政安晨的机器学习笔记——基于Anaconda安装TensorFlow并尝试一个神经网络小实例
准备工作
如果想要在机器学习的过程中马上动手尝试点什么,比较好的方案是把环境配置起来后,上手跑一把程序,现在让我们开始吧。
先安装一个Anaconda,然后把Python环境跑起来。
下载地址:Free Download | AnacondaAnaconda's open-source Distribution is the easiest way to perform Python/R data science and machine learning on a single machine. https://www.anaconda.com/download 大家自己点击上面的链接去官网查看,并下载安装软件,正常安装即可,过程很简单。
https://www.anaconda.com/download 大家自己点击上面的链接去官网查看,并下载安装软件,正常安装即可,过程很简单。
完成Anaconda的安装后,我们的目标开始:安装TensorFlow并测试。
在安装TensorFlow之前,检查并设置一下系统的环境变量,把Anaconda放进去,我的位置是这样:
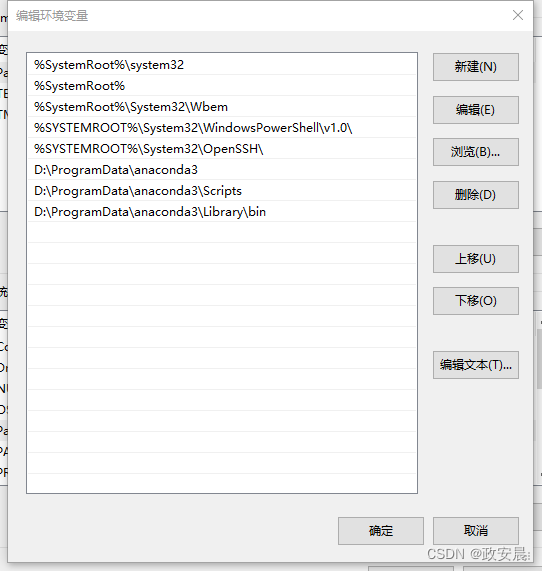
运行Anadaconda Prompt,输入conda info -e,查看所有的虚拟环境, *号表示目前所处的环境。可以看到这是一个干净的环境。
当然,也可以使用 conda list 命令查看,这个命令除了得到当前虚拟环境下的所有已安装的包,还会显示关联环境下的已安装的包。顺道说一句:pip list 只显示当前虚拟环境下的所有已安装的包。
安装TensorFlow
接下来开始安装 TensorFlow,咱们做个实例用来尝试的话,CPU版本的就可以。
在命令行中添加清华镜像(就是 Anadaconda Prompt 打开的这个命令行):
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --set show_channel_urls yes
设置后,查看一下:conda config --show channels

看到这个表示设置成功。
接下来,咱们为即将安装的TensorFlow创建环境(这个环境我们就命名为tensorflow):
在命令行中执行:
conda create -n tensorflow python=3.9
作者政安晨提醒:这里您先别急输入命令,我再说明一下:先去下面这个TensorFlow的官方链接里,看一下咱们要安装的TensorFlow版本和Python版本的对应关系。
在 Windows 环境中从源代码构建 | TensorFlowhttps://tensorflow.google.cn/install/source_windows?hl=zh-cn#cpu
点击上面链接,可以看到对应关系(我这边是这样的):

这里我选择了 Python 3.9 的版本。

安装完成。执行过程中,需要y/n时,选择y。
这时,再输入 conda info -e 命令查看已有的环境,如下:

这时可以发现,环境中已经具备了tensorflow。
执行命令激活它:
conda activate tensorflow

这时您会发现,我们已经处于python 3.9版本的名称为tensorflow的环境中了。
安装CPU版本的tensorflow(执行如下命令安装):
pip install --ignore-installed --upgrade tensorflow
(这个阶段取决于网络原因,可能要耐心等待一下)
安装完成后,可以先退出环境:conda deactivate

此时,再去看Anaconda的Navigator,可以看到我们已经有了tensorflow这个环境。
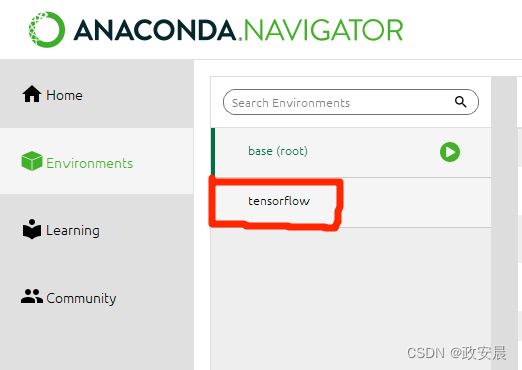
重新进入Anaconda Prompt,输入如下命令:
conda activate tensorflow 激活 tensorflow 环境。
使用 conda info -e ,可以看到当前环境已经在tensorflow中了。
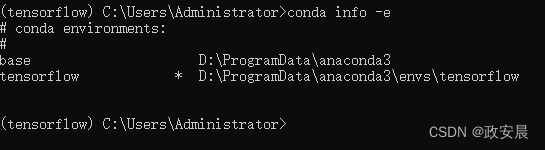
输入 python 进入python 3.9的环境

如果不小心建立错误了虚拟环境,可以删除重建,命令如下:
conda remove -n xxxxx(名字) --all,其中,xxxxx(名字)是指你当时创建环境使用的名称
我这里如果要删除的话,命令就这样写: conda remove -n tensorflow --all
注意,一定要加 --all,否则删除的是当前环境下的某一个库。而不是整体环境。
删除时要退出当前环境:conda deactivate
测试环境
1. 在命令行中执行:conda activate tensorflow
2. 在当前环境中,进入python环境 , 输入:python ,并回车
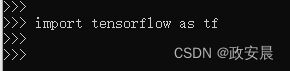
3. 在python环境中输入:import tensorflow as tf
如果命令行界面显示如下表示安装成功(即,可以成功导入库,而没有报错):
好了,至此,TensorFlow 的环境安装完毕,接下来,我们可以做个小尝试啦。
做个神经网络的小实例
让我们通过这个实例小尝试,了解一下神经网络的数学基础吧。
要理解深度学习,需要熟悉很多简单的数学概念:张量(tensor)、张量运算(tensor operation)、微分(differentiation)、梯度下降(gradient descent)等。
作者政安晨试图在笔记中运行一个神经网络应用的小实例,并使用通俗的语言帮助读者建立起对这些概念的直觉。其实建立这种概念直觉最好的方式就是尝试运行一点点代码。
这个实例是使用Python的Keras库来学习手写数字分类。
实例目标:将手写数字的灰度图像(28像素×28像素)划分到10个类别中(从0到9)。
在这个实例中,咱们使用MNIST数据集,它是机器学习领域的一个经典数据集。这个数据集包含60 000张训练图像和10 000张测试图像,由美国国家标准与技术研究院(National Institute of Standards and Technology,即MNIST中的NIST)在20世纪80年代收集而成。
下图是MNIST数据集的一些样本:

(注:在机器学习中,分类问题中的某个类别叫作类(class),数据点叫作样本(sample),与某个样本对应的类叫作标签(label)。)
接下来,咱们把MNIST数据集已预先加载在Keras库中,其中包含4个NumPy数组,程序过程如下图所示:(注:当前环境已经在tensorflow环境的python控制台中了)
执行代码:from tensorflow.keras.datasets import mnist

train_images和train_labels组成了训练集,模型将从这些数据中进行学习。然后,咱们会在测试集(包括test_images和test_labels)上对模型进行测试。
图像在数据集中已经被编码为NumPy数组,而标签是一个数字数组,取值范围是0~9。
图像和标签是一 一对应的。如下图(这个是训练数据):
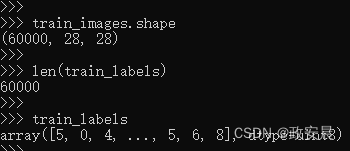
这里 train_labels的数量和图片的数量是一致的,都是60000。
现在我们再来一下测试数据:

咱们的工作流程如下:
首先,将训练数据(train_images和train_labels)输入神经网络;
然后,神经网络学习将图像和标签关联在一起;
最后,神经网络对test_images进行预测,我们来验证这些预测与test_labels中的标签是否匹配。
现在,让我们来构建一个简单的小小的神经网络:神经网络的核心组件是层(layer)。你可以将层看成数据过滤器:进去一些数据,出来的数据变得更加有用。具体来说,层从输入数据中提取表示——我们期望这种表示有助于解决咱们手头的问题。
大多数深度学习工作涉及将简单的层链接起来,从而实现渐进式的数据蒸馏(data distillation)。深度学习模型就像是处理数据的筛子,包含一系列越来越精细的数据过滤器(也就是层)。
如下图所示:
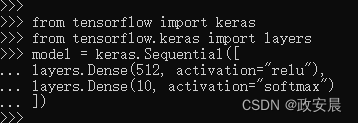
咱们这个小实例中的模型包含2个Dense层,它们都是密集连接(也叫全连接)的神经层。第2层(也是最后一层)是一个10路softmax分类层,它将返回一个由10个概率值(总和为1)组成的数组。每个概率值表示当前数字图像属于10个数字类别中某一个的概率。
接下来我们就要开始训练模型了。
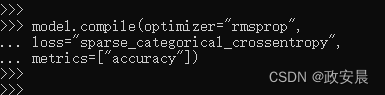
开始之前,我们还需要指定编译(compilation)步骤的3个参数,这三个参数分别是:
优化器(optimizer):模型基于训练数据来自我更新的机制,其目的是提高模型性能。
损失函数(loss function):模型如何衡量在训练数据上的性能,从而引导自己朝着正确的方向前进。
在训练和测试过程中需要监控的指标(metric):本例只关心精度(accuracy),即正确分类的图像所占比例。
指定编译步骤的代码如下:
在开始训练之前,我们先对数据进行预处理,将其变换为模型要求的形状,并缩放到所有值都在[0, 1]区间。
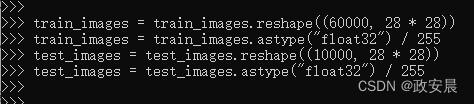
训练图像保存在一个uint8类型的数组中,其形状为(60000, 28, 28),取值区间为[0, 255]。我们将把它变换为一个float32数组,其形状为(60000, 28 * 28),取值范围是[0, 1]。
下面咱们开始准备图像数据:
现在我们准备开始训练模型。
在Keras中,这一步是通过调用模型的fit方法来完成的——我们在训练数据上拟合(fit)模型,如下:
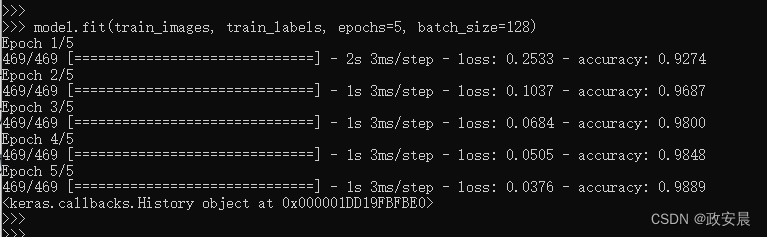
训练过程中显示了两个数字:一个是模型在训练数据上的损失值(loss),另一个是模型在训练数据上的精度(accuracy)。我们很快就在训练数据上达到了0.9889(98.89%)的精度。
现在,咱们已经得到了一个训练好的模型,可以利用它来预测新遇到数字图像的类别概率了。需要注意的是,这些新数字图像不属于训练数据,但可以是测试数据。
马上利用模型进行预测,预测过程如下:
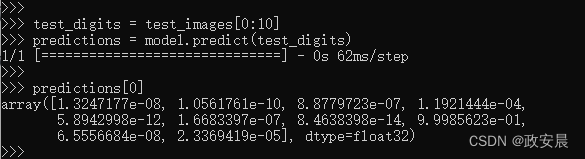
这个数组中每个索引为i的数字对应数字图像test_digits[0]属于类别i的概率。说得再清楚一点就是,predictions[0]里面有10组概率,分别对应着0、1、2、3、4、5、6、7、8、9、10 这些索引下的归属概率。
第一个测试数字在索引为7时的概率最大(0.99985623,几乎等于1),所以根据我们的模型,这个数字一定是7,展示如下:
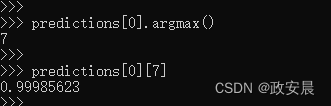
咱们现在可以检查测试标签是否与这个一致,执行如下:
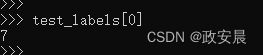
可以看到,确实是7,咱们的神经网络模型预测对了。
那么,咱们刚刚训练的这个小小的神经网络模型对未遇到的数字图像进行分类时的平均效果如何判断呢?现在咱们这个预测模型在这个测试集上的平均精度,执行如下:

测试精度约为97.93%,比训练精度(98.89%)低不少。
训练精度和测试精度之间的这种差距是过拟合(overfit)造成的。过拟合是指机器学习模型在新数据上的性能往往比在训练数据上要差。
好了,到此为止,咱们小小的神经网络模型示例结束了。
你刚刚看到了如何用极短的Python代码构建和训练一个(手写数字分类)的神经网络。
这是次简单到不能再简单的神经网络训练,但可以是一次从门外到门内的跨越。