大模型时序应用——基于对比学习的时序数据embedding
本文是由北京大学和阿里联合发布的大模型应用研究论文,总结了使用今天的语言模型(LLM)完成时间序列(TS)任务的两种策略,并设计了一种适合于LLM的TS嵌入方法——TEST——来激活LLM对TS数据的能力,在llm对TS分类和预测任务中达到了接近SOTA的能力,通过将LLM作为模式机器,让LLM可以在不影响语言能力的情况下处理TS数据。
TEST: Text Prototype Aligned Embedding to Activate LLM’s Ability for Time Series
Chenxi Sun, Yaliang Li, Hongyan Li, Shenda Hong(2023, August).
Peking University, Alibaba Group
1. 背景和问题
将时间序列(Time Series, TS)与LLM融合的方式有两条路线:
(1)LLM-for-TS:针对TS数据,从头开始设计并预训练一个基本的大型模型,然后为各种下游任务相应地微调模型;
(2)TS-for-LLM:基于现有的LLM,使它们能够处理TS数据和任务。不是创建一个新的LLM,而是设计一些机制来为LLM定制TS。
第一种方法是最基本的解决方案,因为预训练是向模型灌输知识的关键步骤。而第二种方法实际上很难超越模型的原始能力。囿于如下三个原因,本论文仍然关注第二种方法:
-
数据:TS通常为专业数据,难以大量获取;
-
模型:LLM-for-TS专注于垂直行业,跨领域需要重新建立,而TS-for-LLM可以插件化,几乎不需要训练,更加通用和方便;
-
用途:LLM-for-TS适合涉及专家的情况,TS-for-LLM保持了LLM的文本能力,同时提供丰富的补充语义,易于访问和用户友好。
基于预训练的LLM,如果将TS视为文本数据,可能的形式是:
[Q] 通过以下平均动脉压力序列(单位:毫米汞柱)判断患者是否患有败血症:88、95、78、65、52、30。
[A] 是的
然而,TS通常是多变量的,而文本是单变量的。处理单变量文本的LLM会将多变量TS转化为多个单变量序列并逐一输入它们。这样有三个缺点:
-
不同的prompts、顺序和连接语句会产生不同的结果;
-
长输入序列可能使LLM效率低下,难以记住前一个单变量TS;
-
TS中的多变量依赖性的关键方面将被忽略。
于是,本论文对TS进行了token化,设计了一个嵌入TS token的模型,并替换了LLM的嵌入层。核心就是创建能够被LLM理解的嵌入。
SOTA方法通过图像的文本描述来对齐文本嵌入和图像嵌入。但是TS缺乏视觉线索,并且存在标注瓶颈,只有少量TS,如ECG,适合转化为文本描述。自监督对比学习可以利用固有信息设计pretext任务,而不是依赖预先定义的先验知识,从而避免标注瓶颈。但是无约束对比学习生成的表示向量很可能与LLM的认知嵌入空间有很大的偏离。
本文提出Text embedding space of LLM (TEST)方法,在对比学习基础上,使用以正交文本嵌入向量为原型约束TS的嵌入空间,并通过识别特征原型来突出模式,激活LLM的模式机能力。
2. 方法介绍
Text embedding space of LLM (TEST)总共分为两步:
(1)将TS token化,并训练编码器一个encoder,用对比学习表征TS tokens;
(2)创建prompts,使LLM对表征更开放,并实现TS任务。
2.1 TS Token增强和编码
-
tokenize和embedding
Token化:
一个多变量时间序列有D个变量和T个时间点;
被分割函数Fs: x →s分割成 K个不重叠的子序列组成的列表;
每一段长度是随机的;
s 为时间序列x的token列表;
Fs 通常是滑动窗口;
使用随机的长度分割TS,得到许多标记 s.
Encoding:
每个token 都可以通过一个嵌入函数 嵌入到一个M维的表示空间中;
.
-
构造对比学习正负样本
· 定义一个TS标记 s 作为锚点实例;
· 正样本s+,定义两个获取来源:
(1)重叠实例:使用与 s 有重叠样本的实例
(2)增强实例:——对原序列加噪声和缩放,——对序列进行随机分割并打乱;
· 负样本:与s不具有重叠样本的实例;
· token表征:利用映射函数,将每个token映射为M维的表征
对于获得的token,首先通过目标函数来保证e能够充分表征原始序列信息,其中是decoder,将embedding还原成token。
2.2 Instance-wise对比学习
对于构造的正负实例,保证目标anchor instance 与其对应的正token instance 尽可能相似,与负 token instance 差异尽可能大。基于实例的对比损失如下:

然而,instance-wise对比学习倾向于将没有重叠样本,但位置相近且语义相似的样本视为负样本。于是本文引入feature-wise对比学习,关注不同列所包含的语义信息。

2.3 Feature-wise对比学习
Figure 1中,特征矩阵由一个minibatch中的实例表征后的向量组成,每一行是每个实例的embedding,因此可以将行视为公式(1)中使用的实例的软标签,每一列可以进一步视为聚类表示,但基于聚类的方法需要先验知识确认簇类数量,并不适合本文的无监督场景,所以本文将列视为特征的软标签,并对相似特征的组进行区分。
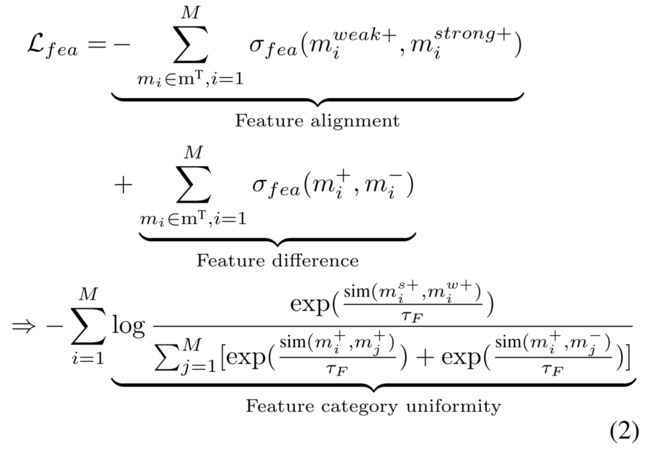
其中,
, .
weak+和strong+都是m+的一部分。
上述目标函数保证对于每个feature级别,正样本间尽可能相似,负样本间差异尽可能大。但是这样容易导致特征表示收缩到一个较小的空间,因此目标函数的最后一项最大化不同特征间差异。
2.4 Text-prototype-aligned对比学习
为了让LLM更好地理解构建的TS-embedding,本文设计了text-prototype-aligned contrast learning,将其与文本表示空间进行对齐。目前预训练的语言模型已经有了自己的 text token embedding, 例如,GPT-2 将词汇表中的文本token嵌入到维度为 768、1024 和 1280 的表示空间中。
本文强制地将时间序列标记 e 与文本标记 tp 进行对齐。比如,虽然TS-embedding可能缺少对应相关的文本表述,但是可以拉近其与例如数值、形状和频率等描述文本的相似度。通过这种形式的对齐,TS token 就有可能获得表征诸如时间序列大、小、上升、下降、稳定、波动等丰富信息的能力。
然而在实际情况中,因为无法提供监督标签或者真实数据作为基准,上述文本时序对齐的结果很可能无法完全符合现实。例如,具有上升趋势的子序列的嵌入可能非常接近下降文本的嵌入,甚至可能是不描述趋势的文本的嵌入。但对本文来说,语义是否可以被人类理解并不重要。
为了更好地匹配TS-embedding和文本token,文章设计了如下的对比损失函数
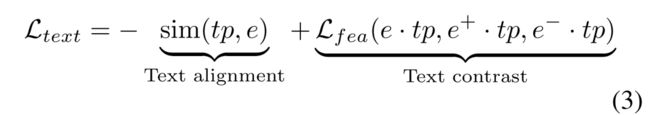
其中第一项text alignment,约束向量的相似性(最大化TS-embedding 与text embedding之间的余弦相似性);第二项text contrast,使用文本原型作为坐标轴将TS嵌入映射到相应的位置,从而保证相似的实例在文本坐标轴中有着类似的表示;此外,需要保证两个空间大小类似。
2.5 可学习的Prompt Embedding:soft prompt
本文进一步训练了针对于时序数据的soft prompt,使得语言模型能够识别到不同序列的模式,从而实现时间序列任务。这些soft prompt是针对特定任务的embedding,通过LLM输出和任务ground truth之间的loss进行学习,可以从均匀分布中随机初始化,或从下游任务标签的文本嵌入中获取初始值、从词汇表中最常见的词汇中获取初始值等。
获取prompt的目标函数如下:
![]()
有监督微调方法能有效提高下游TS任务的准确性,但训练成本高昂,同时无法保证微调后的语言模型能够有效理解TS-embedding中的语义信息。所以本文放弃了有监督微调而采用了训练soft prompt的方式,并且证明了经过训练soft prompt能够达到有监督微调相似的效果。
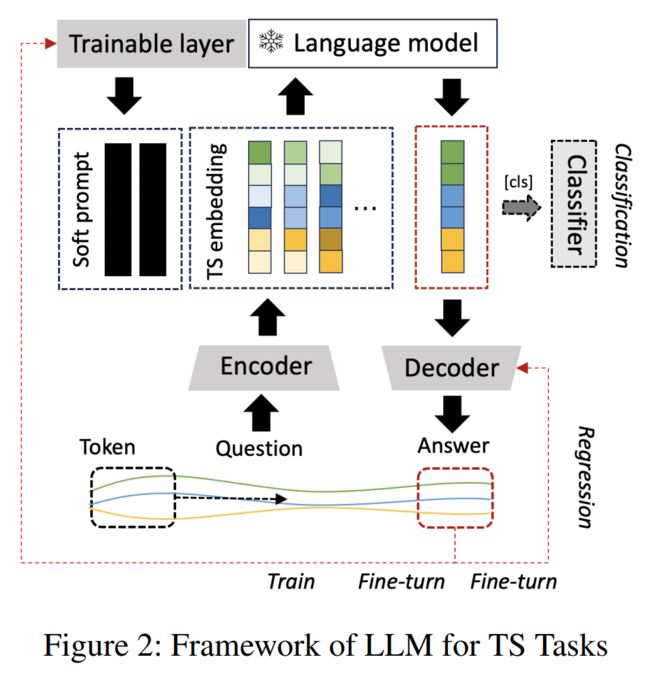
Figure 2展示了利用LLM推断TS的过程。在该框架中,文本数据被输入到LLM的嵌入层,而prompts和TS embeddings则跳过这一层。

TEST的核心是训练一个编码器和一个soft prompt 。是通过对比学习来训练的,它通过投射特征的对比和文本原型对齐特征的对比来进行自监督。针对预测任务训练。由LLM的输出进行训练,其中它由类标签或真值进行监督。对于分类任务,LLM的head 需要训练。对于预测任务,需要进行微调。
对于下游任务,TS分类任务需要在LLM fc的顶部增加一个头部,如在NLP中实现情感分类任务;TS预测任务需要一个与编码器一起训练的解码器fd。
3. 实验和结果
本文在UCR, UEA和TSER数据集上实现TS分类和预测任务,以评估TEST和其他基线。
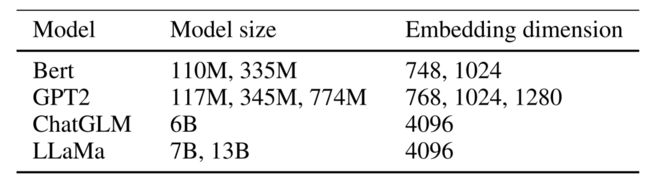
每个encoder和soft prompt使用Adam优化器借助CUDA 11.3在10个NVIDIA Tesla V100-SXM2 GPU上训练。使用到的LLM有:
3.1 分类任务
从UCR中得到128种不同的单变量TS数据集,从UEA中得到30种不同的多变量TS数据集。将本文的方法与使用或不使用prompts的LLM QA方法进行比较。TS分类任务baselines为DWT, DWTD。两个QA templates:
-
[Q] Classify the given [domain] sequence as either [class label] or [class label]: [numerical sequence]. [A];
-
[Q] Classify the sequence with average of [numerical value], variance of [numerical value], and sampling rate of [numerical value] as either [class label] or [class label]. [A].
本文不会与其他设计良好的基于深度学习的方法进行比较。因为本文的目标不是让LLM成为一个专门针对TS的模型,而是保持其原有的语言能力,同时提高其在TS任务上的表现,从以前几乎不可能达到可接受的基线。
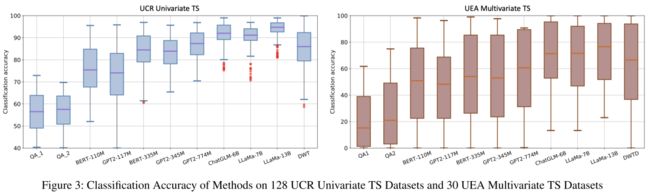
TEST使LLM的分类准确率显著提高。TEST使大多数llm与基线相当。模型的结构和大小会对结果产生影响。分类精度随着模型尺寸的增大而增大。
消融实验
-
text prototypes文本原型

不同的文本原型将导致不同的结果。本文设置了三组文本原型:1)文本值、形状和频率嵌入的3组文本原型;2)基于主成分分析的粗正交嵌入自适应文本原型。3) 10个自适应文本原型。如Figure 4顶部所示,选择一个更准确地代表LLM的整个文本嵌入空间的原型组可以提高整体分类性能。
-
prompts
对比可训练的soft prompts和hard prompt: Classify the given [domain] sequence as either [class label] or [class label]: [TS embedding].如图Figure 4 中部所示,它们的准确率相差至少10%。
对比不同初始化:1)均匀分布随机初始化;2)从分类给定序列的任务描述tokens embeddings进行初始化。如图Figure 4 中部所示,非随机初始化的性能优于随机初始化。
对比prompts长度,如图Figure 4 下部所示,当模型达到一定规模时,prompts长度为1也可以获得良好的效果,prompts长度为20也可以获得优异的效果。
3.2 案例研究
使用最近邻方法在冻结的LLM的词嵌入空间中找到一个TS标记匹配的文本。
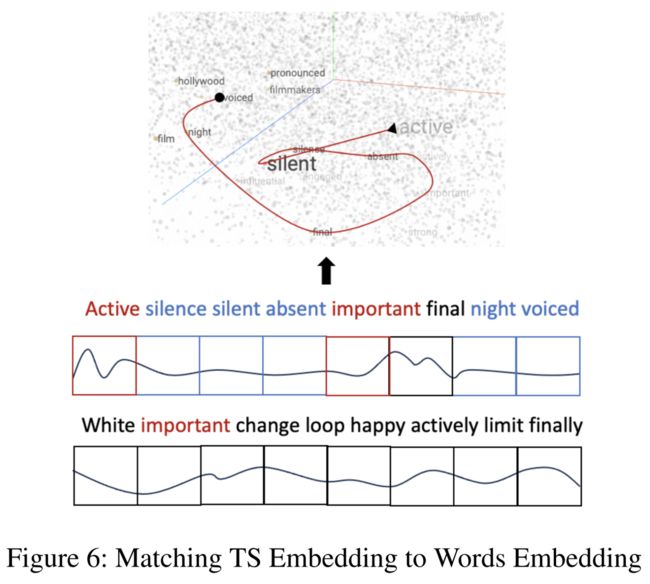
大多数单词都是关于情感的形容词和名词。通过提示,模型将把TS分类任务视为一个情感分类任务。
3.3 预测任务
两个QA templates:
-
[Q] Forecast the next value of the given [domain] sequence: [numerical sequence]. [A];
-
[Q] Forecast the next value of sequence with average of [numerical value], variance of [numerical value], and sampling rate of [numerical value]. [A].
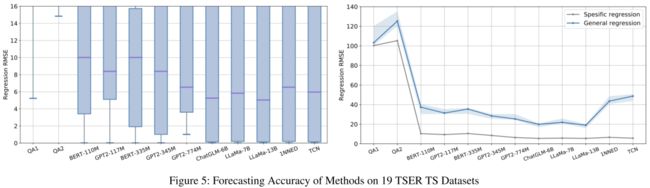
TEST使LLM的预测精度显著提高,与基线相当。原有LLM的QA模式无法实现预测任务,特别是如果TS数据被描述为均值、频次等(QA2),分类任务可能部分完成,但预测任务根本无法完成。
4. 结论和展望
TS-for-LLM的本质是:时间序列→tokens→TS embeddings↔模式文本/词嵌入。
其核心是将TS转换为llm可理解的模式序列。与这个序列相对应的文本的语义可能会让人类感到困惑,但它对LLM来说是有意义的。在本文的方法中,影响任务有效性的主要因素是LLM的大小和类型、文本原型的选择和prompts的设计。
模型类型的影响与下游任务有关,其中双向结构有利于分类,生成的结构有利于预测。更大的模型将使结果更准确。
TS-for-LLM可能不如训练面向任务的小型模型那么高效和准确,但它可以丰富大型模型的能力,并从其他角度探索其机制。TS的抽象意义使得传统的基于对齐的多模态方法难以应用。本文的强制对齐操作具有启发意义。
在当前将大模型技术应用于时序场景的相关研究中,利用大量时序数据从头训练领域化大模型的研究相对较少,直接利用预训练的大语言模型能力执行时序任务的研究要更加主流。本文对这两种技术路线进行了总结和利弊分析,也反映出当前大模型能力在时序领域迁移应用所面临的机遇与挑战。当有效的涌现在时序领域明确出现,相关行业也将加速面临技术迭代。