ETCD高可用架构涉及常用功能整理
ETCD高可用架构涉及常用功能整理
- 1. etcd的高可用系统架构和相关组件
-
- 1.1 Quorum机制
- 1.2 Raft协议
- 2. etcd的核心参数
-
- 2.1 常规配置
- 2.2 特殊优化配置
-
- 2.2.1 强行拉起新集群 --force-new-cluster
- 2.2.2 兼容磁盘io性能差
- 2.2.3 etcd存储quota
- 3. etcd常用命令
-
- 3.1 常用基础命令
-
- 3.1.1 列出特定前缀的key和value
- 3.1.1 重新设置value
- 3.1.1 删除key
- 3.2 常用运维命令
-
- 3.2.1 检查集群member信息
- 3.2.2 检查集群member增加、删除
- 3.2.3 检查节点状态
- 3.2.4 检查集群状态
- 3.2.5 数据备份还原
- 4. 事务性
-
- 4.1 数据写流程
- 4.2 数据读流程
- 4.3 MVCC机制
-
- 4.3.1 并发读写事务的问题
- 4.3.2 锁机制
- 4.3.3 MVCC进行事务隔离
- 4.3.4 etcd中MVCC实现
- 5. 疑问和思考
-
- 5.1 etcd不擅长处理哪些场景?
- 5.2 etcd和zk有什么异同?
- 6. 参考文档
探讨etcd的系统架构以及以及整体常用的命令和系统分析,本文主要探讨高可用版本的etcd集群,并基于日常工作中的沉淀进行思考和整理。更多关于分布式系统的架构思考请参考文档关于常见分布式组件高可用设计原理的理解和思考
1. etcd的高可用系统架构和相关组件
etcd在产品设计上,面对的存储数据量比较小,一台etcd机器就能够满足数据的存储需求,因此在集群的架构设计上,使用镜像模式进行数据高可用,通过Raft 协议进行选举leader,从而满足集群的高可用和数据一致性要求。
etcd的系统架构如下

相关核心的组件和角色作用如下
| 角色 | 数量 | 角色作用 | 备注 |
|---|---|---|---|
| Leader | 有且必须只有1个 | 它会发起并维护与各Follwer及Observer间的心跳,所有的写操作必须要通过Leader完成再由Leader将写操作广播给其它服务器 | 通过内部选举选择出leader |
| Follower | 多个 | 会响应Leader的心跳,可直接处理并返回客户端的读请求,同时会将写请求转发给Leader处理,并且负责在Leader处理写请求时对请求进行投票 | 和Observer统称为Learner |
| Learner | 多个 | 作用跟Follow相同,但是没有投票权 | 和Follower统称为Learner |

1.1 Quorum机制
Quorum机制(有效个数)模式:指分布式系统的每一次修改都要在大多数(超过半数)实例上通过来确定修改通过。
产生Quorum机制(有效个数)的背景如下:
分布式系统的LC矛盾
在一个分布式存储系统中,用户请求会发到一个实例上。通常在一个实例上面执行的修改,需要复制到其他的实例上,这样可以保证在原实例挂了的情况下,用户依然可以看到这个修改。这就涉及到一个问题,究竟复制到多少个其他实例上之后,用户请求才会返回成功呢?如果复制的实例个数过多,那么请求响应时间就会更长;如果复制的实例过少,则这个修改可能会丢失。取得这个平衡性很重要,这也是分布式 PACELC 中的 L(Latency) 与 C(Consistency) 的取舍。
解决方案
当一个修改,被集群中的大部分节点(假设个数为N)通过之后,这个修改也就被这个集群所接受。这个 N 就是有效个数。假设集群数量为 n,那么 N = n/2 + 1.例如 n = 5,则 N = 3,从而应运而生Quorum机制(有效个数)
1.2 Raft协议
etcd 集群使用 Raft 协议保障多节点集群状态下的数据一致性。etcd 是使用 Go 语言对 Raft 协议一种实现方式。
在 Raft 体系中,有一个强 Leader,由它全权负责接收客户端的请求命令,并将命令作为日志条目复制给其他服务器,在确认安全的时候,将日志命令提交执行。当 Leader 故障时,会选举产生一个新的 Leader。在强 Leader 的帮助下,Raft将一致性问题分解为了三个子问题:
- Leader 选举:当已有的leader故障时必须选出一个新的leader。
- 日志复制:leader接受来自客户端的命令,记录为日志,并复制给集群中的- 其他服务器,并强制其他节点的日志与leader保持一致。
- 安全 safety 措施:通过一些措施确保系统的安全性,如确保所有状态机按照相同顺序执行相同命令的措施。
解这三个子问题的过程,保障了数据的一致。
2. etcd的核心参数
2.1 常规配置
etcd常用配置
- --advertise-client-urls=https://xx.xx.xx.xx:2379
- --cert-file=/etc/kubernetes/pki/etcd/server.crt
- --client-cert-auth=true
- --data-dir=/data/var/lib/etcd
- --initial-advertise-peer-urls=https://xx.xx.xx.xx:2380
# 所有集群节点
- --initial-cluster=xx.xx.xx.xx=https://xx.xx.xx.xx:2380,xx.xx.xx.xx=https://xx.xx.xx.xx:2380,xx.xx.xx.xx=https://xx.xx.xx.xx:2380,xx.xx.xx.xx=https://xx.xx.xx.xx:2380,xx.xx.xx.xx=https://xx.xx.xx.xx:2380
- --initial-cluster-state=new
- --key-file=/etc/kubernetes/pki/etcd/server.key
- --listen-client-urls=https://127.0.0.1:2379,https://xx.xx.xx.xx:2379
- --listen-metrics-urls=http://0.0.0.0:2381
- --listen-peer-urls=https://xx.xx.xx.xx:2380
- --name=xx.xx.xx.xx
- --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt
- --peer-client-cert-auth=true
- --peer-key-file=/etc/kubernetes/pki/etcd/peer.key
- --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
- --snapshot-count=10000
- --quota-backend-bytes=8589934592
- --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
- --cipher-suites=TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384,TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384,TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305,TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305,TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA,TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA,TLS_RSA_WITH_AES_128_GCM_SHA256,TLS_RSA_WITH_AES_256_GCM_SHA384,TLS_RSA_WITH_AES_128_CBC_SHA,TLS_RSA_WITH_AES_256_CBC_SHA
更多参数可以参考文档 etcd 配置标记
2.2 特殊优化配置
2.2.1 强行拉起新集群 --force-new-cluster
强行启动一个etcd集群,只有在集群崩溃的应急恢复时使用,配合2个参数
- –initial-cluster=xx.xx.xx.xx=https://xx.xx.xx.xx:2380(只能设置1个节点)
- –initial-cluster-state=new
一起使用,可以拉起一个单节点集群。后续通过member add的方式将节点加入集群进行应急恢复,具体操作可以参考 ETCD单节点故障应急恢复
2.2.2 兼容磁盘io性能差
如果磁盘的io性能很差,etcd集群可能会由于读写过慢导致集群崩溃,可以通过调整如下2个参数进行兼容
--heartbeat-interval=5000
--election-timeout=30000
2.2.3 etcd存储quota
etcd 默认默认设置了2GB 的存储配额,大概能够支撑存储两百万文件的元数据,可以通过 --quota-backend-bytes 选项进行调整,官方建议不要超过8GB。 当数据量达到配额导致无法写入时,可以通过手动压缩( etcdctl compact )和整理碎片( etcdctl defrag )的方式来减少容量。
--quota-backend-bytes=8589934592
3. etcd常用命令
利用etcd安装包中自带的etcdCli.sh命令,能够链接到etcd中,并进行相关的操作
# 连接本地etcd
./etcdCli.sh
# 远程连接etcd
./etcdCli.sh -server xx.xx.xx.xx:2181
3.1 常用基础命令
整理日常操作etcd常用的命令,便于针对etcd的数据操作。由于etcd版本问题,目前主流使用的版本都是etcdv2和etcdv3两个版本。通常主流的命令都是使用v3版本,在本文中主要介绍v3版本的日常操作
3.1.1 列出特定前缀的key和value
# 列出所有的key
ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 --cacert="/etc/kubernetes/pki/etcd/ca.crt" --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" get / --prefix --keys-only
# 列出所有的key,value
ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 --cacert="/etc/kubernetes/pki/etcd/ca.crt" --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" get / --prefix
# 列出前缀为/xx的所有key
ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 --cacert="/etc/kubernetes/pki/etcd/ca.crt" --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" get /xxx --prefix --keys-only
# 列出前缀为xx的所有key,value
ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 --cacert="/etc/kubernetes/pki/etcd/ca.crt" --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" get /xxx--prefix
3.1.1 重新设置value
# 设置对应的key和value
ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 --cacert="/etc/kubernetes/pki/etcd/ca.crt" --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" put /xxx "xxxx"
3.1.1 删除key
# 设置对应的key和value
ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 --cacert="/etc/kubernetes/pki/etcd/ca.crt" --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" del /xxx
3.2 常用运维命令
用于日常运维命令,便于进行服务运维,提升系统稳定性。
3.2.1 检查集群member信息
ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 --cacert="/etc/kubernetes/pki/etcd/ca.crt" --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" --write-out=table member list
3.2.2 检查集群member增加、删除
增加节点信息
ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 --cacert="/etc/kubernetes/pki/etcd/ca.crt" --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" --write-out=table member add xx.xx.xx.xx --peer-urls="https://xx.xx.xx.xx:2380"
删除节点信息
ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 --cacert="/etc/kubernetes/pki/etcd/ca.crt" --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" --write-out=table member remove ${memberid}
3.2.3 检查节点状态
ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 --cacert="/etc/kubernetes/pki/etcd/ca.crt" --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" --write-out=table endpoint health
–endpoints 列出所有需要检查的节点
3.2.4 检查集群状态
ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 --cacert="/etc/kubernetes/pki/etcd/ca.crt" --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" --write-out=table endpoint status
–endpoints 列出所有节点
3.2.5 数据备份还原
备份数据,备份的数据不包含节点信息
ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 --cacert="/etc/kubernetes/pki/etcd/ca.crt" --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" --write-out=table snapshot save snapshot.db
恢复数据,并基于恢复的数据启动一个单节点集群
ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 --cacert="/etc/kubernetes/pki/etcd/ca.crt" --cert="/etc/kubernetes/pki/etcd/server.crt" --key="/etc/kubernetes/pki/etcd/server.key" --write-out=table snapshot save snapshot.db
ETCDCTL_API=3 etcdctl snapshot restore snapshot.db --name xx.xx.xx.xx --initial-cluster xx.xx.xx.xx=https://xx.xx.xx.xx:2380 --initial-advertise-peer-urls https://xx.xx.xx.xx:2380 --data-dir /data/var/lib/etcd
–data-dir 是数据的保存目录,跟etcd的启动参数保持一致
4. 事务性
4.1 数据写流程
etcd的数据写流程,整体流程如下。
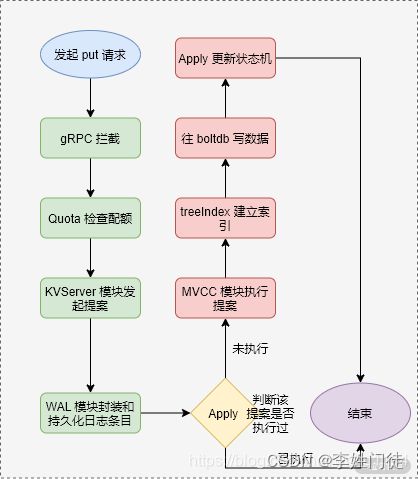
- 客户端发送写请求,通过负载均衡算法选取合适的 etcd 节点,发起 gRPC 调用。
- etcd server 的 gRPC Server 收到这个请求,经过 gRPC 拦截器拦截,实现 Metrics 统计和日志记录等功能。
- Quota 模块配额检查 db 的大小,如果超过会报etcdserver: mvcc: database space exceeded的告警,通过 Raft 日志同步给集群中的节点 db 空间不足,同时告警也会持久化到 db 中。etcd 服务端拒绝写入,对外提供只读的功能。
- 配额检查通过,KVServer 模块经过限速、鉴权、包大小判断之后,生成唯一的编号,这时才会将写请求封装为提案消息,提交给 Raft 模块。
- 写请求的提案只能由 Leader 处理(如果客户端链接到Follower会进行路由到Leader),获取到 Raft 模块的日志条目之后,Leader 会广播提案内容。WAL 模块完成 Raft 日志条目内容封装,当集群大多数节点完成日志条目的持久化,即将提案的状态变更为已提交,可以执行提案内容。
- Apply 模块用于执行提案,首先会判断该提案是否被执行过,如果已经执行,则直接返回结束;未执行过的情况下,将会进入 MVCC 模块执行持久化提案内容的操作。
- MVCC 模块中的 treeIndex 保存了 key 的历史版本号信息,treeIndex 使用 B-tree 结构维护了 key 对应的版本信息,包含了全局版本号、修改次数等属性。版本号代表着 etcd 中的逻辑时钟,启动时默认的版本号为 1。键值对的修改、写入和删除都会使得版本号全局单调递增。写事务在执行时,首先根据写入的 key 获取或者更新索引,如果不存在该 key,则会给予当前最大的 currentRevision 自增得到 revision;否则直接根据 key 获取 revision。
- 根据从 treeIndex 中获取到 revision 、修改次数等属性,以及 put 请求传递的 key-value 信息,作为写入到 boltdb 的 value,而将 revision 作为写入到 boltdb 的 key。同时为了读请求能够获取最新的数据,etcd 在写入 boltdb 时也会同步数据到 buffer。因此上文介绍 etcd 读请求的过程时,会优先从 buffer 中读取,读取不到的情况下才会从 boltdb 读取,以此来保证一致性和性能。为了提高吞吐量,此时提案数据并未提交保存到 db 文件,而是由 backend 异步 goroutine 定时将批量事务提交。
- Server 通过调用网络层接口返回结果给客户端。
总的来说,这个过程为客户端发起写请求,由 Leader 节点处理,经过拦截器、Quota 配额检查之后,KVServer 提交一个写请求的提案给 Raft 一致性模块,经过 RaftHTTP 网络转发,集群中的其他节点半数以上持久化成功日志条目,提案的状态将会变成已提交。接着 Apply 通过 MVCC 的 treeIndex、boltdb 执行提案内容,成功之后更新状态机。
整体的流程机制上,跟zk的类似,具体可以参考ZK高可用架构涉及常用功能整理。
4.2 数据读流程
相比写数据流程,读数据流程就简单得多;因为每台server中数据一致性都一样,所以随便访问哪台server读数据就行;没有写数据流程中请求转发、数据同步、成功通知这些步骤。
4.3 MVCC机制
4.3.1 并发读写事务的问题
我们知道,数据库并发场景有三种,分别为读-读、读-写和写-写。
-
读-读没有问题,不存在线程安全问题,因此不需要并发控制;
-
读-写和写-写都存在线程安全问题,读-写可能遇到脏读,幻读,不可重复读;写-写可能会存在更新丢失问题。
-
脏读(读取未提交数据):无效数据的读出,是指在数据库访问中,事务T1将某一值修改,然后事务T2读取该值,此后T1因为某种原因撤销对该值的修改,这就导致了T2所读取到的数据是无效的。值得注意的是,脏读一般是针对于update操作的,通常解决的方式是使用行级锁。
-
不可重复读(前后多次读取,数据内容不一致):事务A在执行读取操作,由整个事务A比较大,前后读取同一条数据需要经历很长的时间 。而在事务A第一次读取数据,比如此时读取了小明的年龄为20岁,事务B执行更改操作,将小明的年龄更改为30岁,此时事务A第二次读取到小明的年龄时,发现其年龄是30岁,和之前的数据不一样了,也就是数据不重复了,系统不可以读取到重复的数据,成为不可重复读。值得注意的是,不可重复读一般是针对于update操作的,通常解决的方式是使用行级锁。
-
幻读(前后多次读取,数据总量不一致):事务A在执行读取操作,需要两次统计数据的总量,前一次查询数据总量后,此时事务B执行了新增数据的操作并提交后,这个时候事务A读取的数据总量和之前统计的不一样,就像产生了幻觉一样,平白无故的多了几条数据,成为幻读。值得注意的是,幻读一般是针对于针对insert和delete操作,通常解决的方式是使用表级锁。
总结下来,这3种并发控制的问题都是,事务A执行更新操作时,事务B内多次读的结果不一致,从而导致违背了事务的ACID原则。
4.3.2 锁机制
为了解决如上问题通常是通过锁机制实现,常用的是悲观锁和乐观锁
悲观锁和乐观锁。
-
悲观锁: 为了保证事务的隔离性,就需要一致性锁定读。读取数据时给加锁,其它事务无法修改这些数据。修改删除数据时也要加锁,其它事务无法读取这些数据。
-
乐观锁:相对悲观锁而言,乐观锁机制采取了更加宽松的加锁机制。悲观锁大多数情况下依靠数据库的锁机制实现,以保证操作最大程度的独占性。但随之而来的就是数据库性能的大量开销,特别是对长事务而言,这样的开销往往无法承受。乐观锁,大多是基于数据版本( Version )记录机制实现。
MVCC是一种乐观锁
4.3.3 MVCC进行事务隔离
曾经也一度困恼我,MVCC为什么能够解决这个问题,MVCC使用多版本记录数据值,但是如果读事务需要读取最新的数据时,通过MVCC,也不是不能解决在一次读事务中多次读的不一致问题吗?
没错,如果一个读事务一定要求多次读,都必须读取到最新的数据,MVCC地区不能解决这个问题,因为这不是MVCC能够作用的范围!!
后来我重新学习和理解了事务的ACID原则,具体的内容如下
ACID,是指数据库管理系统(DBMS)在写入或更新资料的过程中,为保证交易(transaction)是正确可靠的,所必须具备的四个特性:原子性(atomicity,或称不可分割性)、一致性(consistency)、隔离性(isolation,又称独立性)、持久性(durability)。
这里并没有提到,读取的数据一定是最新的,只是要求一个读事务每次的结果都是可靠正确的,所以这就是MVCC的作用范围。读事务只需要读取到已经提交的历史最新版本,即可以保证事务的ACID!
事实上,在MySQL中MVCC只在REPEATABLE READ和READ COMMITTED两个隔离级别下工作。其他两个隔离级别都和MVCC不兼容,因为READ UNCOMMITTED总是读取最新的数据行,而不是符合当前事务版本的数据行,而SERIALIZABLE会对所有读取到的行都加锁。etcd的实现有些差异,但是整体上是一致的,etcd中没有mysql这样复杂的事务选择,因此能够通过MVCC解决读写并发的问题。
参考mysql的mvcc事务并发过程,如下

假设当前有个正在执行事务99,数据行的历史版本为事务id90(1,1)。
- 按照事务的开启时间,分别递增分配了100,101,102三个事务ID(trx id)
- 在SQL语句执行之前,事务A生成一致性视图【99,100】,事务B生成一致性视图【99,100,101】,事务C生成一致性视图【99,100,101,102】
- SQL语句的执行之前生成undo log,通过undo log可以生成历史版本数据快照,上图右侧历史版本数据。
- 事务A的查询执行时,当前数据版本为trx id:101,跟一致性视图【99,100】进行比较,101大于高水位不可见,通过undo log回退到trx id:102版本,102也大于高水位不可见,再回退一个版本到trx id:90,90低于低水位可见,所以事务A读取到的数据为(1.1)。
4.3.4 etcd中MVCC实现
这里不再赘述,可以参考 MVCC 在 etcd 中的实现
5. 疑问和思考
5.1 etcd不擅长处理哪些场景?
etcd擅长处理kv小量数据(v一般不能超过1M),基于etcd进行分布式锁、选主、服务发现等均有比较好的应用和实践。但是etcd不擅长处理大量数据的存储,通常需要注意不能在etcd路径下写入过多数据。事实上,etcd的官方建议,默认配置的是2G的Quotao,最大不能超过8G的数据存储。
5.2 etcd和zk有什么异同?
说实话,etcd和zk这两款产品实在太雷同了,基本上两者面对的使用场景基本上都是一致的,因此两个产品在是线上其实非常贴近。差异是etcd更贴近容器平台,zk更贴近大数据平台。其他的差别并太大,从使用方的角度来看,差别并不太大。值得一提的是,zk的对运维同学的友好度要比etcd友好一些,节点增加、剔除等步骤要简单很多。
6. 参考文档
- etcd 配置标记
- MVCC 在 etcd 中的实现
- etcd官方文档