使用影刀开发脚本、Python正则表达式
十七周内容笔记
使用影刀
影刀这个工具还是比较简单,智能且强大,简单的描述一下定时发送天气预报的一个功能
首先是打开网页
选择浏览器,这里我选择的是谷歌浏览器
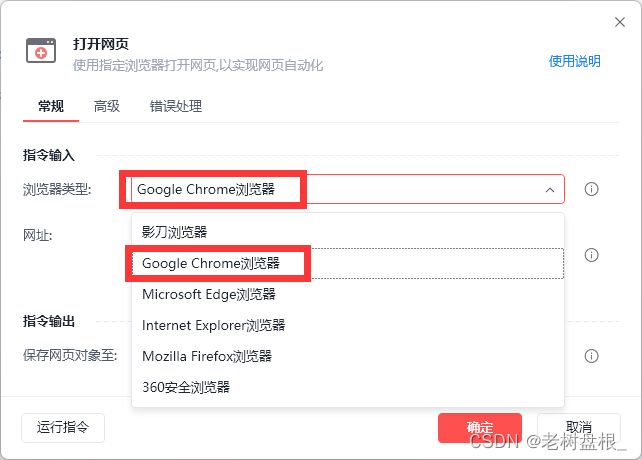
输入找到的天气预报的网址

接着我们打开网页,是这样式儿的
接着我们选择获取元素

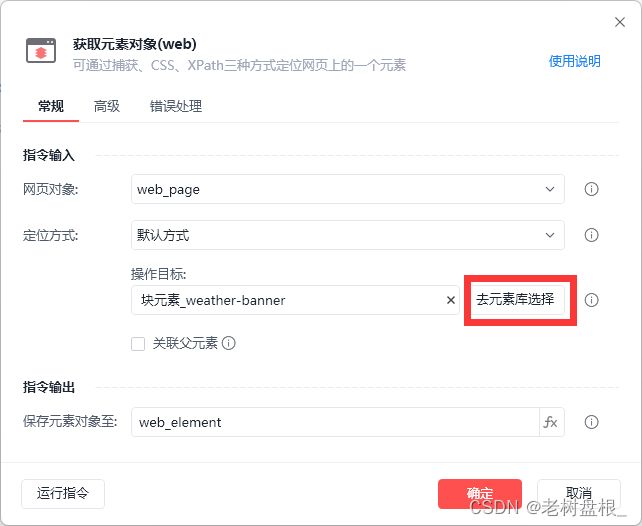
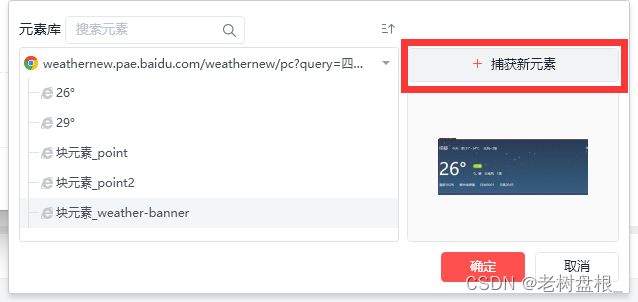
选择元素块
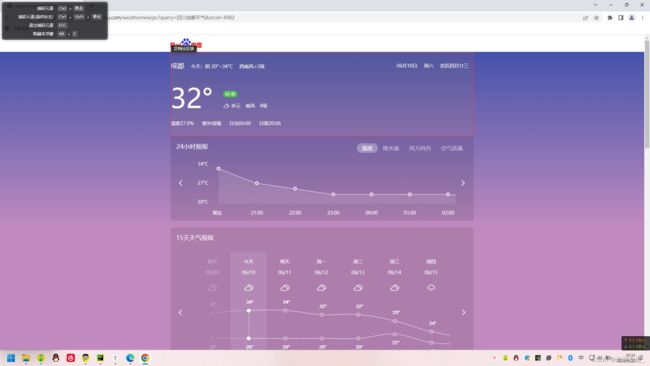
选择获取元素文本内容
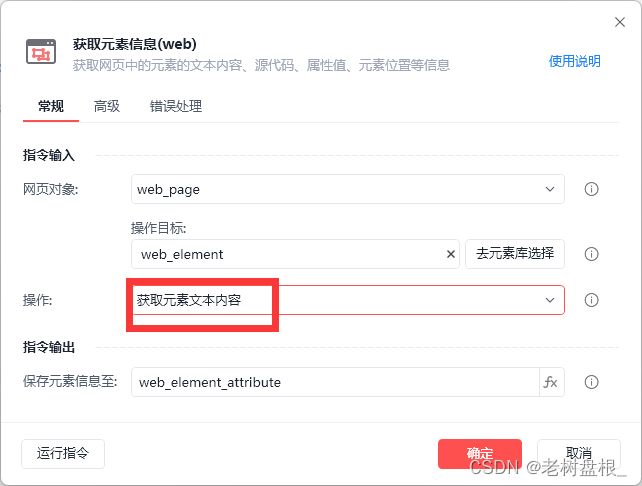
最后选择邮件发送
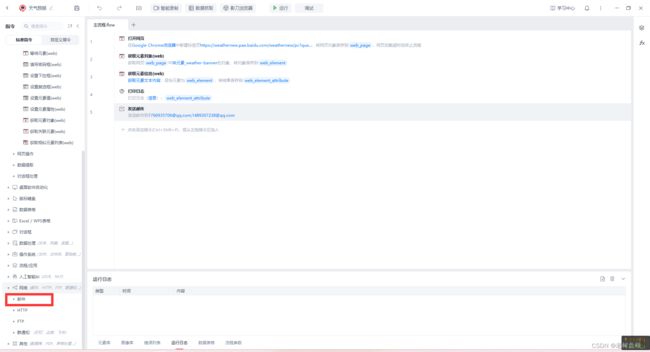

到目前为止就可以选择保存并发版

创建触发器

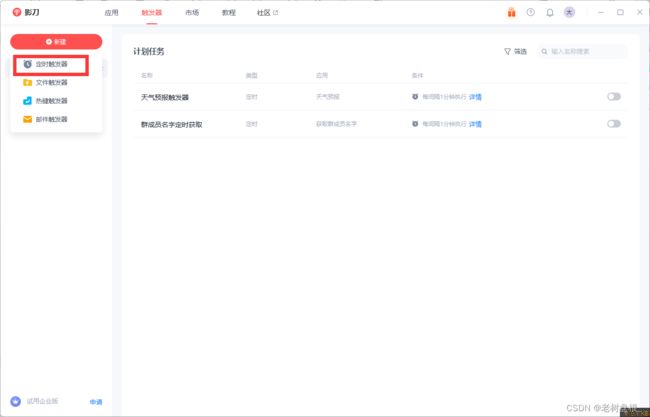
应用选择刚刚编辑好的天气预报
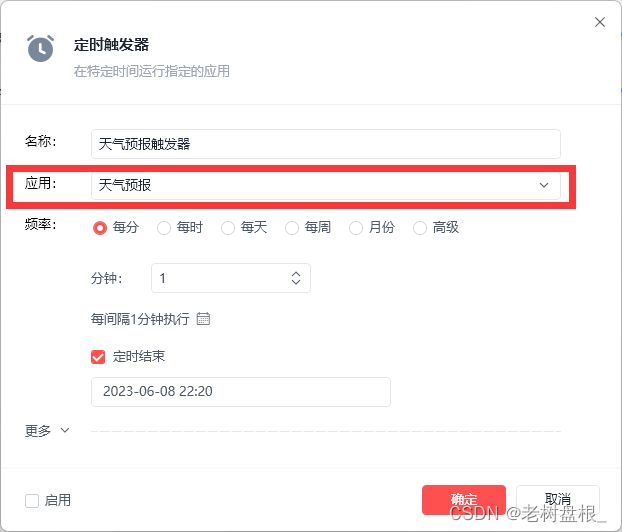
设定好时间就可以启动了。


影刀作为一款大厂工具,体验上真的要比后裔采集器好一点,无论是界面观感还是功能实现都要比后羿采集器好用一点。
day51
01-正则的匹配类符号
一、正则表达式
什么是正则?
1.正则是一种可以让字符串处理变得很简单的工具。
2.正则就是通过各种正则符号来描述字符串的规则。
3,在不同的编程语言中正则语法相同,但是表达方式不同。
二、如何描述字符串(正则符号)
import re
# 1.普通字符在正则中表示这个符号本身-->普通符号
re_str = 'abc'
str_1 = '123abc456abcd'
result = re.findall(re_str, str_1)
# findall(正则符号,普通字符串):从普通字符串中按照正则符号匹配出所有符合的元素
print(result)
# 返回:['abc', 'abc']
# 2.匹配任意字符(通配符),使用.(点)-->通配符
re_str_1 = 'a.c'
result = re.findall(re_str_1, 'abca1ca2cacca22c')
print(result)
# 返回:['abc', 'a1c', 'a2c', 'acc']
# 3.匹配一个任意数字--> \d,匹配一个任意非数字--> \D
result = re.findall('a\dc', 'abca1ca2cacca22c')
print(result)
# 返回:['a1c', 'a2c']
result = re.findall('a\Dc', 'abca1ca2cacca22c')
print(result)
# 返回:['abc', 'acc']
# 4.匹配一个空白字符-->\s,匹配一个非空白字符-->\S
# 空白符号:空格、\n、\t等
result = re.sub('\s', '', 'abc\n123\t456 789')
# sub('正则符号',替换为什么, 从哪里匹配替换):按照正则符号去匹配,匹配到的结果替换为某符号
print(result)
# 返回:abc123456789
result = re.sub('\S', '1', 'abc\n123\t456 789')
print(result)
# 返回:111 111 111
# 5.匹配字母、数字、下划线--> \w(不重要)
# 其实\w 还可以匹配中文,但是一般不使用\w 匹配
result = re.findall('a\wc', 'abca1ca_cacca22ca-c')
print(result)
# 返回:['abc', 'a1c', 'a_c', 'acc']
# 6.匹配字符集中的出现过的任意一个符号-->[字符集]
# 注意:
# a.一个[]只能匹配一个符号。
# b.在[]中可以将 - 放在两个字符中间表示范围,必须保证 - 前面的符号的编码值小于 - 后面的编码值。
# c.在[]中 - 只有在两个字符之间才具有特殊意义,否则只是表示它本身,
# - 符号只能出现在 3 个位置:两个编码值符合规则的符号之间,或者[]最前面或者最后面。
# d.表示取反:在[]最开头写一个^
result = re.findall('[-1-9a-z_A-Z]', 'abcd1234-+ABCD')
# [-1-9a-z_A-Z]:匹配字符集中的任意一个符号
print(result)
# 返回:['a', 'b', 'c', 'd', '1', '2', '3', '4', '-', 'A', 'B', 'C', 'D']
result = re.findall('[^-1-9a-z_A-Z]', 'abcd1234-+ABCD')
# [^-1-9a-z_A-Z]:匹配不属于字符集中的任意一个符号
print(result)
# 返回:['+']
# [a1+]:匹配 a 或者 1 或者+
# [\dxy]:匹配任意一个数字或者 x 或者 y
# [\u4e00-\u9fa5]:匹配所有中文
# 匹配一个11位手机号,'手机号为12345678900'
result = re.findall('\d\d\d\d\d\d\d\d\d\d\d', '手机号为12345678900')
print(result)
# 返回:['12345678900']
02-正则的重复类符号
import re
# 重复类符号特点:要写在一个符号后面,表示针对这个符号的重复次数
# +:表示匹配一次或多次
result = re.findall('a+c', 'aaacaacacc')
print(result)
# 返回:['aaac', 'aac', 'ac']
# ?:表示匹配 0 次或 1 次
result = re.findall('a?c', 'aaacaacacc')
print(result)
# 返回:['ac', 'ac', 'ac', 'c']
# *:匹配任意次数
result = re.findall('a*c', 'aaacaacacc')
print(result)
# 返回:['aaac', 'aac', 'ac', 'c']
# {N, M}:控制匹配次数
# {N} -> 匹配 N 次
# {N, M} -> 最少匹配 N 次,最多匹配 M 次
# {N, } -> 最少匹配 N 次,上不封顶
# {, M} -> 最多匹配 M 次
result = re.findall('\d{11}', '手机号为12345678900, 身份证号为123456789000100101')
print(result)
# 返回:['12345678900', '12345678900']
# (重要)贪婪和非贪婪
# 在匹配次数不确定的时候,匹配分为贪婪和非贪婪,默认都是贪婪的。
# 贪婪:在能匹配成功的前提下,取一次匹配最多符号的结果。
# 贪婪:+、*、{N,}、{N, M}、{, M}
# (一次能匹配到 5 个符号、同时还能一次匹配到9个、10个、13个,贪婪一定是取13个)
result = re.findall('a.+b', 'amnmb123bblkb')
print(result)
# 返回:['amnmb123bblkb']
# 非贪婪:在能匹配成功的前提下,取一次匹配最少符号的结果。
# 非贪婪:如果不想使用贪婪匹配,直接在贪婪匹配基础上添加?
# +?、*?、{N,}?等
result = re.findall('a.+?b', 'amnmb123bblkb')
print(result)
# 返回:['amnmb']
# 案例:从 a 标签中匹配网址
html_source = '百度百度'
# 贪婪(错误结果)
result = re.findall('www.+com', html_source)
print(result)
# 返回:['www.baidu.com">百度# 非贪婪
result = re.findall('www.+?com', html_source)
print(result)
# 返回:['www.baidu.com', 'www.taobao.com']
03-正则的检测类符号
检测类符号:一个符号需要对应一个字符;检测类符号不影响匹配字符串的长度,只是在匹配成功以后对字符串做一次检测。
import re
# ^ -> 检测是否是字符串的开头
# 判断到 ^所在位置不是a33字符串的开头
# ^\d\d -> 判断^所在位置(第一个\d匹配出的元素)是否是字符串开头
result = re.findall('^\d\d', 'a33')
print(result)
result = re.findall('^a\d', 'a33')
print(result)
# 返回:['a3']
# $ -> 检测是否是字符串的结尾
result = re.findall('\d\d$', 'a33')
print(result)
# 返回:['33']
result = re.findall('a\d$', 'a33')
print(result)
# 返回:[]
04-正则的分组、分支、转义字符
分组就是将正则的某一部分使用()括起来看成一个整体,然后进行整体操作,在正则中一个()就是一个分组
import re
# 案例:获取第一组三位数组789
# 一整个正则表达式先将粗略的结果匹配出来 \d{3}ab
# 然后将需要获取的部分再加分许,就能使用findall只拿到分组部分
result = re.findall('\d{3}ab', '789ab788')
print(result)
# 返回:['789ab']
result = re.findall('(\d{3})ab', '789ab788')
print(result)
# 返回:['788']
# 获取 a 标签内的网址
html_source = ' 百度淘宝'
result = re.findall('a href="(www.+?com)"', html_source)
print(result)
# 返回:['www.baidu.com', 'www.taobao.com']
# 如果分组套分组,每一个大分组和每一个小分组匹配的结果会组成一个元组
html_source = '百度淘宝'
result = re.findall('a href="(www(.+?)com)"', html_source)
print(result)
# 返回:[('www.baidu.com', '.baidu.'), ('www.taobao.com', '.taobao.')]
# 二、分支使用|
# 正则1|正则2 -> 分支其实就是或者
result = re.findall('abc([1-9]{3}|[a-z]{2})', 'abcaa123')
print(result)
# 返回:['aa']
result = re.findall('abc[1-9]{3}|[a-z]{2}', 'abcaabc123')
print(result)
# 返回:['ab', 'ca', 'abc123']
# 三、转义符号:\
# \被添加到某个正则符号前面,能够将这个正则符号转为普通符号
# 获取www.和.com之间只有5个符号的网址
html_source = '百度淘宝'
result = re.findall('="(www\..{5}\.com)"', html_source)
# www\.在正则中表示www.这四个普通符号
print(result)
# 返回:['www.baidu.com']
# \\d 表示什么? -> \d
result = re.findall('\\\d', 'a\d1c')
print(result, result[0])
# 返回:['\\d'] \d
# 列表:列表中的元素如果是字符串,那么这个字符串会完整显示
百度淘宝'
result = re.findall('a href="(www.+?com)"', html_source)
print(result)
# 返回:['www.baidu.com', 'www.taobao.com']
# 如果分组套分组,每一个大分组和每一个小分组匹配的结果会组成一个元组
html_source = '百度淘宝'
result = re.findall('a href="(www(.+?)com)"', html_source)
print(result)
# 返回:[('www.baidu.com', '.baidu.'), ('www.taobao.com', '.taobao.')]
# 二、分支使用|
# 正则1|正则2 -> 分支其实就是或者
result = re.findall('abc([1-9]{3}|[a-z]{2})', 'abcaa123')
print(result)
# 返回:['aa']
result = re.findall('abc[1-9]{3}|[a-z]{2}', 'abcaabc123')
print(result)
# 返回:['ab', 'ca', 'abc123']
# 三、转义符号:\
# \被添加到某个正则符号前面,能够将这个正则符号转为普通符号
# 获取www.和.com之间只有5个符号的网址
html_source = '百度淘宝'
result = re.findall('="(www\..{5}\.com)"', html_source)
# www\.在正则中表示www.这四个普通符号
print(result)
# 返回:['www.baidu.com']
# \\d 表示什么? -> \d
result = re.findall('\\\d', 'a\d1c')
print(result, result[0])
# 返回:['\\d'] \d
# 列表:列表中的元素如果是字符串,那么这个字符串会完整显示
06-re模块常用方法
findall(正则,字符串):获取字符串中所有满足正则表达式的子串,返回一个列表。
sub(正则,字符串1,字符串2):替换,将字符串2中满足正则的子串替换为字符串1。
split(正则,字符串):将字符串中满足正则的子串进行切割。
fullmatch(正则,字符串):判断正则是否能完全与字符串匹配,如果能匹配,返回匹配对象,否则为None。
match(正则,字符串):判断字符串开头部分是否与正则匹配,如果能匹配,返回匹配对象,否则为None。
search(正则,字符串):从字符串中查找第一个满足正则的子串,如果查找成功,返回查找对象,否则为None。
import re
str1 = 'a1ca2ca3ca4c'
print(re.match('a.c', str1))
# 返回: