【读点论文】Benchmarking chinese text recognition Datasets, baselines, and an empirical study,中文专题的字符识别
Benchmarking Chinese Text Recognition: Datasets, Baselines, and an Empirical Study
Abstract
- 近年来,深度学习的蓬勃发展见证了文本识别的快速发展。然而,现有的文本识别方法主要针对英语文本。作为另一种广泛使用的语言,中文文本识别在各方面都有着广泛的应用市场。根据我们的观察,我们将对Chinese text recognition CTR 的关注不足归因于缺乏合理的数据集构建标准、统一的评估方案和现有基线的结果。为了填补这一空白,我们从公开的竞赛、项目和论文中手动收集CTR数据集。根据应用场景,我们将收集到的数据集分为场景、web、文档和手写四类数据集。此外,我们还规范了CTR中的评估协议。采用统一的评估协议,在收集到的数据集上对一系列具有代表性的文本识别方法进行评估,以提供基线。实验结果表明,由于中文文本与拉丁字母的差异较大,基线在CTR数据集上的表现不如在英文数据集上。此外,我们观察到通过引入激进级监督作为辅助任务,可以进一步提高基线的性能。代码和数据集可在https://github.com/FudanVI/benchmarking-chinese-text-recognition。上公开获取。
- 论文地址:[2112.15093] Benchmarking Chinese Text Recognition: Datasets, Baselines, and an Empirical Study (arxiv.org)
- OCR在实际生活中有许多应用场景,例如签名认证与车牌识别,甚至我发现苹果手机更新后相机也多了OCR功能;其次,由于OCR涵盖了两个模态,即图像模态和语言模态,这两个模态之间进行交互是一件很有意思的事情(可以花式A+B),从2020年开始有很多论文尝试将语义先验结合到文本识别任务中;最后,该领域持续不断地涌现新的数据集,例如最近学术界推出了很多文档相关的数据集,这也是下游任务检测和识别成熟的标志,学术界将目光转向更加复杂的文档图像。
- 尽管该领域一直在稳步发展,我发现学术界还是将研究重点放在英文文档/文本上,反而缺乏对中文文档/文本的研究。我尝试在Google scholar上进行搜索,发现现有的中文文本识别算法还是倾向研究手写文本图片,而鲜有论文对其他类型的文本图片(场景、网络、文档)进行研究。尽管手写文本识别发展速度较快,但细细品读逐篇论文,发现还是有些不公平比较的成分,例如有些论文会使用额外的数据集进行训练并且不开放源码与数据集,这让大家难以follow。
- 【中文文本识别】大白话 Benchmarking Chinese Text Recognition - 知乎 (zhihu.com)
Introduction
-
近年来,文本识别因其在自动驾驶、文档检索、签名识别等方面的广泛应用而受到广泛关注。然而,现有的文本识别方法主要集中在英文文本,而忽略了中文文本识别(CTR)的巨大市场。具体来说,汉语是世界上使用人数最多的语言,有13.1亿人使用,这意味着CTR及其下游任务肯定会对这一人群产生至关重要的影响。
-
基于我们的观察,我们总结了对中文文本识别关注不足的三个潜在原因:
- 1)缺乏合理的数据集构建标准。理想情况下,基于给定的四边形方框,我们可以沿着标注点裁剪文本区域,然后将其校正为水平方向的图像,与直接使用最小边界水平方框的方法相比,可以有效地消除无用的背景区域。因此,不同的裁剪方法会导致不公平的比较。此外,从不同环境收集的数据集在外观上也有很大差异。找到合理的分割策略也有利于更有效的研究。因此,需要考虑数据集构建的标准。
- 2)缺乏统一的评价方案。通常,在评估英语文本数据集的识别模型时,研究人员通常默认将大写转换为小写。然而,目前还没有统一的CTR评价方案。例如,研究人员可能会对全宽和半宽字符、简体字和繁体字是否应该被视为同一字符感到困惑。此外,评价指标(如标准化编辑距离和准确率)在CTR论文中不一致。因此,迫切需要统一的评价方案来公平地评价CTR方法。
- 3)现有基线缺乏实验结果。现有的文本识别方法主要在IIIT5K、IC03、IC13 等英文文本数据集上进行评估。虽然很少有方法尝试在中文数据集上进行实验,但在相应的论文中并没有明确解释数据集构建的细节,这使得其他研究人员很难将其作为CTR基线。
-
在本文中,我们试图构建一个点击率的基准来填补这一空白。我们首先从公开竞赛、论文和项目中获得现有的CTR数据集,得到四个类别,即场景、网络、文档和手写(每个数据集的一些示例如下图所示)。我们还从人类校准的每个类别的可识别性方面证明了数据集构建的合理性。然后我们以合理的比例将每个数据集手工划分为训练集、验证集和测试集。验证集的目的是公平地比较现有的方法,即确保基于验证集选择最佳的超参数,以避免面向测试集的调优。
-

-
场景、web、文档和手写数据集中的一些示例。
-
-
此外,我们在收集的数据集上再现了一些有代表性的文本识别方法的结果作为基线。实验结果表明,一些最初针对英语文本提出的SOTA方法在CTR数据集上的表现不如英语数据集。通过分析,一个可能的原因是汉语文本的某些特点给现有的方法带来了障碍。针对汉字复杂的内部结构,我们采用多任务的方式引入激进层面的监督,以更好地识别汉字。总的来说,我们的贡献可以列出如下:
- 我们从公开竞赛、论文和项目中手动收集 CTR 数据集。然后我们将它们分为四类,即场景、web、文档和手写数据集。我们进一步以合理的比例将每个数据集分成训练集、评估集和测试集。
- 我们标准化了评估协议,以公平地比较现有的文本识别方法。
- 基于收集的数据集和标准化的评估方案,我们再现了一系列基线的结果,并详细分析了基线的性能。
- 我们在CTR中引入 radical-level 监督,以提高现有的基于注意的识别器的性能。
Preliminaries
Hierarchical Representations for Chinese Characters
-
这里我们介绍汉字的三种表示方式(参见下图(a)中的示例“奇”),即字符级、部首级和笔画级。
-

-
汉字表示的初步知识。
-
-
字符等级。根据中国国家标准GB18030-2005【https://zh.wikipedia.org/wiki/GB_18030】,汉字总数为70244个,其中一级常用字符为3755个。
-
Radical level(偏旁部首级别). 根据具体描述字符的Unicode标准 【https://unicode.org/charts/PDF/U2FF0.pdf】,一级常用汉字共有12个偏旁结构(见上图(b))和514个偏旁。对于3755个常用汉字,根级表示可以有效地将字母表的大小从3755个减少到526个。
-
笔画级别:根据Unicode Han Database 【http://www.unicode.org】,每个汉字都可以分解成一个笔划序列。笔画有五种基本类型(例如,水平、垂直、左向、右向和转弯),每种类型都包含几个实例(参见图©)。
Characteristics of Chinese Texts
- 中文文本比英文文本更难识别,这是学界公认的事实。为了探究其内在原因,我们分析了汉语语篇不同于英语语篇的特点:
-
大量的字符。根据国家标准GB18030-2005,汉字总数为70,244个(其中常用一级字符3,755个)。它比英文字符的比例要大得多,英文字符只包含26个大写字母和26个小写字母(见下图(a))。一方面,进行大规模分类本质上是一项艰巨的任务。另一方面,在CTR数据集上进行实验时,识别器可能会遇到具有挑战性的 zero-shot 问题,即待测试的字符可能不在训练集中。
-
类似的外观。与英文字母相比,有相当多的汉字簇具有相似的外观(见图(b))。例如,“戌”和“戍”之间的区别仅仅在于一个微小的笔划。即使人眼也很难识别,这给现有的文本识别方法带来了负担。
-
复杂的顺序模式。我们观察到,现有英语基准中的大多数样本都处于单词水平。由于两个英语单词之间有一个空格,人们在标记过程中倾向于将它们分开来进行检测。此外,英语单词中存在固有的统计模式(例如,“abl”后面更可能跟着“e”),从而帮助识别器更好地捕捉顺序模式。相反,中文文本更多地出现在短语或句子中。在这种情况下,汉字之间在词性上存在复杂的依赖关系(见下图©),这确实给识别器学习顺序模式带来了困难。
-
常见的垂直文本。与英语文本相比,由于自然场景中常用的传统对联或招牌,中文文本更倾向于垂直呈现。相反,由于人们固有的阅读习惯,垂直英语文本很少出现(见下图(d))。
-
复杂的内部结构。如2.1所述,与英语的单成分汉字不同,汉字大多是多成分的(见上文图(a)),即每个汉字都可以分解成几个由词根结构组织起来的词根。更复杂的内部结构使得汉字分类更加困难。
-

-
汉语文本区别于英语文本的特点。
-
Datasets
Details of Datasets
-
场景数据集。从竞赛、论文和项目中,我们获得了一系列场景数据集,包括RCTW、ReCTS、LSVT、ArT和CTW。每个数据集的详细介绍如下:
- RCTW:
提供12263张自然场景的中文标注文本图像。我们从训练集中获得了44,420个文本图像,并将它们用于基准测试。由于文本标签不可用,所以没有使用RCTW的测试集。 - ReCTS:提供2.5万张带标注的
街景中文文本图像,主要来源于广告牌。我们只采用训练集和裁剪107,657个文本样本作为基准。 - LSVT:它是一个大规模的中英文场景文本数据集,
提供了50,000个全标记(多边形框和文本标签)和400,000个部分标记(每个图像只有一个文本实例)样本。我们只使用全标记的训练集并裁剪243,063个文本图像作为基准。 - ArT:它包含在具有
各种文本布局(例如,旋转文本和弯曲文本)的自然场景中捕获的文本样本。在这里,我们从训练集中获得了49,951个裁剪的文本图像,并将它们用于我们的基准测试。 - CTW[29]:包含3万张带标注的街景图像,具有丰富的多样性,包括凸起文本、遮挡文本、光照不足文本等。此外,它不仅提供字符框和标签,还提供字符属性,如背景复杂性,外观等。这里我们从训练集和测试集裁剪191364个文本图像。
- RCTW:
-
我们结合上述所有数据集,得到636,455个文本样本。我们随机对这些样本进行洗牌,并按8:1:1的比例进行分割,得到509,164个样本用于训练,63,645个样本用于验证,63,646个样本用于测试。
-
网络数据集。为了收集web数据集,我们使用了MTWI,它包含了淘宝网站上17个不同类别的20000张中英文web文本图像。文本样本出现在各种场景、排版和设计中。我们从训练集中提取了140589张文本图像,并按8:1:1的比例进行手动分割,得到112471张样本用于训练,14059张样本用于验证,14059张样本用于测试。
-
文档数据集。我们使用公共存储库Text Render 【https://github.com/Sanster/text_renderer】来生成一些文档样式的合成文本图像。更具体地说,我们对长度从1到15不等的文本进行统一采样。语料库来自维基、电影、亚马逊和百度。该数据集共包含500,000个数据集,随机分为训练集、验证集和测试集,比例为8:1:1 (400,000 v.s. 50,000 v.s. 50,000)。
-
手写体数据集。我们基于SCUT-HCCDoc收集手写数据集,
该数据集在无约束环境下用相机捕获中文手写图像。根据官方设置,我们获得93,254个用于训练的文本图像和23,389个用于测试的文本图像。为了进行更严谨的研究,我们以4:1的比例手动将原始训练集分成两组,得到74603个样本用于训练,18651个样本用于验证。为方便起见,我们继续使用原来的测试集。 -
所采用数据集的许可证。RCTW、ReCTS、ArT、LSVT、MTWI等数据集在发布时没有相关的开源许可。因此,
我们已经联系了这些数据集的所有者,并确认它们可以用于学术研究。数据集CTW使用Attribution-NonCommercial-ShareAlike 4.0 International(简称CC BY-NC-SA 4.0 【https://creativecommons.org/licenses/by-nc-sa/4.0/】)许可协议,授权用户以任何媒介或格式复制和再分发该材料。在SCUT-HCCDoc的GitHub【https://github.com/HCIILAB/SCUT-HCCDoc_Dataset_Release】存储库中,作者已经声明该数据集只能用于非商业研究目的。此外,我们已经联系了数据集的作者,并获得了学术研究的许可。
Preprocessing
- 在这里,我们提出了四个步骤来预处理收集到的四类数据集:1)保留包含其他语言的文本图像。我们观察到,现有的CTR数据集以中文字符为主,同时包含少量英文字符和其他语言(见下图(a))。考虑到自然场景中文本图像的语言分布,我们决定保留带有其他语言字符的样本。2)移除标注为“###”的样本。根据一些数据集的标注标准(如RCTW和ReCTS),将难以辨认的文本图像标注为“###”(见图(b))。我们观察到这些样本中存在严重的模糊或遮挡,即使人眼也难以识别。
考虑到这些样本可能会给训练过程带来噪声,我们决定将其从数据集中去除。3)构建单独的验证集。通过观察,现有的英语文本识别基准通常缺乏验证集。实际上,在训练阶段,测试集是不可用的,需要根据在验证集上的表现来选择最佳模型。在这里,我们考虑了验证集,以进行更严格的研究(参见图©)。4)只收集有可用文本标签的样本。我们观察到,许多测试集的文本标签是不可公开的,特别是那些竞争数据集。在这种情况下,我们只使用那些带有可用标注文本标签的示例。-

-
预处理收集到的数据集的步骤。
-
Analysis of Datasets
-
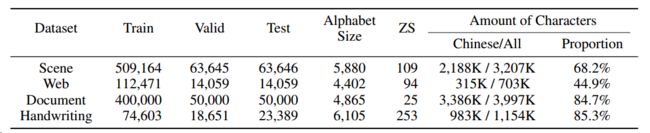
字母大小和字符数量。在下表中,我们可以看到四个数据集的字母表大小和汉字比例有所不同。例如,大多数网络文本都是中文广告,有固定的短语表达,因此在字母表中包含的字符较少(4402个字符)。此外,web数据集包含许多电话号码和英文网站,导致汉字在四个数据集中所占比例最低(44.9%)。对于手写数据集,大多数文本是中国古诗,其中包含比其他数据集更多的不常用字符,因此产生了最大的字母表(6105个字符)。因此,手写数据集的测试集包含了训练集中没有的最多的 zero-shot 字符(253个 zero-shot 字符),这进一步增加了识别的难度。
-
-
统计字母表大小和字符数量的结果。“中文”、“全部”、“比例”分别表示汉字的数量、全部汉字、汉字的比例。“ZS”表示测试集中zero shot 字符的数量。
-
-
下两张图展示了文本长度和长宽比(即宽度与高度的比值)的分布。从这些图中,我们观察到长文本(例如长度≥10)在手写数据集中出现的频率更高,这给基线带来了困难。相反,场景和web数据集中的文本相对较短,可能是考虑到乘客、顾客等的阅读效率。对于比例分布,我们观察到由于野外常用的对联和招牌,场景数据集比其他数据集具有更多的垂直文本(比例≤1)。相比之下,手写数据集包含更多的水平文本。
-
字符和词频。如下表所示,我们分析了每个数据集中字符和单词的频率【用“jieba”把文本拆成单词。https://github.com/fxsjy/jieba】,并观察到一些有趣的现象。例如,由于自然场景中有许多中国品牌或国有企业,因此“
中”、“国”和“中国”一词在场景数据集中频繁出现。此外,网络数据集包含许多高频广告术语,如“包邮”(免费送货)、“正品”(认证产品)等。由于文档和手写体数据集中的样本多为中文句子,因此助词“的”出现频率最高。特别是,在手写数据集中,由于一些文本图像是从日记中裁剪出来的,因此有许多字符或单词指代诸如“我”、“你”、“我们”等。-

-
每个数据集中的前六个高频字符和单词(括号中的频率)。
-
-
人类的可识别性校准。为了找出四个数据集中影响文本图像可识别性的因素,我们邀请了20名受过高等教育的参与者来进行这个实验。我们邀请参与者从不同的角度找出阻碍可识别性的相应原因(多选):1)遮挡(前景),2)倾斜或弯曲(实例级),3)背景混乱(背景),4)涂鸦(字符级),5)模糊(图像源)。如果任何一个原因都不满足,我们认为文本图像是可识别的。总的来说,我们对每个数据集有500票(每个数据集有25个图像样本,20个参与者)。统计数据如下表所示。
-

-
人类校准的可识别性统计结果(BG为背景)。
-
-
我们可以看到,在场景数据集中,参与者的投票主要集中在“遮挡(Occlusion)”,“背景混淆(Background Confusion)”和“模糊(Blur)”,这表明它是人类识别最复杂的数据集。影响文本图像可识别性的因素主要来自于野外环境和文本图像的获取方式。对于web数据集,通过可控生成,文本外观可以更加多样化,导致“斜或弯(Oblique or Curved)”选择的票数最多。对于文档数据集,样本对于人类来说是相对可识别的,因此较少投票。在笔迹数据集中,参与者投票最多的是“潦草(Scribble)”,这表明笔迹中的笔画衔接也是阻碍可识别性的基本因素。从上面的观察中,我们可以发现影响可识别性的因素在不同的数据集上是不同的,因此激励我们分别研究每个数据集上的性能。

Baselines
- 文本识别在过去十年中取得了迅速的进展。根据文本识别方法的主要特点,可以将其分为基于ctc的方法、基于纠偏(rectification-based)的方法等。从这些类别中,我们选择了八种代表性的方法作为基准,这些方法在文本识别任务中主要用于比较。
-
CRNN 是一种典型的基于ctc的方法,在工业中应用广泛。它将文本图像发送给CNN提取图像特征,然后采用两层LSTM对序列模式进行编码。最后,LSTM的输出被馈送到CTC (Connectionist Temperal Classification)解码器,以最大化所有路径通向 GT 的概率。
-
ASTER 是一种典型的基于校正的方法,旨在处理不规则文本图像。它引入了一个空间变换网络(STN) 来校正给定的文本图像。然后将校正后的文本图像发送给CNN和两层LSTM进行特征提取。特别地,ASTER利用注意机制来预测最终的文本序列。
-
MORAN 是一种具有代表性的基于校正的方法。它首先采用多目标整流网络(MORN)以弱监督的方式预测整流像素偏移(不同于ASTER采用STN)。输出的像素偏移量进一步用于生成校正后的图像,该图像进一步发送到基于注意力的解码器(ASRN)进行文本识别。
-
SAR 是利用二维特征映射实现更鲁棒解码的代表性方法。与CRNN、ASTER 和 MORAN 将给定图像压缩成一维特征图不同,SAR采用二维关注特征图的空间维度进行解码,在弯曲和倾斜文本中具有更强的性能。
-
SEED 是一种具有代表性的基于语义的方法。引入语义模块提取全局语义嵌入,并利用它初始化解码器的第一隐藏状态。得益于在识别过程之前引入语义,
SEED解码器在识别低质量文本图像方面显示出优势。 -
MASTER 是一种基于注意的方法,它利用自注意机制来学习对扭曲文本图像的更强大和鲁棒的表示。同时,得益于训练并行化和内存缓存机制,该方法训练效率高,推理速度快。
-
ABINet 是一种自主、双向、迭代的场景文本识别方法。自主原则是
指视觉模型和语言模型应该分开学习;提出了双向原则,以捕获两倍的信息量;迭代原则旨在从视觉和语言线索中改进预测。此外,作者提出了一种自我训练方法,使ABINet能够从未标记的图像中学习。 -
TransOCR 是基于transformer的代表性方法之一。它最初的设计目的是为超分辨率任务提供文本先验。采用ResNet-34作为编码器,自关注模块作为解码器。与基于 rnn 的解码器不同,自注意模块更有效地捕获给定文本图像的语义特征。
-

-
四个数据集的基线结果。ACC / NED分别采用百分制和十进制。
-
- 通过基线的实验结果(细节将在第5节中介绍),我们观察到由于中文文本的特点,基线在CTR数据集上的表现不如在英文数据集上的表现(参见第2.2节)。针对汉字复杂的内部结构,我们提出了一个可插入的词根感知分支(PRAB),它可以插入到任何基于注意的识别器中,以多任务的方式引入词根级监督,以提高识别效果。关于PRAB的更多细节见补充资料。
An Empirical Study
Experiments
-
实现细节。我们在Github上采用CRNN、ASTER、MORAN、SAR、SEED、MASTER、ABINet和TransOCR的现成PyTorch实现,在收集到的CTR数据集上重现实验结果。所有基线实验均在 11GB 内存的NVIDIA RTX 2080Ti GPU上进行。为了保持现有识别器的时间效率,并使文本图像对识别器更具可识别性,我们将所有实验的输入图像大小调整为32 × 256。我们利用每个数据集的验证集根据识别精度选择最佳超参数,然后使用测试集评估基线。为了方便起见,我们将所有实验的四个数据集的字母表组合在一起,得到了一个总共7934个字符的字母表。基线没有使用数据增强和预训练等其他策略。
-
评估协议。在实践中,统一的评价方案对于公平比较是必不可少的。在ICDAR2019 ReCTS Competition【https://rrc.cvc.uab.es/?ch=12&com=tasks】之后,我们利用一些规则来转换预测和标签:(1)将全宽字符转换为半宽字符;(2)将繁体字转换为简体字;(3)将大写字母转换为小写字母;(4)清除所有空格。在这些转换之后,我们利用广泛使用的度量精度(ACC)来评估基线。此外,由于CTR数据集比英文文本识别数据集包含更多的长文本图像,因此使用归一化编辑距离(NED)来综合评估基线的性能。ACC 和 NED 的取值范围均为[0,1]。较高的ACC 和 NED 表明评估基线的表现较好。
-
实验结果。我们首先分析不同方法的实验结果(见上表)。我们观察到,CRNN在每个数据集上的性能都优于那些基于注意力的普通识别器(即MORAN , SEED和SAR),后者在遇到较长中文文本的文本图像时容易出现注意力漂移问题(drift problem)。虽然CRNN在场景数据集上的性能不如基于 Transformer 的方法,但CRNN的参数更少,推理时间更短。此外,我们注意到SEED并不是在所有数据集上都表现良好。一个可能的原因是SEED需要将每个文本图像映射到 fastText 引导下对应的语义嵌入,而中文文本通常包含复杂的语义,这给语义学习过程带来了困难。显然,TransOCR超越了所有同类算法,因为它能够更灵活地对序列模式进行建模。
-
接下来,我们从数据集的角度对实验结果进行分析。如上表所示,由于该数据集中的潦草,所有基线在手写数据集上的性能都不太好。如上上表所示,手写数据集中几乎40%的文本样本被标记为“Scribble”。实际上,写作者可能会加入或省略一些笔画来加快书写速度,这确实给现有的方法带来了困难。相反,由于文档数据集中的文本样本与其他三个数据集相比具有更高的可识别性,因此所有基线的识别准确率都可以超过90.0%。虽然场景数据集中包含了更多的样本,但一些问题(如遮挡、背景混淆、模糊等)仍然对基线方法提出了挑战,导致场景数据集中的性能相对较差。对于web数据集,所有基线的性能都低于场景数据集,这可能源于训练样本的稀缺性。
Discussions
- 对合成数据集进行预训练。考虑到以前的英语文本识别方法倾向于在大规模合成数据集上进行训练,我们还生成了一个合成CTR数据集来预训练基线模型,以进一步提高性能。关于合成CTR数据集和实验结果的详细信息见补充材料。通过大量的实验,我们观察到用合成数据集预训练基线模型在大多数情况下确实可以提高性能。虽然使用了大型合成数据集进行预训练,但由于中文文本的特点,基线模型仍然无法达到预期的性能。
- PRAB的有效性。考虑到汉字可以根据cjkvi-ids 【https://github.com/cjkvi/cjkvi-ids】将每个汉字分解为特定的部首序列的特点,我们提出了一个可插入的部首感知分支(Pluggable radical - aware Branch, PRAB),为每个汉字引入更细粒度的监督(即部首)。我们进行了大量的实验来评估PRAB的有效性,将其用于第4节中提到的所有基于注意力的方法。通过实验结果(见补充材料),我们观察到,当所提出的PRAB用于提供激进级监督时,基于注意力的识别器在四个数据集上表现更好,这验证了PRAB的有效性。其中,PRAB对MORAN、SAR和TransOCR的平均准确率分别提高了1.83%、3.35%和2.33%。
- 疑难案例分析。我们手动选择一些困难的情况【我们在场景和web数据集中手动挑选100个遮挡样本,100个倾斜或弯曲样本,100个混淆背景样本,100个垂直样本,500个模糊样本】(例如,遮挡,倾斜或弯曲,令人困惑的背景,模糊和垂直),并分析这些情况下基线的性能。请注意,“潦草”情况主要与手写数据集相关,因此我们不会单独分析“潦草”情况。这些 hard 情况下的实验结果见下表。特别是,我们观察到TransOCR与其他基线相比,可以很好地适应每种困难情况。得益于自关注模块,识别器可以轻松处理不常见的文本布局,如倾斜和弯曲,或减轻混淆前景(遮挡)或混淆背景引起的噪声。有趣的是,与TransOCR相比,ASTER在大多数情况下实现了更好的NED,因为ASTER利用的STN增加了对具有一定倾斜程度的 hard 样品的识别。此外,基于ctc的CRNN简单地将原始输入转换为一维特征,因此在垂直文本图像上表现不佳。总的来说,在这些困难的情况下,仍有很大的改进空间。
Conclusions
- 本文首先讨论了对中文文本识别缺乏关注的可能原因。为了解决这些问题,我们收集了公开可用的数据集,并将它们分别分为场景、web、文档和手写数据集。我们还分析了每个数据集的特征。然后,我们规范了CTR中的评价协议(如研究者是否应将繁体和简体汉字视为同一字符),使不具备汉字知识的研究者也能参与到CTR研究中来。最后,我们在收集到的数据集上采用了8种具有代表性的方法作为基线。通过实证研究,我们观察到结合汉字知识有助于中文文本识别任务,这也为今后的CTR工作提供了指导。
A Details of PRAB
- 通过基线的实验结果,我们观察到现有识别器在收集的CTR数据集上的性能不如在英文数据集上的性能。一个可能的原因是汉字的特征与拉丁字母的特征大不相同。考虑到每个汉字都可以被分解成一个特定的词根序列,我们提出了一个可插入词根感知分支(Pluggable radical-aware Branch, PRAB)来引入更细粒度的监督(即词根),使识别器能够捕获词根感知特征,从而更好地识别汉字。如下图所示,我们的方法框架可以分为三个部分:共享特征提取器、识别分支和PRAB。
PRAB与识别器共享特征提取器,并使用识别器的注意掩码裁剪每个字符的特征映射。通过基于 Transformer 的解码器,每个字符被解码成一个根序列,根序列的监督是现成的,如[Denseran for offline handwritten chinese character recognition]所述。-

-
我们方法的框架。红色箭头表示的数据流仅用于训练阶段。
-
A.1 Shared Feature Extractor
- 在这里,我们使用 TransOCR 作为基线,因此使用ResNet-34作为共享特征提取器。为了为PRAB保留更多的空间信息,我们在ResNet-34中删除了最后三个下采样层,因此共享特征提取器后的特征映射 F t e x t F_{text} Ftext 的维度为 H 4 × W 4 × C \frac H4 × \frac W4 × C 4H×4W×C,其中H和W表示输入文本图像的高度和宽度。
A.2 Recognition Branch
- 为了给 PRAB 提供 attention masks,我们应该
采用二维的基于注意的识别器,即TransOCR。在这里,识别器可以被任何其他基于二维注意力的识别器所取代。为了使基于一维注意力的识别器(例如ASTER , MORAN和SEED)受益于所提出的PRAB,我们可以简单地将它们的解码器替换为二维注意力解码器。
A.3 Pluggable Radical-Aware Branch
- 通过共享特征提取器提取的特征映射 F t e x t F_{text} Ftext 与识别分支的注意掩模 M a t t M_{att} Matt 的位置相乘,我们可以得到与 F t e x t F_{text} Ftext 维数相同的每个字符 F c h a r F_{char} Fchar 的特征映射,即 H 4 × W 4 × C \frac H4 × \frac W4 × C 4H×4W×C。但是, F c h a r F_{char} Fchar 中包含了更多无用的特征。为了保留每个字符的相关特征,我们使用 1 × 1 的卷积层将特征 $F_{char}\in \R^{\frac H 4 × \frac W 4 ×C} $ 压缩成大小为 H 4 × H 4 × C \frac H 4 × \frac H 4 × C 4H×4H×C 的 F c h a r ′ F'_{char} Fchar′,然后将每个字符的压缩特征解码成相应的根式序列。受益于所提出的PRAB,共享特征提取器将捕获更多细粒度的偏旁部首级特征,以获得更好的字符识别。PRAB仅在训练阶段使用,不会引入额外的推理时间。
A.4 Experimental Results
- 如下表所示,采用本文提出的 PRAB 后,基于注意的方法的性能得到了进一步提高,因为PRAB引入了更细粒度的监督(即词根)来对字符进行分类。例如,在PRAB的帮助下,MORAN、SAR和TransOCR的平均准确率分别提高了1.83%、3.35%和2.33%。
-

-
采用所提出的PRAB的基线模型的实验结果。
-
B Pretrained with Synthetic Datasets
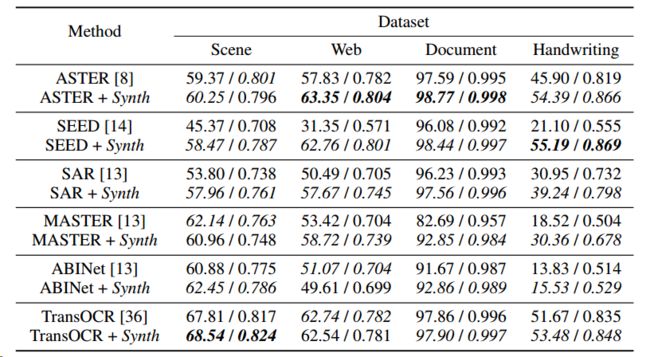
- 现有的场景文本识别器大多采用大规模的合成数据集进行预训练。因此,对于中文文本识别,我们也使用搜狗新闻https://github.com/lijqhs/text-classification-cn的语料库,通过文本生成器https://github.com/Belval/TextRecognitionDataGenerator生成一个包含20M样本的合成训练数据集。我们首先使用合成数据集对基线模型进行预训练,然后在四个收集到的数据集上对基线模型进行微调。实验结果(如下表所示)表明,在大多数情况下,使用生成的合成数据集进行预训练确实可以提高基线模型的性能。然而,这些为英语文本识别设计的基线模型仍然没有达到预期的性能。
-
-
用合成数据集预训练基线模型的实验结果。
-
C Visualization of Failure Cases.
- 我们在下面系列图中可视化了场景、web、文档、手写数据集的一些失败案例。特别地,我们从每个数据集中选出10个被所有基线错误预测的样本。作为显示在下图中,我们注意到,遮挡的文本(例如,“纽恩泰”、“财经天下”,“冰淇淋鸡蛋仔”,和“从小做起”)的确带来困难的识别器的前景可能会错误地认为部分文本。此外,还有一些极其困难的情况,如镜像文本(例如“麦当劳”),即使人眼也难以辨认。
-

-
Failure cases in the scene dataset.
-
- 对于web数据集中的失败案例,我们注意到基线很难处理具有艺术字体的文本图像(例如,“遇见”,“魅力端午节”,“没有地沟油”,“我爱姓名贴”)。
-

-
Failure cases in the web dataset
-
- 如下图所示,尽管文档数据集具有最高的可识别性,因为它是通过文本呈现合成的,但一些样本仍然对所有基线造成困难。我们注意到基线没有处理一些很少使用的字符(例如,“瑗”,“菘”和“轭”),从而错误地将它们视为其他类似字符。对于手写数据集,我们注意到连接或缺失的笔画可能会混淆基线(例如,“垂体”和“火夏”)。此外,一些带有长文本的图像可能会使基线难以捕获顺序模式。
-

-
Failure cases in the document dataset.
-

-
Failure cases in the handwriting dataset.
-