redis面试题2
面经来源于github上的
Java-Interview
在学习时,用自己的语言解释
6、讲解一下Redis的线程模型?
redis 内部使用文件事件处理器 file event handler,这个文件事件处理器是单线程的,所以 redis 才叫做单线程的模型。它采用 IO 多路复用机制同时监听多个 socket,根据 socket 上的事件来选择对应的事件处理器进行处理。
如果面试官继续追问为啥 redis 单线程模型也能效率这么高?
-
纯内存操作
-
核心是基于非阻塞的 IO 多路复用机制
-
单线程反而避免了多线程的频繁上下文切换问题
7、缓存雪崩、缓存穿透、缓存预热、缓存击穿、缓存降级的区别是什么?
在实际生产环境中有时会遇到缓存穿透、缓存击穿、缓存雪崩等异常场景,为了避免异常带来巨大损失,我们需要了解每种异常发生的原因以及解决方案,帮助提升系统可靠性和高可用。
(1)缓存穿透
什么是缓存穿透?
缓存穿透是指用户请求的数据在缓存中不存在即没有命中,同时在数据库中也不存在,导致用户每次请求该数据都要去数据库中查询一遍,然后返回空。
如果有恶意攻击者不断请求系统中不存在的数据,会导致短时间大量请求落在数据库上,造成数据库压力过大,甚至击垮数据库系统。
缓存穿透常用的解决方案
(1)布隆过滤器(推荐)
布隆过滤器(Bloom Filter,简称BF)由Burton Howard Bloom在1970年提出,是一种空间效率高的概率型数据结构。
布隆过滤器专门用来检测集合中是否存在特定的元素。
如果在平时我们要判断一个元素是否在一个集合中,通常会采用查找比较的方法,下面分析不同的数据结构查找效率:
-
采用线性表存储,查找时间复杂度为O(N)
-
采用平衡二叉排序树(AVL、红黑树)存储,查找时间复杂度为O(logN)
-
采用哈希表存储,考虑到哈希碰撞,整体时间复杂度也要O[log(n/m)]
当需要判断一个元素是否存在于海量数据集合中,不仅查找时间慢,还会占用大量存储空间。接下来看一下布隆过滤器如何解决这个问题。
布隆过滤器设计思想
布隆过滤器由一个长度为m比特的位数组(bit array)与k个哈希函数(hash function)组成的数据结构。位数组初始化均为0,所有的哈希函数都可以分别把输入数据尽量均匀地散列。
当要向布隆过滤器中插入一个元素时,该元素经过k个哈希函数计算产生k个哈希值,以哈希值作为位数组中的下标,将所有k个对应的比特值由0置为1。
当要查询一个元素时,同样将其经过哈希函数计算产生哈希值,然后检查对应的k个比特值:如果有任意一个比特为0,表明该元素一定不在集合中;如果所有比特均为1,表明该集合有可能性在集合中。为什么不是一定在集合中呢?因为不同的元素计算的哈希值有可能一样,会出现哈希碰撞,导致一个不存在的元素有可能对应的比特位为1,这就是所谓“假阳性”(false positive)。相对地,“假阴性”(false negative)在BF中是绝不会出现的。
总结一下:布隆过滤器认为不在的,一定不会在集合中;布隆过滤器认为在的,可能在也可能不在集合中。
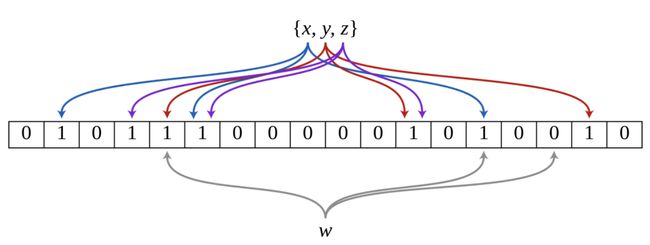
举个例子:下图是一个布隆过滤器,共有18个比特位,3个哈希函数。集合中三个元素x,y,z通过三个哈希函数散列到不同的比特位,并将比特位置为1。当查询元素w时,通过三个哈希函数计算,发现有一个比特位的值为0,可以肯定认为该元素不在集合中。
布隆过滤器优缺点
优点:
-
节省空间:不需要存储数据本身,只需要存储数据对应hash比特位
-
时间复杂度低:插入和查找的时间复杂度都为O(k),k为哈希函数的个数
缺点:
-
存在假阳性:布隆过滤器判断存在,可能出现元素不在集合中;判断准确率取决于哈希函数的个数
-
不能删除元素:如果一个元素被删除,但是却不能从布隆过滤器中删除,这也是造成假阳性的原因了
布隆过滤器适用场景
-
爬虫系统url去重
-
垃圾邮件过滤
-
黑名单
(2)返回空对象
当缓存未命中,查询持久层也为空,可以将返回的空对象写到缓存中,这样下次请求该key时直接从缓存中查询返回空对象,请求不会落到持久层数据库。为了避免存储过多空对象,通常会给空对象设置一个过期时间。
这种方法会存在两个问题:
-
如果有大量的key穿透,缓存空对象会占用宝贵的内存空间。
-
空对象的key设置了过期时间,在这段时间可能会存在缓存和持久层数据不一致的场景。
(2)缓存击穿
什么是缓存击穿?
缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
缓存击穿危害
数据库瞬时压力骤增,造成大量请求阻塞。
如何解决?
方案一:使用互斥锁(mutex key)
这种思路比较简单,就是让一个线程回写缓存,其他线程等待回写缓存线程执行完,重新读缓存即可。

同一时间只有一个线程读数据库然后回写缓存,其他线程都处于阻塞状态。如果是高并发场景,大量线程阻塞势必会降低吞吐量。这种情况如何解决?
如果是分布式应用就需要使用分布式锁。
方案二:热点数据永不过期
永不过期实际包含两层意思:
-
物理不过期,针对热点key不设置过期时间
-
逻辑过期,把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建
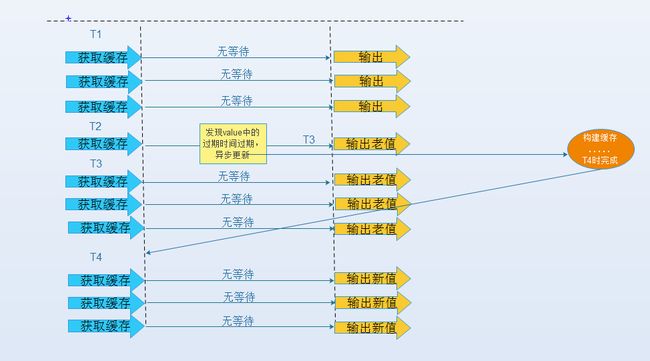
从实战看这种方法对于性能非常友好,唯一不足的就是构建缓存时候,其余线程(非构建缓存的线程)可能访问的是老数据,对于不追求严格强一致性的系统是可以接受的。
(3)缓存雪崩
什么是缓存雪崩?
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,请求直接落到数据库上,引起数据库压力过大甚至宕机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
缓存雪崩解决方案
常用的解决方案有:
-
均匀过期
-
加互斥锁
-
缓存永不过期
-
双层缓存策略
(1)均匀过期
设置不同的过期时间,让缓存失效的时间点尽量均匀。通常可以为有效期增加随机值或者统一规划有效期。
(2)加互斥锁
跟缓存击穿解决思路一致,同一时间只让一个线程构建缓存,其他线程阻塞排队。
(3)缓存永不过期
跟缓存击穿解决思路一致,缓存在物理上永远不过期,用一个异步的线程更新缓存。
(4)双层缓存策略
使用主备两层缓存:
主缓存:有效期按照经验值设置,设置为主读取的缓存,主缓存失效后从数据库加载最新值。
备份缓存:有效期长,获取锁失败时读取的缓存,主缓存更新时需要同步更新备份缓存。
(4)缓存预热
什么是缓存预热?
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统,这样就可以避免在用户请求的时候,先查询数据库,然后再将数据回写到缓存。
如果不进行预热, 那么 Redis 初始状态数据为空,系统上线初期,对于高并发的流量,都会访问到数据库中, 对数据库造成流量的压力。
缓存预热的操作方法
-
数据量不大的时候,工程启动的时候进行加载缓存动作;
-
数据量大的时候,设置一个定时任务脚本,进行缓存的刷新;
-
数据量太大的时候,优先保证热点数据进行提前加载到缓存。
(5)缓存降级
缓存降级是指缓存失效或缓存服务器挂掉的情况下,不去访问数据库,直接返回默认数据或访问服务的内存数据。
在项目实战中通常会将部分热点数据缓存到服务的内存中,这样一旦缓存出现异常,可以直接使用服务的内存数据,从而避免数据库遭受巨大压力。
降级一般是有损的操作,所以尽量减少降级对于业务的影响程度。
8、Redis的内存淘汰机制
Redis内存淘汰策略是指当缓存内存不足时,通过淘汰旧数据处理新加入数据选择的策略。
如何配置最大内存?
(1)通过配置文件配置
修改redis.conf配置文件
maxmemory 1024mb //设置Redis最大占用内存大小为1024M
注意:maxmemory默认配置为0,在64位操作系统下redis最大内存为操作系统剩余内存,在32位操作系统下redis最大内存为3GB。
(2)通过动态命令配置
Redis支持运行时通过命令动态修改内存大小:
127.0.0.1:6379> config set maxmemory 200mb //设置Redis最大占用内存大小为200M 127.0.0.1:6379> config get maxmemory //获取设置的Redis能使用的最大内存大小 1) "maxmemory" 2) "209715200"
淘汰策略的分类
Redis最大占用内存用完之后,如果继续添加数据,如何处理这种情况呢?实际上Redis官方已经定义了八种策略来处理这种情况:
noeviction
默认策略,对于写请求直接返回错误,不进行淘汰。
allkeys-lru
lru(less recently used), 最近最少使用。从所有的key中使用近似LRU算法进行淘汰。
volatile-lru
lru(less recently used), 最近最少使用。从设置了过期时间的key中使用近似LRU算法进行淘汰。
allkeys-random
从所有的key中随机淘汰。
volatile-random
从设置了过期时间的key中随机淘汰。
volatile-ttl
ttl(time to live),在设置了过期时间的key中根据key的过期时间进行淘汰,越早过期的越优先被淘汰。
allkeys-lfu
lfu(Least Frequently Used),最少使用频率。从所有的key中使用近似LFU算法进行淘汰。从Redis4.0开始支持。
volatile-lfu
lfu(Least Frequently Used),最少使用频率。从设置了过期时间的key中使用近似LFU算法进行淘汰。从Redis4.0开始支持。
注意:当使用volatile-lru、volatile-random、volatile-ttl这三种策略时,如果没有设置过期的key可以被淘汰,则和noeviction一样返回错误。
LRU算法
LRU(Least Recently Used),即最近最少使用,是一种缓存置换算法。在使用内存作为缓存的时候,缓存的大小一般是固定的。当缓存被占满,这个时候继续往缓存里面添加数据,就需要淘汰一部分老的数据,释放内存空间用来存储新的数据。这个时候就可以使用LRU算法了。其核心思想是:如果一个数据在最近一段时间没有被用到,那么将来被使用到的可能性也很小,所以就可以被淘汰掉。
LRU在Redis中的实现
Redis使用的是近似LRU算法,它跟常规的LRU算法还不太一样。近似LRU算法通过随机采样法淘汰数据,每次随机出5个(默认)key,从里面淘汰掉最近最少使用的key。
可以通过maxmemory-samples参数修改采样数量, 如:maxmemory-samples 10
maxmenory-samples配置的越大,淘汰的结果越接近于严格的LRU算法,但因此耗费的CPU也很高。
Redis为了实现近似LRU算法,给每个key增加了一个额外增加了一个24bit的字段,用来存储该key最后一次被访问的时间。
Redis3.0对近似LRU的优化
Redis3.0对近似LRU算法进行了一些优化。新算法会维护一个候选池(大小为16),池中的数据根据访问时间进行排序,第一次随机选取的key都会放入池中,随后每次随机选取的key只有在访问时间小于池中最小的时间才会放入池中,直到候选池被放满。当放满后,如果有新的key需要放入,则将池中最后访问时间最大(最近被访问)的移除。
当需要淘汰的时候,则直接从池中选取最近访问时间最小(最久没被访问)的key淘汰掉就行。
LFU算法
LFU(Least Frequently Used),是Redis4.0新加的一种淘汰策略,它的核心思想是根据key的最近被访问的频率进行淘汰,很少被访问的优先被淘汰,被访问的多的则被留下来。
LFU算法能更好的表示一个key被访问的热度。假如你使用的是LRU算法,一个key很久没有被访问到,只刚刚是偶尔被访问了一次,那么它就被认为是热点数据,不会被淘汰,而有些key将来是很有可能被访问到的则被淘汰了。如果使用LFU算法则不会出现这种情况,因为使用一次并不会使一个key成为热点数据。
9、Redis有事务机制吗?
-
有事务机制。Redis事务生命周期: 开启事务:使用MULTI开启一个事务
-
命令入队列:每次操作的命令都会加入到一个队列中,但命令此时不会真正被执行
-
提交事务:使用EXEC命令提交事务,开始顺序执行队列中的命令
10、Redis事务到底是不是原子性的?
先看关系型数据库ACID 中关于原子性的定义:原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被恢复(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
官方文档对事务的定义:
-
事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
-
事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。EXEC 命令负责触发并执行事务中的所有命令:如果客户端在使用 MULTI 开启了一个事务之后,却因为断线而没有成功执行 EXEC ,那么事务中的所有命令都不会被执行。另一方面,如果客户端成功在开启事务之后执行 EXEC ,那么事务中的所有命令都会被执行。
官方认为Redis事务是一个原子操作,这是站在执行与否的角度考虑的。但是从ACID原子性定义来看,严格意义上讲Redis事务是非原子型的,因为在命令顺序执行过程中,一旦发生命令执行错误Redis是不会停止执行然后回滚数据。