100 bytes/rec, 4K pages contains 1,000,000 records (as data entries) and 25,000 directory elements; 100MB文件,每个数据项是100字节,4KB大小的页面包含1000000条记录(作为数据项)和25000个目录元素
- chances are high that directory will fit in memory. 目录很有可能放入内存中。
Delete in Extendible Hashing 可扩展哈希中的删除
P282
- If removal of data entry makes a bucket empty, the bucket can be merged with its `split image’. 如果删除数据条目使桶为空,则该桶可以与其“分裂映像”合并。
- If each directory element points to same bucket as its split image, we can halve the directory. 如果每个目录元素指向与其分裂映像相同的桶,我们可以将目录减半。
Linear Hashing (LH) 线性哈希
P283
- This is another dynamic hashing scheme, an alternative to Extendible Hashing. 这是另一个动态哈希方案,是可扩展哈希的替代方案。
- LH handles the problem of long overflow chains without using a directory, and handles duplicates. LH在不使用目录的情况下处理长溢出链的问题,并处理重复的溢出链。
- What problem will duplicates cause in Extendible Hashing? 在可扩展散列中,重复会导致什么问题?
The Idea of Linear Hashing 线性哈希的想法
P283
- Use a family of hash functions h0, h1, h2, …, where hi+1 doubles the range of hi (similar to directory doubling) 利用哈希函数h0, h1, h2, …的家族,其特性是每个函数的区间都是它前辈的两倍
- hi(key) = h(key) mod (2iN); N = initial # buckets 哈希函数h,桶的初始数N
- h is some hash function (range is not 0 to N-1)
- If N = 2^d0, for some d0, hi consists of applying h and looking at the last di bits, where di = d0 + i. 可以应用h,察看后di位,其中d0是表达N需要的位数,并且di = d0 + i
- Directory avoided in LH by using overflow pages, and choosing bucket to split round-robin. 在LH中使用溢出页并选择痛来拆分循环,从而避免了目录。
- Splitting proceeds in `rounds’. 将过程分成“轮”
- Round ends when all NR initial (for round R) buckets are split. 当所有NR初始(第R轮)桶分裂时,每一轮结束
- Buckets 0 to Next-1 have been split; Next to NR yet to be split. 桶0到Next-1已拆分;Next-1到NR尚未分裂。
- Current round number is Level. 当前轮数为计数


Bucket Split 桶分裂
P284
- A split can be triggered by 分裂可以通过以下方式触发
- the addition of a new overflow page 添加新的溢出页
- conditions such as space utilization 空间利用率的条件限制
- Whenever a split is triggered, 无论何时分裂被触发
- the Next bucket is split, Next指向的桶将被分裂
- and hash function hLevel+1 redistributes entries between this bucket (say bucket number b) and its split image; 哈希函数hLevel+1将在该桶(设桶号为b)和它的分裂映像之间重新分布项
- the split image is therefore bucket number b+NLevel. 因此,分裂映像的桶号是b+NLevel
- Next <- Next + 1. 分裂完一个桶后,Next的值加一
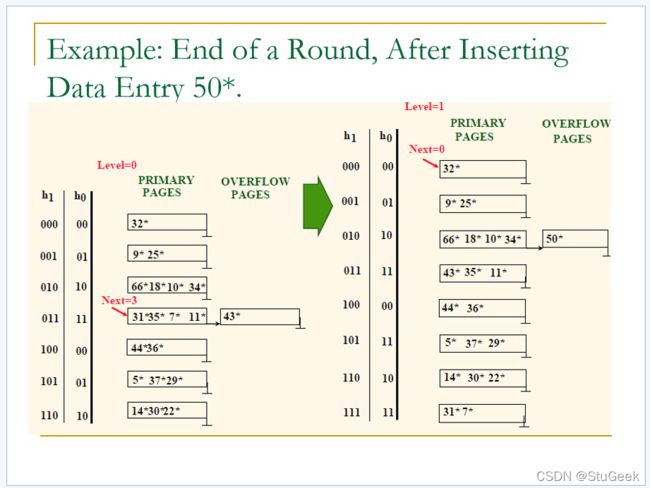
线性哈希例子
P284


Extendible VS. Linear Hashing 可扩展哈希和线性哈希对比
- Imagine that we also have a directory in LH with elements 0 to N-1. 假设在LH中有一个目录,其中包含元素0到N-1。
- The first split is at bucket 0, and so we add directory element N. 第一次分裂在桶0处,因此添加了目录元素N。
- Imagine directory being doubled at this point, but elements <1,N+1>, <2,N+2>, … are the same. So, we can avoid copying elements from 1 to N-1. 设想目录在这一点上翻了一番,但是元素<1,N+1>,<2,N+2>,…都是一样的。因此,我们可以避免将元素从1复制到N-1。
- We process subsequent splits in the same way, 以同样的方式处理后续拆分,
- And at the end of the round, all the orginal N buckets are split, and the directory is doubled in size. 在这一轮结束时,所有原始的N个桶都被拆分,目录的大小增加了一倍。
- i.e., LH doubles the imaginary directory gradually. LH逐渐将虚拟目录加倍
Summary 总结
- Hash-based indexes: best for equality searches, cannot support range searches. 基于哈希的索引:最适合等值搜索,不支持范围搜索。
- Static Hashing can lead to long overflow chains. 静态哈希可能导致长溢出链。
- Extendible Hashing avoids overflow pages by splitting a full bucket when a new data entry is to be added to it. 可扩展哈希通过在添加新数据项时分裂一个完整的桶来避免溢出页面。
- Linear Hashing avoids directory by splitting buckets round-robin, and using overflow pages. 线性哈希通过循环分割存储桶和使用溢出页来避免目录
lec8 Implementation of Relational Operations 关系操作的实现
Introduction
- Next topic: QUERY PROCESSING 下一个主题:查询处理
- Some database operations are EXPENSIVE 有些数据库操作很昂贵
- Huge performance gained by being “smart” “聪明”带来的巨大业绩
- We’ll see 1,000,000x over naïve approach
- Main weapons are:
- clever implementation techniques for operators 运算符的巧妙实现技术
- exploiting relational algebra “equivalences” 利用关系代数的“等价性”
- using statistics and cost models to choose 使用统计数据和成本模型进行选择
Simple SQL Refresher 简单SQL复习
SELECT
FROM
WHERE
SELECT S.name, E.cid
FROM Students S, Enrolled E
WHERE S.sid=E.sid AND E.grade='A'
A Really Bad Query Optimizer 一个非常糟糕的查询优化器
- For each Select-From-Where query block 对于每个Select-From-Where查询块
- Create a plan that: 创建一个计划
- Forms the cross product of the FROM clause 形成FROM子句的叉积
- Applies the WHERE clause 应用WHERE子句
- Create a plan that: 创建一个计划
- (Then, as needed: 然后,根据需要:
- Apply the GROUP BY clause 应用GROUP BY子句
- Apply the HAVING clause 应用HAVING子句
- Apply any projections and output expressions 应用任何投影和输出表达式
- Apply duplicate elimination and/or ORDER BY) 应用重复消除和/或ORDER BY

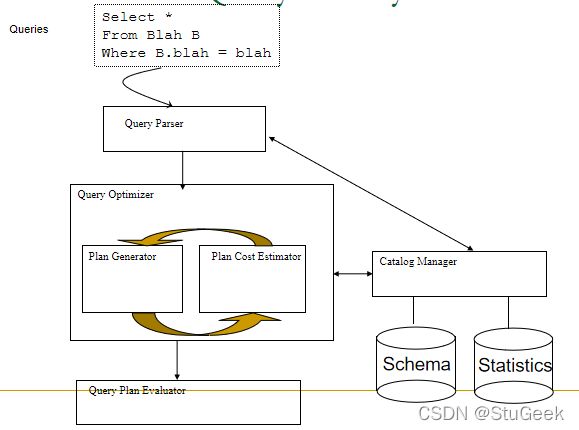
Cost-based Query Sub-System 基于成本的查询子系统
The Query Optimization Game 查询优化博弈
- Goal is to pick a “good” plan 目标是选择一个“好”的计划
- Good = low expected cost, under cost model 良好=低预期成本,低于成本模型
- Degrees of freedom: 自由度
- access methods 访问方法
- physical operators 物理操作员
- operator orders 操作员命令
- Roadmap for this topic: 本主题的路线图:
- First: implementing individual operators 首先:实现单个操作符
- Then: optimizing multiple operators 然后:优化多个操作符
Relational Operations 关系操作
- We will consider how to implement:
- Selection ( σ ) Select a subset of rows. 选择行的子集
- Projection ( π ) 投影 Remove unwanted columns. 移除不需要的列
- Join ( × ) Combine two relations. 联合两个关系
- Set-difference ( − ) Tuples in reln. 1, but not in reln. 2.
- Union ( ∪ ) 并表 Tuples in reln. 1 and in reln. 2.
- Q: What about Intersection?
Schema for Examples 模式例子
P329
Sailors (sid: integer, sname: string, rating: integer, age: real)
Reserves (sid: integer, bid: integer, day: dates, rname: string)
- Sailors: 水手
- Each tuple is 50 bytes long, 80 tuples per page, 500 pages. 每个元组50字节,每一页可以容纳80个Reserves元组,共有500个这样的页
- [S]=500, pS=80.
- Reserves: 预约
- Each tuple is 40 bytes, 100 tuples per page, 1000 pages. 每个元组40字节,每一页可以容纳100个Reserves元组,共有1000个这样的页
- [R]=1000, pR=100.
Simple Selections 简单选择
P329

- How best to perform? Depends on: 怎样最好的执行?取决于:
- what indexes are available 有哪些索引可用
- expected size of result 预期结果大小
- Size of result approximated as 结果的大小近似为
(size of R) * selectivity (R的大小)*选择性 - selectivity estimated via statistics – we will discuss shortly. 通过统计数据估计的选择性–我们将很快讨论。
Our options … 我们的选择
P329
- If no appropriate index exists: 如果不存在适当的索引:
Must scan the whole relation 必须扫描整个关系 - cost = [R]. For “reserves” = 1000 I/Os. 成本=[R]。对于“reserves”=1000 I/O。
P331
- With index on selection attribute: 在选择属性上使用索引:
-
- Use index to find qualifying data entries 使用索引查找符合条件的数据项
-
- Retrieve corresponding data records 检索相应的数据记录
-
- Total cost = cost of step 1 + cost of step 2 总成本=步骤1的成本+步骤2的成本
- For “reserves”, if selectivity = 10% (100 pages, 10000 tuples): 对于“reserves”,如果选择性=10%(100页,10000元组):
- If clustered index, cost is a little over 100 I/Os; 如果使用聚簇索引,则成本略高于100 I/O;
- If unclustered, could be up to 10000 I/Os! … unless … 如果使用非聚簇索引,则可能到达有10000个I/O…除非…

Refinement for unclustered indexes 非聚簇索引的优化
- Find qualifying data entries. 查找符合条件的数据条目。
- Sort the rids of the data records to be retrieved. 对要检索的数据记录的RID进行排序。
- Fetch rids in order. 按顺序取出RID
Each data page is looked at just once (though # of such pages likely to be higher than with clustering). 每个数据页只被查看一次(尽管这些页面中的#个可能比使用聚簇时要高
General Selection Conditions 一般的选择条件
P331
(day<8/9/94 AND rname=‘Paul’) OR bid=5 OR sid=3
- First, convert to conjunctive normal form (CNF): 首先,转换为合取范式
- (day<8/9/94 OR bid=5 OR sid=3 ) AND (rname=‘Paul’ OR bid=5 OR sid=3)
- We only discuss the case with no ORs 我们只讨论这个没有or的例子
- Terminology: 术语
- A B-tree index matches terms that involve only attributes in a prefix of the search key. e.g.: B树索引匹配只涉及搜索键前缀中属性
- Index on
上的索引匹配a=5和b=3,但不匹配b=3。
2 Approaches to General Selections 一般选择的2种方法
Approach I: 方法一
-
- Find the cheapest access path 找到最便宜的访问路径
-
- retrieve tuples using it 使用它检索元组
-
- Apply any remaining terms that don’t match the index 应用与索引不匹配的任何剩余术语
Cheapest access path: An index or file scan that we estimate will require the fewest page I/Os. 最便宜的访问路径:我们估计需要最少页面I/O的索引或文件扫描。
Cheapest Access Path - Example 花费最少的访问路径 - 例子
P332
query: day < 8/9/94 AND bid=5 AND sid=3
some options:
B+tree index on day; check bid=5 and sid=3 afterward. 利用属性域day上的B+树索引,找出满足条件的元组标识
hash index on
How about a B+tree on
How about a B+tree on
How about a Hash index on
Approach II: use 2 or more matching indexes. 方法二:使用2个或更多匹配索引。
-
- From each index, get set of rids 从每个索引中,获取一组RID
-
- Compute intersection of rid sets 计算rid集的交集
-
- Retrieve records for rids in intersection 检索交集中RID的记录
-
- Apply any remaining terms 适用任何剩余项
EXAMPLE: day<8/9/94 AND bid=5 AND sid=3
- Suppose we have an index on day, and another index on sid. 假设在day有一个索引,在sid上有另一个索引。
- Get rids of records satisfying day<8/9/94. 获取满足日期<8/9/94的记录的RID。
- Also get rids of records satisfying sid=3. 还要获取满足sid=3的记录的RID。
- Find intersection, then retrieve records, then check bid=5. 找到交集,然后检索记录,然后检索bid=5。
Projection 投影
P334
SELECT DISTINCT
R.sid, R.bid
FROM Reserves R
- Issue is removing duplicates. 问题是删除重复项
- Use sorting!! 使用排序
-
- Scan R, extract only the needed attributes 扫描R,仅提取所需的属性
-
- Sort the resulting set 对结果集进行排序
-
- Remove adjacent duplicates 删除相邻的重复项
- Cost: 费用
- Ramakrishnan/Gehrke writes to temp table at each step! 在每一步都写入临时表
- Reserves with size ratio 0.25 = 250 pages. 大小比为0.25的Reserves=250页
- With 20 buffer pages can sort in 2 passes, so: 1000 +250 + 2 * 2 * 250 + 250 = 2500 I/Os 由于有20个缓冲页,可以在2个过程中进行排序,因此:1000+250+22250+250=2500 I/O
-
Projection – improved 投影 – 优化
P335
- Avoid the temp files, work on the fly: 避免临时文件,动态工作
- Modify Pass 0 of sort to eliminate unwanted fields. 优化第0趟以消除不需要的字段。
- Modify Passes 1+ to eliminate duplicates. 优化第1趟以消除重复项。
- Cost:
- Reserves with size ratio 0.25 = 250 pages.
- With 20 buffer pages can sort in 2 passes, so:
-
- Read 1000 pages
-
- Write 250 (in runs of 40 pages each) = 7 runs
-
- Read and merge runs (20 buffers, so 1 merge pass!) 读取和合并run
-
- Total cost = 1000 + 250 +250 = 1500.
Other Projection Tricks
P337
- If an index search key contains all wanted attributes: 如果索引搜索键包含所有需要的属性
- Do index-only scan 只扫描索引
- Apply projection techniques to data entries (much smaller!) 将投影技术应用于数据条目(小得多!)
- Do index-only scan 只扫描索引
- If a B+Tree index search key prefix has all wanted attributes: 如果B+树索引搜索键前缀具有所有需要的属性
- Do in-order index-only scan 按顺序只进行索引扫描
- Just retrieve the data entries in order; 只需按顺序检索数据条目
- Discarding unwanted fields; 丢弃不需要的字段
- Compare adjacent tuples on the fly to check for duplicates. 动态比较相邻元组以检查重复项
- Do in-order index-only scan 按顺序只进行索引扫描
Joins 连接
P338
SELECT *
FROM Reserves R1, Sailors S1
WHERE R1.sid=S1.sid
- Joins are very common. 连接非常常见
- R x S is large; so, R x S followed by a selection is inefficient. 后跟一个选择是低效的
- Many approaches to reduce join cost. 许多降低连接成本的方法
- Join techniques we will cover today:
-
- Nested-loops join 嵌套循环连接
-
- Index-nested loops join 索引嵌套循环连接
-
- Sort-merge join 排序合并连接
-

Block Nested Loops Join 块嵌套循环连接
P339




Hash-Join 哈希连接
P345
Memory Requirements of Hash-Join 对内存的需求
P346
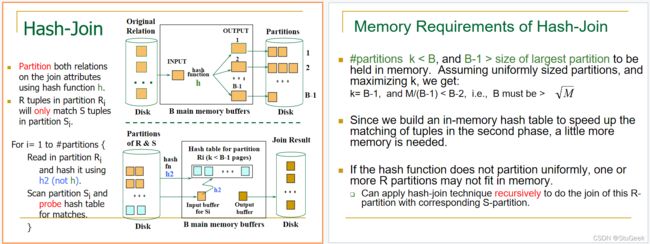
Cost of Hash-Join 哈希连接的花费
- In partitioning phase, read+write both relns; 2(M+N). In matching phase, read both relns; M+N I/Os. 在分区阶段,读+写两个reln;2(M+N)。在匹配阶段,读取两个reln;M+N I/O。
- In our running example, this is a total of 4500 I/Os. 在我们正在运行的示例中,总共有4500个I/O。
- Sort-Merge Join vs. Hash Join: 排序合并连接与哈希连接:
- Given a minimum amount of memory (what is this, for each?) both have a cost of 3(M+N) I/Os. Hash Join superior if relation sizes differ greatly (e.g., if one reln fits in memory). Also, Hash Join shown to be highly parallelizable. 给定最小内存量(这是什么,每一个?)两者都有3(M+N)I/O的成本。如果关系大小差异很大(例如,如果内存中有一个reln),则哈希连接优于其他连接。此外,哈希连接显示出高度的可并行性。
- Sort-Merge less sensitive to data skew; result is sorted. 排序合并对数据倾斜不太敏感;结果已排序。
Set Operations 集合操作
P349
- Intersection and cross-product as special cases of join. 交集和叉积作为连接的特例
- Union (Distinct) and Except similar; we’ll do union.
- Sorting based approach to union: 基于排序的联合方法
- Sort both relations (on combination of all attributes). 对两个关系进行排序(根据所有属性的组合)
- Scan sorted relations and merge them. 扫描已排序的关系并合并它们
- Alternative: Merge runs from Pass 0 for both relations. 备选方案:合并从两个关系的第0趟运行
- Hash based approach to union: 基于哈希的联合方法
- Partition R and S using hash function h. 使用哈希函数h划分R和S
- For each S-partition, build in-memory hash table (using h2), scan corresponding R-partition and add tuples to table while discarding duplicates. 对于每个S分区,构建内存哈希表(使用h2),扫描相应的R分区并向表中添加元组,同时丢弃重复的元组。
General Join Conditions 一般连接条件
P348
- Equalities over several attributes (e.g., R.sid=S.sid AND R.rname=S.sname): 多个属性上的等式(例如,R.sid=S.sid和R.rname=S.sname):
- For Index NL, build index on
上构建索引(如果S是内部的);或者使用sid或sname上的现有索引。 - For Sort-Merge and Hash Join, sort/partition on combination of the two join columns. 对于排序合并和哈希连接,根据两个连接列的组合进行排序/分区。
- For Index NL, build index on
- Inequality conditions (e.g., R.rname < S.sname): 不等式条件
- For Index NL, need (clustered!) B+ tree index. 对于索引NL,需要(聚簇!)B+树索引。
- Range probes on inner; # matches likely to be much higher than for equality joins. 在内部探查范围;#匹配可能远高于相等连接的匹配
- Hash Join, Sort Merge Join not applicable! 哈希联接、排序合并联接不适用!
- Block NL quite likely to be the best join method here. 块NL很可能是这里最好的连接方法。
- For Index NL, need (clustered!) B+ tree index. 对于索引NL,需要(聚簇!)B+树索引。
Aggregate Operations (AVG, MIN, etc.) 聚集操作(平均值、最小值等)
P350
Example:
SELECT AVG(S.age)
FROM Sailors S
- Without grouping: 不分组
- In general, requires scanning the relation. 通常,需要扫描关系
- Given a tree index whose search key includes all attributes in the SELECT or WHERE clauses, can do index-only scan. 给定一个树索引,其搜索键包含SELECT或WHERE子句中的所有属性,则只能执行索引扫描。
- With grouping: 分组
- Sort on group-by attributes, then scan relation and compute aggregate for each group. (Better: combine sorting and aggregate computation.) 按属性分组排序,然后扫描关系并计算每个组的聚合。(更好:将排序和聚合计算结合起来。)
- Similar approach based on hashing on group-by attributes. 类似的方法基于按属性分组的哈希。
- Given a tree index whose search key includes all attributes in SELECT, WHERE and GROUP BY clauses, can do index-only scan; 给定一个树索引,其搜索键包括SELECT、WHERE和GROUP BY子句中的所有属性,则只能进行索引扫描;
- if group-by attributes form prefix of search key, can retrieve data entries/tuples in group-by order. 若按属性分组形成搜索键的前缀,则可以按顺序分组检索数据项/元组。
Summary 总结
- Queries are composed of a few basic operators; 查询由几个基本运算符组成
- The implementation of these operators can be carefully tuned (and it is important to do this!). 可以仔细调整这些操作符的实现(这一点很重要!)
- Many alternative implementation techniques for each operator; no universally superior technique for most. 针对每个操作符的许多替代实施技术;对于大多数来说,没有普遍优越的技术
- Must consider alternatives for each operation in a query and choose best one based on statistics, etc. 必须考虑查询中的每个操作的备选方案,并基于统计等选择最佳操作
- This is part of the broader task of Query Optimization, which we will cover next! 这是查询优化这一更广泛任务的一部分,我们将在下一步介绍它
lec9 Relational Query Optimization 关系查询优化
Query Optimization Overview
- Query can be converted to relational algebra 查询可以转换为关系代数
- Relational Algebra converts to tree, joins form branches 关系代数转换为树,连接形成分支
- Each operator has implementation choices 每个操作符都有实现选项
- Operators can also be applied in different order! 运算符也可以按不同顺序应用!

- Plan: Tree of Relation Algebra operations (and some others) with choice of algorithm for each operation. 计划:关系代数操作树(以及其他一些操作),为每个操作选择算法。
- Three main issues: 三个主要问题:
- For a given query, what plans are considered? 对于给定的查询,考虑哪些计划?
- How is the cost of a plan estimated? 如何估算计划的成本?
- How do we “search” in the “plan space”? 我们如何在“计划空间”中“搜索”?
- Ideally: Want to find best plan. 理想情况下:想找到最好的计划。
- Reality: Avoid worst plans! 现实:避免最糟糕的计划!
Cost-based Query Sub-System 基于花费的查询子系统
Usually there is a heuristics-based rewriting step before the cost-based steps. 通常在基于成本的步骤之前有一个基于启发式的重写步骤。

Schema for Examples 模式实例
Sailors (sid: integer, sname: string, rating: integer, age: real)
Reserves (sid: integer, bid: integer, day: dates, rname: string)
- Reserves: 预约
- Each tuple is 40 bytes long, 100 tuples per page, 1000 pages.
- Assume there are 100 boats 每个元组40字节,每一页可以容纳100个Reserves元组,共有1000个这样的页
- Sailors: 水手
- Each tuple is 50 bytes long, 80 tuples per page, 500 pages.
- Assume there are 10 different ratings 每个元组50字节,每一页可以容纳80个Reserves元组,共有500个这样的页
- Assume we have 5 pages in our buffer pool! 假设缓冲池中有5个页面!
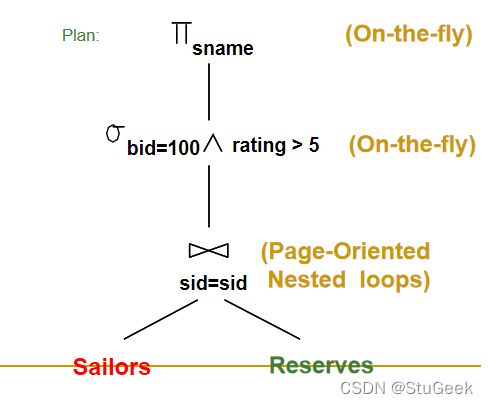
Motivating Example
SELECT S.sname
FROM Reserves R, Sailors S
WHERE R.sid=S.sid AND
R.bid=100 AND S.rating>5
- Cost: 500+500*1000 I/Os
- By no means the worst plan!
- Misses several opportunities:
- selections could be`pushed’ down
- no use made of indexes
- Goal of optimization: Find faster plans that compute the same answer.
Alternative Plans – Push Selects (No Indexes)



Summing up 总结
- There are lots of plans 有很多计划
- Even for a relatively simple query 即使是相对简单的查询
- People tend to think they can pick good ones by hand 人们倾向于认为他们可以q亲手挑选好的
- MapReduce is based on that assumption MapReduce就是基于这个假设
- Not so clear that’s true! 不太清楚那是真的!
- Machines are better at enumerating options than people 机器比人更擅长列举选项
- But we will see soon how optimizers make simplifying assumptions 但我们很快就会看到优化器如何简化假设
What is Needed for Optimization? 优化需要什么
- A closed set of operators 闭合操作符集
- Relational ops (table in, table out) 关系操作(表输入、表输出)
- Encapsulation (e.g. based on iterators) 封装(例如,基于迭代器)
- Plan space 规划空间
- Based on relational equivalences, different implementations 基于关系等价性,不同的实现
- Cost Estimation, based on 成本估算,基于
- Cost formulas 成本公式
- Size estimation, in turn based on 尺寸估算,依次基于
- Catalog information on base tables 基表上的目录信息
- Selectivity (Reduction Factor) estimation 选择性(折减系数)估算
- A search algorithm: To sift through the plan space and find lowest cost option! 一个搜索算法:在计划空间中筛选并找到成本最低的选项!
Query Optimization 优化查询
- Will focus on “System R” (Selinger) style optimizers 将重点关注“System R”(Selinger)风格的优化器
Highlights of System R Optimizer R系统优化器的亮点
- Impact:
- Most widely used currently; works well for 10-15 joins. 目前使用最广泛;适用于10-15个连接。
- Cost estimation: 成本估算:
- Very inexact, but works OK in practice. 非常不精确,但在实践中效果良好。
- Statistics in system catalogs used to estimate cost of operations and result sizes. 用于估计操作成本和结果大小的系统目录中的统计信息。
- Considers combination of CPU and I/O costs. 考虑CPU和I/O成本的组合。
- System R’s scheme has been improved since that time. 自那时以来,System R的方案得到了改进。
- Plan Space: Too large, must be pruned. 计划空间:太大,必须修剪。
- Many plans share common, “overpriced” subtrees 许多计划共享共同的“价格过高”子树
- ignore them all! 别理他们!
- In some implementations, only the space of left-deep plans is considered. 在一些实现中,只考虑左深平面的空间。
- Cartesian products avoided in some implementations. 在某些实现中避免使用笛卡尔积。
- Many plans share common, “overpriced” subtrees 许多计划共享共同的“价格过高”子树
Query Blocks: Units of Optimization 查询块:优化单元
- Break query into query blocks 将查询分解为查询块
- Optimized one block at a time 一次优化一个块
- Uncorrelated nested blocks computed once 一次计算的不相关嵌套块
- Correlated nested blocks like function calls 相关嵌套块,如函数调用
- But sometimes can be “decorrelated” 但有时可能是“不相关的”
- Beyond the scope of introductory course! 超出介绍课程的范围!
- For each block, the plans considered are: 对于每个块,考虑计划为
- All available access methods, for each relation in FROM clause. FROM子句中每个关系的所有可用访问方法。
- All left-deep join trees 所有左深连接树
- right branch always a base table 右分支始终是基表
- consider all join orders and join methods 考虑所有连接顺序和连接方法

Schema for Examples
Sailors (sid: integer, sname: string, rating: integer, age: real)
Reserves (sid: integer, bid: integer, day: dates, rname: string)
- Reserves: 预约
- Each tuple is 40 bytes long, 100 tuples per page, 1000 pages. 100 distinct bids. 每个元组40字节,每一页可以容纳100个Reserves元组,共有1000个这样的页,100个独立的bid
- Sailors: 水手
- Each tuple is 50 bytes long, 80 tuples per page, 500 pages. 10 ratings, 40,000 sids. 每个元组50字节,每一页可以容纳80个Reserves元组,共有500个这样的页,40000个dis
Translating SQL to Relational Algebra 将SQL翻译为关系代数
P359

Relational Algebra Equivalences 关系代数等式
- Allow us to choose different join orders and to `push’ selections and projections ahead of joins. 允许我们选择不同的连接顺序,并在连接之前“推送”选择和投影。

More Equivalences 更多等式
- A projection commutes with a selection that only uses attributes retained by the projection. 投影与仅使用投影保留的属性的选择进行转换。
- Selection between attributes of the two arguments of a cross-product converts cross-product to a join. 在叉积的两个参数的属性之间进行选择将叉积转换为连接。

Cost Estimation 花费估计
P360
- For each plan considered, must estimate total cost: 对于考虑的每个计划,必须估算总成本:
- Must estimate cost of each operation in plan tree. 必须在计划树中估计每个操作的成本。
- Depends on input cardinalities. 取决于输入基数。
- We’ve already discussed this for various operators 我们已经为不同的运算符讨论过这个问题
- sequential scan, index scan, joins, etc. 顺序扫描、索引扫描、连接等。
- Must estimate size of result for each operation in tree! 必须估计树中每个操作的结果大小!
- Use information about the input relations. 使用有关输入关系的信息
- For selections and joins, assume independence of predicates. 对于选择和连接,假设谓词独立
- In System R, cost is boiled down to a single number consisting of #I/O + CPU-factor * #tuples 在System R中,成本被归结为一个由#I/O+CPU因子*#元组组成的单个数字
- Must estimate cost of each operation in plan tree. 必须在计划树中估计每个操作的成本。
- Q: Is “cost” the same as estimated “run time”? 问:“成本”与估计的“运行时间”相同吗?

P362

P366

P370




Summary 总结
- Optimization is the reason for the lasting power of the relational system 优化是关系系统持久强大的原因
- But it is primitive in some ways 但它在某些方面是原始的
- New areas: many! 新领域:很多!
- Smarter summary statistics (fancy histograms and “sketches”) 更智能的汇总统计(精美的直方图和“草图”)
- Auto-tuning statistics, 自动调整统计信息,
- Adaptive runtime re-optimization (e.g. eddies), 自适应运行时重新优化(例如涡流),
- Multi-query optimization, 多查询优化,
- And parallel scheduling issues, etc. 以及并行调度问题等。
lec9 Physical DB Design 物理数据库设计
Physical DB Design
P483
- Query optimizer does what it can to use indices, clustering etc. 查询优化器尽其所能使用索引、聚簇等。
- DataBase Administrator (DBA) is expected to set up physical design well. 数据库管理员(DBA)应做好物理设计。
- Good DBAs understand query optimizers very well. 优秀的DBA非常了解查询优化器。
One Key Decision: Indexes 一个关键决定:索引
P485
- Which tables 哪些表格
- Which field(s) should be the search key? 哪些字段应为搜索关键字?
- Multiple indexes? 多重索引?
- Clustering? 聚簇?
Index Selection 索引选择
- One approach: 一种方法:
- Consider most important queries in turn. 依次考虑最重要的查询。
- Consider best plan using the current indexes 使用当前索引考虑最佳方案
- See if better plan is possible with an additional index. 看看是否有可能用一个额外的索引来制定更好的计划。
- If so, create it. 如果是这样,创建它。
- But consider impact on updates! 但是考虑更新的影响!
- Indexes can make queries go faster, updates slower. 索引可以使查询更快,更新更慢。
- Require disk space, too. 也需要磁盘空间。
Issues to Consider in Index Selection 索引选择中应考虑的几个问题
- Attributes mentioned in a WHERE clause are candidates for index search keys. WHERE子句中提到的属性是索引搜索键的候选属性。
- Range conditions are sensitive to clustering 范围条件对聚簇很敏感
- Exact match conditions don’t require clustering 精确匹配条件不需要聚簇
- Or do they???
- Choose indexes that benefit many queries 选择有利于许多查询的索引
- NOTE: only one index can be clustered per relation! 注意:每个关系只能聚簇一个索引!
- So choose it wisely! 所以,明智地选择它!
Example 1 例子1
P486
SELECT E.ename, D.mgr
FROM Emp E, Dept D
WHERE E.dno=D.dno AND D.dname=‘Toy’
- B+ tree index on D.dname supports ‘Toy’ selection. D.dname上的B+树索引支持‘Toy’选择。
- Given this, index on D.dno is not needed. 鉴于此,不需要在D.dno上建立索引。
- B+ tree on E.dno allows us to get matching (inner) Emp tuples for each selected (outer) Dept tuple. E.dno上的B+树允许我们为每个选定的(外部)Dept元组获取匹配的(内部)Emp元组。
- What if WHERE included: `` … AND E.age=25’’ ?
- Could retrieve Emp tuples using index on E.age, then join with Dept tuples satisfying dname selection. 可以使用E.age上的索引检索Emp元组,然后与满足dname选择的Dept元组连接。
- Comparable to strategy that used E.dno index. 与使用E.dno索引的策略相当。
- So, if E.age index is already created, this query provides much less motivation for adding an E.dno index. 因此,如果已经创建了E.age索引,那么该查询就不会为添加E.dno索引提供太多动机。
- Could retrieve Emp tuples using index on E.age, then join with Dept tuples satisfying dname selection. 可以使用E.age上的索引检索Emp元组,然后与满足dname选择的Dept元组连接。
Example 2 例子2
P487
SELECT E.ename, D.mgr
FROM Emp E, Dept D
WHERE E.sal BETWEEN 10000 AND 20000
AND E.hobby=‘Stamps’ AND E.dno=D.dno
- All selections are on Emp so it should be the outer relation in any Index NL join. 所有选择都在Emp上,因此它应该是任何索引NL连接中的外部关系。
- Suggests that we build a B+ tree index on D.dno. 建议我们在D.dno上建立一个B+树索引。
- What index should we build on Emp? 应该在Emp上建立什么索引?
- B+ tree on E.sal could be used, OR an index on E.hobby could be used. 可以使用E.sal上的B+树,也可以使用E.hobby上的索引。
- Only one of these is needed, and which is better depends upon the selectivity of the conditions. 只需要其中一个,哪个更好取决于条件的选择性。
- As a rule of thumb, equality selections more selective than range selections. 根据经验,相等选择比范围选择更有选择性。
- Have to understand optimizers to get this right! 必须了解优化器才能正确使用它!
Examples of Clustering 聚簇例子
P488
SELECT E.dno
FROM Emp E
WHERE E.age>40
- B+ tree index on E.age can be used to get qualifying tuples. E.age上的B+树索引可用于获取符合条件的元组。
- How selective is the condition? 这种情况有多大的选择性?
- Is the index clustered? 索引是聚簇的吗?
SELECT E.dno, COUNT (*)
FROM Emp E
WHERE E.age>10
GROUP BY E.dno
- Consider the GROUP BY query. 考虑GROUP BY查询
- If many tuples have E.age > 10, using E.age index and sorting the retrieved tuples may be costly. 如果许多元组的E.age>10,则使用E.age索引并对检索到的元组进行排序可能代价高昂。
- Clustered E.dno index may be better! 聚簇E.dno索引可能更好!
SELECT E.dno
FROM Emp E
WHERE E.hobby=Stamps
- Equality queries and duplicates: 相等查询和重复项
- Clustering on E.hobby helps! 在E.hobby上进行聚簇有帮助!
lec10 Schema Refinement and Normal Forms 模式求精与范式
Review: Database Design 回顾:数据库设计
- Requirements Analysis 需求分析
- user needs; what must database do? 用户需求;数据库必须做什么?
- Conceptual Design 概念设计
- high level description (often done with ER model) 高级描述(通常使用ER模型完成)
- Logical Design 逻辑设计
- translate ER into DBMS data model 将ER转换为DBMS数据模型
- Schema Refinement 模式优化
- consistency, normalization 一致性、规范化
- Physical Design - indexes, disk layout 物理设计-索引、磁盘布局
- Security Design - who accesses what 安全设计-谁访问什么
The Evils of Redundancy 冗余的问题
P452
- Redundancy is at the root of several problems associated with relational schemas: 冗余性的弊端是与关系模式相关的几个问题的根源:
- redundant storage, insert/delete/update anomalies 冗余存储、插入/删除/更新异常
- Integrity constraints, in particular functional dependencies, can be used to identify schemas with such problems and to suggest refinements. 完整性约束,特别是功能依赖,可用于识别存在此类问题的模式,并提出改进建议。
- Main refinement technique: decomposition 主要细化技术:分解
- replacing ABCD with, say, AB and BCD, or ACD and ABD. 将ABCD替换为AB和BCD,或ACD和ABD
- Decomposition should be used judiciously: 应明智地使用分解
- Is there reason to decompose a relation? 有理由分解关系吗?
- What problems (if any) does the decomposition cause? 分解会导致哪些问题(如有)?
Functional Dependencies (FDs) 函数依赖
P455
- A functional dependency X -> Y holds over relation schema R if, for every allowable instance r of R: t1 ∈ r, t2 ∈ r, πX (t1) = πX (t2)
implies πY (t1) =πY (t2) R是一个关系模式,X和Y是R中的属性的两个非空子集,关系R的一个实例r - (where t1 and t2 are tuples;X and Y are sets of attributes) (其中t1和t2是元组;X和Y是属性集)
- In other words: X -> Y means
Given any two tuples in r, if the X values are the same, then the Y values must also be the same. (but not vice versa) 给定r中的任意两个元组,如果X值相同,那么Y值也必须相同。(但反之不一定) - Can read “->” as “determines” 可以将“->”翻译为“决定”
- An FD is a statement about all allowable relations. 一个函数依赖是关于所有允许关系的语句
- Must be identified based on semantics of application. 必须根据应用程序的语义进行标识
- Given some instance r1 of R, we can check if r1 violates some FD f, but we cannot determine if f holds over R. 给定R的某个实例r1,我们可以检查r1是否违反了某些函数依赖f,但我们无法确定f是否对R有效
- Question: How related to keys? 问题:和键有什么关系?
- if “K -> all attributes of R” then K is a superkey for R
(does not require K to be minimal.) 如果“K->R的所有属性”,则K是R的超键
- if “K -> all attributes of R” then K is a superkey for R
- FDs are a generalization of keys. 函数依赖是键的泛化
Example: Constraints on Entity Set 示例:实体集上的约束
- Consider relation obtained from Hourly_Emps: 考虑从Hourly_Emps得到的关系:
- Hourly_Emps (ssn, name, lot, rating, wage_per_hr, hrs_per_wk)
We sometimes denote a relation schema by listing the attributes: e.g., SNLRWH 我们有时通过列出属性来表示关系模式:例如,SNLRWH - Sometimes, we refer to the set of all attributes of a relation by using the relation name. e.g., “Hourly_Emps” for SNLRWH 有时,我们通过使用关系名称来引用关系的所有属性集。e、 例如,SNLRWH的“Hourly_Emps”
- What are some FDs on Hourly_Emps? Hourly_Emps上有哪些函数依赖:
- ssn is the key: S -> SNLRWH
- rating determines wage_per_hr: R -> W
- lot determines lot: L -> L (“trivial” dependnency)
Problems Due to R -> W 由于R决定W引起的问题

- Update anomaly: Can we modify W in only the 1st tuple of SNLRWH? 更新异常:我们可以只修改SNLRWH的第一个元组中的W吗?
- Insertion anomaly: What if we want to insert an employee and don’t know the hourly wage for his or her rating? (or we get it wrong?) 插入异常:如果我们想插入一名员工,但不知道他或她的评分的小时工资,该怎么办?(或者我们弄错了?)
- Deletion anomaly: If we delete all employees with rating 5, we lose the information about the wage for rating 5! 删除异常:如果我们删除所有评级为5的员工,我们将丢失评级为5的工资信息!
Detecting Redundancy 检测冗余

Decomposing a Relation 分解关系
- Redundancy can be removed by “chopping” the relation into pieces. 可以通过将关系“切碎”成碎片来消除冗余。
- FD’s are used to drive this process. 函数依赖用于驱动该过程。
- R -> W is causing the problems, so decompose SNLRWH into what relations? R -> W是问题的根源,因此将SNLRWH分解为什么关系?

Refining an ER Diagram by FD: Attributes Can Easily Be Associated with the “Wrong” Entitity Set in ER Design. 通过FD细化ER图:属性很容易与ER设计中的“错误”实体集相关联。
- 1st diagram becomes: Workers(S,N,L,D,Si) Departments(D,M,B)
- Lots associated with workers.
- Suppose all workers in a dept are assigned the same lot: D -> L
- Redundancy; fixed by decomposition: Workers2(S,N,D,Si) Dept_Lots(D,L) Departments(D,M,B)
- Can fine-tune this: Workers2(S,N,D,Si) Departments(D,M,B,L)

Reasoning About FDs 关于FDs的推理
- Given some FDs, we can usually infer additional FDs: 给定一些FD,我们通常可以推断出其他FD:
title -> studio, star implies title -> studio and title -> star
title -> studio and title -> star implies title -> studio, star
title -> studio, studio -> star implies title -> star - But, title, star -> studio does NOT necessarily imply that title -> studio or that star -> studio 但是 title, star -> studio 不一定能推出 title -> studio 或者 star -> studio
- An FD f is implied by a set of FDs F if f holds whenever all FDs in F hold.
- F+ = closure of F is the set of all FDs that are implied by F. (includes “trivial dependencies”)
Rules of Inference 推理规则
P456
Reflexivity:自反律
Augmentation:增补律
Transitivity:传递率
Union:合并
Decomposition:分解

















Summary of Schema Refinement 模式优化概述
- BCNF: each field contains information that cannot be inferred using only FDs. BCNF:每个字段都包含仅使用FD无法推断的信息。
- ensuring BCNF is a good heuristic. 确保BCNF是一个很好的启发。
- Not in BCNF? Try decomposing into BCNF relations. 不在BCNF?尝试分解成BCNF关系。
- Must consider whether all FDs are preserved! 必须考虑所有的FDS是否被保存!
- Lossless-join, dependency preserving decomposition into BCNF impossible? Consider 3NF. 无损连接,保持依赖性分解为BCNF不可能?考虑3NF。
- Same if BCNF decomp is unsuitable for typical queries 如果BCNF decomp不适用于典型查询,则相同
- Decompositions should be carried out and/or re-examined while keeping performance requirements in mind. 分解应进行和/或重新检查,同时牢记性能要求。
03 Database Storage Part I
OVERVIEW 概述
- We now understand what a database looks like at a logical level and how to write queries to read/write data from it. 现在,我们了解了数据库在逻辑级别的模样,以及如何编写查询以从中读取/写入数据。
- We will next learn how to build software that manages a database. 接下来我们将学习如何构建管理数据库的软件。
COURSE OUTLINE 课程大纲
Relational Databases 关系数据库
Storage 存储
Execution 执行
Concurrency Control 并发控制
Recovery 恢复
Distributed Databases 分布式数据库
Potpourri

DISK-ORIENTED ARCHITECTURE 面向磁盘的体系结构
- The DBMS assumes that the primary storage location of the database is on non-volatile disk. DBMS假定数据库的主存储位置在非易失性磁盘上。
- The DBMS’s components manage the movement of data between non-volatile and volatile storage. DBMS的组件管理非易失性和易失性存储之间的数据移动。
STORAGE HIERARCHY 存储层次结构
Volatile 易失的
Random Access 随机存取
Byte-Addressable 字节可寻址
Non-Volatile 非易失的
Sequential Access 顺序存取
Block-Addressable 块可寻址
CPU Registers CPU寄存器
CPU Caches CPU缓存
DRAM 动态随机存取存储器
SSD 固态硬盘
HDD 硬盘驱动器
Network Storage 网络存储
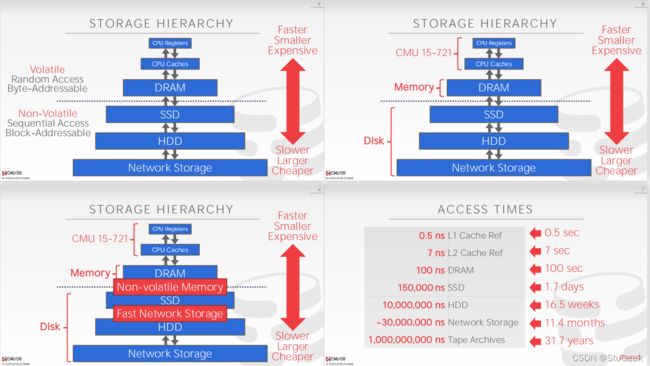
SEQUENTIAL VS. RANDOM ACCESS 顺序访问对比随机访问
Random access on non-volatile storage is usually much slower than sequential access. 非易失性存储器上的随机访问通常是比顺序访问慢得多。
DBMS will want to maximize sequential access. DBMS将希望最大化顺序访问。
→ Algorithms try to reduce number of writes to random pages so that data is stored in contiguous blocks. 算法试图减少对随机页面的写入次数,以便将数据存储在连续块中。
→ Allocating multiple pages at the same time is called an extent. 同时分配多个页面称为区段。
SYSTEM DESIGN GOALS 系统设计目标
- Allow the DBMS to manage databases that exceed the amount of memory available. 允许DBMS管理超过可用内存量的数据库。
- Reading/writing to disk is expensive, so it must be managed carefully to avoid large stalls and performance degradation. 读取/写入磁盘的成本很高,因此必须小心管理,以避免大的暂停和性能下降。
- Random access on disk is usually much slower than sequential access, so the DBMS will want to maximize sequential access. 磁盘上的随机访问通常比顺序访问慢得多,因此DBMS希望最大化顺序访问。
DISK-ORIENTED DBMS 面向磁盘的数据库管理系统

WHY NOT USE THE OS? 为什么不使用操作系统?
- One can use memory mapping (mmap) to store the contents of a file into a process’ address space. 可以使用内存映射(mmap)将文件内容存储到进程的地址空间中。
- The OS is responsible for moving data for moving the files’ pages in and out of memory 操作系统负责移动数据,以便将文件的页面移入和移出内存


- What if we allow multiple threads to access the mmap files to hide page fault stalls? 如果我们允许多个线程访问mmap文件以隐藏页面错误暂停,该怎么办?
- This works good enough for read-only access. It is complicated when there are multiple writers… 这对于只读访问来说已经足够好了。当有多个写者时,情况就复杂了…
- There are some solutions to this problem: 有一些解决此问题的方法:
- → madvise: Tell the OS how you expect to read certain pages. 告诉操作系统您希望如何阅读某些页面。
- → mlock: Tell the OS that memory ranges cannot be paged out. 告诉操作系统内存范围无法分页。
- → msync: Tell the OS to flush memory ranges out to disk. 告诉操作系统将内存范围刷新到磁盘。
- DBMS (almost) always wants to control things itself and can do a better job at it. DBMS(几乎)总是希望自己控制事情,并且可以做得更好。
- → Flushing dirty pages to disk in the correct order. 按正确顺序将脏页刷新到磁盘。
- → Specialized prefetching. 专门的预取。
- → Buffer replacement policy. 缓冲区替换策略。
- → Thread/process scheduling. 线程/进程调度。
- The OS is not your friend. 操作系统不是你的朋友。
DATABASE STORAGE 数据库存储
- Problem #1: How the DBMS represents the database in files on disk. ← Today
- Problem #2: How the DBMS manages its memory and move data back-and-forth from disk.
TODAY’S AGENDA 今天日程
- File Storage 文件存储
- Page Layout 页面布局
- Tuple Layout 元组布局
FILE STORAGE 文件存储
- The DBMS stores a database as one or more files on disk typically in a proprietary format. DBMS将数据库作为一个或多个文件存储在磁盘上,通常采用专有格式。
- → The OS doesn’t know anything about the contents of these files. 操作系统对这些文件的内容一无所知
- Early systems in the 1980s used custom filesystems on raw storage. 20世纪80年代的早期系统在原始存储上使用自定义文件系统。
- → Some “enterprise” DBMSs still support this. 一些“企业”DBMS仍然支持这个。
- → Most newer DBMSs do not do this. 大多数较新的DBMS不这样做。
STORAGE MANAGER 存储管理
- The storage manager is responsible for maintaining a database’s files. 存储管理器负责维护数据库的文件。
- → Some do their own scheduling for reads and writes to improve spatial and temporal locality of pages. 有些自己进行读写调度,以改善页面的空间和时间位置。
- It organizes the files as a collection of pages. 它将文件组织为一个页面集合。
- → Tracks data read/written to pages. 跟踪读取/写入页面的数据。
- → Tracks the available space. 跟踪可用空间。
DATABASE PAGES 数据库页面
- A page is a fixed-size block of data. 页面是一个固定大小的数据块。
- → It can contain tuples, meta-data, indexes, log records… 它可以包含元组、元数据、索引、日志记录…
- → Most systems do not mix page types. 大多数系统不会混合页面类型。
- → Some systems require a page to be self-contained. 有些系统要求页面是自包含的。
- Each page is given a unique identifier. 每个页面都有一个唯一的标识符。
- → The DBMS uses an indirection layer to map page ids to physical locations. DBMS使用间接层将页面ID映射到物理位置。
- There are three different notions of “pages” in a DBMS: DBMS中有三种不同的“页面”概念:
- → Hardware Page (usually 4KB) 硬件页面(通常为4KB)
- → OS Page (usually 4KB) 操作系统页面(通常为4KB)
- → Database Page (512B-16KB) 数据库页(512B-16KB)
- A hardware page is the largest block of data that the storage device can guarantee failsafe writes. 硬件页是存储设备能够保证故障保护写入的最大数据块。

DATABASE HEAP 数据库堆
- A heap file is an unordered collection of pages where tuples that are stored in random order. 堆文件是一个无序的页面集合,其中元组以随机顺序存储。
- → Create / Get / Write / Delete Page 创建/获取/写入/删除页面
- → Must also support iterating over all pages. 还必须支持对所有页面进行迭代。
- Two ways to represent a heap file: 表示堆文件的两种方法:
- → Linked List 链表
- → Page Directory 页面目录
- It is easy to find pages if there is only a single heap file. 如果只有一个堆文件,则很容易找到页面。
- Need meta-data to keep track of what pages exist in multiple files and which ones have free space. 需要元数据来跟踪多个文件中存在哪些页面以及哪些页面有可用空间。

HEAP FILE: LINKED LIST 堆文件:链表
- Maintain a header page at the beginning of the file that stores two
pointers: 在文件开头维护一个标题页,其中存储两个指针:- → HEAD of the free page list. 释放页面链表的的头指针
- → HEAD of the data page list. 数据页面链表的头指针
- Each page keeps track of how many free slots they currently have 每一页都记录着他们目前有多少空闲位置
- The DBMS maintains special pages that tracks the location of data pages in the database files. DBMS维护跟踪数据库文件中数据页位置的特殊页。
- The directory also records the number of free slots per page. 该目录还记录每页的可用位置数。
- The DBMS must make sure that the directory pages are in sync with the data pages. DBMS必须确保目录页与数据页同步。
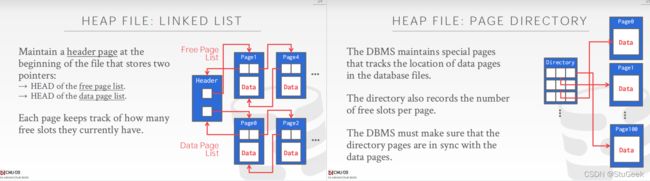
PAGE HEADER 页头部
- Every page contains a header of meta-data about the page’s contents. 每个页面都包含一个关于页面内容的元数据头部。
- → Page Size 页面大小
- → Checksum 校验和
- → DBMS Version 数据库管理系统版本
- → Transaction Visibility 事务可见性
- → Compression Information 压缩信息
- Some systems require pages to be self-contained (e.g., Oracle). 有些系统要求页面是自包含的(例如Oracle)

PAGE LAYOUT 页面布局
- For any page storage architecture, we now need to decide how to organize the data inside of the page. 对于任何页面存储体系结构,我们现在都需要决定如何组织页面内部的数据。
- → We are still assuming that we are only storing tuples. 我们仍然假设只存储元组。
- Two approaches: 两种方法:
- → Tuple-oriented 面向元组
- → Log-structured 日志结构
TUPLE STORAGE 元组存储
- How to store tuples in a page? 如何在页面中存储元组?
- Strawman Idea: Keep track of the number of tuples in a page and then just append a new tuple to the end. 斯特鲁曼的想法:跟踪页面中元组的数量,然后在末尾追加一个新元组。
- → What happens if we delete a tuple? 如果我们删除一个元组会发生什么?
- → What happens if we have a variable-length attribute? 如果我们有一个可变长度属性,会发生什么?


SLOTTED PAGES 分槽页结构
- The most common layout scheme is called slotted pages. 最常见的布局方案称为分槽页结构。
- The slot array maps “slots” to the tuples’ starting position offsets. 分槽数组将“分槽”映射到元组的起始位置偏移。
- The header keeps track of: 标题记录以下内容
- → The # of used slots 使用过的分槽的#
- → The offset of the starting location of the last slot used. 最后使用的分槽的起始位置的偏移量。


RECORD IDS 记录序号
- The DBMS needs a way to keep track of individual tuples. DBMS需要一种跟踪单个元组的方法。
- Each tuple is assigned a unique record identifier. 每个元组都分配了一个唯一的记录标识符。
- → Most common: page_id + offset/slot 最常见:页面id+偏移量/分槽
- → Can also contain file location info. 还可以包含文件位置信息
- An application cannot rely on these ids to mean anything. 应用程序不能依赖这些ID来表示任何内容

TUPLE LAYOUT 元组布局
- A tuple is essentially a sequence of bytes. 元组本质上是一个字节序列。
- It’s the job of the DBMS to interpret those bytes into attribute types and values. DBMS的工作是将这些字节解释为属性类型和值。
TUPLE HEADER 元组头部
- Each tuple is prefixed with a headerthat contains meta-data about it. 每个元组都有一个包含元数据的标题作为前缀。
- → Visibility info (concurrency control) 见性信息(并发控制)
- → Bit Map for NULL values. 空值的位映射。
- We do not need to store meta-data about the schema. 我们不需要存储关于模式的元数据。
TUPLE DATA 元组数据
- Attributes are typically stored in the order that you specify them when you create the table. 属性通常按照创建表时指定的顺序存储。
- This is done for software engineering reasons. 这是出于软件工程的原因。
- We re-order attributes automatically in CMU’s new DBMS… 在CMU的新DBMS中自动重新排序属性…

DENORMALIZED TUPLE DATA 非规格化元组数据
- Can physically denormalize (e.g., “pre join”) related tuples and store them together in the same page. 可以物理地反规格化(例如,“预连接”)相关元组,并将它们存储在同一页中。
- → Potentially reduces the amount of I/O for common workload patterns. 可能会减少常见工作负载模式的I/O量。
- → Can make updates more expensive. 可能会使更新更昂贵。
- Not a new idea. 这不是什么新主意
- → IBM System R did this in the 1970s. IBM System R 在20世纪70年代就这样做了。
- → Several NoSQL DBMSs do this without calling it physical denormalization. 一些NoSQL数据库管理系统不称之为物理非规范化,而是这样做的。

CONCLUSION 总结
- Database is organized in pages. 数据库按页面组织。
- Different ways to track pages. 跟踪页面的不同方式。
- Different ways to store pages. 存储页面的不同方式。
- Different ways to store tuples 存储元组的不同方法。
12 Query Execution
12.1 Query PlAN
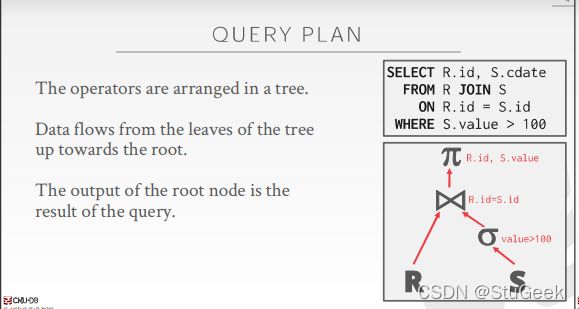
操作符被安排在一个树中。数据从树的叶向上流向根。根节点的输出是查询的结果。
12.2 Processing Models
A DBMS’s processing model defines how the system executes a query plan.
→ Different trade-offs for different workloads.
Approach #1: Iterator Model
Approach #2: Materialization Model
Approach #3: Vectorized / Batch Model
DBMS的处理模型定义了系统如何执行查询计划。
→对不同的工作负载进行不同的权衡。
方法#1:迭代器模型
方法#2:物化模型
方法#3:向量化/批量模型
12.2.1 Iterator Model 迭代器模型
Each query plan operator implements a Next function.
→ On each invocation, the operator returns either a single tuple or a null marker if there are no more tuples.
→ The operator implements a loop that calls next on its children to retrieve their tuples and then process them.
Also called Volcano or Pipeline Model.
迭代模型又称 Volcano Model 或者 Pipeline Model火山模型或管道模型。这种模型中的查询计划算子(query plan operator)都需要实现 next() 函数:
- 每次调用的时候,operator 将返回一个元组(tuple)或一个空标记(null),空标记代表数据已经遍历完;
- operator 需要实现一个循环,其调用子 operator 的
next()函数,用于从子 operator 中获取数据,然后再处理它。
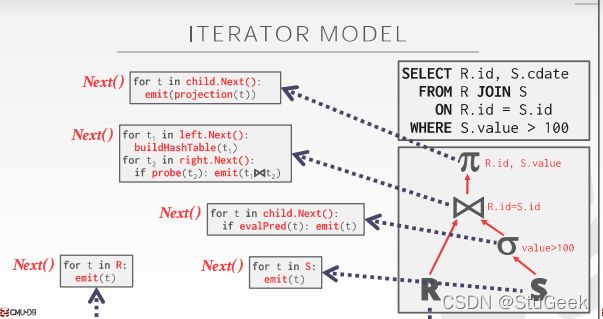
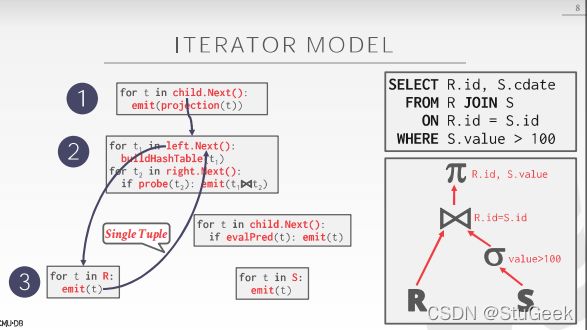
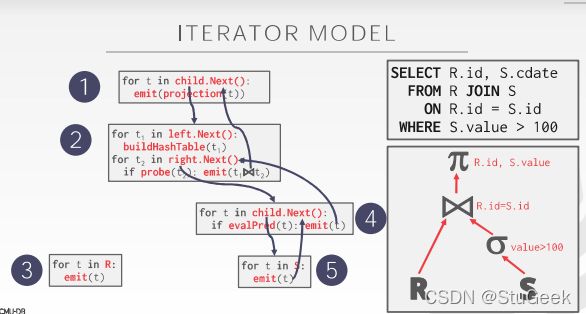
这在几乎所有的DBMS中都被使用。
迭代模型的优点是抽象起来很简单,很容易实现,而且可以通过任意组合算子来表达复杂的查询。但是缺点也很明显,存在大量的虚函数调用,会引起 CPU 的中断,最终影响了执行效率;而且 Joins, Subqueries, Order By 等操作在其子 operator 返回数据之前会被 block 住。
12.2.2 Materialization Model 物化模型
Each operator processes its input all at once and then emits its output all at once.
→ The operator “materializes” its output as a single result.
→ The DBMS can push down hints into to avoid scanning too many tuples.
→ Can send either a materialized row or a single column.
The output can be either whole tuples (NSM) or subsets of columns (DSM)
每个操作符一次处理所有的输入,然后一次发出所有的输出。
→运算符将其输出“具体化”为单个结果。
→数据库管理系统可以将提示下推,以避免扫描过多的元组。
→可以发送一个实体化行或单个列。
输出可以是整个元组(NSM)或列的子集(DSM)
**物化模型的处理方式是:**每个 operator 一次处理所有的输入,处理完之后将所有结果一次性输出。由于这种模式中的 operator 其输出“物化”为单个结果,所以称为物化模型。。
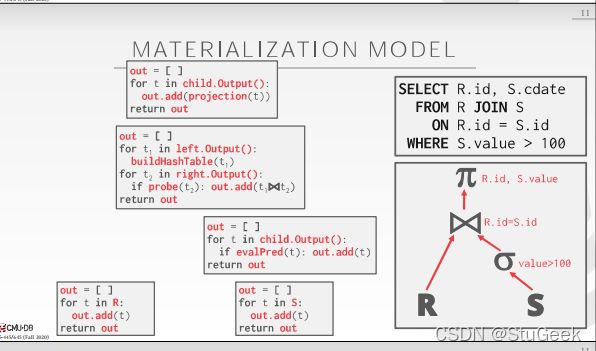


Better for OLTP workloads because queries only access a small number of tuples at a time. → Lower execution / coordination overhead.
→ Fewer function calls.
Not good for OLAP queries with large intermediate results
更适合于OLTP工作负载,因为查询一次只能访问少量的元组。
→降低执行/协调开销。
→减少函数调用。
对于具有大型中间结果的OLAP查询来说,这并不好
12.2.2 Vectorized / Batch Model 向量化/批量模型
Like the Iterator Model where each operator implements a Next function in this model.
Each operator emits a batch of tuples instead of a single tuple.
→ The operator’s internal loop processes multiple tuples at a time.
→ The size of the batch can vary based on hardware or query properties.
Vectorization Model 和 Iterator Model 类似,每个 operator 需要实现一个 next() 函数,但是每次调用 next() 函数会返回一批的元组(tuples)而不是一个元组。在 operator 内部,每次循环都会处理多个元组。批次的大小可以根据硬件或者查询数据进行配置的。可以看出Vectorization Model 是 Iterator Model 和 Materialization Model 的折衷。
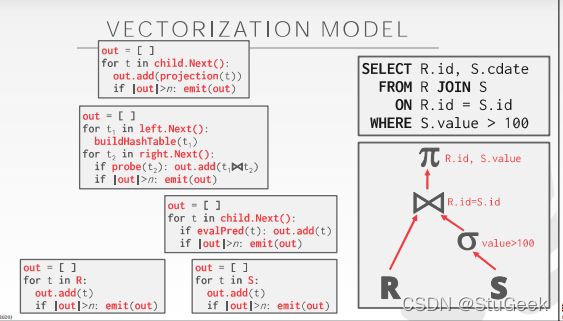

Ideal for OLAP queries because it greatly reduces the number of invocations per operator. Allows for operators to use vectorized (SIMD) instructions to process batches of tuples
Vectorization Model 比较适合 OLAP 查询,因为其大大减少了每个 operator 的调用次数,也就简单减少了虚函数的调用。而且现代编译器和 CPU 在运行简单的循环时,是非常高效的。编译器会自动展开简单的循环,甚至在每个 CPU 指令中产生 SIMD 指令来处理多个元组。
12.3 PLAN PROCESSING DIRECTION 计划处理方向
Approach #1: Top-to-Bottom
→ Start with the root and “pull” data up from its children.
→ Tuples are always passed with function calls.
Approach #2: Bottom-to-Top
→ Start with leaf nodes and push data to their parents.
→ Allows for tighter control of caches/registers in pipelines
方法# 1:自上而下
→从根开始,从它的子节点中“拉”出数据。
→元组总是通过函数调用传递。
方法# 2:自下而上
→从叶子节点开始,将数据推送给它们的父节点。
→允许对管道中的缓存/寄存器进行更严格的控制
12.4 Access Methods 访问方式;存取方法
An access method is a way that the DBMS can access the data stored in a table.
→ Not defined in relational algebra.
Three basic approaches:
→ Sequential Scan
→ Index Scan
→ Multi-Index / “Bitmap” Scan
访问方法是DBMS访问存储在表中的数据的一种方式。
→关系代数中没有定义。
三种基本方法:
→顺序扫描
→索引扫描
→多索引/“位图”扫描
12.4.1 Sequential Scan 顺序扫描

表格中每一页:
→从缓冲池中取回。
→遍历每个元组,检查是否包含它。
DBMS维护一个内部游标,跟踪它检查的最后一个页面/插槽
This is almost always the worst thing that the DBMS can do to execute a query.
Sequential Scan Optimizations:
→ Prefetching
→ Buffer Pool Bypass
→ Parallelization
→ Heap Clustering
→ Zone Maps
→ Late Materialization
这几乎总是DBMS在执行查询时所能做的最糟糕的事情。
顺序扫描的优化:
→预取
→缓冲池旁路
→并行化
→堆集群
→区域地图

页中属性值的预计算聚合。DBMS首先检查zone map来决定它是否想要访问这个页面。
DSM DBMS 可以延迟将元组拼接在一起,直到查询计划的上半部分。


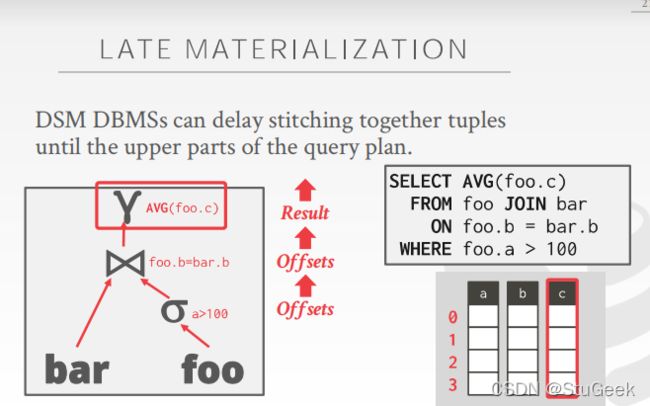
12.4.2 Index Scan 索引扫描
The DBMS picks an index to find the tuples that the query needs.
Which index to use depends on:
→ What attributes the index contains
→ What attributes the query references
→ The attribute’s value domains
→ Predicate composition
→ Whether the index has unique or non-unique keys
DBMS选择一个索引来找到查询需要的元组。
使用哪个索引取决于:
→索引包含哪些属性
→查询引用什么属性
→属性的值域
→谓语成分
→索引是否具有唯一或非唯一键
12.4.3 Multi-Index / “Bitmap” Scan
If there are multiple indexes that the DBMS can use for a query: → Compute sets of record ids using each matching index.
→ Combine these sets based on the query’s predicates (谓词)(union vs. intersect).
→ Retrieve (检索)the records and apply any remaining predicates. Postgres calls this Bitmap Scan
如果有多个索引,DBMS可以用于查询:
→使用每个匹配的索引计算记录id集。
→根据查询的谓词组合这些集合(并与交)。
→检索记录并应用任何剩余的谓词。
Postgres称之为位图扫描。

集合交集可以用位图、哈希表或Bloom过滤器来完成。
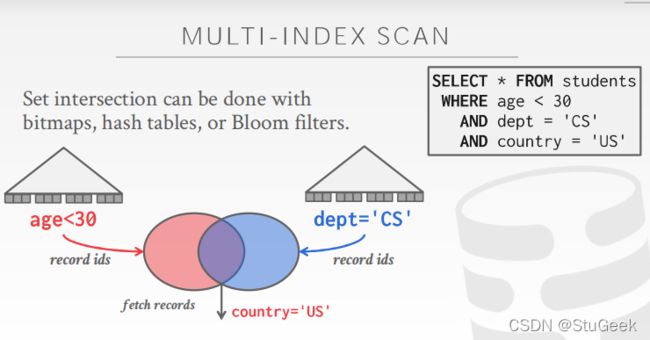
12.5 Modification Queries


HALLOWEEN(万圣节) PROBLEM
Anomaly where an update operation changes the physical location of a tuple, which causes a scan operator to visit the tuple multiple times.
→ Can occur on clustered tables or index scans.
First discovered by IBM researchers while working on System R on Halloween day in 1976.
更新操作改变了元组的物理位置,导致扫描操作符多次访问元组的异常现象。
→可以发生在集群表或索引扫描。
1976年的万圣节,IBM研究人员在研究System R时首次发现。
Expression Evaluation
表达式树
DBMS将子句表示为一个表达式树。
树中的节点表示不同的表达式类型:
→比较
→连接,分离
→算术运算符
→常量值
→元组属性引用
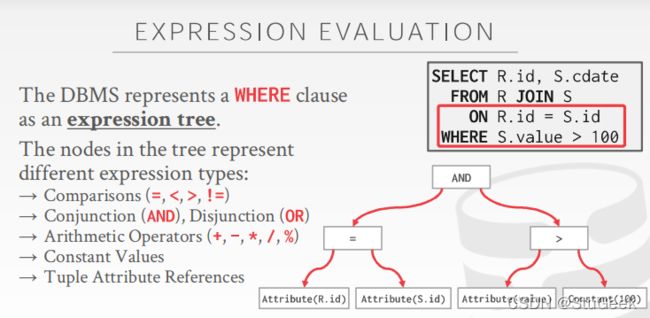

Evaluating predicates in this manner is slow.
→ The DBMS traverses the tree and for each node that it visits it must figure out what the operator needs to do.
Consider the predicate "WHERE 1=1 "
A better approach is to just evaluate the expression directly.
→ Think JIT compilation
以这种方式计算谓词很慢。
→DBMS遍历这棵树,对于它访问的每个节点,它必须弄清楚操作符需要做什么。
考虑谓词 "WHERE 1=1 "
更好的方法是直接对表达式求值。
→考虑JIT编译
总结:(Most) DBMSs will want to use an index scan as much as possible. Expression trees are flexible but slow.
16 Concurrency Control Theory 并发控制理论
16.1 transaction (事务)
A transaction is the execution of a sequence of one or more operations (e.g., SQL queries) on a database to perform some higher-level function.
It is the basic unit of change in a DBMS: → Partial transactions are not allowed!
事务是在数据库上执行一个或多个操作序列(例如,SQL查询),来执行一些更高级的功能。
它是DBMS中变化的基本单位:
→不允许部分事务!(原子性)
example
把100美元从安迪的银行账户转到他的发起人账户。
事务:
查一下安迪是否有100美元。
→从他的帐户中扣除100美元。
→给他的推广人账户加100美元
16.2 strawman system 稻草人系统
Execute each txn one-by-one (i.e., serial order) as they arrive at the DBMS.
→ One and only one txn can be running at the same time in the DBMS.
Before a txn starts, copy the entire database to a new file and make all changes to that file.
→ If the txn completes successfully, overwrite the original file with the new one.
→ If the txn fails, just remove the dirty copy.
当每一个txn到达DBMS时,一个接一个地(即,串行顺序)执行它们。
→在DBMS中,一个且只有一个txn可以同时运行。
在启动txn之前,将整个数据库复制到一个新文件,并对该文件进行所有更改。
→如果txn成功完成,则用新文件覆盖原文件。
→如果txn失败,只需删除脏拷贝。
A (potentially) better approach is to allow concurrent execution of independent transactions.
Why do we want that?
→ Better utilization/throughput
→ Increased response times to users.
But we also would like:
→ Correctness
→ Fairness
一个(可能的)更好的方法是允许并发执行独立事务。
我们为什么要这样做?
→更好的利用率和吞吐量
→增加用户的响应时间。
但我们也想:
→正确性
→公平
Hard to ensure correctness…
→ What happens if Andy only has $100 and tries to pay off two promotors at the same time?
Hard to execute quickly…
→ What happens if Andy tries to pay off his gambling debts at the exact same time?
很难保证正确性……
如果安迪只有100美元,并试图同时支付给两个发起人会发生什么?
很难快速执行……
如果安迪试图同时还清他的赌债会发生什么?
Arbitrary(任意 )interleaving(交错 )of operations can lead to:
→ Temporary Inconsistency (ok, unavoidable)
→ Permanent Inconsistency (bad!)
We need formal correctness criteria (形式化的正确性标准) to determine whether an interleaving is valid.
任意交错操作会导致:
→临时不一致性(好吧,不可避免)
→永久的不一致性(糟糕!)
我们需要形式化的正确性标准来确定交错是否有效。
A txn may carry out many operations on the data retrieved from the database The DBMS is only concerned about what data is read/written from/to the database. → Changes to the “outside world” are beyond the scope of the DBMS
txn可以对从数据库中检索到的数据进行许多操作
DBMS只关心从数据库中读/写什么数据。
→对“外部世界”的改变超出了DBMS的范围。
16.3 事务在SQL中
A new txn starts with the BEGIN command.
The txn stops with COMMIT either or ABORT(中止) :
→ If commit, the DBMS either saves all the txn’s changes or aborts it.
→ If abort, all changes are undone so that it’s like as if the txn never executed at all.
Abort can be either self-inflicted or caused by the DBMS.
一个新的txn以BEGIN命令开始。
txn通过COMMIT或ABORT停止:
→如果COMMIT(提交),DBMS要么保存所有txn的更改,要么中止它。
→如果ABORT (中止),所有的更改都被撤消,就像txn从来没有执行过一样。
中止可以是自己造成的,也可以是DBMS引起的。
16.4 correctness criteria:ACID 正确的标准ACID
Atomicity: All actions in the txn happen, or none happen.
Consistency: If each txn is consistent and the DB starts consistent, then it ends up consistent.
Isolation: Execution of one txn is isolated from that of other txns.
Durability: If a txn commits, its effects persist.
原子性:txn中的所有动作都发生,或者什么都不发生。
一致性:如果每个txn是一致的,并且DB启动时是一致的,那么它结束时也是一致的。
隔离性:一个txn的执行与其他txn的执行是隔离的。
持久性:如果txn提交,其效果将持续存在。
16.4.1 原子性
Two possible outcomes of executing a txn:
→ Commit after completing all its actions.
→ Abort (or be aborted by the DBMS) after executing some actions.
DBMS guarantees that txns are atomic.
→ From user’s point of view: txn always either executes all its actions or executes no actions at all
执行txn的两个可能结果:
→完成所有动作后提交。
→在执行一些操作后终止(或被DBMS终止)。
DBMS保证txns是原子的。
→从用户的角度来看:txn总是要么执行所有的动作,要么不执行任何动作
场景# 1:
我们从安迪的帐户中取出100美元,但是在我们转移它之前,DBMS中止了txn。
场景# 2:
我们从安迪的账户上取了100美元,但在我们转账之前,突然停电了。
在两个txns中止后,Andy的帐户的正确状态是什么?
mechanisms for ensuring atomicity 确保原子性的机制
Approach #1: Logging
→ DBMS logs all actions so that it can undo the actions of aborted transactions.
→ Maintain undo records both in memory and on disk.
→ Think of this like the black box in airplanes…
Logging is used by almost every DBMS.
→ Audit Trail
→ Efficiency Reasons
方法# 1:日志记录
→DBMS记录所有的操作,这样它就可以撤消中止事务的操作。
→维护内存和磁盘上的撤销记录。
→想象一下飞机上的黑匣子……
几乎所有DBMS都使用日志记录。
→审计跟踪
→效率的原因
Approach #2: Shadow Paging
→ DBMS makes copies of pages and txns make changes to those copies. Only when the txn commits is the page made visible to others.
→ Originally from System R.
Few systems do this:
→ CouchDB
→ LMDB (OpenLDAP)
方法2:阴影分页
→DBMS复制页面,而txns对这些副本进行更改。只有当txn提交时,页面才对其他人可见。
→起源于系统R。
很少有系统这样做:
→CouchDB
→LMDB (OpenLDAP)
16.4.2 Consistency 一致性
Database Consistency 数据库的一致性
The database accurately models the real world and follows integrity constraints.
Transactions in the future see the effects of transactions committed in the past inside of the databas
该数据库准确地模拟了现实世界,并遵循完整性约束。
未来的事务将看到过去提交的事务在数据库中的影响
Transaction Consistency 事务的一致性
If the database is consistent before the transaction starts (running alone), it will also be consistent after.
Transaction consistency is the application’s responsibility. DBMS cannot control this.
→ We won’t discuss this issue further…
如果数据库在事务启动前(单独运行)是一致的,那么事务启动后也将是一致的。
事务一致性是应用程序的职责。DBMS无法控制这一点。
我们不再进一步讨论这个问题了。
16.4.3 Isolation 隔离性
Users submit txns, and each txn executes as if it was running by itself.
→ Easier programming model to reason about.
But the DBMS achieves concurrency by interleaving(交错) the actions (reads/writes of DB objects) of txns.
We need a way to interleave txns but still make it appear as if they ran one-at-a-time.
用户提交txns,每个txn执行时就像它自己在运行一样。
→更容易推理的编程模型。
但是DBMS是通过交错txns的动作(读/写DB对象)来实现并发的。
我们需要一种方法来交错txns,但仍然使它看起来好像它们一次运行一个。
mechanisms for ensuring Isolation 确保隔离性的机制
A concurrency control protocol is how the DBMS decides the proper interleaving of operations from multiple transactions.
Two categories of protocols:
→ Pessimistic: Don’t let problems arise in the first place.
→ Optimistic: Assume conflicts are rare, deal with them after they happen.
并发控制协议是如何实现的
数据库管理系统(DBMS)决定从多个事务中操作的适当交错。
两类协议:
→悲观:一开始就不要让问题出现。
→乐观:假设冲突很少发生,发生后再处理。

We interleave txns(交错txns) to maximize concurrency.
→ Slow disk/network I/O.
→ Multi-core CPUs.
When one txn stalls because of a resource (e.g., page fault), another txn can continue executing and make forward progress.
我们交错txns以最大化并发性。
→缓慢的磁盘/网络I/O。
→多核cpu。
当一个txn由于资源(例如,页面错误)而停止时,另一个txn可以继续执行并继续前进。
16.5 调度
How do we judge whether a schedule is correct?
If the schedule is equivalent to some serial execution
我们如何判断一个时间表是否正确?
如果c调度等同于串行执行。
Equivalent Schedules 等价调度
→ For any database state, the effect of executing the first schedule is identical to the effect of executing the second schedule.
→ Doesn’t matter what the arithmetic operations are!
等价调度
→对于任何数据库状态,执行第一个调度的效果与执行第二个调度的效果相同。
算术运算是什么并不重要!
Serializable Schedule 可串行化的调度
→ A schedule that is equivalent to some serial execution of the transactions.
If each transaction preserves consistency, every serializable schedule preserves consistency.
可串行化的调度
→相当于事务的串行执行的调度。
如果每个事务保持一致性,那么每个可序列化调度也保持一致性。
better parallelism 更好的并行性
冲突概念
Two operations conflict if:
→ They are by different transactions,
→ They are on the same object and at least one of them is a write.
如果两个操作发生冲突:
→他们是来自不同的事务,
→它们作用在同一个对象上,并且至少有一个是写的
冲突种类
Read-Write Conflicts (R-W) 不可重复的读
Write-Read Conflicts (W-R) 读为提交的数据
Write-Write Conflicts (W-W)重写未提交的数据


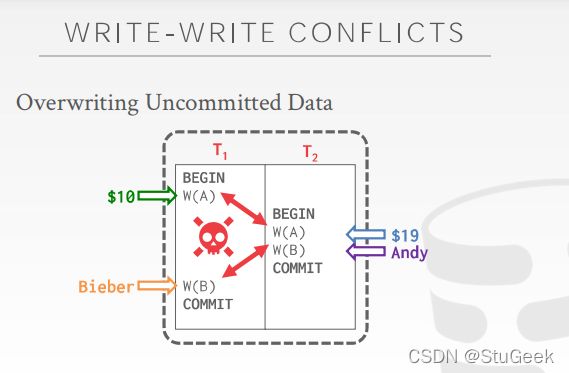
Given these conflicts, we now can understand what it means for a schedule to be serializable.
→ This is to check whether schedules are correct.
→ This is not how to generate a correct schedule.
There are different levels of serializability:
→ Conflict Serializability
→ View Serializability
考虑到这些冲突,我们现在可以理解to be可序列化的调度意味着什么了。
→这是检查调度是否正确。
这不是如何生成一个正确的调度。
序列化有不同的级别:
→冲突可串行性
→视图可串行性
Two schedules are conflict equivalent iff:
→ They involve the same actions of the same transactions, and
→ Every pair of conflicting actions is ordered the same way.
Schedule S is conflict serializable if:
→S is conflict equivalent to some serial schedule
两个时间表是冲突等效iff:
→它们涉及相同事务的相同动作,并且
→每对相互冲突的动作都以相同的方式排列。
Schedule S是冲突可序列化的,如果:
→S是冲突等价于某个串行调度
Schedule S is conflict serializable if you can transform S into a serial schedule by swapping consecutive non-conflicting operations of different transactions.
如果您可以通过交换不同事务的连续非冲突操作将S转换为串行调度,那么Schedule S就是冲突可序列化的。
Are there any faster algorithms to figure this out other than transposing operations?
有没有比转置运算更快的算法?
dependency graphs 依赖图

每txn一个节点。
从 T i T_i Ti到 T j T_j Tj,如果:
→ T i T_i Ti的一个操作 O i O_i Oi与 T j T_j Tj的一个操作 O j O_j Oj冲突
→ O i O_i Oi在时间表中出现的比 O j O_j Oj早。
也称为优先图。
如果一个调度依赖图是无循环的,它就是冲突可序列化的。
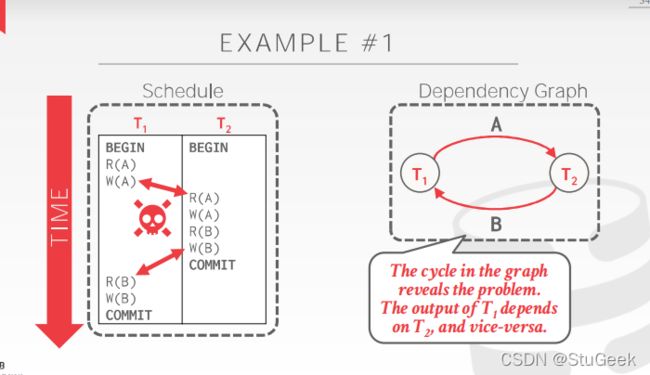
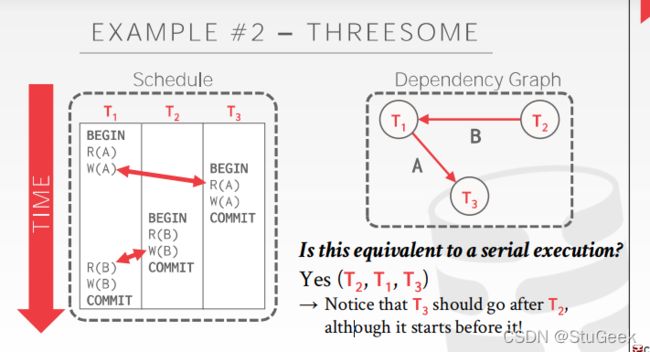
是否可能只修改应用程序逻辑,以使调度产生“正确”的结果,但仍然不是冲突可序列化的?

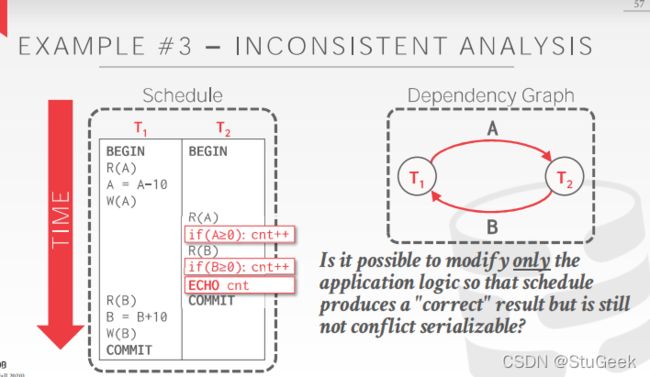
???
View Serializability
Alternative (weaker) notion of serializability.
Schedules S1 and S2 are view equivalent if:
→ If T1 reads initial value of A in S1, then T1 also reads initial
value of A in S2.
→ If T1 reads value of A written by T2 in S1, then T1 also
reads value of A written by T2 in S2 .
→ If T1 writes final value of A in S1, then T1 also writes final
value of A in S2.
可串行化的另一种(较弱的)概念。
表S1和表S2是视图等价的如果:
→**初始读取:**S1中T1读取A的初始值,那么S2中T1(而不是T2)也读取初始值
A的值。
→在时间表:S1中, 如果Ti正在读取由Tj更新的A, 那么在S2中, Ti也应读取由Tj更新的A。
→**最终写:**在时间表S1中, 如果事务T1最后更新了A, 则在S2中, 最后的写操作也应由T1完成。


View Serializability allows for (slightly) more schedules than Conflict Serializability does.
→ But is difficult to enforce efficiently.
Neither definition allows all schedules that you would consider “serializable”.
→ This is because they don’t understand the meanings of the operations or the data (recall example #3)
View Serializability比Conflict Serializability允许(稍微)更多的调度。
→但是很难有效地执行。
这两个定义都不允许所有你认为“可序列化”的时间表。
→这是因为他们不理解操作或数据的含义(回想一下例子3)

16.6 持久性
All the changes of committed transactions should be persistent. → No torn updates.
→ No changes from failed transactions.
The DBMS can use either logging or shadow paging to ensure that all changes are durable
提交事务的所有更改都应该是持久性的。
→没有损坏的更新。
→失败的事务没有变化。
DBMS可以使用日志记录或影子分页来确保所有更改都是持久的
17 Two-Phase Locking 两阶段封锁
LAST CLASS 上一节课
- Conflict Serializable 冲突可串行化
- → Verify using either the “swapping” method or dependency graphs. 使用“交换”方法或依赖关系图进行验证。
- → Any DBMS that says that they support “serializable” isolation does this. 任何表示支持“可串行化”隔离的DBMS都会这样做。
- View Serializable 视图可串行化
- → No efficient way to verify. 没有有效的方法来验证。
- → Andy doesn’t know of any DBMS that supports this. Andy不知道有任何数据库管理系统支持这一点。
EXAMPLE 例子

OBSERVATION 观察
- We need a way to guarantee that all execution schedules are correct (i.e., serializable) without knowing the entire schedule ahead of time. 我们需要一种方法来保证所有执行计划都是正确的(即可序列化的),而不需要提前知道整个计划。
- Solution: Use locks to protect database objects. 解决方案:使用锁来保护数据库对象。
EXECUTING WITH LOCKS 用锁来执行
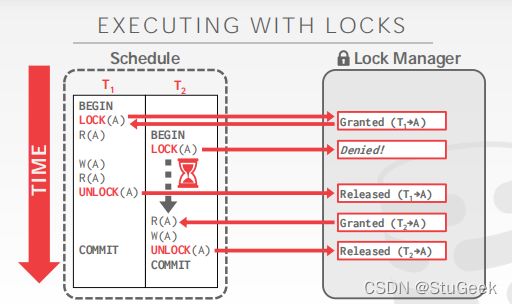
TODAY’S AGENDA 今天日程
Lock Types 锁类型
Two-Phase Locking 两阶段封锁
Deadlock Detection + Prevention 死锁检测+预防
Hierarchical Locking 分级锁定
Isolation Levels 隔离级别
LOCKS VS. LATCHES 事物之间锁和线程之间锁
| Locks | Latches | |
|---|---|---|
| Separate… 分离 | User transactions 用户事务 | Threads 线程 |
| Protect… 保护 | Database Contents 数据库内容 | In-Memory Data Structures 内存数据结构 |
| During… 在什么期间 | Entire Transactions 整个事务 | Critical Sections 临界区 |
| Modes… 模式 | Shared, Exclusive, Update, Intention 共享、独占、更新、意图 | Read, Write 读、写 |
| Deadlock 死锁 | Detection & Resolution 检测和解决 | Avoidance 避免 |
| …by… 通过 | Waits-for, Timeout, Aborts 等待、超时、中止 | Coding Discipline 编码规则 |
| Kept in… 保存在 | Lock Manager 锁管理器 | Protected Data Structure 受保护的数据结构中 |
BASIC LOCK TYPES 基本锁类型
- S-LOCK: Shared locks for reads. S锁:用于读取的共享锁。
- X-LOCK: Exclusive locks for writes. X锁:用于写入的独占锁。
Compatibility Matrix 兼容性矩阵
| Shared | Exclusive | |
|---|---|---|
| Shared | √ | x |
| Exclusive | x | x |
EXECUTING WITH LOCKS 用锁执行
- Transactions request locks (or upgrades). 事务请求锁定(或更新)。
- Lock manager grants or blocks requests. 锁管理器允许或阻止请求
- Transactions release locks. 事务释放锁
- Lock manager updates its internal lock-table. 锁管理器更新其内部锁表
- → It keeps track of what transactions hold what locks and what transactions are waiting to acquire any locks. 它跟踪哪些事务持有哪些锁以及哪些事务正在等待获取任何锁。

CONCURRENCY CONTROL PROTOCOL 并发控制协议
- Two-phase locking (2PL) is a concurrency control protocol that determines whether a txn can access an object in the database on the fly. 两阶段封锁(2PL)是一种并发控制协议,用于确定txn是否可以动态访问数据库中的对象。
- The protocol does not need to know all the queries that a txn will execute ahead of time. 协议不需要知道txn将提前执行的所有查询。
TWO-PHASE LOCKING 两阶段封锁
加锁和解锁操作不能交叉执行(同一个事务内)
-
Phase #1: Growing 加锁、增长阶段
- → Each txn requests the locks that it needs from the DBMS’s lock manager. 每个txn都从DBMS的锁管理器请求它需要的锁。
- → The lock manager grants/denies lock requests. 锁管理器授予/拒绝锁请求。
-
Phase #2: Shrinking 解锁、缩减阶段
- → The txn is allowed to only release locks that it previously acquired. It cannot acquire new locks. txn只允许释放它以前获得的锁。它无法获取新锁。
-
The txn is not allowed to acquire/upgrade locks after the growing phase finishes 在增长阶段结束后,txn不允许获取/更新锁
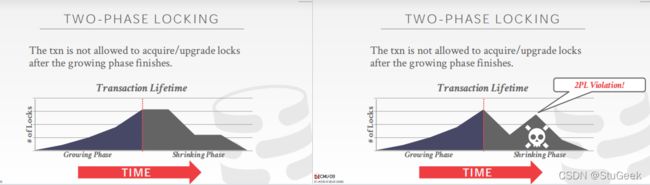

- 2PL on its own is sufficient to guarantee conflict serializability. 2PL本身就足以保证冲突序列化。
- → It generates schedules whose precedence graph is acyclic. But it is subject to cascading aborts 它生成优先级图为非循环的计划。但它会受到级联中止的影响
2PL - CASCADING ABORTS 2PL - 级联中止
- This is a permissible schedule in 2PL, but the DBMS has to also abort T2 when T1 aborts. 这是2PL中允许的调度,但DBMS也必须在T1中止时中止T2。
- → Any information about T1 cannot be “leaked” to the outside world. 关于T1的任何信息都不能“泄露”给外界。
2PL OBSERVATIONS 2PL 观察
- There are potential schedules that are serializable but would not be allowed by 2PL. 存在可串行化但2PL不允许的潜在计划
- → Locking limits concurrency. 锁定限制了并发性
- May still have “dirty reads”. 可能仍然有“脏读”
- → Solution: Strong Strict 2PL (aka Rigorous 2PL) 解决方案:强严格2PL(又称严格2PL)
- May lead to deadlocks. 可能导致死锁
- → Solution: Detection or Prevention 解决办法:检测或者预防
STRONG STRICT TWO-PHASE LOCKING 强严格两阶段封锁
要求事务提交之前不得释放任何锁
- The txn is not allowed to acquire/upgrade locks after the growing phase finishes. 在增长阶段结束后,txn不允许获取/升级锁。
- Allows only conflict serializable schedules, but it is often stronger than needed for some apps. 只允许冲突串行化计划,但它通常比某些应用程序所需的更强大。

- A schedule is strict if a value written by a txn is not read or overwritten by other txns until that txn finishes. 如果由txn写入的值在txn完成之前未被其他txn读取或覆盖,则计划是严格的。
- Advantages: 优点:
- → Does not incur cascading aborts. 不会导致级联中止。
- → Aborted txns can be undone by just restoring original values of modified tuples. 中止的TXN可以通过恢复修改过的元组的原始值来撤消。
EXAMPLES 例子
- T1 – Move $100 from Andy’s account (A) to his bookie’s account (B). 将100美元从安迪的账户(A)转移到他的博彩账户(B)。
- T2 – Compute the total amount in all accounts and return it to the application. 计算所有帐户中的总金额并将其返回给应用程序。

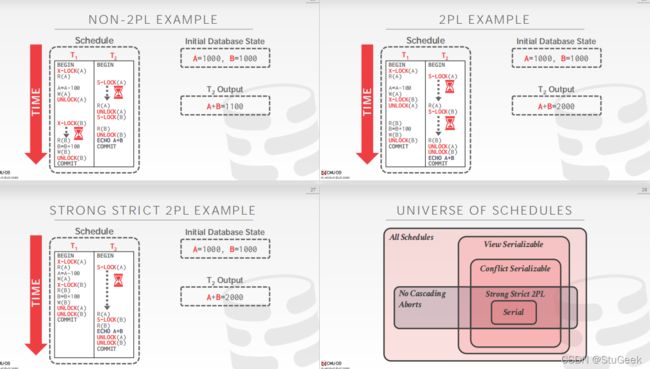
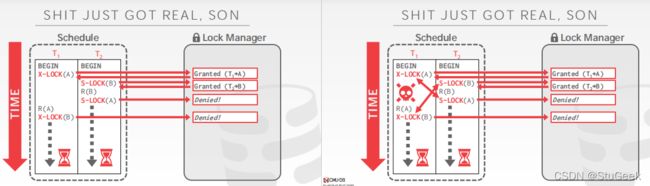
2PL DEADLOCKS 死锁
- A deadlock is a cycle of transactions waiting for locks to be released by each other. 死锁是等待彼此释放锁的事务循环。
- Two ways of dealing with deadlocks: 处理死锁的两种方法
- → Approach #1: Deadlock Detection 死锁检测
- → Approach #2: Deadlock Prevention 死锁预防
DEADLOCK DETECTION 死锁检测
- The DBMS creates a waits-for graph to keep track of what locks each txn is waiting to acquire: DBMS创建一个等待图,以跟踪每个txn等待获取的锁:
- → Nodes are transactions 节点是事务
- → Edge from Ti to Tj,if Ti is waiting for Tj to release a lock. 从Ti到Tj的边,如果Ti正在等待Tj释放锁。
- The system periodically checks for cycles in waits-for graph and then decides how to break it. 系统定期检查等待图中的循环,然后决定如何打破它。

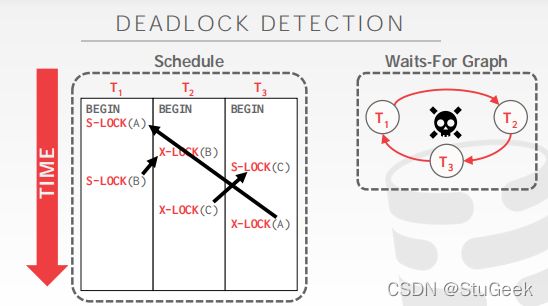
DEADLOCK HANDLING 死锁解决
- When the DBMS detects a deadlock, it will select a “victim” txn to rollback to break the cycle. 当DBMS检测到死锁时,它将选择一个“受害者”txn进行回滚以打破循环。
- The victim txn will either restart or abort(more common) depending on how it was invoked. 受害者txn将根据其调用方式重新启动或中止(更常见)。
- There is a trade-off between the frequency of checking for deadlocks and how long txns have to wait before deadlocks are broken. 在检查死锁的频率和txn必须等待多长时间才能打破死锁之间存在权衡。
VICTIM SELECTION 受害者选择算法
- Selecting the proper victim depends on a lot of different variables…. 选择合适的受害者取决于许多不同的变量…
- → By age (lowest timestamp) 按年龄(最低时间戳)
- → By progress (least/most queries executed) 按进度(执行的查询最少/最多)
- → By the # of items already locked 通过已锁定的项目的#
- → By the # of txns that we have to rollback with it 根据必须用它回滚的txns的#
- We also should consider the # of times a txn has been restarted in the past to prevent starvation. 我们也应该考虑过去的txn已经被重新启动的时间,以防止饥饿。
DEADLOCK HANDLING: ROLLBACK LENGTH 死锁解决:回滚长度
- After selecting a victim txn to abort, the DBMS can also decide on how far to rollback the txn’s changes. 选择要中止的受害者txn后,DBMS还可以决定回滚txn更改的距离。
- Approach #1: Completely 完全
- Approach #2: Minimally 最低限度
DEADLOCK PREVENTION 死锁预防
- When a txn tries to acquire a lock that is held by another txn, the DBMS kills one of them to prevent a deadlock. 当一个txn试图获取另一个txn持有的锁时,DBMS会杀死其中一个以防止死锁。
- This approach does not require a waits-for graph or detection algorithm. 这种方法不需要等待图或检测算法。
- Assign priorities based on timestamps: 根据时间戳分配优先级
- → Older Timestamp = Higher Priority (e.g., T1 > T2) 时间戳越旧=优先级越高(例如T1>T2)
- Wait-Die (“Old Waits for Young”) (“老等待年轻”)
- → If requesting txn has higher priority than holding txn, then requesting txn waits for holding txn. 如果请求txn的优先级高于保持txn,则请求txn将等待保持txn。
- → Otherwise requesting txn aborts. 否则,请求txn将中止。
- Wound-Wait (“Young Waits for Old”) (“年轻等待老的”)
- → If requesting txn has higher priority than holding txn, then holding txn aborts and releases lock. 如果请求txn的优先级高于保持txn,则保持txn将中止并释放锁。
- → Otherwise requesting txn waits. 否则,请求txn将等待。
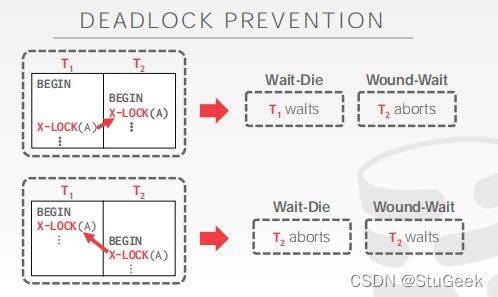
DEADLOCK PREVENTION 死锁预防
- Why do these schemes guarantee no deadlocks? 为什么这些计划保证没有死锁?
- Only one “type” of direction allowed when waiting for a lock. 等待锁定时只允许一种“类型”的方向。
- When a txn restarts, what is its (new) priority? txn重新启动时,其(新)优先级是多少?
- Its original timestamp. Why? 它的原始时间戳。为什么?
OBSERVATION
- All these examples have a one-to-one mapping from database objects to locks. 所有这些示例都具有从数据库对象到锁的一对一映射。
- If a txn wants to update one billion tuples, then it must acquire one billion locks. 如果txn想要更新10亿个元组,那么它必须获得10亿个锁。
- Acquiring locks is a more expensive operation than acquiring a latch even if that lock is available. 获取lock比获取latch (即使该锁可用)成本更高。
LOCK GRANUL ARITIES 锁的颗粒
- When a txn wants to acquire a “lock”, the DBMS can decide the granularity (i.e., scope) of that lock. 当txn想要获取“锁”时,DBMS可以决定该锁的粒度(即范围)。
- → Attribute? Tuple? Page? Table? 属性元组?页?表格?
- The DBMS should ideally obtain fewest number of locks that a txn needs. 理想情况下,DBMS应该获得txn所需的最少数量的锁。
- Trade-off between parallelism versus overhead. 在并行性和开销之间进行权衡。
- → Fewer Locks, Larger Granularity vs. More Locks, Smaller Granularity. 锁越少,粒度越大,而锁越多,粒度越小。
DATABASE LOCK HIERARCHY 数据库锁层次结构

EXAMPLE
- T1 – Get the balance of Andy’s shady off-shore bank account. 获取安迪可疑离岸银行账户的余额。
- T2 – Increase Biden’s bank account balance by 1%. 将拜登的银行账户余额增加1%。
- What locks should these txns obtain? 这些txns应该获得什么锁?
- → Exclusive + Shared for leaf nodes of lock tree. 锁树的叶节点的独占+共享。
- → Special Intention locks for higher levels. 更高级别的特殊意图锁。
INTENTION LOCKS 意图锁
- An intention lock allows a higher-level node to be locked in shared or exclusive mode without having to check all descendent nodes. 意向锁允许在共享或独占模式下锁定更高级别的节点,而无需检查所有子节点。
- If a node is locked in an intention mode, then some txn is doing explicit locking at a lower level in the tree. 如果一个节点在意图模式下被锁定,那么一些txn在树的较低级别上执行显式锁定。
- Intention-Shared (IS) 意向共享
- → Indicates explicit locking at lower level with shared locks. 指示使用共享锁在较低级别显式锁定。
- Intention-Exclusive (IX) 意向排除
- → Indicates explicit locking at lower level with exclusive locks. 指示使用独占锁在较低级别显式锁定。
- Shared+Intention-Exclusive (SIX) 共享+专用
- → The subtree rooted by that node is locked explicitly in shared mode and explicit locking is being done at a lower level with exclusive-mode locks. 以该节点为根的子树在共享模式下被显式锁定,显式锁定是在较低级别上使用独占模式锁定完成的。
COMPATIBILITY MATRIX 兼容性矩阵

LOCKING PROTOCOL 锁的协议
- Each txn obtains appropriate lock at highest level of the database hierarchy. 每个txn在数据库层次结构的最高级别获得适当的锁。
- To get S or IS lock on a node, the txn must hold at least IS on parent node. 要在节点上获得S或IS锁,txn必须至少在父节点上保持IS。
- To get X, IX, or SIX on a node, must hold at least IX on parent node. 若要在节点上获取X、IX或SIX,必须在父节点上至少保留IX。


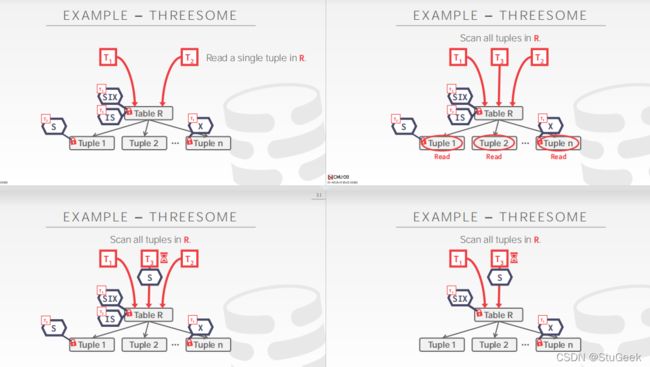
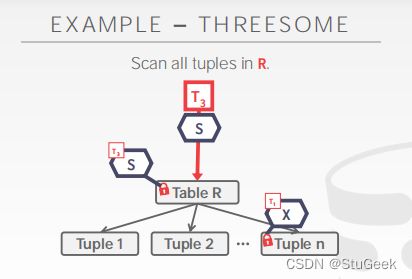
MULTIPLE LOCK GRANUL ARITIES 多重锁粒度
- Hierarchical locks are useful in practice as each txn only needs a few locks. 分层锁在实践中很有用,因为每个txn只需要几个锁。
- Intention locks help improve concurrency: 意图锁有助于提高并发性:
- → Intention-Shared (IS): Intent to get S lock(s) at finer granularity. 意图共享(IS):意图以更精细的粒度获取S锁。
- → Intention-Exclusive (IX): Intent to get X lock(s) at finer granularity. 意图独占(IX):意图以更细的粒度获得X锁。
- → Shared+Intention-Exclusive (SIX): Like S and IX at the same time. 共享+意图排除(SIX):像S和IX一样同时出现。
LOCK ESCAL ATION 解锁行为
- Lock escalation dynamically asks for coarser-grained locks when too many low-level locks acquired. 当获取了太多低级锁时,锁升级会动态地请求粗粒度的锁。
- This reduces the number of requests that the lock manager must process. 这减少了锁管理器必须处理的请求数。
LOCKING IN PRACTICE 实践中的锁
- You typically don’t set locks manually in txns.Sometimes you will need to provide the DBMS with hints to help it to improve concurrency. 您通常不会在txns中手动设置锁。有时,您需要向DBMS提供提示,以帮助它提高并发性。
- Explicit locks are also useful when doing major changes to the database. 显式锁在对数据库进行重大更改时也很有用。
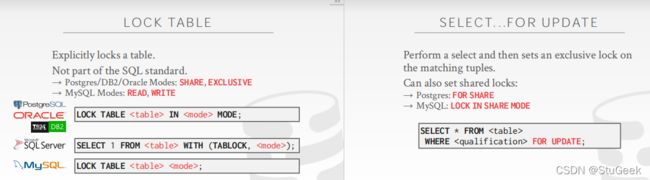
CONCLUSION 总结
- 2PL is used in almost DBMS. 2PL用于大多数DBMS中。
- Automatically generates correct interleaving: 自动生成正确的交织:
- → Locks + protocol (2PL, SS2PL …) 锁+协议(2PL,SS2PL…)
- → Deadlock detection + handling 死锁检测+处理
- → Deadlock prevention 死锁预防